Comprendere la Policy Gradient costruendo Cross Entropy da zero
'Understand Policy Gradient by building Cross Entropy from scratch'
Una visione unificata di come addestrare i modelli
Il Reinforcement Learning (RL) può fare cose incredibili. Più recentemente, ChatGPT è stato ottimizzato sulla base del feedback umano con PPO, una variante di una classe di algoritmi di apprendimento di rinforzo chiamati Policy Gradient (PG). Capire l’RL, in particolare il policy gradient, potrebbe essere non banale, soprattutto se ti piace avere intuizioni come me. In questo post, camminerò attraverso un filo di pensieri che mi ha davvero aiutato a capire il PG partendo da un ambiente di apprendimento supervisionato più familiare.
TL;DR
- Inizieremo progettando una semplice procedura di formazione supervisionata di un robot di classificazione binaria premiandolo con +1 per le risposte corrette
- Formuleremo l’obiettivo della procedura
- Dedurremo la formulazione della discesa del gradiente per la procedura (che si rivelerà essere la stessa procedura della discesa del gradiente con Cross Entropy)
- Confronteremo la nostra procedura con le impostazioni di RL e relazioneremo la nostra discesa del gradiente al policy gradient
Chi dovrebbe leggere questo?
- Il mio obiettivo è fornire un aiuto amichevole e intuitivo per comprendere il PG. È utile se si ha una comprensione generale dell’ambiente di problema RL e si sa a grandi linee cosa sia il PG.
- Spero di aiutarti a comprendere meglio la relazione tra RL con PG e l’apprendimento supervisionato. Quindi è utile se sai come addestrare un algoritmo di apprendimento supervisionato con una funzione di perdita di Cross Entropy.
Perché questo post?
Policy Gradient
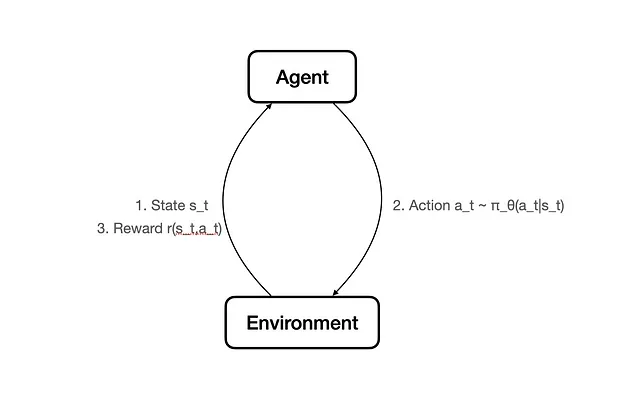
In un problema RL, un agente interagisce con un ambiente per apprendere una policy. La policy dice all’agente cosa fare in diversi stati per massimizzare la ricompensa.
L’idea del PG sembra semplice.
- La policy che guida il comportamento dell’agente al tempo t è π_θ(a_t|s_t).
- Questa è una sorta di funzione (spesso una rete neurale) con parametro θ.
- Prende in informazioni di stati s_t e restituisce una distribuzione di probabilità di azione da intraprendere a_t .
- Quindi riceve una ricompensa r(s_t, a_t).
- Quando abbiamo la storia di molti cicli di azione e ricompensa del genere, possiamo aggiornare il parametro θ per massimizzare la ricompensa attesa prodotta dalle azioni generate da π_θ.
Come lo aggiorniamo? Attraverso… gradienti! Aggiorniamo il modello che produce π_θ con il seguente gradiente
- Ricerca di similarità, Parte 1 kNN e Indice a File Invertito
- Svelare il Pattern di Progettazione delle Reti Neurali Informate dalla Fisica Parte 06
- Accelerare l’Acceleratore uno scienziato velocizza l’HPC del CERN con le GPU e l’AI
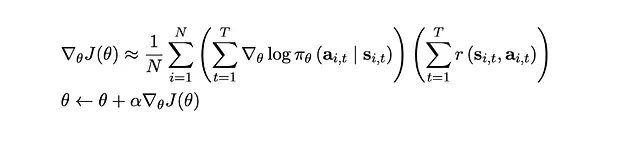
Qualcosa non va
Questo sembra molto familiare. Quando addestriamo un modello di rete neurale nell’apprendimento supervisionato, aggiorniamo anche i parametri del modello facendo l’operazione nella seconda riga, ovvero la discesa del gradiente (tecnicamente nel caso del PG, poiché stiamo massimizzando un obiettivo, è la risalita del gradiente).
