Utilizzando LoRA per una messa a punto della diffusione stabile ed efficiente
Utilizzando LoRA per la diffusione stabile ed efficiente.
LoRA: Low-Rank Adaptation of Large Language Models è una nuova tecnica introdotta dai ricercatori di Microsoft per affrontare il problema del fine-tuning dei modelli di linguaggio di grandi dimensioni. Modelli potenti con miliardi di parametri, come GPT-3, sono proibitivamente costosi da sintonizzare per adattarli a compiti o domini specifici. LoRA propone di congelare i pesi del modello pre-addestrato e inserire strati addestrabili (matrici di decomposizione di rango) in ogni blocco del trasformatore. Questo riduce notevolmente il numero di parametri addestrabili e i requisiti di memoria GPU poiché i gradienti non devono essere calcolati per la maggior parte dei pesi del modello. I ricercatori hanno scoperto che concentrandosi sui blocchi di attenzione del trasformatore dei modelli di linguaggio di grandi dimensioni, la qualità del fine-tuning con LoRA era paragonabile al fine-tuning del modello completo, ma molto più veloce e richiedeva meno risorse di calcolo.
LoRA per i diffusori 🧨
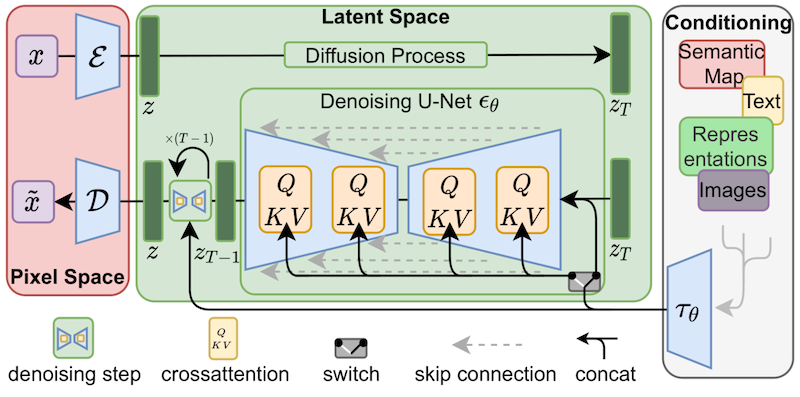
Anche se LoRA è stato inizialmente proposto per i modelli di linguaggio di grandi dimensioni e dimostrato su blocchi di trasformatori, la tecnica può essere applicata anche altrove. Nel caso del fine-tuning di Stable Diffusion, LoRA può essere applicato ai livelli di cross-attenzione che collegano le rappresentazioni delle immagini alle descrizioni che le riguardano. I dettagli della figura seguente (tratta dal documento di Stable Diffusion) non sono importanti, basta notare che i blocchi gialli sono quelli responsabili della creazione della relazione tra le rappresentazioni delle immagini e del testo.
Per quanto ne sappiamo, Simo Ryu ( @cloneofsimo ) è stato il primo a proporre un’implementazione di LoRA adattata a Stable Diffusion. Vi preghiamo di dare un’occhiata al loro progetto GitHub per vedere esempi e molte discussioni e intuizioni interessanti.
- Generazione di risorse 2D Intelligenza Artificiale per lo sviluppo di giochi #4
- Lo stato della Visione Artificiale presso Hugging Face 🤗
- Un’immedesimazione nei modelli di visione-linguaggio
Per inserire matrici addestrabili LoRA nel modello fino ai livelli di cross-attenzione, le persone dovevano solitamente manipolare il codice sorgente dei diffusori in modi fantasiosi (ma fragili). Se Stable Diffusion ci ha mostrato qualcosa, è che la comunità trova sempre modi per piegare e adattare i modelli a scopi creativi, e ciò ci entusiasma! Fornire la flessibilità di manipolare i livelli di cross-attenzione potrebbe essere vantaggioso per molti altri motivi, come rendere più facile l’adozione delle tecniche di ottimizzazione come xFormers. Altri progetti creativi come Prompt-to-Prompt potrebbero trarre vantaggio da un modo semplice per accedere a quei livelli, quindi abbiamo deciso di fornire un modo generale per farlo. Abbiamo testato quella richiesta di pull dalla fine di dicembre ed è stata lanciata ufficialmente con il nostro rilascio dei diffusori ieri.
