Decodifica dell’Audizione del Senato degli Stati Uniti sulla Supervisione dell’IA Analisi NLP in Python.
Senate Hearing on AI Supervision NLP Analysis Decoded in Python.
Analisi della frequenza dei termini, visualizzazione e punteggi di sentimento utilizzando il toolkit NLTK
La scorsa domenica mattina, mentre cambiavo canale cercando qualcosa da guardare mentre facevo colazione, mi sono imbattuto in una replica dell’audizione del Senato sulla supervisione dell’AI. Era passato solo un’ora da quando era iniziata, così ho deciso di guardarla fino alla fine (che modo interessante di trascorrere una domenica mattina!).
Quando eventi come l’audizione del Sottocomitato Giudiziario del Senato sulla supervisione dell’AI hanno luogo e si vuole conoscere i punti salienti, si hanno quattro opzioni: assistere in diretta, cercare registrazioni future (entrambe le opzioni richiederebbero tre ore della tua vita); leggere la versione scritta (trascrizioni), che sono di circa 79 pagine e oltre 29.000 parole; o leggere le recensioni su siti web o social media per avere opinioni diverse e formare la propria (se non sono di altri).
Oggi, con tutto che si muove così velocemente e le nostre giornate sembrano troppo corte, è tentatore scegliere la scorciatoia e affidarsi alle recensioni invece di andare alla fonte originale (ci sono passato anch’io). Se scegli la scorciatoia per questa audizione, è molto probabile che la maggior parte delle recensioni che troverai sul web o sui social media si concentreranno sulla richiesta di regolamentare l’AI del CEO di OpenAI, Sam Altman. Tuttavia, dopo aver visto l’audizione, ho sentito che c’era di più da esplorare oltre i titoli.
Quindi, dopo la mia attività di domenica mattina, ho deciso di scaricare la trascrizione dell’audizione del Senato e utilizzare il Package NLTK (un pacchetto Python per il processing del linguaggio naturale – NLP) per analizzarla, confrontare le parole più utilizzate e applicare alcuni punteggi di sentimento tra diversi gruppi di interesse (OpenAI, IBM, Accademie, Congresso) e vedere cosa c’è tra le righe. Avviso spoiler! Su 29.000 parole analizzate, solo 70 (0,24%) erano relative a parole come regolamentazione, regolare, regolamentare o legislazione.
- Le migliori 10 strumenti per rilevare ChatGPT, GPT-4, Bard e Claude
- L’arte dell’Ingegneria di Prompt Decodificare ChatGPT
- GPT4All è la ChatGPT locale per i tuoi documenti ed è gratuita!
È importante notare che questo articolo non riguarda le mie impressioni da queste udienze sull’AI o Mr. ChatGPT Sam Altman. Invece, si concentra su ciò che si nasconde dietro le parole di ogni parte della società (Privato, Accademie, Governo) rappresentate in questa sessione sotto il tetto del Campidoglio, e su ciò che possiamo imparare da quelle parole che si mescolano tra di loro.
Dato che i prossimi mesi sono tempi interessanti per il futuro della regolamentazione sull’Intelligenza Artificiale, poiché la bozza finale dell’AI Act dell’UE attende il dibattito al Parlamento europeo (previsto per giugno), vale la pena esplorare ciò che si cela dietro le discussioni sull’AI su questo lato dell’Atlantico.
STEP-01: OTTIENI I DATI
Ho utilizzato la trascrizione pubblicata da Justin Hendrix in Tech Policy Press (accessibile qui).

Mentre Hendrix afferma che si tratta di una trascrizione rapida e suggerisce di confermare le citazioni guardando il video dell’audizione del Senato, l’ho comunque trovata abbastanza accurata e interessante per questa analisi. Se vuoi guardare l’audizione del Senato o leggere le testimonianze di Sam Altman (Open AI), Christina Montgomery (IBM) e Gary Marcus (professore presso la New York University), puoi trovarle qui.