Ma questo sembra anche molto diverso. Se guardi al suo processo di derivazione, puoi vedere che ci vuole un po’ di sforzo per derivare questa equazione. Questo è molto diverso dal modo più intuitivo in cui facciamo l’apprendimento supervisionato: alimentiamo un’input nella rete neurale, otteniamo un output, lo confrontiamo con il target e calcoliamo una funzione di perdita, premiamo il pulsante backprop e siamo fatti!
Inoltre, per me, il termine log sembra sempre uscire dal nulla. Anche se lo stesso corso online al link sopra ci guida su come arrivare al termine log, il processo sembra essere solo un po’ di matematica che è corretta ma che manca di motivazione.
Che differenza c’è esattamente rispetto all’apprendimento supervisionato? Scoprire la risposta a questa domanda fornisce un ottimo modo per capire il PG. Inoltre, è un buon promemoria per la natura di alcune cose familiari nell’apprendimento supervisionato che facciamo tutti i giorni.
Costruiamo la Cross Entropy da Zero
Se ci vengono presentate alcune funzioni di perdita utilizzate nell’apprendimento supervisionato, queste avrebbero un senso immediato. Ma è necessario fare uno sforzo maggiore per capire da dove provengono. Ad esempio, la vecchia funzione di perdita quadratica media ha intuitivamente senso: minimizza la distanza tra la previsione e l’obiettivo. Ma ci sono così tante metriche di distanza; perché la distanza quadratica? È necessario approfondire per capire che l’errore quadratico medio è il prodotto secondario di fare la massima verosimiglianza e di assumere che la distribuzione sottostante della popolazione sia normale.
Stessa cosa con un’altra buona vecchia funzione di perdita che usiamo tutti i giorni: Cross Entropy. Mentre ci sono molte buone interpretazioni di ciò che fa la Cross Entropy, proviamo a costruirla dal modo più rudimentale.
Alleniamo un Bot di Classificazione!
Immaginiamo di voler allenare un robot per classificare immagini di cani e gatti. È intuitivo addestrarlo premiando la risposta corretta e punendolo (o non premiandolo) per le risposte sbagliate. Ecco come si fa:
- Dai al robot un’immagine. Chiamiamola s. Questa immagine è campionata da una distribuzione di popolazione D_s
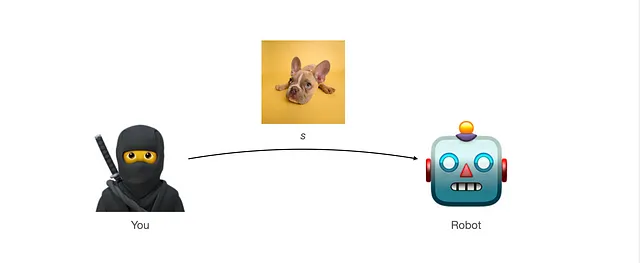
- Il robot ti darà una risposta se pensa che sia un’immagine di cane (azione a_dog) o se è un’immagine di gatto (azione a_cat).
- Il robot ha la sua previsione data l’immagine sulla probabilità dell’immagine di essere un cane o un gatto: π_θ(a|s) = (a_dog, a_cat). Ad esempio, π_θ(a|s) = (0,9, 0,1) significa che pensa che ci sia una probabilità del 0,9 che sia un cane e del 0,1 che sia un gatto.
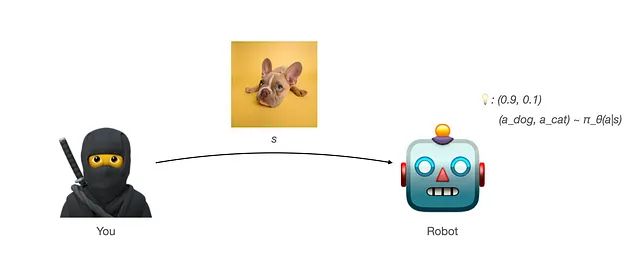
- Ma ogni volta che il robot ti darà una risposta, le risposte (azioni) saranno campionate casualmente dalla distribuzione prodotta da π_θ(a|s): a = (a_dog, a_cat) ~ π_θ(a|s).