Abbiamo collaborato con @cloneofsimo per fornire supporto all’addestramento di LoRA nei diffusori, sia per i metodi di Dreambooth che per il fine-tuning completo! Queste tecniche offrono i seguenti vantaggi:
- L’addestramento è molto più veloce, come già discusso.
- I requisiti di calcolo sono inferiori. Siamo riusciti a creare un modello completamente addestrato su una 2080 Ti con 11 GB di VRAM!
- I pesi addestrati sono molto, molto più piccoli. Poiché il modello originale è congelato e inseriamo nuovi strati da addestrare, possiamo salvare i pesi dei nuovi strati in un unico file che pesa circa 3 MB. Questo è circa mille volte più piccolo rispetto alle dimensioni originali del modello UNet!
Siamo particolarmente entusiasti dell’ultimo punto. Per permettere agli utenti di condividere i loro fantastici modelli addestrati o dreamboothed, dovevano condividere una copia completa del modello finale. Gli altri utenti che desiderano provarli devono scaricare i pesi addestrati nella loro interfaccia utente preferita, con costi di archiviazione e download combinati massicci. Ad oggi, ci sono circa 1.000 modelli Dreambooth registrati nella Dreambooth Concepts Library, e probabilmente molti altri non registrati nella libreria.
Con LoRA, ora è possibile pubblicare un singolo file di 3,29 MB per consentire agli altri di utilizzare il tuo modello addestrato.
(h/t a @mishig25, la prima persona che ho sentito usare dreamboothing come verbo in una conversazione normale).
Fine-tuning con LoRA
Il fine-tuning del modello completo di Stable Diffusion era solitamente lento e difficile, ed è parte del motivo per cui metodi più leggeri come Dreambooth o Textual Inversion sono diventati così popolari. Con LoRA, è molto più facile sintonizzare un modello su un dataset personalizzato.
Diffusers fornisce ora uno script di fine-tuning con LoRA che può essere eseguito con soli 11 GB di RAM GPU senza ricorrere a trucchi come gli ottimizzatori a 8 bit. Ecco come si utilizza per sintonizzare un modello utilizzando il dataset dei Pokémon di Lambda Labs:
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="/sddata/finetune/lora/pokemon"
export HUB_MODEL_ID="pokemon-lora"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch --mixed_precision="fp16" train_text_to_image_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME \
--dataloader_num_workers=8 \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=15000 \
--learning_rate=1e-04 \
--max_grad_norm=1 \
--lr_scheduler="cosine" --lr_warmup_steps=0 \
--output_dir=${OUTPUT_DIR} \
--push_to_hub \
--hub_model_id=${HUB_MODEL_ID} \
--report_to=wandb \
--checkpointing_steps=500 \
--validation_prompt="Totoro" \
--seed=1337Una cosa da notare è che il tasso di apprendimento è 1e-4, molto più grande dei normali tassi di apprendimento per il fine-tuning regolare (nell’ordine di ~1e-6, di solito). Questo è un cruscotto W&B dell’esecuzione precedente, che ha richiesto circa 5 ore su una GPU 2080 Ti (11 GB di RAM). Non ho cercato di ottimizzare gli iperparametri, quindi sentiti libero di provarlo tu stesso! Sayak ha eseguito un’altra esecuzione su una T4 (16 GB di RAM), ecco il suo modello finale e qui c’è una demo Space che lo utilizza.

Per ulteriori dettagli sul supporto LoRA nei diffusers, consulta la nostra documentazione: sarà sempre aggiornata con l’implementazione.
Inferenza
Come abbiamo discusso, uno dei principali vantaggi di LoRA è che si ottengono risultati eccellenti addestrando ordini di grandezza di pesi inferiori rispetto alla dimensione del modello originale. Abbiamo progettato un processo di inferenza che consente di caricare i pesi aggiuntivi oltre ai pesi non modificati del modello Stable Diffusion. Vediamo come funziona.