Inizialmente, avevo pianificato di copiare la trascrizione in un documento Word e creare manualmente una tabella in Excel con i nomi dei partecipanti, le loro organizzazioni rappresentative e i loro commenti. Tuttavia, questo approccio era lento e inefficiente. Quindi, mi sono rivolto a Python e ho caricato l’intera trascrizione da un file Microsoft Word in un data frame. Ecco il codice che ho usato:
# STEP 01-Leggi il documento Word# ricorda di installare pip install python-docximport docximport pandas as pddoc = docx.Document('D:\....il tuo file Word su Microsoft Word')items = []names = []comments = []# Itera sui paragrafi for paragraph in doc.paragraphs: text = paragraph.text.strip() if text.endswith(':'): name = text[:-1] else: items.append(len(items)) names.append(name) comments.append(text)dfsenate = pd.DataFrame({'item': items, 'name': names, 'comment': comments})# Rimuovi le righe con commenti vuotidfsenate = dfsenate[dfsenate['comment'].str.strip().astype(bool)]# Reimposta l'indicedefsenate.reset_index(drop=True, inplace=True)dfsenate['item'] = dfsenate.index + 1print(dfsenate)L’output dovrebbe apparire come segue:
nome dell'oggetto commento0 1 Sen. Richard Blumenthal (D-CT) Ora per alcune osservazioni introduttive.1 2 Sen. Richard Blumenthal (D-CT) "Troppo spesso abbiamo visto cosa succede quando la tecnologia supera la regolamentazione, lo sfruttamento sfrenato dei dati personali, la proliferazione di disinformazione e l'approfondimento delle disuguaglianze sociali. Abbiamo visto come i pregiudizi algoritmici possano perpetuare la discriminazione e il pregiudizio, e come la mancanza di trasparenza possa minare la fiducia del pubblico. Questo non è il futuro che vogliamo".2 3 Sen. Richard Blumenthal (D-CT) Se stavate ascoltando da casa, potreste aver pensato che quella voce fosse mia e le parole da me, ma in realtà quella voce non era mia. Le parole non erano mie. E l'audio era un software di clonazione vocale AI addestrato sui miei discorsi sul pavimento. Le osservazioni sono state scritte da ChatGPT quando gli è stato chiesto come avrei aperto questa udienza. E avete appena sentito il risultato. Ho chiesto a ChatGPT perché ha scelto quei temi e quel contenuto? E ha risposto. E cito, Blumenthal ha un forte record nel difendere la protezione dei consumatori e i diritti civili. Ha espresso la sua opinione su questioni come la privacy dei dati e il potenziale per la discriminazione nella decisione algoritmica. Pertanto, la dichiarazione sottolinea questi aspetti.3 4 Sen. Richard Blumenthal (D-CT) Signor Altman, apprezzo l'approvazione di ChatGPT. In tutta serietà, questa apparente ragionamento è piuttosto impressionante. Sono sicuro che tra un decennio guarderemo a ChatGPT e GPT-4 come facciamo con il primo cellulare, quei grandi aggeggi maldestri che usavamo per portare in giro. Ma riconosciamo che siamo sull'orlo, veramente, di una nuova era. L'audio e il mio gioco, potrebbe sembrarti curioso o divertente, ma ciò che ha rimbombato nella mia mente è stato "e se l'avessi chiesto?" E se avesse fornito un'approvazione dell'Ucraina, della resa o della leadership di Vladimir Putin? Sarebbe stato davvero spaventoso. E la prospettiva è più che un po' spaventosa, per usare la parola, signor Altman, che hai usato tu stesso, e penso che tu sia stato molto costruttivo nel richiamare l'attenzione sui rischi e sulle promesse.4 5 Sen. Richard Blumenthal (D-CT) Ecco perché volevamo che fossi qui oggi. E ringraziamo te e gli altri nostri testimoni per esserti unito a noi per diversi mesi. Ora, il pubblico è stato affascinato da GPT, dally e altri strumenti di intelligenza artificiale. Questi esempi come i compiti svolti da ChatGPT o gli articoli e gli editoriali che può scrivere sembrano novità. Ma gli avanzi sottostanti di questa era sono più che semplici esperimenti di ricerca. Non sono più fantasie di fantascienza. Sono reali e rappresentano le promesse di curare il cancro o sviluppare nuove comprensioni della fisica e della biologia o modellare il clima e il tempo. Tutto molto incoraggiante e speranzoso. Ma conosciamo anche i potenziali danni e li abbiamo già visti disinformazione armata, discriminazione abitativa, molestie alle donne e impersonificazione, frode, clonazione vocale di profondità. Questi sono i rischi potenziali nonostante gli altri premi. E per me, forse il più grande incubo è la nuova rivoluzione industriale imminente. La dislocazione di milioni di lavoratori, la perdita di un enorme numero di posti di lavoro, la necessità di prepararsi per questa nuova rivoluzione industriale nella formazione delle competenze e nella ricollocazione che potrebbe essere richiesta. E già i leader dell'industria stanno richiamando l'attenzione su quelle sfide.5 6 Sen. Richard Blumenthal (D-CT) Per citare ChatGPT, questo non è necessariamente il futuro che vogliamo. Dobbiamo massimizzare il bene sul male. Il Congresso ha una scelta. Adesso. Abbiamo avuto la stessa scelta quando ci siamo confrontati con i social media. Abbiamo fallito nel cogliere quell'attimo. Il risultato sono i predatori su Internet, i contenuti tossici che sfruttano i bambini, creando pericoli per loro. E il senatore Blackburn, io e altri come il senatore Durbin della commissione giudiziaria stiamo cercando di affrontarlo nella legge sulla sicurezza online dei bambini. Ma il Congresso ha fallito nell'affrontare l'IA. Adesso abbiamo l'obbligo di farlo prima che le minacce e i rischi diventino reali. Le salvaguardie sensate non sono in opposizione all'innovazione. La responsabilità non è un onere, anzi. Sono la base su cui possiamo procedere proteggendo la fiducia del pubblico. Sono come possiamo guidare il mondo nella tecnologia e nella scienza, ma anche nella promozione dei nostri valori democratici.6 7 Sen. Richard Blumenthal (D-CT) Altrimenti, in assenza di quella fiducia, credo che potremmo perdere entrambi. Queste sono tecnologie sofisticate, ma ci sono aspettative di base comuni nella nostra legge. Possiamo iniziare con la trasparenza. Le società di intelligenza artificiale dovrebbero essere obbligate a testare i loro sistemi, divulgare i rischi noti e consentire l'accesso a ricercatori indipendenti. Possiamo stabilire schede di valutazione e etichette nutrizionali per incoraggiare la concorrenza basata sulla sicurezza e sulla fiducia, limitazioni d'uso. Ci sono luoghi in cui il rischio dell'IA è così estremo che dovremmo limitare o addirittura vietare il loro uso, specialmente quando si tratta di invasioni commerciali della privacy a scopo di lucro e decisioni che influenzano il sostentamento delle persone. E ovviamente, la responsabilità, l'affidabilità. Quando le società di intelligenza artificiale e i loro clienti causano danni, dovrebbero essere ritenuti responsabili. Non dovremmo ripetere i nostri errori passati, ad esempio la sezione 230, costringere le società a pensare in anticipo e essere responsabili delle conseguenze delle loro decisioni commerciali può essere lo strumento più potente di tutti. Spazzatura in, spazzatura fuori. Il principio si applica ancora. Dobbiamo prestare attenzione alla spazzatura, che sia in queste piattaforme o che esca da esse.In seguito, ho considerato l’aggiunta di alcune etichette per future analisi, identificando gli individui dal segmento della società che rappresentavano
def assign_sector(name): if name in ['Sam Altman', 'Christina Montgomery']: return 'Privato' elif name == 'Gary Marcus': return 'Accademia' else: return 'Congresso'# Applica la funzione dfsenate['sector'] = dfsenate['name'].apply(assign_sector)# Assegna le organizzazioni in base ai nomidef assign_organization(name): if name == 'Sam Altman': return 'OpenAI' elif name == 'Christina Montgomery': return 'IBM' elif name == 'Gary Marcus': return 'Accademia' else: return 'Congresso'# Applica la funzionedfsenate['Organizzazione'] = dfsenate['name'].apply(assign_organization)print(dfsenate)Infine, ho deciso di aggiungere una colonna che conta le parole di ogni dichiarazione, che potrebbe aiutarci anche per ulteriori analisi.
