Dal caos all’ordine utilizzare il clustering dei dati per migliorare la presa di decisioni
Utilizzare il clustering dei dati per migliorare la presa di decisioni
Questo articolo mostrerà i casi d’uso importanti dei metodi di clustering dei dati, come utilizzare questi metodi e mostrerà anche come si possono utilizzare questi metodi come tecnica di riduzione della dimensionalità.
Prima di tutto, discutiamo dei casi d’uso che rendono questi metodi così popolari.
Segmentazione dei clienti
I negozi online utilizzano questo metodo per raggruppare i loro clienti in base ai loro modelli di acquisto, al giorno dell’acquisto, all’età, al reddito e ad altri fattori. Questo aiuta il negozio a capire meglio i propri clienti e aiuta anche a prendere decisioni che garantiscano una grande redditività.
Per capire questo in modo più chiaro, prendiamo un esempio. Supponiamo che dopo il clustering dei clienti in base al giorno dell’acquisto e alla loro età, abbiamo scoperto che le persone con un’età inferiore ai 22 anni spendono molto meno negli ultimi giorni del mese. È molto probabile che la maggior parte delle persone con un’età inferiore ai 22 anni siano studenti e, dato che la fine del mese è finanziariamente difficile per la maggior parte di loro, potrebbero essere riluttanti a visitare il negozio. Quindi, per utilizzare questo a vantaggio del negozio, il negozio potrebbe organizzare sconti alla fine del mese, che potrebbero attirare il pubblico degli studenti nel negozio più frequentemente rispetto a prima, anche alla fine del mese.
- Introduzione alla Data Science Guida per principianti
- All’interno di SDXL 1.0 Stabilità AI Nuovo Super Modello di Testo-immagine
- Ricercatori trovano falle nei controlli di sicurezza di ChatGPT e altri chatbot
Il negozio potrebbe non aver trovato questa soluzione se non avesse utilizzato il clustering sui clienti.
Puoi trovare un altro esempio di clustering in questo Tableau Dashboard.
Per l’analisi dei dati
A volte troviamo risultati interessanti quando analizziamo ciascun cluster dei dati separatamente anziché analizzare tutti i dati insieme.
Come tecnica di riduzione della dimensionalità
I metodi di clustering possono anche essere utilizzati come metodi di riduzione della dimensionalità. Vedremo come fare questo alla fine dell’articolo.
Apprendimento semi-supervisionato
Possiamo aumentare l’accuratezza del nostro modello di apprendimento automatico raggruppando prima i dati e poi addestrando un modello separato per ogni cluster.
A volte, quando utilizziamo un metodo di apprendimento semi-supervisionato per il problema di classificazione, potremmo ottenere istanze con la stessa etichetta in uno dei cluster. Per affrontare una tale situazione, possiamo creare un modello che restituisca la stessa etichetta per ogni istanza che viene fornita in input.
Puoi trovare questo approccio utilizzato in uno dei miei progetti. Puoi vedere il codice sorgente per il progetto sul mio account Github.
Altri casi d’uso
Oltre ai casi d’uso sopra citati, il clustering è molto utile per la segmentazione delle immagini, ecc.
Ora vediamo alcuni dei metodi di clustering più famosi.
Clustering di KMeans
KMeans è uno dei metodi di clustering più famosi. Questo metodo cercherà di trovare il centro del blob e quindi assegnerà ciascuna istanza a uno dei centri.
Vediamo come funziona questo metodo.
Inizia semplicemente posizionando casualmente i centroidi. Quindi etichetta ciascuno dei cluster. Assegna quindi un’etichetta a ogni istanza. L’istanza otterrà l’etichetta di un cluster che è più vicino ad essa. Quindi aggiorneremo nuovamente i centroidi. Dopo questo, ripeteremo il processo ancora e ancora fino a quando non troveremo alcuna modifica ai centroidi.
Anche se questo algoritmo è garantito di convergere, potrebbe non convergere alla soluzione ottimale. La convergenza alla soluzione corretta dipende dall’inizializzazione dei centroidi, ovvero le coordinate del centroide che utilizziamo all’inizio dell’algoritmo.
