Ricerca di similarità, Parte 2 Quantizzazione di prodotto
Similarity Search, Part 2 Product Quantization
Impara una potente tecnica per comprimere in modo efficiente grandi dati
La ricerca di similarità è un problema dove, dato un query, l’obiettivo è trovare i documenti più simili ad esso tra tutti i documenti del database.
Introduzione
Nella scienza dei dati, la ricerca di similarità appare spesso nel dominio di NLP, motori di ricerca o sistemi di raccomandazione dove i documenti o gli elementi più pertinenti devono essere recuperati per una query. Esiste una grande varietà di modi diversi per migliorare le prestazioni di ricerca in grandi volumi di dati.
Nella prima parte di questa serie di articoli, abbiamo esaminato kNN e la struttura dell’indice di file invertito per effettuare la ricerca di similarità. Come abbiamo appreso, kNN è l’approccio più semplice mentre l’indice di file invertito agisce al suo interno suggerendo un compromesso tra l’accelerazione della velocità e l’accuratezza. Tuttavia, entrambi i metodi non utilizzano tecniche di compressione dei dati che potrebbero portare a problemi di memoria, soprattutto in caso di grandi dataset e RAM limitata. In questo articolo, cercheremo di affrontare questo problema guardando ad un altro metodo chiamato Quantizzazione di prodotto.
- Rimozione e distillazione architetturale un percorso verso una compressione efficiente nei modelli di diffusione testo-immagine dell’IA.
- Forged in Flames Startup combina l’IA generativa e la computer vision per combattere gli incendi forestali.
- Google AI presenta Imagen Editor e EditBench per migliorare e valutare l’inpainting di immagini guidate da testo.
Ricerca di similarità, Parte 1: kNN & Indice di file invertito
La ricerca di similarità è un problema dove, dato un query Q, l’obiettivo è trovare i documenti più simili ad esso tra tutti…
towardsdatascience.com
Definizione
La quantizzazione di prodotto è il processo in cui ogni vettore del dataset viene convertito in una rappresentazione breve ed efficiente in termini di memoria (chiamata codice PQ). Invece di conservare completamente tutti i vettori, vengono memorizzate le loro rappresentazioni brevi. Allo stesso tempo, la quantizzazione di prodotto è un metodo di compressione con perdita che porta a una minore accuratezza di previsione ma, in pratica, questo algoritmo funziona molto bene.
In generale, la quantizzazione è il processo di mappare i valori infiniti in quelli discreti.
Formazione
In primo luogo, l’algoritmo divide ogni vettore in diverse parti uguali — subvettori. Ciascuna delle parti rispettive di tutti i vettori del dataset forma spazi indipendenti e viene elaborata separatamente. Quindi, viene eseguito un algoritmo di clustering per ogni sottospazio di vettori. In questo modo, vengono creati diversi centroidi in ciascun sottospazio. Ciascun subvettore viene codificato con l’ID del centroide a cui appartiene. Inoltre, le coordinate di tutti i centroidi vengono memorizzate per un uso successivo.
I centroidi del sottospazio sono anche chiamati vettori quantizzati.
Nella quantizzazione di prodotto, un ID di cluster è spesso indicato come un valore di riproduzione.
Nota. Nelle figure sottostanti, un rettangolo rappresenta un vettore contenente diversi valori mentre un quadrato indica un singolo numero.