dfsenate['ConteggioParole'] = dfsenate['comment'].apply(lambda x: len(x.split()))In questa parte, il tuo dataframe dovrebbe apparire così:
item name ... Organizzazione ConteggioParole0 1 Sen. Richard Blumenthal (D-CT) ... Congresso 51 2 Sen. Richard Blumenthal (D-CT) ... Congresso 552 3 Sen. Richard Blumenthal (D-CT) ... Congresso 1253 4 Sen. Richard Blumenthal (D-CT) ... Congresso 1454 5 Sen. Richard Blumenthal (D-CT) ... Congresso 197.. ... ... ... ... ...399 400 Sen. Cory Booker (D-NJ) ... Congresso 156400 401 Sam Altman ... OpenAI 180401 402 Sen. Cory Booker (D-NJ) ... Congresso 72402 403 Sen. Richard Blumenthal (D-CT) ... Congresso 154403 404 Sen. Richard Blumenthal (D-CT) ... Congresso 98FASE 02: VISUALIZZA I DATI
Diamo uno sguardo ai numeri che abbiamo finora: 404 domande o testimonianze e quasi 29.000 parole. Questi numeri ci danno il materiale di cui abbiamo bisogno per cominciare. È importante sapere che alcune dichiarazioni sono state divise in parti più piccole. Quando c’erano dichiarazioni lunghe con diversi paragrafi, il codice le divideva in dichiarazioni separate, anche se facevano parte di un’unica contribuzione. Per avere una migliore comprensione dell’implicazione di ciascun partecipante, ho considerato anche il numero di parole utilizzate. Ciò ha fornito un’altra prospettiva sulla loro partecipazione.
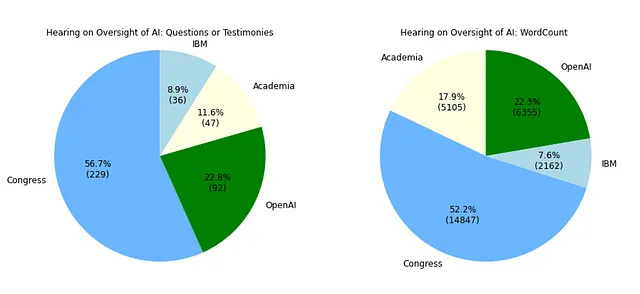
Come si può vedere nella Figura 01, le interviste dei membri del Congresso rappresentano più della metà di tutte le audizioni, seguite dalla testimonianza di Sam Altman. Tuttavia, una vista alternativa ottenuta contando le parole di ciascun lato mostra una rappresentanza più equilibrata tra il Congresso (11 membri) e il panel composto da Altman (OpenAI), Montgomery (IBM) e Marcus (Accademia).
È interessante notare i diversi livelli di coinvolgimento tra i membri del Congresso che hanno partecipato all’audizione del Senato (vedi tabella qui sotto). Come previsto, il senatore Blumenthal, in qualità di presidente del sottocomitato, è stato altamente coinvolto. Ma gli altri membri? La tabella mostra significative variazioni nel coinvolgimento tra tutti gli undici partecipanti. Ricorda, la quantità di contributi non necessariamente indica la loro qualità. Ti lascerò fare la tua valutazione mentre rivisiti i numeri.
Infine, anche se Sam Altman ha ricevuto molta attenzione, vale la pena notare che Gary Marcus, nonostante sembri abbia avuto poche opportunità di partecipazione, ha avuto molto da dire, come indicato dal suo conteggio delle parole, che è simile a quello di Altman. O forse perché l’accademia fornisce spiegazioni dettagliate, mentre il mondo degli affari preferisce la praticità e la semplicità?
Va bene, professore Marcus, se potesse essere specifico. Questa è la tua occasione, parla in lingua semplice e dimmi quali, se ci sono, regole dovremmo implementare. E per favore non usare solo concetti. Sto cercando specificità.