Una delle soluzioni a questo problema è eseguire l’algoritmo più volte con diverse inizializzazioni casuali dei centroidi e quindi conservare la migliore soluzione. La migliore soluzione viene trovata dalla misura delle prestazioni nota come inerzia. È fondamentalmente la distanza quadrata media tra ciascuna istanza e il centroide più vicino.
C’è una soluzione più popolare a questo problema. Il nuovo algoritmo che implementa questa soluzione è noto come KMeans++.
Ha introdotto un nuovo passaggio di inizializzazione che tende a selezionare centroidi distanti tra loro e questo miglioramento ha reso l’algoritmo KMeans molto meno probabile che converga a una soluzione sub-ottimale.
Esistono alcune variazioni dell’algoritmo KMeans, come ad esempio KMeans accelerato o KMeans a mini batch, ecc.
Possiamo facilmente implementare questo algoritmo utilizzando le classi integrate della libreria Scikit-Learn. Ma, la vera sfida è trovare il numero ottimale di cluster che separerebbe perfettamente i dati.
Trovare il numero ottimale di cluster
Ci sono due metodi che possono essere utilizzati per trovare il numero ottimale di cluster:
- Utilizzando il metodo del gomito e un punteggio di silhouette
- Utilizzando la libreria Python kneed
Utilizzando il metodo del gomito e il punteggio di silhouette
Il metodo del gomito consiste nel trovare il punto di flesso nel grafico tra l’inertia e il numero di cluster. Vogliamo un valore di inertia che non sia né troppo alto né troppo basso. In generale, tale valore si trova nel punto di flesso del grafico inertia vs numero-di-cluster.
Possiamo trovare il punteggio di silhouette utilizzando la libreria Scikit-learn. Il punteggio di silhouette si trova tra -1 e 1.
Un punteggio di silhouette vicino a 1 significa che l’istanza è ben all’interno del proprio cluster e lontana dagli altri cluster. Un punteggio di silhouette vicino a 0 significa che è vicino al limite del cluster. Un punteggio di silhouette vicino a -1 significa che l’istanza potrebbe essere stata assegnata al cluster sbagliato.
Quindi troviamo il numero ottimale di cluster in modo che l’inertia non sia né troppo alta né troppo bassa e anche il punteggio di silhouette dovrebbe essere decente.
Vediamo come fare questo.
