Segmentazione universale dell’immagine con Mask2Former e OneFormer
'Universal image segmentation with Mask2Former and OneFormer'
Questa guida presenta Mask2Former e OneFormer, 2 reti neurali all’avanguardia per la segmentazione delle immagini. I modelli sono ora disponibili in 🤗 transformers, una libreria open source che offre implementazioni facili da usare di modelli all’avanguardia. Lungo il percorso, imparerai le differenze tra le varie forme di segmentazione delle immagini.
Segmentazione delle immagini
La segmentazione delle immagini è il compito di identificare diversi “segmenti” in un’immagine, come persone o automobili. Più tecnicamente, la segmentazione delle immagini è il compito di raggruppare pixel con diverse semantica. Consulta la pagina delle attività di Hugging Face per una breve introduzione.
La segmentazione delle immagini può essere suddivisa principalmente in 3 sotto-compiti: segmentazione di istanze, segmentazione semantica e segmentazione panottica, con numerosi metodi e architetture di modelli per eseguire ciascun sotto-compito.
- Segmentazione di istanze è il compito di identificare diverse “istanze”, come persone individuali, in un’immagine. La segmentazione di istanze è molto simile alla rilevazione di oggetti, tranne che desideriamo ottenere un insieme di maschere di segmentazione binarie, invece di bounding box, con le relative etichette di classe. Le istanze vengono spesso chiamate anche “oggetti” o “cose”. Nota che le istanze individuali possono sovrapporsi.
- Segmentazione semantica è il compito di identificare diverse “categorie semantiche”, come “persona” o “cielo”, di ogni pixel in un’immagine. A differenza della segmentazione di istanze, non viene fatta distinzione tra istanze individuali di una determinata categoria semantica; si desidera solo creare una maschera per la categoria “persona”, ad esempio, anziché per le persone individuali. Le categorie semantiche che non hanno istanze individuali, come “cielo” o “erba”, vengono spesso definite “stuff”, per fare la distinzione con le “things” (nomi fantastici, eh?). Nota che non è possibile sovrapporre categorie semantiche, poiché ogni pixel appartiene a una categoria.
- Segmentazione panottica, introdotta nel 2018 da Kirillov et al., mira a unificare la segmentazione di istanze e la segmentazione semantica, facendo sì che i modelli identifichino semplicemente un insieme di “segmenti”, ognuno con una maschera binaria e un’etichetta di classe corrispondente. I segmenti possono essere sia “things” che “stuff”. A differenza della segmentazione di istanze, non è possibile sovrapporre segmenti diversi.
La figura di seguito illustra la differenza tra i 3 sotto-compiti (tratta da questo post sul blog).
- Accelerazione dei trasformatori PyTorch con Intel Sapphire Rapids – parte 1
- AI per lo sviluppo di giochi Creazione di un gioco di agricoltura in 5 giorni. Parte 1
- Introduzione all’apprendimento automatico su grafi

Negli ultimi anni, i ricercatori hanno sviluppato diverse architetture che erano solitamente molto adatte alla segmentazione di istanze, semantiche o panottiche. La segmentazione di istanze e panottica venivano tipicamente risolte producendo un insieme di maschere binarie + etichette corrispondenti per ogni istanza dell’oggetto (molto simile alla rilevazione di oggetti, tranne che si produce una maschera binaria invece di una bounding box per istanza). Questo viene spesso chiamato “classificazione di maschere binarie”. La segmentazione semantica, d’altra parte, veniva tipicamente risolta facendo sì che i modelli producessero una singola “mappa di segmentazione” con un’etichetta per pixel. Pertanto, la segmentazione semantica veniva trattata come un problema di “classificazione per pixel”. I modelli popolari di segmentazione semantica che adottano questo paradigma sono SegFormer, su cui abbiamo scritto un ampio post sul blog, e UPerNet.