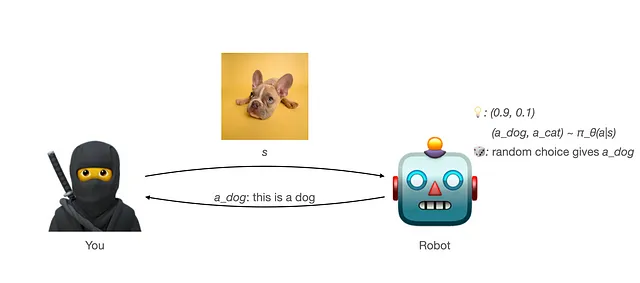
- Quindi premi il robot (forse dandogli una prelibatezza?) con una ricompensa di 1 quando risponde correttamente (r(s,a) = 1). Non c’è alcuna ricompensa (ricompensa 0) quando la risposta è errata (r(s,a) = 0).
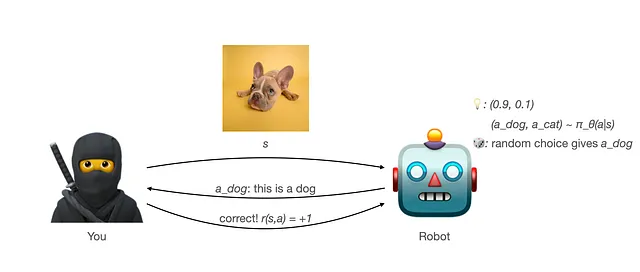
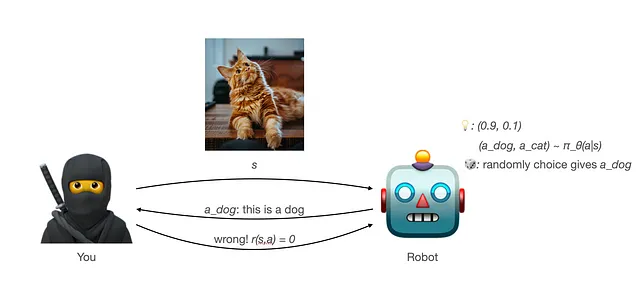
Questo processo è ciò che avevo in mente quando ho imparato per la prima volta il ML supervisionato. Ricompensare quando è corretto. Punirlo (o semplicemente non ricompensarlo in questo processo di formazione che abbiamo progettato) quando sbaglia. Probabilmente il modo più intuitivo per addestrare qualcosa.
Massimizzazione dell’obiettivo
Qual è il nostro obiettivo per il robot? Vogliamo che la sua risposta sia corretta il più spesso possibile. Più precisamente, vogliamo trovare il parametro ottimale θ* , che produce una π_θ(a|s), in modo che su tutte le possibili occorrenze di s (campionate dalla distribuzione di popolazione dell’immagine D_s ) e a (campionate dalla distribuzione data da s prodotta dal modello π_θ(a|s) ), otteniamo il massimo premio medio ponderato dalla probabilità di ogni occorrenza di (s,a) :
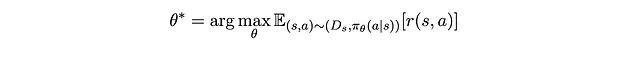
In altre parole, stiamo massimizzando la funzione obiettivo J(θ) definita come
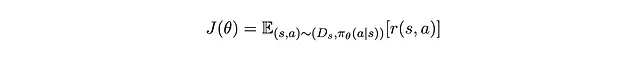
Gradiente dell’obiettivo
Ora che abbiamo una funzione obiettivo, potremmo provare a massimizzarla attraverso…ascesa del gradiente! In altre parole, possiamo ottimizzare la funzione iterativamente facendo
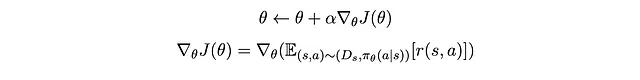
Ma come calcoliamo il gradiente, ovvero la derivata di J rispetto a θ ? È un po’ complicato in questo caso poiché
- La funzione di cui vogliamo calcolare la derivata è un’aspettativa.
