Sfruttare il potere delle GPU con CuPy in Python
Utilizzare al meglio il potere delle GPU con CuPy in Python

Cos’è CuPy?
CuPy è una libreria Python compatibile con gli array NumPy e SciPy, progettata per il calcolo accelerato su GPU. Sostituendo la sintassi NumPy con quella di CuPy, è possibile eseguire il codice su piattaforme NVIDIA CUDA o AMD ROCm. Ciò consente di eseguire compiti legati agli array utilizzando l’accelerazione GPU, il che si traduce in un’elaborazione più rapida di array più grandi.
- La minaccia esistenziale non è l’IA, ma la mancanza di leggi sulla privacy dei dati.
- Rivoluzionare la diagnosi prenatale scopri come il sistema di apprendimento profondo PAICS migliora la rilevazione delle malformazioni intracraniche fetali dalle immagini neurosonografiche
- I ricercatori cinesi hanno introdotto un nuovo paradigma di compressione chiamato Retrieval-based Knowledge Transfer (RetriKT) una rivoluzione nella distribuzione di modelli di linguaggio pre-addestrati su larga scala nelle applicazioni del mondo reale.
Semplicemente sostituendo poche righe di codice, è possibile sfruttare la massiccia potenza di elaborazione parallela delle GPU per velocizzare notevolmente le operazioni sugli array come l’indicizzazione, la normalizzazione e la moltiplicazione di matrici.
CuPy consente anche l’accesso alle funzionalità CUDA a basso livello. Consente il passaggio di ndarray a programmi CUDA C/C++ esistenti mediante RawKernels, ottimizza le prestazioni con gli Stream e consente la chiamata diretta delle API del Runtime CUDA.
Installazione di CuPy
Puoi installare CuPy utilizzando pip, ma prima devi trovare la versione corretta di CUDA utilizzando il comando seguente.
!nvcc --version
nvcc: NVIDIA (R) Cuda compiler driverCopyright (c) 2005-2022 NVIDIA CorporationBuilt on Wed_Sep_21_10:33:58_PDT_2022Cuda compilation tools, release 11.8, V11.8.89Build cuda_11.8.r11.8/compiler.31833905_0
Sembra che la versione corrente di Google Colab utilizzi la versione CUDA 11.8. Pertanto, procederemo all’installazione della versione cupy-cuda11x.
Se stai utilizzando una versione più vecchia di CUDA, ho fornito una tabella di seguito per aiutarti a determinare il pacchetto CuPy appropriato da installare.
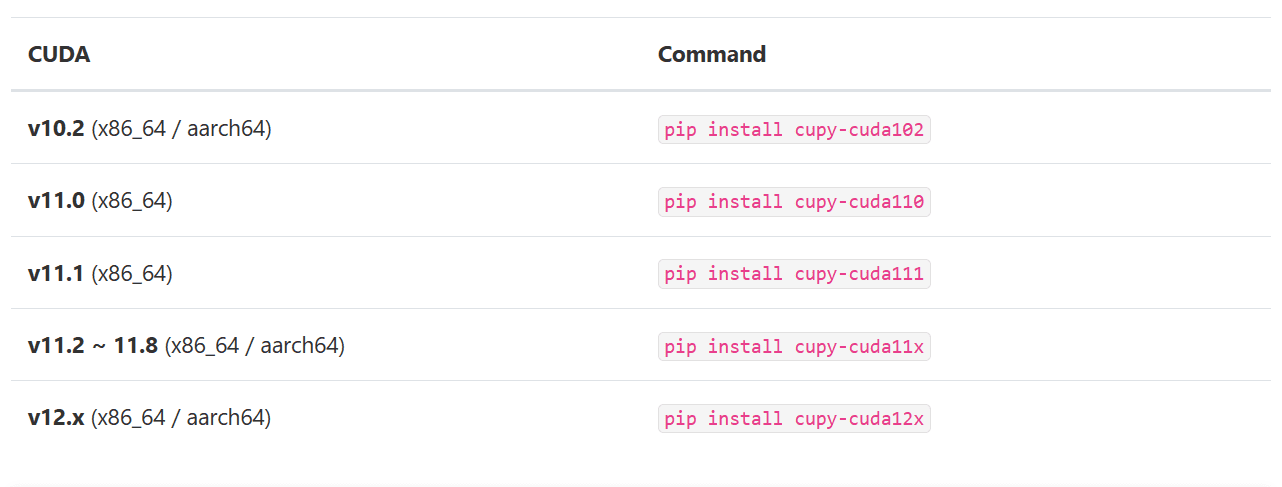
Dopo aver selezionato la versione corretta, installeremo il pacchetto Python utilizzando pip.
pip install cupy-cuda11x
Puoi anche utilizzare il comando conda per rilevare e installare automaticamente la versione corretta del pacchetto CuPy se hai installato Anaconda.
conda install -c conda-forge cupy
Fondamenti di CuPy
In questa sezione, confrontiamo la sintassi di CuPy con quella di NumPy e sono simili al 95%. Invece di utilizzare np, lo sostituiremo con cp.