Segmentazione universale delle immagini
Fortunatamente, a partire dal 2020, le persone hanno iniziato a sviluppare modelli in grado di risolvere tutti e 3 i compiti (segmentazione di istanze, segmentazione semantica e segmentazione panottica) con un’architettura unificata, utilizzando lo stesso paradigma. Questo è iniziato con DETR, che è stato il primo modello a risolvere la segmentazione panottica utilizzando un paradigma di “classificazione di maschere binarie”, trattando le classi “things” e “stuff” in modo unificato. L’innovazione chiave è stata quella di avere un decodificatore Transformer che generasse un insieme di maschere binarie + classi in modo parallelo. Ciò è stato poi migliorato nel paper di MaskFormer, che ha mostrato che il paradigma di “classificazione di maschere binarie” funziona anche molto bene per la segmentazione semantica.
Mask2Former estende ciò alla segmentazione di istanze migliorando ulteriormente l’architettura della rete neurale. Pertanto, siamo passati da architetture separate a quello che i ricercatori ora definiscono architetture di “segmentazione universale delle immagini”, capaci di risolvere qualsiasi compito di segmentazione delle immagini. Interessantemente, questi modelli universali adottano tutti il paradigma di “classificazione di maschere”, eliminando completamente il paradigma di “classificazione per pixel”. Una figura che illustra l’architettura di Mask2Former è rappresentata di seguito (tratta dal paper originale).
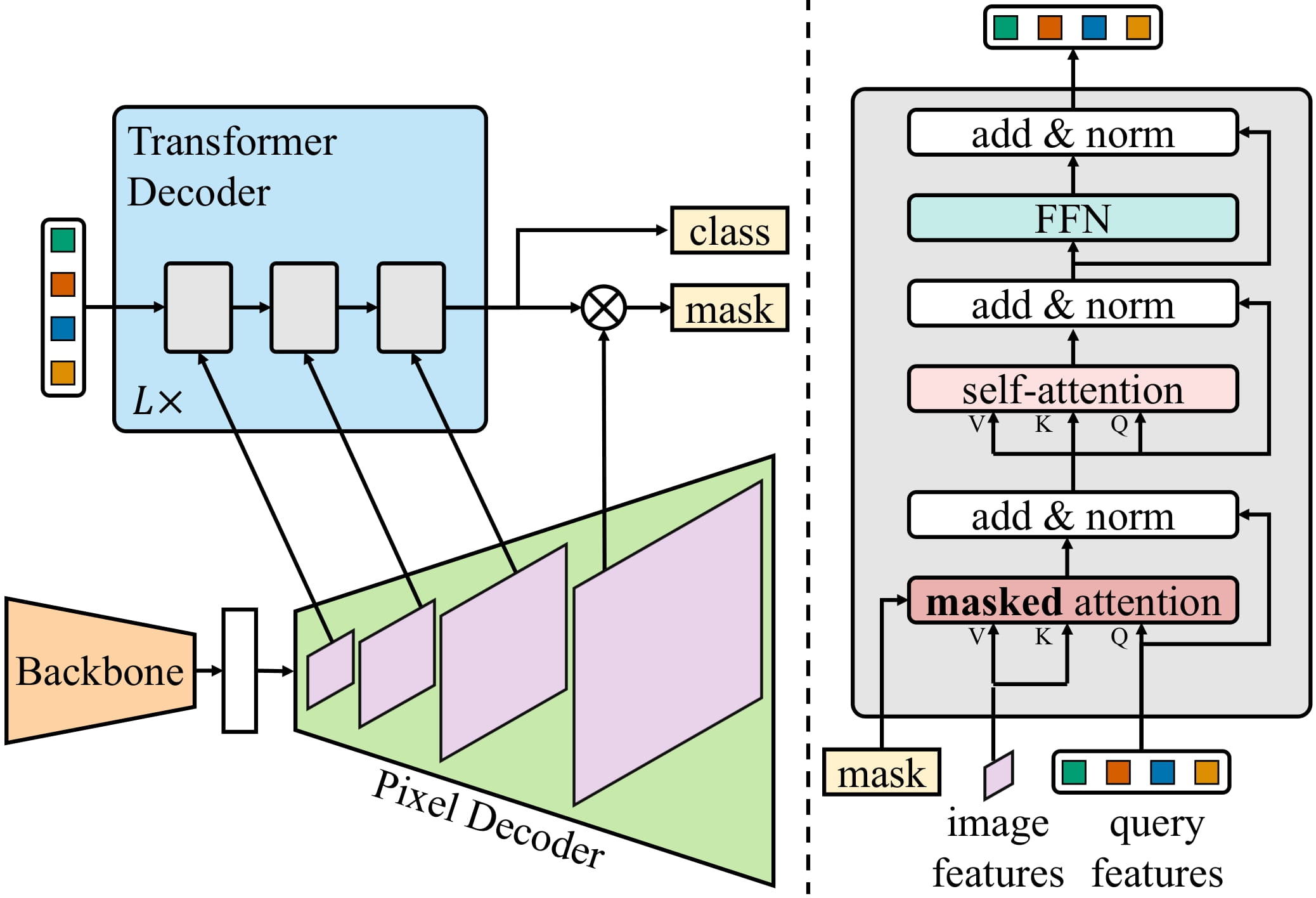
In breve, un’immagine viene prima inviata a un backbone (che, nel paper, potrebbe essere ResNet o Swin Transformer) per ottenere un elenco di mappe delle caratteristiche a bassa risoluzione. Successivamente, queste mappe delle caratteristiche vengono migliorate utilizzando un modulo decodificatore dei pixel per ottenere caratteristiche ad alta risoluzione. Infine, un decodificatore Transformer riceve un insieme di query e le trasforma in un insieme di maschere binarie e previsioni di classe, condizionate sulle caratteristiche del decodificatore dei pixel.