- Se l’aspettativa non dipende da una distribuzione dipendente da θ, allora per la linearità dell’aspettativa, possiamo semplicemente prendere la derivata di ciò che si trova all’interno dell’aspettativa e lasciare l’aspettativa lì. Tuttavia, in questo caso, l’aspettativa riguarda (s,a) ~ (D_s, π_θ(a|s)), che dipende da θ . Quindi la derivata non è ovvia.
- Un altro modo di pensare a questo è che J ( θ ) cambia valore man mano che cambia la frequenza di campionamento di (s,a) da una distribuzione parzialmente determinata da θ . Vogliamo occorrenze più frequenti di s=immagine di cane e a=a_cane (coppia simile per gatto). Come possiamo catturare i cambiamenti di θ in questa direzione quando eseguiamo l’ascesa del gradiente?
Inoltre, idealmente, vogliamo che il gradiente sia nella forma
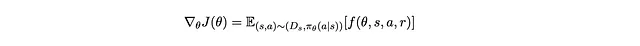
Questo perché si addestra il robot da campioni di interazioni tra robot e voi. Ogni campione consiste in una tripletta di (s,a,r) . Possiamo quindi approssimare questo gradiente prendendo la media di f(θ,s,a,r) con N campioni che raccogliamo (per il teorema del numero grande, ovvero facendo l’ascesa del gradiente stocastico):
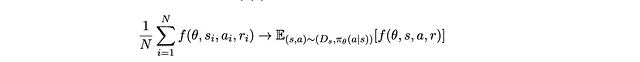
Possiamo quindi fare l’ascesa del gradiente facendo
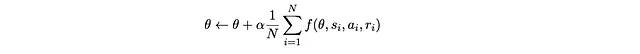
Ora troviamo f.
Trovare il gradiente
Per riassumere, vogliamo partire da (1) per ottenere (2) per una certa f(θ,s,a,r) .
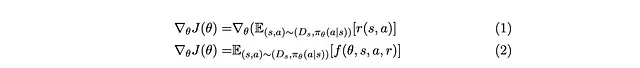
Cominciamo con il riscrivere (1) con la definizione di aspettativa :
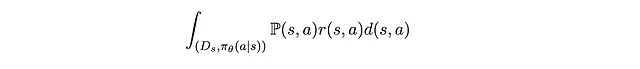
Questa è essenzialmente l’integrazione della ricompensa ponderata dalla probabilità su tutte le possibili coppie (s,a).
Ora, qual è esattamente la probabilità congiunta P(s,a) perché una coppia di (s,a) compaia? Possiamo decomporla nella probabilità che il campione di immagine (s) compaia e nella probabilità che il robot selezioni casualmente l’azione a.
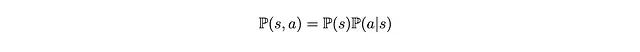
Dal momento che il robot seleziona casualmente l’azione a dal modello di previsione interno del robot π_θ(a|s), abbiamo
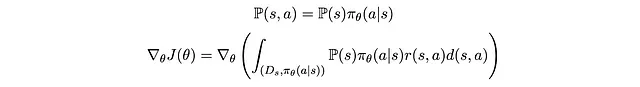
Di tutti i termini all’interno delle parentesi, solo π_θ(a|s) dipende da θ. Gli altri termini sono tutti costanti. Quindi possiamo spostare l’operazione di gradiente all’interno del segno integrale accanto a questo termine e ottenere
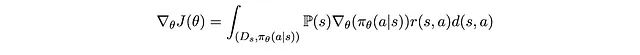
Si noti che possiamo anche scrivere quanto segue. Niente di importante qui. Basta moltiplicare il lato sinistro originale per 1 scritto come frazione e riordinare i termini.
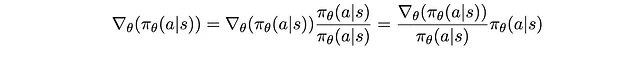
Rimpiazzandolo nuovamente e riordinando un po’, otteniamo
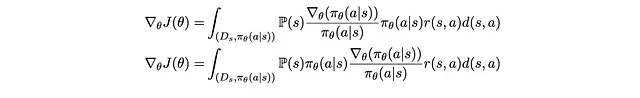
P(s)π_θ(a|s) sembra familiare. È P(s,a) che abbiamo decomposto in precedenza! Rimettendolo a posto, abbiamo
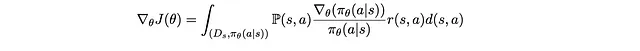
Ora che abbiamo un integrale e P(s,a), possiamo…rimetterlo nella definizione di aspettativa!