Senatore John Kennedy (R-LA). Udienza del Senato degli Stati Uniti sull’Oversight dell’IA (2023)
#*****************************GRAFICI A TORTA************************************import pandas as pdimport matplotlib.pyplot as plt# Grafico a torta - Raggruppamento per 'Organizzazione' Domande e Testimonianzeorg_colors = {'Congresso': '#6BB6FF', 'OpenAI': 'verde', 'IBM': 'azzurro chiaro', 'Accademici': 'giallo chiaro'}org_counts = dfsenate['Organizzazione'].value_counts()plt.figure(figsize=(8, 6))patches, text, autotext = plt.pie(org_counts.values, labels=org_counts.index, autopct=lambda p: f'{p:.1f}%\n({int(p * sum(org_counts.values) / 100)})', startangle=90, colors=[org_colors.get(org, 'grigio') for org in org_counts.index])plt.title('Udienza sulla supervisione dell\'Intelligenza Artificiale: Domande o Testimonianze')plt.axis('equal')plt.setp(text, fontsize=12)plt.setp(autotext, fontsize=12)plt.show()# Grafico a torta - Raggruppamento per 'Organizzazione' (Conteggio Parole)org_colors = {'Congresso': '#6BB6FF', 'OpenAI': 'verde', 'IBM': 'azzurro chiaro', 'Accademici': 'giallo chiaro'}org_wordcount = dfsenate.groupby('Organizzazione')['Conteggio Parole'].sum()plt.figure(figsize=(8, 6))patches, text, autotext = plt.pie(org_wordcount.values, labels=org_wordcount.index, autopct=lambda p: f'{p:.1f}%\n({int(p * sum(org_wordcount.values) / 100)})', startangle=90, colors=[org_colors.get(org, 'grigio') for org in org_wordcount.index])plt.title('Udienza sulla supervisione dell\'Intelligenza Artificiale: Conteggio Parole')plt.axis('equal')plt.setp(text, fontsize=12)plt.setp(autotext, fontsize=12)plt.show()#************Coinvolgimento tra i membri del Congresso**********************# Raggruppa per nome e conta le righeSummary_Name = dfsenate.groupby('nome').agg(comment_count=('commento', 'size')).reset_index()# Colonna Conteggio Parole per ogni nomeSummary_Name ['Conteggio_Parole_Totale'] = dfsenate.groupby('nome')['Conteggio Parole'].sum().values# Distribuzione percentuale per comment_countSummary_Name ['Percentuale_comment_count'] = Summary_Name['comment_count'] / Summary_Name['comment_count'].sum() * 100# Distribuzione percentuale per Conteggio_Parole_TotaleSummary_Name ['Percentuale_Conteggio_Parole'] = Summary_Name['Conteggio_Parole_Totale'] / Summary_Name['Conteggio_Parole_Totale'].sum() * 100Summary_Name = Summary_Name.sort_values('Conteggio_Parole_Totale', ascending=False)print (Summary_Name)+-------+--------------------------------+---------------+---------------------+---------------------------+--------------+| index | nome | Interventi | Conteggio_Parole_Totale | Percentuale_comment_count | Percentuale_Conteggio_Parole |+-------+--------------------------------+---------------+------------------------+---------------------------+------------------------------+| 2 | Sam Altman | 92 | 6355 | 22.772277 | 22.322526 || 1 | Gary Marcus | 47 | 5105 | 11.633663 | 17.931785 || 15 | Sen. Richard Blumenthal (D-CT) | 58 | 3283 | 14.356435 | 11.531841 || 10 | Sen. Josh Hawley (R-MO) | 25 | 2283 | 6.188118 | 8.019249 || 0 | Christina Montgomery | 36 | 2162 | 8.910891 | 7.594225 || 6 | Sen. Cory Booker (D-NJ) | 20 | 1688 | 4.950495 | 5.929256 || 7 | Sen. Dick Durbin (D-IL) | 8 | 1143 | 1.980198 | 4.014893 || 11 | Sen. Lindsey Graham (R-SC) | 32 | 880 | 7.920792 | 3.091081 || 5 | Sen. Christopher Coons (D-CT) | 6 | 869 | 1.485148 | 3.052443 || 12 | Sen. Marsha Blackburn (R-TN) | 14 | 869 | 3.465346 | 3.052443 || 4 | Sen. Amy Klobuchar (D-MN) | 11 | 769 | 2.722772 | 2.701183 || 13 | Sen. Mazie Hirono (D-HI) | 7 | 755 | 1.732673 | 2.652007 || 14 | Sen. Peter Welch (D-VT) | 11 | 704 | 2.722772 | 2.472865 || 3 | Sen. Alex Padilla (D-CA) | 7 | 656 | 1.732673 | 2.304260 |+-------+--------------------------------+---------------+------------------------+---------------------------+------------------------------+PASSO 03: TOKENIZZAZIONE
Qui inizia il divertimento del processamento del linguaggio naturale (NLP). Per analizzare il testo, utilizzeremo il pacchetto NLTK in Python. Esso fornisce utili strumenti per l’analisi e la visualizzazione della frequenza delle parole. Le seguenti librerie e moduli forniranno gli strumenti necessari per l’analisi e la visualizzazione della frequenza delle parole.
#pip install nltk#pip install spacy#pip install wordcloud#pip install subprocess#python -m spacy download enPer prima cosa, inizieremo con la Tokenizzazione, che significa scomporre il testo in singole parole, anche note come “token”. Per questo, utilizzeremo spaCy, una libreria NLP open source che può gestire contrazioni, punteggiatura e caratteri speciali. Successivamente, rimuoveremo le parole comuni che non aggiungono molto significato, come “un”, “una”, “il”, “è” e “e”, utilizzando la risorsa stop word dalla libreria NLTK. Infine, applicheremo la Lemmatizzazione che riduce le parole alla loro forma base, nota come lemma. Ad esempio, “running” diventa “run” e “happier” diventa “happy”. Questa tecnica ci aiuta a lavorare con il testo in modo più efficace e a comprenderne il significato.