Inizieremo creando un array NumPy e CuPy utilizzando la lista Python. Successivamente, calcoleremo la norma del vettore.
import cupy as cpimport numpy as npx = [3, 4, 5] x_np = np.array(x)x_cp = cp.array(x) l2_np = np.linalg.norm(x_np)l2_cp = cp.linalg.norm(x_cp) print("NumPy: ", l2_np)print("CuPy: ", l2_cp)
Come possiamo vedere, abbiamo ottenuto risultati simili.
NumPy: 7.0710678118654755CuPy: 7.0710678118654755
Per convertire un array NumPy in un array CuPy, puoi semplicemente utilizzare cp.asarray(X).
x_array = np.array([10, 22, 30])x_cp_array = cp.asarray(x_array)type(x_cp_array)
cupy.ndarray
Oppure, utilizza .get() per convertire un array CuPy in un array NumPy.
x_np_array = x_cp_array.get()type(x_np_array)
numpy.ndarray
Confronto delle prestazioni
In questa sezione, compareremo le prestazioni di NumPy e CuPy.
Utilizzeremo time.time() per misurare il tempo di esecuzione del codice. Successivamente, creeremo un array tridimensionale di NumPy e eseguiremo alcune funzioni matematiche.
import time# NumPy e_Runtime = time.time()x_cpu = np.ones((1000, 100, 1000))np_result = np.sqrt(np.sum(x_cpu**2, axis=-1))e = time.time()np_time = e - sprint("Tempo richiesto da NumPy: ", np_time)
Tempo richiesto da NumPy: 0.5474584102630615
Allo stesso modo, creeremo un array tridimensionale CuPy, eseguiremo operazioni matematiche e misureremo le prestazioni.
# CuPy e_Runtime = time.time()x_gpu = cp.ones((1000, 100, 1000))cp_result = cp.sqrt(cp.sum(x_gpu**2, axis=-1))e = time.time()cp_time = e - sprint("\nTempo richiesto da CuPy: ", cp_time)
Tempo richiesto da CuPy: 0.001028299331665039
Per calcolare la differenza, divideremo il tempo di NumPy per il tempo di CuPy e sembra che abbiamo ottenuto un incremento delle prestazioni di oltre 500 volte utilizzando CuPy.
diff = np_time/cp_timeprint(f'\nCuPy è {diff: .2f} volte più veloce di NumPy')
CuPy è 532.39 volte più veloce di NumPy
Nota: Per ottenere risultati migliori, è consigliabile eseguire alcune esecuzioni preliminari per ridurre al minimo le fluttuazioni temporali.
Oltre al vantaggio in termini di velocità, CuPy offre un supporto multi-GPU superiore, consentendo di sfruttare la potenza collettiva di più GPU.
Inoltre, puoi controllare il mio quaderno Colab, se desideri confrontare i risultati.
Conclusioni
In conclusione, CuPy offre un modo semplice per accelerare il codice NumPy sulle GPU NVIDIA. Sostituendo semplicemente NumPy con CuPy, è possibile ottenere velocizzazioni dell’ordine dei numeri decimali nelle operazioni sugli array. Questo incremento delle prestazioni consente di lavorare con set di dati e modelli molto più grandi, consentendo un’apprendimento automatico e una computazione scientifica più avanzati.
Risorse
- Documentazione: CuPy – NumPy & SciPy per GPU — Documentazione CuPy 12.2.0
- GitHub: cupy/cupy
- Esempi: cupy/examples
- API: Riferimento all’API
****[Abid Ali Awan](https://www.polywork.com/kingabzpro)**** (@1abidaliawan) è un professionista certificato in data science che ama creare modelli di apprendimento automatico. Attualmente, si concentra sulla creazione di contenuti e sulla stesura di blog tecnici su tecnologie di apprendimento automatico e data science. Abid è laureato in Tecnologia e gestione e possiede una laurea in Ingegneria delle telecomunicazioni. La sua visione è quella di costruire un prodotto AI utilizzando una rete neurale a grafo per gli studenti che lottano con disturbi mentali.