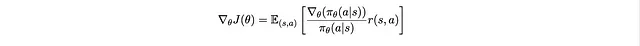
Che è esattamente la forma che vogliamo ottenere in (2), dove f sono i termini all’interno delle parentesi!
Vi sarete chiesti perché abbiamo riscritto il gradiente di π_θ(a|s) nella complicata frazione precedente? L’idea era quella di creare un termine π_θ(a|s) (che avevamo perso in precedenza prendendone la derivata), così potevamo produrre nuovamente un termine P(s,a), e trasformare l’integrazione nuovamente in una aspettativa!
Costruire l’entropia incrociata
Ora è il momento della magia.
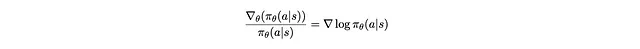
Non mi credete? Lavorate dal lato destro al lato sinistro con la regola della catena. (Pensieri laterali [opzionali]: Quindi se siete anche confusi sulla motivazione del termine log nella formula del gradiente di politica, è un prodotto collaterale della semplificazione di una complicata equazione che otteniamo, con l’intenzione di estrarre un termine π_θ(a|s) per trasformare le cose nuovamente in aspettativa.)
Quindi possiamo semplificare un po’ il gradiente di J(θ):
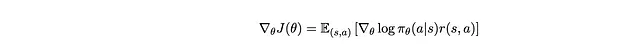
Quindi ogni volta che abbiamo un batch di (s,a) come campioni, possiamo fare una ascesa del gradiente con
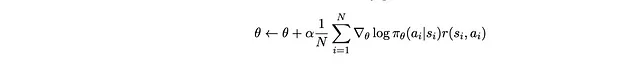
Per portarlo in una forma più familiare, spostiamo il segno del gradiente al di fuori della sommatoria:
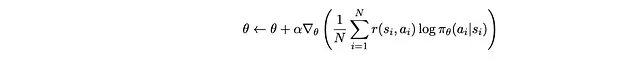
Invertiamo anche il segno con:
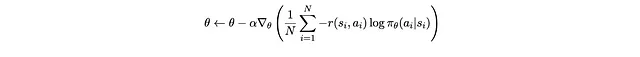
Ti suona familiare? Confrontiamolo con ciò che facciamo quando facciamo discesa del gradiente sulla perdita di entropia incrociata.
Ricorda che la perdita di entropia incrociata è:
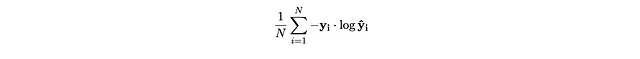
dove y_i è l’etichetta vera, un vettore one-hot (y_i_1, y_i_2) che descrive se un’immagine è di un gatto o di un cane (sia (0,1) sia (1,0)). y_hat_i è la previsione di un modello, un vettore (y_hat_i_1, y_hat_i_2) in cui le due voci sommano a uno.
Quando facciamo discesa del gradiente su questa funzione di perdita, calcoliamo la funzione di perdita di entropia incrociata per il batch e premiamo il pulsante backprop:
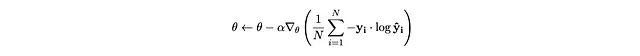
Le differenze tra questa espressione e l’espressione di aumento del gradiente che abbiamo derivato in precedenza sono:
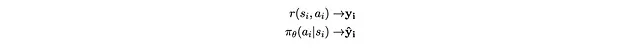
Per portare la relazione in parole, significa essenzialmente: sul campione x_i, y_i
- Il modello fa una previsione (y_hat_i_1, y_hat_i_2) data x_i
- Il modello preleva casualmente una risposta dalla distribuzione prevista
- Noi premiamo la risposta 1 con y_i_1 e la risposta 2 con y_i_2.
- Dato che quando l’etichetta è la classe 1, y_i_1 = 1, y_i_2 = 0, premiamo il modello con 1 quando risponde correttamente con 1 e non c’è premio quando risponde in modo errato con 0. Simile per la classe 2.