Per riassumere:
o Tokenizzare il testo.
o Rimuovere le parole comuni.
o Applicare la lemmatizzazione.
#***************************FREQUENZA DELLE PAROLE*******************************import subprocessimport nltkimport spacyfrom nltk.probability import FreqDistfrom nltk.corpus import stopwords# Scaricare le risorsec subprocess.run('python -m spacy download en', shell=True)nltk.download('punkt')# Caricare il modello spaCy e impostare le stopwordsnlp = spacy.load('en_core_web_sm')stop_words = set(stopwords.words('english'))def preprocess_text(text): words = nltk.word_tokenize(text) words = [word.lower() for word in words if word.isalpha()] words = [word for word in words if word not in stop_words] lemmas = [token.lemma_ for token in nlp(" ".join(words))] return lemmas# Aggregare le parole e creare la distribuzione delle frequenzeall_comments = ' '.join(dfsenate['comment'])processed_comments = preprocess_text(all_comments)fdist = FreqDist(processed_comments)#**********************LE 30 PAROLE PIÙ COMUNI DELLA AUDIZIONE*********************import matplotlib.pyplot as pltimport numpy as np# Parole più comuni e le loro frequenze top_word = fdist.most_common(30)words = [word for word, freq in top_words]frequencies = [freq for word, freq in top_words]# Grafico a barre - Udienza sulla sorveglianza dell'AIfig, ax = plt.subplots(figsize=(8, 10))ax.barh(range(len(words)), frequencies, align='center', color='skyblue')ax.invert_yaxis()ax.set_xlabel('Frequenza', fontsize=12)ax.set_ylabel('Parole', fontsize=12)ax.set_title('Udienza sulla sorveglianza dell\'AI: Le 30 parole più comuni', fontsize=14)ax.set_yticks(range(len(words)))ax.set_yticklabels(words, fontsize=10)ax.spines['right'].set_visible(False)ax.spines['top'].set_visible(False)ax.spines['left'].set_linewidth(0.5)ax.spines['bottom'].set_linewidth(0.5)ax.tick_params(axis='x', labelsize=10)plt.subplots_adjust(left=0.3)for i, freq in enumerate(frequencies): ax.text(freq + 5, i, str(freq), va='center', fontsize=8)plt.show()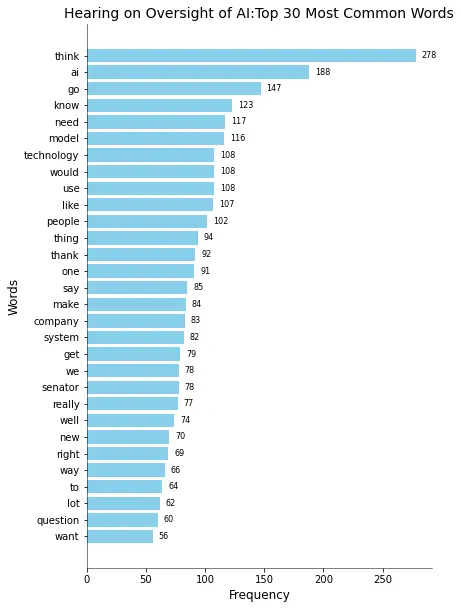
Come si può vedere nel grafico a barre (Figura 02), c’era molto “Thinking”. Forse le prime cinque parole ci danno un interessante suggerimento su cosa dovremmo fare oggi e per il nostro futuro in termini di AI:
“Abbiamo bisogno di pensare e sapere dove dovrebbe andare l’AI”.
Come ho menzionato all’inizio di questo articolo, a prima vista, “regolamentazione” non spicca come parola frequentemente usata nell’Udienza del Senato sull’AI. Tuttavia, concludere che non fosse un argomento di grande preoccupazione potrebbe essere inesatto. L’interesse sulla necessità o meno di regolamentare l’AI è stato espresso con parole diverse come “regolamentazione”, “regolare”, “agenzia” o “regolamentare”. Pertanto, apportiamo alcune modifiche al codice, aggreghiamo queste parole e ri-eseguiamo il grafico a barre per vedere come influisce sull’analisi.
