Perché hai bisogno di un Knowledge Graph e come costruirlo
Why you need a Knowledge Graph and how to build it
Una guida alla migrazione da un database relazionale a un database a grafo
TLDR: Un grafo di conoscenza organizza eventi, persone, risorse e documenti in un database a grafo per l’analisi avanzata. Questo articolo spiegherà lo scopo di un grafo di conoscenza e ti mostrerà i concetti di base su come tradurre un modello di dati relazionale in un modello a grafo, caricare i dati in un database a grafo e scrivere alcune query di esempio sul grafo.
Perché un grafo di conoscenza?
I database relazionali sono ottimi per creare liste, ma terribili per gestire reti di entità diverse. Hai mai provato a svolgere uno di questi compiti con un database relazionale?
- analizzare un episodio di assistenza sanitaria in cui un paziente interagisce con decine di persone, luoghi e procedure
- trovare schemi di furti finanziari con una rete di fornitori, clienti e tipi di transazione coinvolti
- ottimizzare le dipendenze e gli elementi interconnessi di una catena di fornitura
Questi sono tutti esempi di reti di eventi, persone e risorse che creano enormi problemi agli analisti SQL che utilizzano database relazionali. I database relazionali diventano esponenzialmente più lenti all’aumentare delle dimensioni della rete, mentre i database a grafo hanno una relazione relativamente lineare. Se stai gestendo una rete o una serie di attività e cose, un database a grafo è la scelta giusta. In futuro, ci aspettiamo che i gruppi di dati aziendali adottino una combinazione di database relazionali per analisi isolate su una sola funzione aziendale e grafo di conoscenza per processi complessi e in rete che coinvolgono diverse funzioni.
Un grafo di conoscenza, basato sulla tecnologia dei database a grafo, è progettato per gestire una rete diversificata di processi ed entità. In un grafo di conoscenza, hai nodi che rappresentano persone, eventi, luoghi, risorse, documenti, ecc. E hai relazioni (archi) che rappresentano i collegamenti tra i nodi. Le relazioni sono fisicamente memorizzate nel database con un nome e una direzione. Non tutti i database a grafo sono grafi di conoscenza. Per essere considerato un grafo di conoscenza, il design deve incorporare il modello semantico aziendale, riflettendo nomi aziendali chiari per nodi e relazioni, in un insieme diversificato di nodi che coprono diverse funzioni aziendali. In sostanza, stai creando una rete continua di tutte le parti dell’azienda che interagiscono e stai usando la semantica aziendale per collegare strettamente i dati ai processi che rappresentano. Questo può servire come fondamento per l’uso futuro di modelli generativi LLM.
- Se gli ingegneri iniziano a utilizzare strumenti di codifica AI, cosa succede ai nostri team di prodotto?
- Gizzmo AI Recensione Il Miglior Strumento AI per i Contenuti di Affiliazione Amazon?
- Inizia il lavoro sul progetto per costruire ‘la strada più sofisticata al mondo
Per illustrare un insieme diversificato di dati in un grafo di conoscenza, vediamo un semplice esempio per la logistica della catena di fornitura. Il processo aziendale potrebbe essere modellato così:
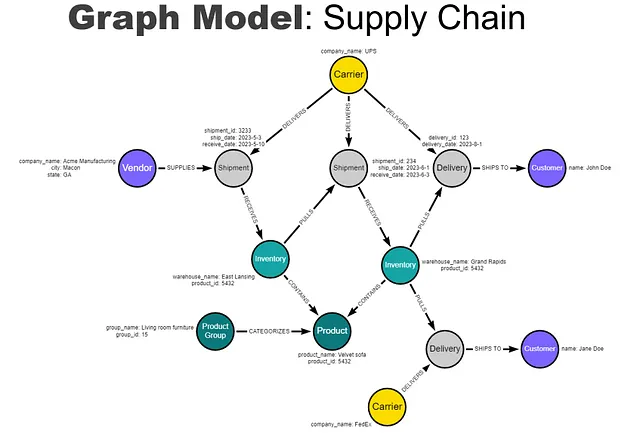
Questo modello potrebbe essere esteso per includere qualsiasi parte correlata dei processi aziendali: resi dei clienti, fatture, materie prime, processi di produzione, dipendenti e persino recensioni dei clienti. Non esiste uno schema predefinito, quindi il modello può espandersi in qualsiasi direzione o profondità.