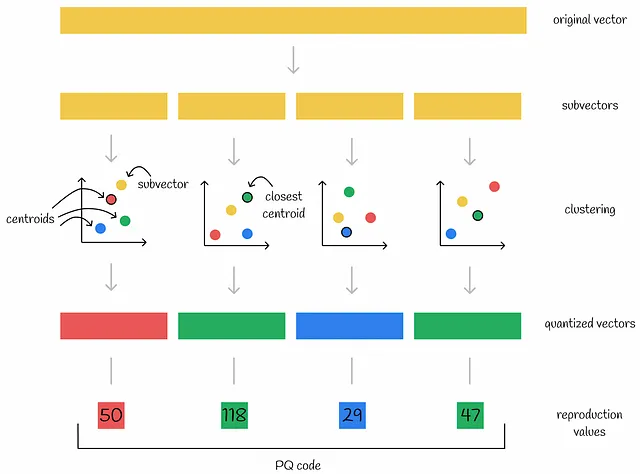
Come risultato, se un vettore originale è diviso in n parti, può essere codificato da n numeri — ID dei centroidi rispettivi per ciascuno dei suoi subvettori. Tipicamente, il numero di centroidi creati k viene scelto di solito come potenza di 2 per un uso più efficiente della memoria. In questo modo, la memoria richiesta per memorizzare un vettore codificato è di n * log(k) bit.
La raccolta di tutti i centroidi all’interno di un sottospazio è chiamata catabook. L’esecuzione di n algoritmi di clustering per tutti i sottospazi produce n codebook separati.
Esempio di compressione
Immagina un vettore originale di dimensioni 1024 che memorizza float (32 bit) è stato diviso in n = 8 subvettori in cui ciascun subvettore è codificato da uno dei k = 256 cluster. Pertanto, la codifica dell’ID di un singolo cluster richiederebbe log(256) = 8 bit. Confrontiamo le dimensioni di memoria per la rappresentazione del vettore in entrambi i casi:
- Vettore originale: 1024 * 32 bit = 4096 byte.
- Vettore codificato: 8 * 8 bit = 8 byte.
La compressione finale è di ben 512 volte! Questo è il vero potere della quantizzazione di prodotto.

Ecco alcune note importanti:
- L’algoritmo può essere addestrato su un sottoinsieme di vettori (ad esempio, per creare cluster) e utilizzato su un altro: una volta che l’algoritmo è stato addestrato, viene passato un altro dataset di vettori in cui i nuovi vettori vengono codificati utilizzando i centroidi già costruiti per ogni sottospazio.
- In genere, viene scelto k-means come algoritmo di clustering. Uno dei suoi vantaggi è che il numero di cluster k è un iperparametro che può essere definito manualmente, secondo i requisiti di utilizzo della memoria.
Inferenza
Per avere una migliore comprensione, vediamo prima alcune approcci ingenui e scopriamo i loro svantaggi. Ciò ci aiuterà anche a capire perché non dovrebbero essere normalmente usati.
Approcci ingenui
Il primo approccio ingenuo consiste nella decompressione di tutti i vettori concatenando i centroidi corrispondenti di ciascun vettore. Dopo di che, la distanza L2 (o un’altra metrica) può essere calcolata da un vettore di query a tutti i vettori del dataset. Ovviamente, questo metodo funziona, ma è molto dispendioso in termini di tempo perché viene eseguita una ricerca a forza bruta e il calcolo della distanza viene effettuato su vettori decompressi ad alta dimensionalità.
Un’altra possibile soluzione è quella di dividere un vettore di query in sottovettori e calcolare una somma di distanze da ciascun sottovettore di query ai rispettivi vettori quantizzati di un vettore del database, in base al suo codice PQ. Di conseguenza, viene utilizzata nuovamente la tecnica di ricerca a forza bruta e il calcolo della distanza richiede ancora un tempo lineare della dimensionalità dei vettori originali, come nel caso precedente.