Prima di tutto, useremo l’API di Hub per determinare automaticamente quale è stato il modello di base utilizzato per il fine-tuning di un modello LoRA. A partire dal modello di Sayak, possiamo utilizzare questo codice:
from huggingface_hub import model_info
# Pesi LoRA ~3 MB
model_path = "sayakpaul/sd-model-finetuned-lora-t4"
info = model_info(model_path)
model_base = info.cardData["base_model"]
print(model_base) # CompVis/stable-diffusion-v1-4Questo frammento di codice stamperà il modello usato per il fine-tuning, che è CompVis/stable-diffusion-v1-4. Nel mio caso, ho addestrato il mio modello a partire dalla versione 1.5 di Stable Diffusion, quindi se esegui lo stesso codice con il mio modello LoRA vedrai che l’output è runwayml/stable-diffusion-v1-5.
Le informazioni sul modello di base vengono automaticamente popolate dallo script di fine-tuning che abbiamo visto nella sezione precedente, se si utilizza l’opzione --push_to_hub. Questo viene registrato come un tag di metadati nel file README del repository del modello, come puoi vedere qui.
Dopo aver determinato il modello di base che abbiamo utilizzato per il fine-tuning con LoRA, carichiamo una normale pipeline Stable Diffusion. La personalizziamo con il DPMSolverMultistepScheduler per un’inferenza molto veloce:
import torch
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
pipe = StableDiffusionPipeline.from_pretrained(model_base, torch_dtype=torch.float16)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)E qui arriva la magia. Carichiamo i pesi LoRA dall’Hub in cima ai pesi del modello regolare, spostiamo la pipeline sul dispositivo cuda e facciamo l’inferenza:
pipe.unet.load_attn_procs(model_path)
pipe.to("cuda")
image = pipe("Pokemon verde con faccia minacciosa", num_inference_steps=25).images[0]
image.save("green_pokemon.png")Dreamboothing con LoRA
Dreambooth ti consente di “insegnare” nuovi concetti a un modello di diffusione stabile. LoRA è compatibile con Dreambooth e il processo è simile al fine-tuning, con un paio di vantaggi:
- La formazione è più veloce.
- Abbiamo bisogno solo di alcune immagini del soggetto che vogliamo addestrare (di solito 5 o 10 sono sufficienti).
- Possiamo regolare l’encoder di testo, se vogliamo, per una maggiore fedeltà al soggetto.
Per addestrare Dreambooth con LoRA devi utilizzare questo script diffusori . Per favore, dai un’occhiata al README , alla documentazione e al nostro post sul blog sull’esplorazione degli iperparametri per i dettagli.
Per un modo rapido, economico e facile per addestrare i tuoi modelli Dreambooth con LoRA, controlla questo Spazio di hysts . Devi duplicarlo e assegnare una GPU in modo che funzioni velocemente. Questo processo ti risparmierà la necessità di configurare il tuo ambiente di addestramento e sarai in grado di addestrare i tuoi modelli in pochi minuti!
Altri metodi
La ricerca di un facile fine-tuning non è nuova. Oltre a Dreambooth, l’inversione testuale è un altro metodo popolare che cerca di insegnare nuovi concetti a un modello di diffusione stabile addestrato. Uno dei principali motivi per utilizzare l’inversione testuale è che i pesi addestrati sono anche piccoli e facili da condividere. Tuttavia, funzionano solo per un singolo soggetto (o un piccolo gruppo di essi), mentre LoRA può essere utilizzato per il fine-tuning a uso generale, il che significa che può essere adattato a nuovi domini o dataset.
Pivotal Tuning è un metodo che cerca di combinare l’inversione testuale con LoRA. Prima, insegni al modello un nuovo concetto utilizzando tecniche di inversione testuale, ottenendo un nuovo embedding di token per rappresentarlo. Quindi, addestri quell’embedding di token utilizzando LoRA per ottenere il meglio dei due mondi.
Non abbiamo ancora esplorato il Pivotal Tuning con LoRA. Chi è pronto per la sfida? 🤗