Ecco esattamente ciò che stiamo facendo!
Quindi, per riassumere,
- Abbiamo progettato un semplice ambiente di addestramento in cui premiamo il robot con 1 punto quando risponde correttamente e 0 quando risponde in modo errato
- Riassumiamo ciò che vogliamo raggiungere in una funzione obiettivo che descrive la ricompensa ottenuta dal robot ponderata dalle possibilità delle sue risposte
- Troviamo la procedura di discesa del gradiente per massimizzare questa funzione obiettivo
- E otteniamo… la procedura esatta che usiamo quando addestriamo un modello calcolando prima la perdita di entropia incrociata e backproping attraverso di essa!
Tornando all’apprendimento per rinforzo
Ora torniamo al focus sull’apprendimento per rinforzo. Quali sono le differenze tra l’apprendimento per rinforzo e l’ambiente di apprendimento supervisionato?
Più istanti temporali
La prima differenza è che l’apprendimento per rinforzo coinvolge di solito stati multipli e episodi multipli. Nel nostro ambiente, il robot inizia con l’input dell’immagine, ovvero lo stato s. Dopo che il robot ti restituisce una risposta basata sulla sua previsione e raccoglie la ricompensa, le interazioni tra il robot e te sono finite.
Al contrario, nei problemi di RL, gli agenti interagiscono spesso con l’ambiente in episodi multipli, e potrebbe passare ad altri stati dopo lo stato iniziale.
La funzione obiettivo diventa quindi
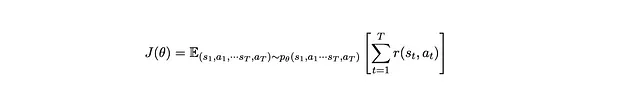
Per spiegarlo in parole semplici, massimizziamo la somma media delle ricompense di tutti gli step su tutte le possibili sequenze (traiettorie) di stati e azioni, ponderate dalla probabilità di ogni traiettoria che si verifica quando le azioni sono decise dal parametro θ.
È importante notare che p_θ è la distribuzione congiunta di una sequenza di stati e azioni quando le azioni sono decise dal parametro del modello dell’agente, θ. Ad ogni passo, l’azione dell’agente è decisa da π_θ(a_t|s_t), dove π_θ è un parametro del modello parametrizzato da θ. p_θ è un astrazione di alto livello di quanto sia probabile che una sequenza di stati e azioni si verifichi quando l’agente prende decisioni basate su π_θ (cioè, p_θ è un segnaposto per teoricamente quante volte l’agente assume la traiettoria. D’altra parte, π_θ(a|s) è la probabilità che l’agente prenda un’azione in un determinato passaggio. Non conosciamo effettivamente il valore p_θ, quindi in seguito lo riscriveremo con l’output del modello π_θ(a|s) che conosciamo effettivamente).
Confrontiamolo con l’obiettivo che abbiamo avuto in precedenza:
Le principali differenze sono
- Calcoliamo l’aspettativa su una sequenza di s e a invece di solo una coppia.
- Massimizziamo la somma delle ricompense di tutti gli step nella traiettoria invece che solo la ricompensa di un solo passaggio dall’immagine e dalla risposta.
Confronto della Formula del Gradiente
Possiamo fare manipolazioni simili a questo obiettivo per derivare il gradiente che possiamo usare per aggiornare θ ad ogni passaggio.
Per riassumere, il nostro obiettivo è trovare il gradiente di J(θ) nella seguente forma per qualche f
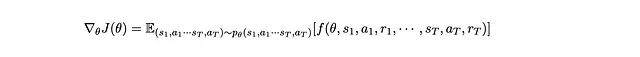
Quando otteniamo un batch di sequenze campionate di s_1, a_1, r_1,… s_T, a_T, r_T, possiamo quindi aggiornare θ tramite Stochastic Gradient Ascent:
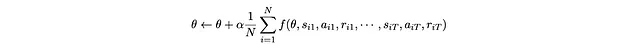
Per semplificare le cose, indichiamo la sequenza di stato e con una sola variabile τ.