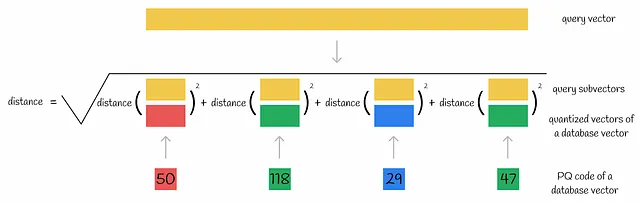
Un altro possibile metodo consiste nell’codificare il vettore di query in un codice PQ. Poi, questo codice PQ viene utilizzato direttamente per calcolare le distanze a tutti gli altri codici PQ. Il vettore del dataset con il corrispondente codice PQ che ha la distanza più breve viene quindi considerato come il vicino più vicino alla query. Questo approccio è più veloce dei primi due perché la distanza viene sempre calcolata tra codici PQ a bassa dimensionalità. Tuttavia, i codici PQ sono composti da ID di cluster che non hanno molto significato semantico e possono essere considerati come una variabile categorica esplicitamente utilizzata come una variabile reale. Chiaramente, questa è una pratica sbagliata e questo metodo può portare a una scarsa qualità della predizione.
Approccio ottimizzato
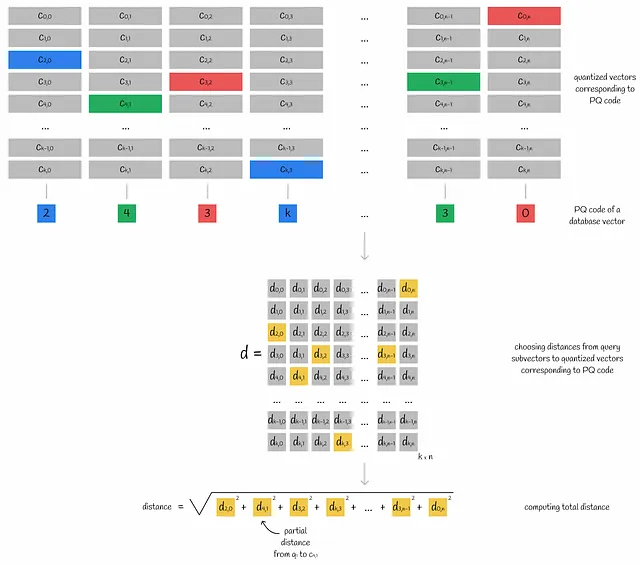
Un vettore di query è diviso in sottovettori. Per ciascuno dei suoi sottovettori, vengono calcolate le distanze a tutti i centroidi dello spazio corrispondente. Alla fine, queste informazioni vengono memorizzate nella tabella d .
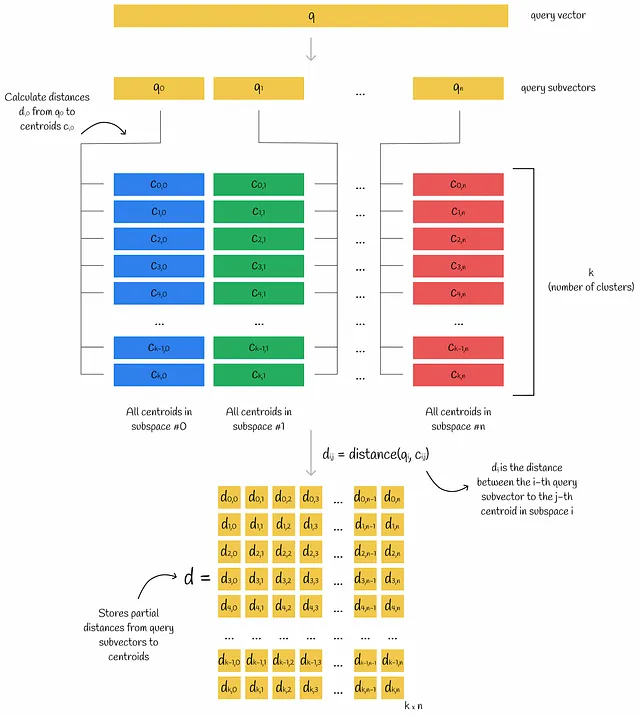
Le distanze parziali calcolate tra sottovettori e centroidi sono spesso indicate come distanze parziali.