Dal modello relazionale al modello dimensionale al modello a grafo
Ora passiamo al processo di traduzione di un tipico modello di database relazionale in un modello a grafo utilizzando lo scenario di un venditore di e-commerce. Supponiamo che questo venditore gestisca una serie di campagne di marketing digitale, riceva ordini sul suo sito web e spedisci prodotti ai clienti. Il modello relazionale potrebbe apparire così:
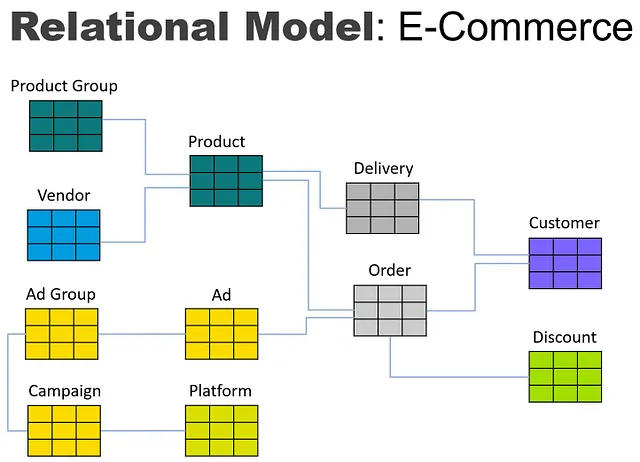
Se volessimo convertire questo in un modello dimensionale per l’uso in un data warehouse, il modello potrebbe apparire così:
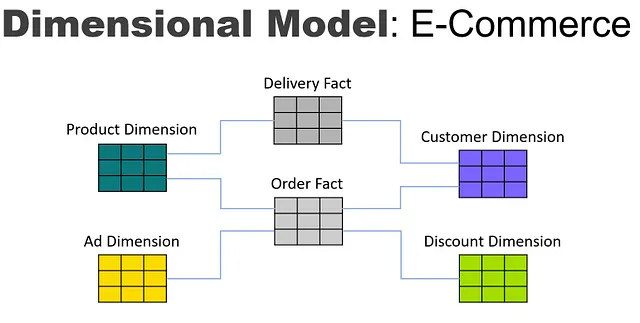
Nota che le tabelle dei fatti sono incentrate sugli eventi, mentre le tabelle dimensionali rappresentano tutti gli attributi di un’entità aziendale combinati in una tabella. Questo design incentrato sugli eventi consente tempi di interrogazione più rapidi, ma crea altri problemi. Ogni evento è una tabella dei fatti distinta ed è difficile vedere la connessione da un evento a un evento correlato. Non esiste un modo facile per comprendere tutte le relazioni tra un’entità dimensionale, come un prodotto, e tutti gli eventi che condivide con un’entità in un’altra dimensione, come un vettore, quando tali relazioni sono divise tra più tabelle dei fatti. Il modello dimensionale si concentra su un evento alla volta, ma oscura le connessioni tra i diversi eventi.
Il modello del grafo risolve il problema di mostrare l’interdipendenza tra le entità modellando il processo in questo modo:

Ad una prima occhiata, questo modello a grafo ha più somiglianze con il modello relazionale che con il modello dimensionale, ma può essere utilizzato per gli stessi scopi analitici del data warehouse. Nota che ogni relazione è denominata e ha una direzione. E le relazioni possono essere create tra qualsiasi nodo: evento a evento, persona a persona, documento a evento, ecc. Le query dei grafi ti consentono anche di attraversare il grafo in modi non possibili con SQL.
Ad esempio, puoi raccogliere tutti i nodi correlati a un evento chiave e studiare il pattern di occorrenza. Le gerarchie sono conservate e ogni livello può essere referenziato singolarmente, a differenza di una tabella dimensionale denormalizzata. Ma soprattutto, i grafi sono molto più flessibili nel modellare qualsiasi evento o entità aziendale senza seguire un rigoroso insieme di vincoli di schema. Il grafo è progettato per corrispondere al modello semantico dell’azienda.