## import necessariimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as sns## lettura dei dati"""A scopo dimostrativo, utilizzeremo un dataset semplice che mostra la quantità di mancia ricevuta da un cameriere, basata su vari fattori come il giorno della settimana, l'orario del pasto, il conto totale e altro ancora."""df = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/tips.csv')df.head()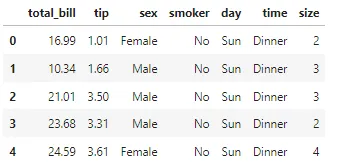
## grafico del totale del conto vs manciaplt.figure(figsize=(12,8))sns.set_style('darkgrid')plt.plot(df['total_bill'], df['tip'], 'bo')plt.xlabel('Totale Conto')plt.ylabel('Mancia')plt.title('Totale Conto VS Mancia')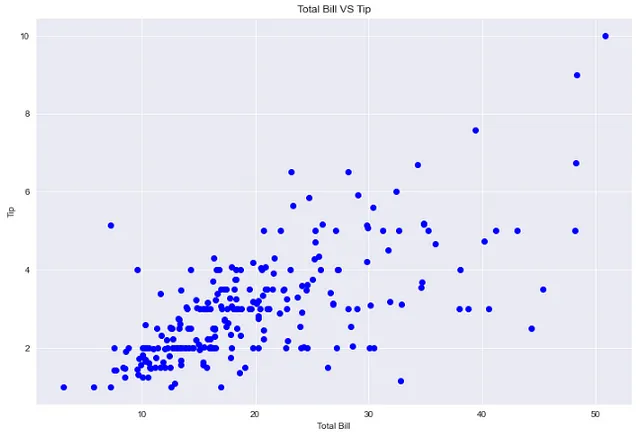
## clustering del dataframe utilizzando la colonna total_bill, tip e size## ricerca del numero ottimale di cluster utilizzando il metodo del gomito"""Per tracciare la relazione tra inertia e numero di cluster, addestreremo diversi modelli di clustering con diversi numeri di cluster ogni volta. Per ciascuno di questi modelli, registreremo l'inertia. Infine, utilizzeremo tutte le inertia registrate per creare un grafico."""from sklearn.cluster import KMeansinertia_list = [KMeans(n_clusters=i).fit(df[['total_bill','tip']]).inertia_ for i in range(2,10)]plt.figure(figsize=(12,8))sns.set_style('darkgrid')plt.plot(list(range(2,10)),inertia_list, 'rx', ls='solid')plt.xlabel('Numero di Cluster')plt.ylabel('Inertia')plt.title('Ricerca del numero ottimale di cluster utilizzando il metodo del gomito')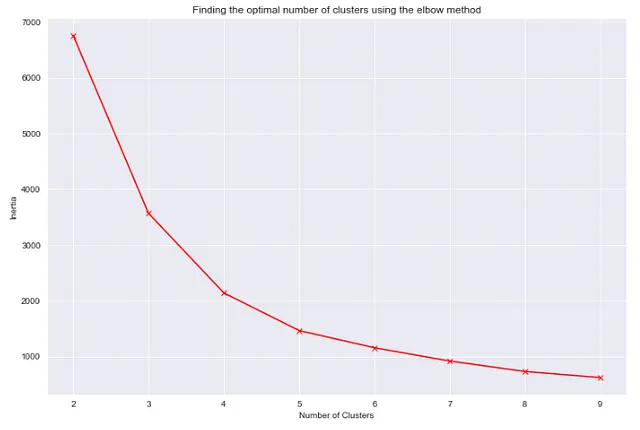
Secondo il grafico, il numero ottimale di cluster dovrebbe essere 4 o 5. Il valore di inertia a questi due valori non è né troppo alto né troppo basso.
## ricerca del numero ottimale di cluster utilizzando il punteggio di silhouettefrom sklearn.metrics import silhouette_score"""Utilizzeremo un processo simile per creare un grafico dei punteggi di silhouette vs numero di cluster, come abbiamo fatto durante la creazione del grafico inertia vs numero di cluster."""sil_score_list = []for i in range(2,10): kmeans = KMeans(n_clusters=i) kmeans.fit(df[['total_bill','tip']]) sil_score_list.append(silhouette_score(df[['total_bill','tip']],kmeans.labels_))plt.figure(figsize=(12,8))sns.set_style('darkgrid')plt.plot(list(range(2,10)),sil_score_list, 'mx', ls='solid')plt.xlabel('Numero di Cluster')plt.ylabel('Punteggio di Silhouette')plt.title('Ricerca del numero ottimale di cluster utilizzando il punteggio di silhouette')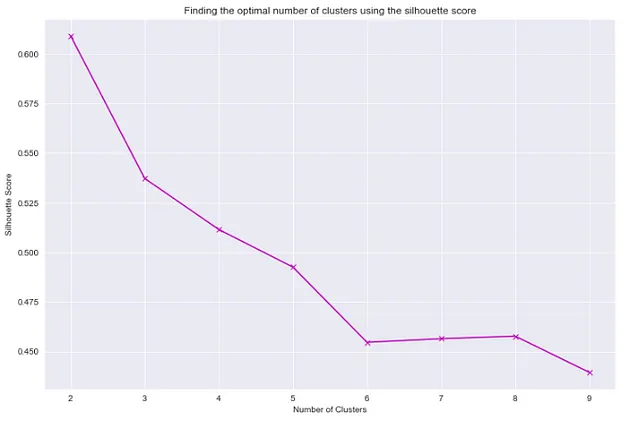
Secondo i due grafici sopra, con il numero di cluster pari a 4, otterremo un punteggio di silhouette abbastanza buono e un buon valore di inerzia. Quindi, possiamo utilizzare 4 cluster per ottenere una buona prestazione per il clustering.