Utilizzando questa tabella di distanze tra sottovettore e centroide d , la distanza approssimativa dalla query a qualsiasi vettore del database può essere facilmente ottenuta dai suoi codici PQ:
- Per ciascuno dei sottovettori di un vettore del database, viene trovato il centroide più vicino j (utilizzando i valori di mappatura dai codici PQ) e viene presa la distanza parziale d[i][j] da quel centroide al sottovettore di query i (utilizzando la matrice calcolata d ).
- Tutte le distanze parziali vengono elevate al quadrato e sommate. Prendendo la radice quadrata di questo valore, si ottiene la distanza euclidea approssimativa. Se si vuole sapere come ottenere risultati approssimati per altre metriche, passare alla sezione “Approssimazione di altre metriche di distanza”.
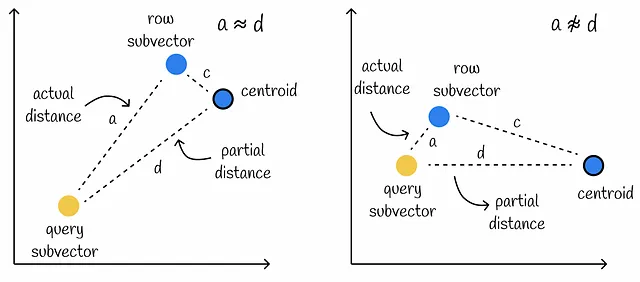
Utilizzare questo metodo per il calcolo delle distanze approssimate presuppone che le distanze parziali d siano molto vicine alle distanze effettive a tra la query e i sottovettori del database.
Tuttavia, questa condizione potrebbe non essere soddisfatta, specialmente quando la distanza c tra il sottovettore del database e il suo centroide è grande. In tali casi, i calcoli producono una minore precisione.
Dopo aver ottenuto le distanze approssimate per tutte le righe del database, cerchiamo i vettori con i valori più piccoli. Quei vettori saranno i vicini più vicini alla query.
Approssimazione di altri metriche di distanza
Fino ad ora abbiamo visto come approssimare la distanza euclidea utilizzando le distanze parziali. Generalizziamo la regola anche per altre metriche.
Immaginiamo di voler calcolare una metrica di distanza tra una coppia di vettori. Se conosciamo la formula della metrica, possiamo applicarla direttamente per ottenere il risultato. Ma a volte possiamo farlo per parti nel seguente modo:
- Entrambi i vettori sono divisi in n sottovettori.
- Per ogni coppia di sottovettori rispettivi, viene calcolata la metrica di distanza.
- Le n metriche calcolate vengono quindi combinate per produrre la distanza effettiva tra i vettori originali.
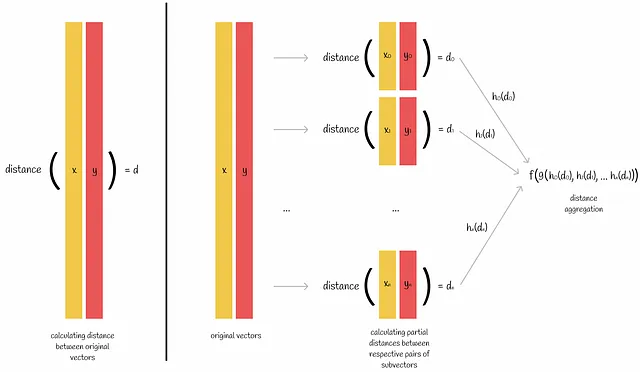
La distanza euclidea è un esempio di metrica che può essere calcolata per parti. Basandoci sulla figura sopra, possiamo scegliere le funzioni di aggregazione per essere h(z) = z² , g(z₀, z₁, …, zₙ) = sum(z₀, z₁, …, zₙ) e f(z) = √z .

Il prodotto interno è un altro esempio di tale metrica con le funzioni di aggregazione h(z) = z, g(z₀, z₁, …, zₙ) = sum(z₀, z₁, …, zₙ) e f(z) = z .