nlp = spacy.load('en_core_web_sm')
stop_words = set(stopwords.words('english'))
def preprocess_text(text):
words = nltk.word_tokenize(text)
words = [word.lower() for word in words if word.isalpha()]
words = [word for word in words if word not in stop_words]
lemmas = [token.lemma_ for token in nlp(" ".join(words))]
return lemmas
# Aggregazione di parole e creazione della distribuzione di frequenza
all_comments = ' '.join(dfsenate['comment'])
processed_comments = preprocess_text(all_comments)
fdist = FreqDist(processed_comments)
original_fdist = fdist.copy() # Salva l'oggetto originale
aggregate_words = ['regolamentazione', 'regolare', 'agenzia', 'regolatorio', 'legislazione']
aggregate_freq = sum(fdist[word] for word in aggregate_words)
df_aggregatereg = pd.DataFrame({'Parola': aggregate_words, 'Frequenza': [fdist[word] for word in aggregate_words]})
# Rimuovi le singole parole e aggiungi l'aggregazione
for word in aggregate_words:
del fdist[word]
fdist['regolamentazione+agenzia'] = aggregate_freq
# Grafico a torta per la distribuzione di regolamentazione+agenzia
import matplotlib.pyplot as plt
labels = df_aggregatereg['Parola']
values = df_aggregatereg['Frequenza']
plt.figure(figsize=(8, 6))
plt.subplots_adjust(top=0.8, bottom=0.25)
patches, text, autotext = plt.pie(values, labels=labels,
autopct=lambda p: f'{p:.1f}%\n({int(p * sum(values) / 100)})',
startangle=90, colors=['#6BB6FF', 'green', 'lightblue', 'lightyellow', 'gray'])
plt.title('Regolamentazione+agenzia: Distribuzione', fontsize=14)
plt.axis('equal')
plt.setp(text, fontsize=8)
plt.setp(autotext, fontsize=8)
plt.show()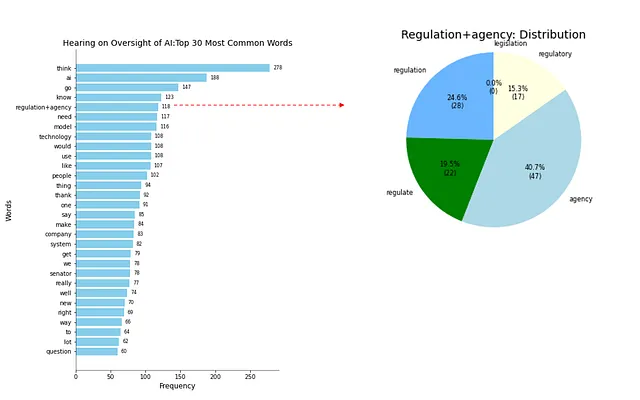
Come si può vedere nella Figura 03, l’argomento della regolamentazione è stato discusso molte volte durante l’Udienza sul Controllo dell’AI del Senato.
STEP-04: COSA SI NASCONDE DIETRO LE PAROLE
Le parole da sole possono fornirci alcuni indizi, ma è l’interconnessione delle parole che offre veramente una prospettiva. Quindi, prendiamo un approccio usando le nuvole di parole per esplorare se possiamo scoprire informazioni che non possono essere mostrate da semplici grafici a barre e a torta.
# Nuvola di parole - Udienza sul Controllo dell'AI del Senatoda wordcloud import WordCloud
wordcloud = WordCloud(width=800, height=400, background_color='white').generate_from_frequencies(fdist)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title('Nuvola di parole - Udienza sul Controllo dell\'AI del Senato')
plt.show()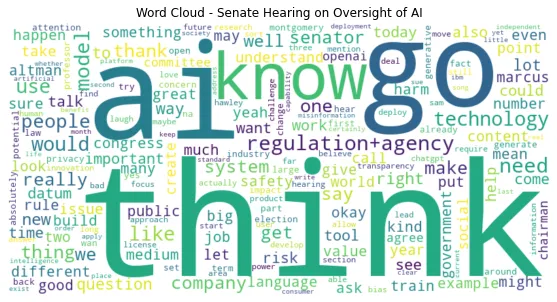
Esploriamo ulteriormente e confrontiamo le nuvole di parole per i diversi gruppi di interesse rappresentati nell’Udienza sull’AI (privati, Congresso, Accademici) e vediamo se le parole rivelano prospettive diverse sul futuro dell’AI.
# Nuvole di parole per ogni gruppo di interesseorganizations = dfsenate['Organizzazione'].unique()
for organization in organizations:
comments = dfsenate[dfsenate['Organizzazione'] == organization]['comment']
all_comments = ' '.join(comments)
processed_comments = preprocess_text(all_comments)
fdist_organization = FreqDist(processed_comments)
# Nuvole di parole
wordcloud = WordCloud(width=800, height=400, background_color='white').generate_from_frequencies(fdist_organization)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
if organization == 'IBM':
plt.title(f'Nuvola di parole: {organization} - Christina Montgomery')
elif organization == 'OpenAI':
plt.title(f'Nuvola di parole: {organization} - Sam Altman')
elif organization == 'Accademici':
plt.title(f'Nuvola di parole: {organization} - Gary Marcus')
else:
plt.title(f'Nuvola di parole: {organization}')
plt.show()
È interessante come alcune parole appaiano (o scompaiano) per ogni gruppo di interesse rappresentato nell’audizione del Senato sull’Intelligenza Artificiale mentre parlano di intelligenza artificiale.
Per quanto riguarda il grande titolo, “La chiamata di Sam Altman per la regolamentazione dell’AI”; beh, se è a favore della regolamentazione o meno, non lo posso dire con certezza, ma non sembra avere molta regolamentazione nelle sue parole. Invece, Sam Altman sembra avere un approccio centrato sulle persone quando parla di AI, ripetendo parole come “pensare,” “persone,” “sapere,” “importante,” e “usare,” e si affida di più a parole come “tecnologia,” “sistema” o “modello” invece di usare la parola “AI”.
Qualcuno che ha avuto qualcosa da dire riguardo al “rischio” e alle “questioni” è stato Christina Montgomery (IBM) che ha ripetuto queste parole costantemente parlando di “tecnologia”, “aziende” e “AI”. Un fatto interessante nella sua testimonianza è trovare parole che ci si aspetterebbe di sentire soprattutto da aziende coinvolte nello sviluppo della tecnologia; “fiducia,” “governance” e “pensare” a ciò che è “giusto” in termini di AI.