Si noti che Mask2Former deve ancora essere allenato separatamente su ogni singolo compito per ottenere risultati all’avanguardia. Questo è stato migliorato dal modello OneFormer, che ottiene prestazioni all’avanguardia su tutti e 3 i compiti allenandosi solo su una versione panottica del dataset (!), aggiungendo un codificatore di testo per condizionare il modello su input “istanza”, “semantico” o “panottico”. Questo modello è anche disponibile oggi in 🤗 transformers . È ancora più preciso di Mask2Former, ma ha una latenza maggiore a causa del codificatore di testo aggiuntivo. Vedere la figura sottostante per una panoramica di OneFormer. Sfrutta Swin Transformer o il nuovo modello DiNAT come supporto.

Inferenza con Mask2Former e OneFormer in Transformers
L’utilizzo di Mask2Former e OneFormer è piuttosto semplice e molto simile al loro predecessore MaskFormer. Istanziamo un modello Mask2Former dal repository hub allenato sul dataset panottico COCO, insieme al suo processore. Si noti che gli autori hanno rilasciato ben 30 checkpoint allenati su vari dataset.
from transformers import AutoImageProcessor, Mask2FormerForUniversalSegmentation
processor = AutoImageProcessor.from_pretrained("facebook/mask2former-swin-base-coco-panoptic")
model = Mask2FormerForUniversalSegmentation.from_pretrained("facebook/mask2former-swin-base-coco-panoptic")Successivamente, carichiamo l’immagine dei gatti familiare dal dataset COCO su cui effettueremo l’inferenza.
from PIL import Image
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image
Prepariamo l’immagine per il modello utilizzando il processore di immagini e la inoltriamo attraverso il modello.
inputs = processor(image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)Il modello restituisce un insieme di maschere binarie e corrispondenti logit di classe. I risultati grezzi di Mask2Former possono essere facilmente postelaborati utilizzando il processore di immagini per ottenere le previsioni finali di segmentazione istanza, semantica o panottica:
prediction = processor.post_process_panoptic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
print(prediction.keys())Nella segmentazione panottica, la previsione finale contiene 2 cose: una mappa di segmentazione di forma (altezza, larghezza) in cui ogni valore codifica l’ID dell’istanza di un dato pixel, così come un corrispondente segments_info. Il segments_info contiene ulteriori informazioni sui singoli segmenti della mappa (come il loro ID di classe/categoria). Si noti che Mask2Former restituisce proposte di maschere binarie di forma (96, 96) per efficienza e l’argomento target_sizes viene utilizzato per ridimensionare la maschera finale alla dimensione dell’immagine originale.