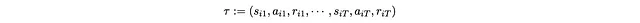
Quindi speriamo di massimizzare la seguente funzione obiettivo
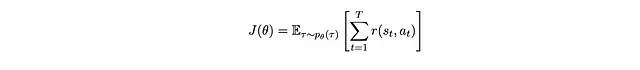
Possiamo fare manipolazioni simili a quelle fatte:
- Scrivere l’aspettativa in termini di integrazione
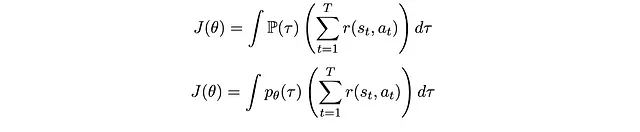
- Prendere la derivata rispetto a θ sull’unico termine che coinvolge θ: p_θ(τ)
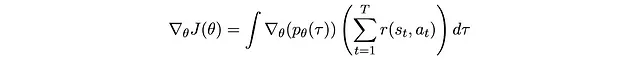
- Riscrivere il gradiente di p_θ(τ) come prodotto di p_θ(τ) e qualcos’altro per recuperare la forma che definisce un’aspettativa
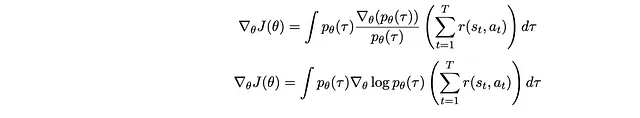
Quindi otteniamo
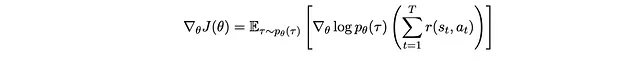
Ecco! È esattamente ciò che vogliamo trovare. In parole povere, significa che stiamo aggiornando θ alla direzione del gradiente della log-probabilità dei campioni τ sotto le azioni determinate da θ, pesato dalla ricompensa totale lungo τ campionato. Questa è esattamente la formulazione di Policy Gradients.
Se estendiamo l’analogia dell’entropia incrociata da prima, la somma delle ricompense è fondamentalmente l’etichetta per la traiettoria, e p_θ(τ) è quanto è probabile che τ accada sotto la previsione del modello. Il processo di addestramento incoraggia il modello a prevedere distribuzioni simili alla distribuzione delle ricompense su diverse traiettorie τ. (Questa è in realtà una dichiarazione matematicamente accurata [correggetemi se sbaglio]. Se conoscete la divergenza KL, confrontate ciò che viene preso il gradiente con la divergenza KL).
Possiamo fare ulteriori manipolazioni con le probabilità condizionate e la definizione di p_θ(τ). Questo processo è ben spiegato in questo video (intorno al 9:27). Otteniamo infine il seguente, che riscrive p_θ(τ) come π_θ(a_t|s_t) di cui conosciamo effettivamente il valore:
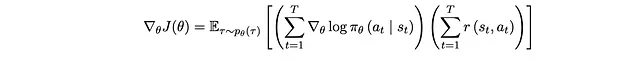
Nota che quando T = 1 (singolo episodio), questo è lo stesso gradiente che abbiamo ottenuto nel nostro ambiente precedente. In altre parole, ML supervisionato è un caso particolare di RL in cui c’è solo un episodio, e la ricompensa non è stocastica (vedere la sezione successiva).
Un’altra differenza: stimare le ricompense
Un’altra differenza tra RL e ML supervisionato è quanto possiamo fidarci delle ricompense. Nel ML supervisionato, la ricompensa è l’etichetta di verità fondamentale che viene fornita con i campioni di immagini. Siamo solitamente sicuri al 100% che le ricompense siano corrette e il nostro robot adatterà i suoi comportamenti verso quelle etichette.
Tuttavia, nei problemi di RL, le ricompense potrebbero essere più stocastiche (immaginate quando giocate a un gioco, potreste essere nello stesso posto due volte ma ottenere punteggi diversi). Quindi dobbiamo stimare la ricompensa per una particolare coppia stato-azione con la ricompensa storica mentre interagiamo con l’ambiente.
[Opzionale] Pensieri laterali: stavo anche pensando se c’è un territorio intermedio tra ML supervisionato (dove le etichette/ricompense sono affidabili al 100%) e RL (dove le ricompense sono più stocastiche). Sembra che quando le etichette sono rumorose (contengono alcune etichette sbagliate), siamo un po’ a metà strada? Quindi il metodo di pseudo-etichettatura condividerebbe qualche sapore come problema RL? Fatemi sapere i vostri pensieri.