“ Dobbiamo rendere le aziende responsabili oggi e responsabili dell’AI che stanno implementando…“
Christina Montgomery. Audizione del Senato degli Stati Uniti sulla vigilanza dell’AI (2023)
Gary Marcus nella sua dichiarazione iniziale ha detto: “Vengo come scienziato, qualcuno che ha fondato aziende di AI e qualcuno che ama veramente l’AI…” Quindi, per il bene di questa analisi NLP, lo consideriamo come una rappresentazione della voce dell’Accademia. Parole come “necessità,” “pensare,” “sapere,” “andare,” “persone” risaltano tra le altre. Un fatto interessante è che la parola “sistema” sembra essere ripetuta più spesso di “AI” nella sua testimonianza. Forse l’AI non è una singola tecnologia solitaria che cambierà il futuro, l’impatto sul futuro verrà da molteplici tecnologie o sistemi che interagiscono tra loro (IoT, robotica, BioTech, ecc.) anziché affidarsi esclusivamente a uno di essi.
Alla fine, la prima ipotesi menzionata dal senatore John Kennedy non sembra del tutto falsa (non solo per il Congresso ma per l’intera società). Siamo ancora in quella fase in cui stiamo cercando di capire la direzione verso cui si sta dirigendo l’AI.
“ Permit me to share with you three hypotheses that I would like you to assume for the moment to be true. Hypothesis number one, many members of Congress do not understand artificial intelligence. Hypothesis. Number two, that absence of understanding may not prevent Congress from plunging in with enthusiasm and trying to regulate this technology in a way that could hurt this technology. Hypothesis number three, that I would like you to assume there is likely a berserk wing of the artificial intelligence community that intentionally or unintentionally could use artificial intelligence to kill all of us and hurt us the entire time that we are dying….. “
Sen. John Kennedy (R-LA). Audizione del Senato degli Stati Uniti sulla vigilanza dell’AI (2023)
STEP-05: L’EMOZIONE DIETRO LE TUE PAROLE
Utilizzeremo la classe SentimentIntensityAnalyzer della libreria NLTK per l’analisi del sentiment. Questo modello pre-addestrato utilizza un approccio basato su lessico, in cui ogni parola nel lessico (VADER) ha un valore di polarità del sentimento predefinito. I punteggi di sentimento delle parole in un frammento di testo vengono aggregati per calcolare un punteggio complessivo del sentimento. Il valore numerico varia da -1 (sentimento negativo) a +1 (sentimento positivo), con 0 che indica un sentimento neutro. Il sentimento positivo riflette un’emozione, un atteggiamento o un entusiasmo favorevole, mentre il sentimento negativo comunica un’emozione o un atteggiamento sfavorevole.
#************ANALISI DEL SENTIMENTO************dall'nltk.sentiment import SentimentIntensityAnalyzernltk.download('vader_lexicon')sid = SentimentIntensityAnalyzer()dfsenate['Sentiment'] = dfsenate['comment'].apply(lambda x: sid.polarity_scores(x)['compound'])#************BOXPLOT-GRUPPO DI INTERESSE************import seaborn as snsimport matplotlib.pyplot as pltsns.set_style('white')plt.figure(figsize=(12, 7))sns.boxplot(x='Sentiment', y='Organizzazione', data=dfsenate, color='giallo', width=0.6, showmeans=True, showfliers=True)# Personalizzazione degli assi def add_cosmetics(title='Distribuzione dell\'analisi del sentimento per gruppo di interesse', xlabel='Sentimento'): plt.title(title, fontsize=28) plt.xlabel(xlabel, fontsize=20) plt.xticks(fontsize=15) plt.yticks(fontsize=15) sns.despine()def customize_labels(label): if "OpenAI" in label: return label + "-Sam Altman" elif "IBM" in label: return label + "-Christina Montgomery" elif "Accademia" in label: return label + "-Gary Marcus" else: return label# Applicazione di etichette personalizzate all'asse ytcks = plt.yticks()[1]plt.yticks(ticks=plt.yticks()[0], labels=[customize_labels(label.get_text()) for label in yticks])add_cosmetics()plt.show()
Un boxplot è sempre interessante poiché mostra i valori minimi e massimi, la mediana, il primo (Q1) e il terzo (Q3) quartile. Inoltre, è stato aggiunto un codice per visualizzare il valore medio. (Riconoscimento a Elena Kosourova per la progettazione del modello di codice del boxplot; ho solo apportato modifiche per il mio dataset).
In generale, tutti sembravano essere di buon umore durante l’Udienza al Senato, in particolare Sam Altman, che si è distinto con il punteggio di sentimento più alto, seguito da Christina Montgomery. D’altra parte, Gary Marcus sembrava avere un’esperienza più neutra (mediana intorno a 0,25) e potrebbe essersi sentito un po’ a disagio a volte, con valori vicini a 0 o addirittura negativi. Inoltre, il Congresso nel suo insieme ha mostrato una distribuzione a sinistra nei punteggi di sentimento, indicando una tendenza verso la neutralità o la positività. Interessante notare che, se osserviamo più attentamente, alcune interviste si sono distinte con punteggi di sentimento estremamente alti o bassi.