Nel contesto della quantizzazione del prodotto, questa è una proprietà molto importante perché durante l’inferezza l’algoritmo calcola le distanze per parti. Ciò significa che sarebbe molto più problematico utilizzare metriche per la quantizzazione del prodotto che non hanno questa proprietà. La distanza coseno è un esempio di tale metrica.
Se c’è ancora la necessità di utilizzare una metrica senza questa proprietà, allora sono necessarie euristici aggiuntivi per aggregare le distanze parziali con qualche errore.
Prestazioni
Il principale vantaggio della quantizzazione del prodotto è una massiccia compressione dei vettori del database che vengono archiviati come codici PQ brevi. Per alcune applicazioni, tale tasso di compressione può essere addirittura superiore al 95%! Tuttavia, oltre ai codici PQ, deve essere archiviata la matrice d di dimensioni k x n che contiene i vettori quantizzati di ogni sottospazio.
La quantizzazione del prodotto è un metodo di compressione con perdita, quindi maggiore è la compressione, maggiore è la probabilità che la precisione delle previsioni diminuisca.
La creazione di un sistema per una rappresentazione efficiente richiede la formazione di diversi algoritmi di clustering. Oltre a questo, durante l’infusione, k * n distanze parziali devono essere calcolate in modo brutale e sommate per ciascuno dei vettori del database, il che può richiedere del tempo.

Implementazione di Faiss
Faiss (Facebook AI Search Similarity) è una libreria Python scritta in C++ usata per la ricerca ottimizzata di similarità. Questa libreria presenta diversi tipi di indici che sono strutture dati utilizzate per memorizzare ed eseguire query in modo efficiente.
In base alle informazioni della documentazione di Faiss, vedremo come viene utilizzata la quantizzazione del prodotto.
La quantizzazione del prodotto è implementata nella classe IndexPQ. Per l’inizializzazione, dobbiamo fornire 3 parametri:
- d : numero di dimensioni nei dati.
- M : numero di suddivisioni per ogni vettore (lo stesso parametro n utilizzato sopra).
- nbits : numero di bit necessari per codificare un singolo ID di cluster. Ciò significa che il numero totale di cluster in un singolo sottospazio sarà pari a k = 2^nbits .
Per la suddivisione di dimensioni di sottospazio uguali, il parametro dim deve essere divisibile per M.
Il numero totale di byte richiesti per memorizzare un singolo vettore è pari a:
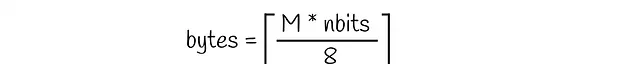
Come possiamo vedere dalla formula sopra, per un uso più efficiente della memoria il valore di M * nbits dovrebbe essere divisibile per 8.

Conclusione
Abbiamo esaminato un algoritmo molto popolare nei sistemi di recupero delle informazioni che comprime efficientemente grandi volumi di dati. Il suo principale svantaggio è una lenta velocità di inferenza. Nonostante questo fatto, l’algoritmo è ampiamente utilizzato nelle moderne applicazioni Big Data, specialmente in combinazione con altre tecniche di ricerca di similarità.
Nella prima parte della serie di articoli, abbiamo descritto il flusso di lavoro dell’indice del file invertito. In effetti, possiamo unire questi due algoritmi in uno più efficiente che avrà i vantaggi di entrambi! Questo è esattamente ciò che faremo nella prossima parte di questa serie.
Ricerca di similarità, Parte 3: Fusione dell’indice del file invertito e della quantizzazione del prodotto
Nelle prime due parti di questa serie abbiamo discusso due algoritmi fondamentali nel recupero delle informazioni: invertiti…
Nisoo.com
Risorse
- Quantizzazione del prodotto per la ricerca del vicino più vicino
- Documentazione di Faiss
- Repository di Faiss
- Riepilogo degli indici di Faiss
Tutte le immagini, a meno che non sia diversamente indicato, sono dell’autore.