Tecnicamente, a lungo termine, dovremmo avere abbastanza ricompense storiche per comprendere il comportamento medio delle ricompense, ma a breve termine, un numero ridotto di campioni potrebbe produrre stime instabili e sbagliate su di esse.
Più male, poiché il comportamento dell’agente viene aggiornato dalla ricompensa raccolta, se raccogliamo ricompense di bassa qualità, potremmo finire in una politica sbagliata e restare bloccati lì a lungo. E ci vorrà molto tempo per uscirne e tornare sulla giusta strada.
Questa è una delle sfide in RL che è ancora un’area di ricerca in corso. Manipolazioni delle ricompense e varianti del gradiente di politica come TRPO e PPO sono progettati per affrontare meglio questo problema e sono diventati più comunemente usati rispetto a PG standard.
[Opzionale] Un altro pensiero laterale: confronto con ML supervisionato sequenziale
Una differenza tra la nostra impostazione di ML supervisionato e RL è che RL spesso coinvolge più intervalli di tempo. Ho subito avuto la domanda: quindi come differisce RL dall’addestramento di un modello sequenziale come Transformer o LSTM?
La risposta a questa domanda dipende sicuramente dal design esatto della funzione di perdita dell’addestramento del vostro modello sequenziale preferito.
Per ora, diciamo che addestrate un modello di sequenza f( x_1,x_2,…x_T ) per prevedere y_1, y_2…y_T Ad esempio, in un compito di traduzione automatica, gli x potrebbero essere le parole della frase in inglese di input e gli y sono le parole della frase in francese in uscita (ciascuna di x_t, y_t è una rappresentazione del vettore one-hot della parola).
Calcoliamo la funzione di perdita su ogni campione prendendo la somma dell’entropia incrociata tra ogni previsione di output di parola e l’etichetta corretta. Poi facciamo la media su un batch di campioni e facciamo backprop come segue:
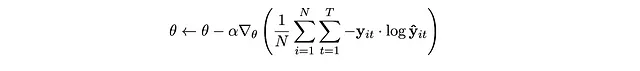
Mettendo di nuovo nella formulazione della Policy Gradient, questo per me è lo stesso che calcolare il gradiente della funzione obiettivo come:
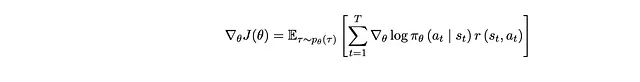
La differenza tra questa formulazione e quella della PG è che non stiamo moltiplicando la somma della probabilità logaritmica di tutte le previsioni del timestep con la somma delle ricompense di tutti i passaggi. Invece, prendiamo il prodotto a coppie della probabilità logaritmica e della ricompensa di ogni timestep e le sommiamo.
Ciò rimuove molti termini riducendo notevolmente la varianza dei gradienti, il che potrebbe rendere più facile addestrare un Transformer/LSTM in un ambiente supervisionato rispetto a un algoritmo di RL? (oltre alle ricompense non stocastiche in un ambiente supervisionato).
In questo video viene presentata una tecnica per ridurre la varianza della PG: cambiare la somma della ricompensa di tutti i timestep nella PG con le ricompense future (cioè la somma da t’ = t a t’ = T). Questo ha un sapore simile a quello che differisce tra PG e l’addestramento di un Transformer/LSTM in un ambiente supervisionato. Mentre il metodo delle ricompense future fa sì che l’agente valuti ogni stato in base alle possibili ricompense future, potremmo dire che l’addestramento sequenziale supervisionato fa sì che il modello si concentri solo sulla correttezza del timestep corrente?
Inoltre, ho provato a lavorare all’indietro da questa espressione del gradiente e trovare l’originale J(θ) che produce questa espressione del gradiente, in modo da poter interpretare più direttamente l’obiettivo dell’addestramento sequenziale supervisionato. Ma sono rimasto bloccato a metà. Fatemi sapere se avete qualche pensiero in merito.
Riconoscimenti
La connessione tra la policy gradient e l’entropia incrociata non è una mia idea originale. Grazie a questo post per avermi dato spunti per espanderla per comprendere più fondamentalmente cosa stiano facendo entropia incrociata e policy gradient.