Utilizzando la libreria Python kneed
## trovare il numero ottimale di cluster per il modello kmeans utilizzando la libreria kneedfrom kneed import KneeLocatorkn = KneeLocator(range(2,10), inertia_list, curve='convex',direction='decreasing')print(f"Il numero ottimale di cluster per il modello kmeans: {kn.knee}")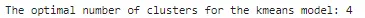
La libreria Kneed ha dato lo stesso valore per il numero di cluster come il primo metodo. Ora utilizziamo 4 cluster per separare i dati e poi visualizzare i cluster.
## utilizzare il numero di cluster pari a 4 per il clustering dei datikmeans_final = KMeans(n_clusters=4)kmeans_final.fit(df[['total_bill','tip']])pred = kmeans_final.predict(df[['total_bill','tip']])## creare una nuova colonna per le etichette dei clusterdf['cluster'] = pred## visualizzare i cluster ## tracciare i dati dopo il clusteringsns.set_style('whitegrid')sns.jointplot(x='total_bill', y='tip', data=df, hue='cluster',palette='coolwarm');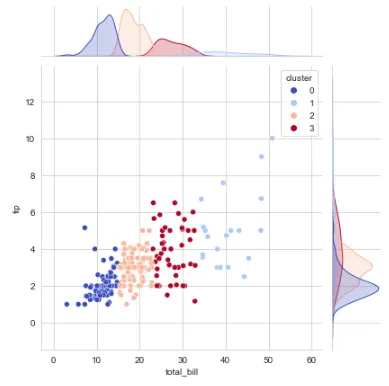
Clustering DBSCAN
Questo algoritmo definisce i cluster come regioni continue di alta densità separate da regioni di bassa densità. A causa di ciò, il clustering effettuato da DBSCAN può assumere qualsiasi forma, a differenza di KMeans, che fornisce cluster a forma convessa.
Il componente più importante dell’algoritmo DBSCAN è il concetto di campioni centrali. I campioni centrali sono le istanze presenti nelle regioni ad alta densità. Quindi, fondamentalmente, i cluster nell’algoritmo DBSCAN sono l’insieme di campioni centrali che sono vicini l’uno all’altro e un insieme di campioni non centrali che sono vicini ai campioni centrali. Possiamo facilmente implementare l’algoritmo DBSCAN utilizzando la classe DBSCAN di Scikit-Learn. Questa classe ha due parametri importanti, min_samples ed eps, che definiscono cosa intendiamo quando diciamo denso.
Per ogni istanza, l’algoritmo conta quante istanze si trovano entro una piccola distanza eps da essa. Questa regione viene chiamata vicinato eps dell’istanza.
Se un’istanza ha almeno min_samples istanze nel suo vicinato eps (inclusa se stessa), viene considerata un’istanza centrale. Tutte le istanze nel vicinato dell’istanza centrale appartengono allo stesso cluster. Questo vicinato può includere altre istanze centrali e quindi una lunga sequenza di istanze centrali vicine da un singolo cluster.
Vediamo come eseguire il clustering utilizzando la classe Scikit-Learn utilizzando gli stessi dati che abbiamo utilizzato per il clustering KMeans.
from sklearn.cluster import DBSCAN## creare i clustersdbscan_pred = DBSCAN(eps=2, min_samples=5).fit_predict(df[['total_bill','tip']])df['DBSCAN_Pred'] = dbscan_pred## tracciare i dati dopo il clusteringsns.set_style('whitegrid')sns.jointplot(x='total_bill', y='tip', data=df, hue='DBSCAN_Pred',palette='coolwarm');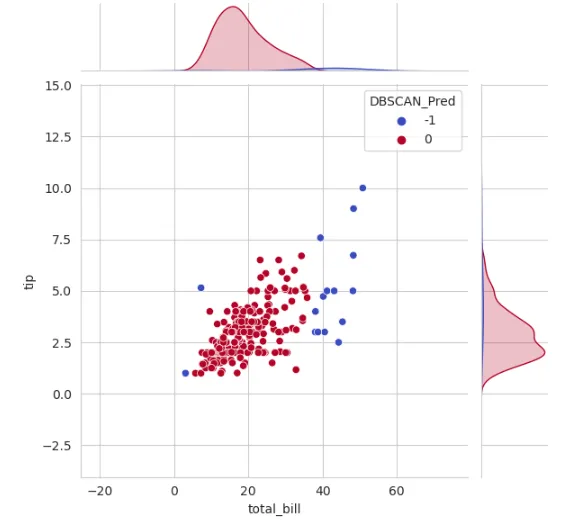
Si noti che i campioni di dati rumorosi sono etichettati con il valore -1.