Estrazione, Trasformazione e Caricamento (ETL)
Ora diamo un’occhiata a una tabella di un database relazionale di esempio e creiamo alcuni script di esempio per estrarre, trasformare e caricare i dati in un database a grafo. Per questo articolo, utilizzerò il linguaggio Cypher, utilizzato da Neo4j, il database a grafo commerciale più popolare. Ma i concetti si applicano anche ad altre varianti di linguaggi di interrogazione a grafo (GQL). Utilizzeremo la seguente tabella di esempio dei prodotti:
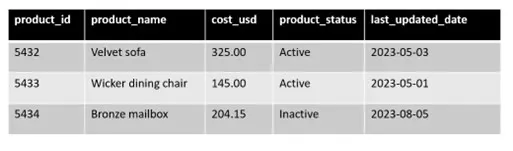
Utilizzando questa query, potremmo estrarre i nuovi prodotti aggiornati nelle ultime 24 ore:
SELECT product_id, product_name, cost_usd, product_statusFROM ProductWHERE last_updated_date > current_date -1;Potremmo recuperare questi risultati in un dataframe Python Pandas chiamato “df”, aprire una connessione al database a grafo e quindi unire il dataframe al grafo utilizzando questo script
UNWIND $df as rowMERGE INTO (p:Product {product_id: row.product_id})SET p.product_name = row.product_name, p.cost_usd = row.cost_usd, p.product_status= row.product_status, p.last_updated_date = datetime();La prima riga fa riferimento a un parametro “df”, che è il dataframe da Pandas. Eseguiamo un merge nel tipo di nodo “Product”, che viene referenziato da un alias “P”. Quindi la sezione “product_id” viene utilizzata per collegarsi a un identificatore univoco nel nodo. Dopo di ciò, l’istruzione Merge assomiglia a un merge in SQL.
Dopo aver creato ciascuno dei nodi utilizzando istruzioni di merge come quella sopra, creiamo le relazioni. Le relazioni possono essere create nello stesso script o in uno script di post-elaborazione utilizzando un comando di merge come questo:
MATCH (p:Product), (o:Order)WHERE p.product_id = o.order_idMERGE (o)-[:CONTAINS]->(p);L’istruzione Match assomiglia all’uso di join legacy in Oracle, con due tipi di nodi dichiarati dopo il Match e quindi il join che avviene nella clausola Where.
Interrogazioni sul Modello a Grafo
Supponiamo di aver costruito il grafo e ora vogliamo interrogarlo. Possiamo utilizzare una query come questa per visualizzare i gruppi di annunci che hanno generato ordini dall’Arizona.
MATCH (ag:AdGroup)<-[:BELONGS_TO]-(a:Ad)-[:DRIVES]->(o:Order)<-[:PLACES]-(c:Customer)WHERE c.state = 'AZ'RETURN ag.group_name, COUNT(o) as order_countQuesta query restituirebbe il nome del gruppo di annunci e il conteggio degli ordini, filtrati per lo stato dell’Arizona. Nota che in Cypher non è necessaria una clausola Group By, a differenza di SQL. Da questa query, otterremmo il seguente output di esempio:

Questo esempio potrebbe sembrare banale perché potresti facilmente creare una query simile in un database relazionale o un data warehouse utilizzando la tabella dei fatti degli ordini. Ma consideriamo una query più complicata. Supponiamo che tu voglia vedere il tempo che intercorre dal lancio di una campagna fino a quando le consegne attribuibili sono state ricevute. In un data warehouse, questa query attraverserebbe tabelle dei fatti (non un compito semplice) e richiederebbe risorse considerevoli. In un database relazionale, questa query comporterebbe una lunga serie di join. In un database su grafo, la query sarebbe così:
MATCH (cp:Campaign) )<-[:BELONGS_TO]-(ag:AdGroup)<-[:BELONGS_TO]-(a:Ad)MATCH (a)-[:DRIVES]->(o:Order)<-[:FULFILLS]-(d:Delivery)RETURN cp.campaign_name, cp.start_date as campaign_launch_date, MAX(d.receive_date) as last_delivery_dateHo utilizzato un percorso di query di esempio, ma esistono diverse varianti di percorsi che un utente potrebbe seguire per rispondere a diverse domande di business. Nella query, nota che il percorso da Campaign a Delivery passa attraverso una relazione tra Order e Delivery. Nota anche che per una migliore leggibilità ho diviso il percorso in due parti, iniziando con l’alias per Ad nella seconda riga. L’output della query sarebbe simile a questo:

Conclusioni
Abbiamo esaminato alcuni passaggi di esempio per tradurre un processo aziendale di e-commerce da un modello relazionale a un modello su grafo, ma non possiamo coprire tutti i principi di progettazione in questo unico articolo. Spero che tu abbia visto che i database su grafo richiedono circa lo stesso livello di competenze tecniche dei database relazionali e che la migrazione non sia un ostacolo enorme.
La sfida più grande è rieducare la tua mente a distanziarsi dalle tecniche tradizionali di modellazione relazionale e pensare in termini di modellazione semantica o aziendale. Se vedi un’applicazione potenziale per la tecnologia dei grafi, provala con un progetto di proof-of-concept. Le possibilità di analisi con un grafo di conoscenza vanno ben oltre ciò che puoi fare con tabelle bidimensionali!
Tutte le immagini sono dell’autore