Visualizziamo i risultati:
from collections import defaultdict
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from matplotlib import cm
def draw_panoptic_segmentation(segmentation, segments_info):
# ottieni la mappa dei colori utilizzata
viridis = cm.get_cmap('viridis', torch.max(segmentation))
fig, ax = plt.subplots()
ax.imshow(segmentation)
instances_counter = defaultdict(int)
handles = []
# per ogni segmento, disegna la sua legenda
for segment in segments_info:
segment_id = segment['id']
segment_label_id = segment['label_id']
segment_label = model.config.id2label[segment_label_id]
label = f"{segment_label}-{instances_counter[segment_label_id]}"
instances_counter[segment_label_id] += 1
color = viridis(segment_id)
handles.append(mpatches.Patch(color=color, label=label))
ax.legend(handles=handles)
draw_panoptic_segmentation(**panoptic_segmentation)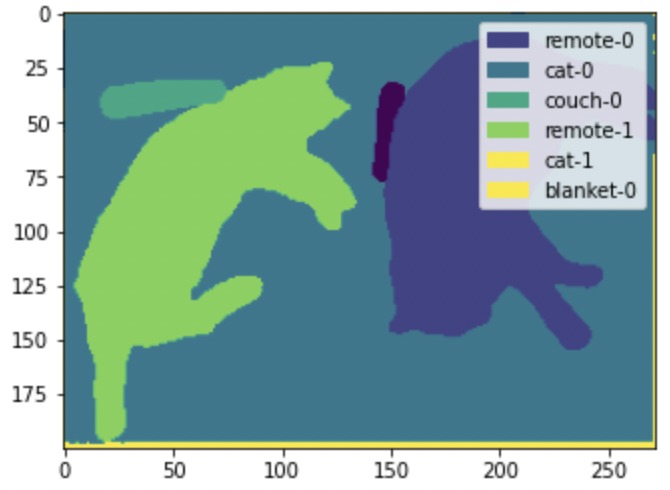
Qui possiamo vedere che il modello è in grado di rilevare i singoli gatti e telecomandi nell’immagine. La segmentazione semantica, d’altra parte, creerebbe semplicemente una singola maschera per la categoria “gatto”.
Per eseguire l’inferenza con OneFormer, che ha un’API identica tranne che per l’aggiunta di un prompt di testo aggiuntivo come input, si fa riferimento al notebook di demo.
Fine-tuning di Mask2Former e OneFormer in Transformers
Per il fine-tuning di Mask2Former/OneFormer su un dataset personalizzato per l’istanza, la segmentazione semantica e panottica, consulta i nostri notebook di demo. MaskFormer, Mask2Former e OneFormer condividono un’API simile, quindi l’aggiornamento da MaskFormer è facile e richiede poche modifiche.
I notebook di demo utilizzano MaskFormerForInstanceSegmentation per caricare il modello, mentre dovrai passare all’utilizzo di Mask2FormerForUniversalSegmentation o OneFormerForUniversalSegmentation. In caso di elaborazione delle immagini per Mask2Former, dovrai anche passare all’utilizzo di Mask2FormerImageProcessor. Puoi anche caricare l’elaboratore di immagini utilizzando la classe AutoImageProcessor, che si occupa automaticamente del caricamento dell’elaboratore corretto corrispondente al tuo modello. OneFormer, d’altra parte, richiede un OneFormerProcessor, che prepara le immagini, insieme a un input di testo, per il modello.
Ecco fatto! Ora conosci la differenza tra segmentazione per istanza, segmentazione semantica e segmentazione panottica, così come l’utilizzo di “architetture universali” come Mask2Former e OneFormer utilizzando la libreria 🤗 transformers.
Speriamo che tu abbia apprezzato questo post e che tu abbia imparato qualcosa. Non esitare a farci sapere se sei soddisfatto dei risultati ottenuti con il fine-tuning di Mask2Former o OneFormer.
Se ti è piaciuto questo argomento e vuoi saperne di più, ti consigliamo le seguenti risorse:
- I nostri notebook di demo per MaskFormer, Mask2Former e OneFormer, che offrono una panoramica più ampia sull’inferenza (inclusa la visualizzazione), così come il fine-tuning su dati personalizzati.
- Le [demo live] per Mask2Former e OneFormer disponibili su Hugging Face Hub, che puoi utilizzare per provare rapidamente i modelli su input di esempio a tua scelta.