Ci sono molti altri algoritmi di clustering come il clustering agglomerativo, il clustering mean-shift, la propagazione di affinità, il clustering spettrale, ecc.
Ora che abbiamo imparato come implementare algoritmi di clustering, vediamo come possiamo utilizzare questi metodi per il problema della riduzione della dimensionalità.
Utilizzo del clustering come metodo di riduzione della dimensionalità
Possiamo individuare l’affinità di ogni istanza con ciascun cluster una volta completato il clustering dei dati.
L’affinità è la misura di quanto bene ogni istanza si adatta ai diversi cluster.
Una volta che abbiamo il vettore di affinità di ogni istanza, possiamo sostituire l’istanza originale con il suo vettore di affinità. Se il vettore di affinità ha k dimensioni, allora le nuove dimensioni dei dati saranno solo k.
Non importa quante dimensioni ha il dato originale, dopo il clustering, il dato avrà dimensioni pari al numero di cluster in cui il dato è diviso.
Utilizziamo un dataset di fiori di iris per questa dimostrazione.
## import necessarimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.metrics import confusion_matrix## lettura del datasetdf1 = pd.read_csv('percorso-dati')## Rimozione delle caratteristiche non necessariedf1.drop('Id',axis=1,inplace=True)## Divisione del dato in caratteristiche dipendenti e indipendentiX = df1.drop('Species',axis=1)y = df1['Species']## Divisione del dato in dati di allenamento e di testX_train, X_test, y_train, y_test = train_test_split(X, y,random_state=238, test_size=0.33)## alleniamo prima il modello direttamente senza utilizzare alcuna tecnica di riduzione della dimensionalità## qui utilizziamo il modello classificatore random forest per l'allenamentorfc = RandomForestClassifier(n_estimators=250,n_jobs=-1,max_depth=3)rfc.fit(X_train, y_train)rfc_predictions = rfc.predict(X_test)## verifica della matrice di confusione delle previsionifrom sklearn.metrics import confusion_matrixmatrix = confusion_matrix(y_test, rfc_predictions)print("Matrice di confusione per il modello creato prima di applicare qualsiasi tipo di metodo di riduzione della dimensionalità:\n")confusion_matrix(y_test,rfc_predictions, labels = df1['Species'].unique())
## import necessarifrom sklearn.cluster import KMeans## creiamo 3 clusterk = 3kmeans = KMeans(n_clusters=k)kmeans.fit(X_train)X_train_new = kmeans.transform(X_train)## ora utilizziamo questi valori come nuovo set di allenamentorfc_new = RandomForestClassifier(max_depth=3,n_jobs=-1,n_estimators=250)rfc_new.fit(X_train_new,y_train)rfc_new_predictions = rfc_new.predict(kmeans.transform(X_test))## verifica della matrice di confusione delle previsioni dopo aver sostituito i vettori di caratteristiche per le istanze con il vettore di affinitàprint("Matrice di confusione per il modello creato dopo aver sostituito i vettori di caratteristiche per le istanze con il vettore di affinità:\n")confusion_matrix(y_test,rfc_new_predictions, labels = df1['Species'].unique())
Qui possiamo vedere che ci sono 2 previsioni più inaccurate rispetto a prima. Questo è dovuto al fatto che il metodo di riduzione della dimensionalità perde alcune informazioni. Tuttavia, avere solo 2 previsioni inaccurate indica comunque un alto livello di precisione.
Spero che l’articolo ti piaccia. Se hai qualche pensiero sull’articolo, fammelo sapere. Qualsiasi feedback costruttivo è molto apprezzato. Collegati con me su LinkedIn. Buona giornata!