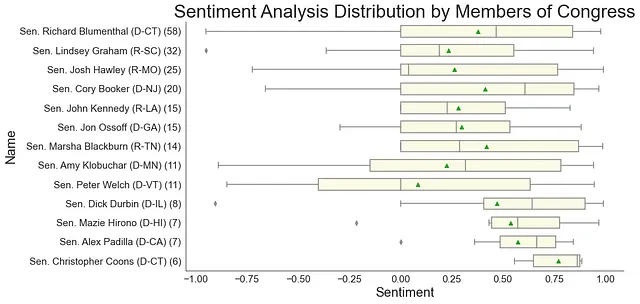
Forse dovremmo interpretare i risultati non come se le persone presenti all’Udienza del Senato sull’AI fossero felici o a disagio. Forse questo suggerisce che coloro che partecipano all’Udienza potrebbero non avere una visione eccessivamente ottimistica di dove sta andando l’AI, ma allo stesso tempo, non sono pessimisti. I punteggi potrebbero indicare che ci sono alcune preoccupazioni e si sta procedendo con cautela sulla direzione che l’AI dovrebbe prendere.
E per quanto riguarda una linea temporale? L’umore durante l’udienza è rimasto lo stesso? Come è evoluto l’umore di ogni gruppo di interesse? Per analizzare la linea temporale, ho organizzato le dichiarazioni nell’ordine in cui sono state registrate ed effettuato un’analisi del sentimento. Poiché ci sono oltre 400 domande o testimonianze, ho definito una media mobile dei punteggi di sentimento per ciascun gruppo di interesse (Congresso, Accademia, Privati), utilizzando una finestra di dimensione 10. Ciò significa che la media mobile viene calcolata mediante la media dei punteggi di sentimento su ogni 10 dichiarazioni consecutive:
#**************************LINEA TEMPORALE UDienza SENATO AI**************************************import seaborn as snsimport matplotlib.pyplot as pltimport numpy as npfrom scipy.interpolate import make_interp_spline# Media mobile per ciascuna organizzazionewindow_size = 10 organizations = dfsenate['Organizzazione'].unique()# Creazione del grafico a lineecolor_palette = sns.color_palette('Set2', len(organizations))plt.figure(figsize=(12, 6))for i, org in enumerate(organizations): df_org = dfsenate[dfsenate['Organizzazione'] == org] # media mobile df_org['Sentiment'].fillna(0, inplace=True) # valori mancanti riempiti con 0 df_org['Media_mobile'] = df_org['Sentiment'].rolling(window=window_size, min_periods=1).mean() x = np.linspace(df_org.index.min(), df_org.index.max(), 500) spl = make_interp_spline(df_org.index, df_org['Media_mobile'], k=3) y = spl(x) plt.plot(x, y, linewidth=2, label=f'{org} Media mobile a {window_size} punti', color=color_palette[i])plt.xlabel('Numero dichiarazione', fontsize=12)plt.ylabel('Punteggio di sentimento', fontsize=12)plt.title('Evoluzione del punteggio di sentimento durante l\'Udienza sul controllo dell\'AI', fontsize=16)plt.legend(fontsize=12)plt.grid(color='grigio chiaro', linestyle='--', linewidth=0.5)plt.axhline(0, color='nero', linewidth=0.5, alpha=0.5)for org in organizations: df_org = dfsenate[dfsenate['Organizzazione'] == org] plt.text(df_org.index[-1], df_org['Media_mobile'].iloc[-1], f'{df_org["Media_mobile"].iloc[-1]:.2f}', ha='right', va='top', fontsize=12, color='nero')plt.tight_layout()plt.show()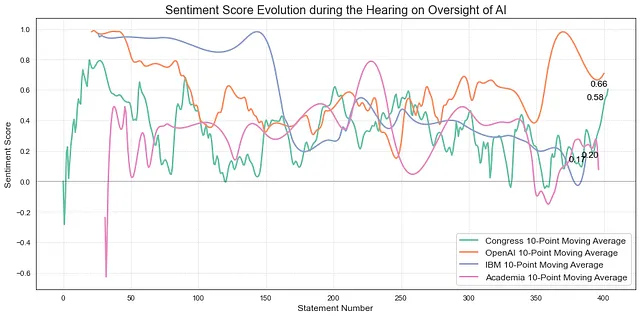
All’inizio, la sessione sembrava amichevole e ottimistica, con tutti che discutevano del futuro dell’AI. Ma man mano che la sessione continuava, l’umore è cambiato. I membri del Congresso sono diventati meno ottimisti e le loro domande sono diventate più sfidanti. Questo ha influenzato i punteggi dei relatori, con alcuni che hanno ottenuto punteggi bassi (è possibile vederlo verso la fine della sessione). Interessantemente, il modello ha visto Altman come neutrale o leggermente positivo, anche durante i momenti tesi con i membri del Congresso.
È importante ricordare che il modello ha le sue limitazioni e potrebbe confinare nella soggettività. Sebbene l’analisi del sentiment non sia perfetta, ci offre uno sguardo interessante sull’intensità delle emozioni che hanno prevalso quel giorno a Capitol Hill.
Considerazione finale
A mio parere, le lezioni dietro questa audizione dell’AI del Senato degli Stati Uniti si trovano nelle cinque parole più ripetute: “Dobbiamo pensare e sapere dove dovrebbe andare l’AI”. È degno di nota il fatto che parole come “persone” e “importanza” fossero presenti inaspettatamente nella nuvola di parole di Sam Altman, andando oltre il titolo di un “Appello alla regolamentazione”. Sebbene avessi sperato di trovare più parole come “trasparenza”, “responsabilità”, “fiducia”, “governance” e “equità” nell’analisi NLP di Altman, è stato un sollievo trovarne alcune ripetute frequentemente nella testimonianza di Christina Montgomery. Questo è ciò che tutti ci aspettiamo di sentire più frequentemente quando si parla di AI.
Gary Marcus ha enfatizzato “sistema” tanto quanto “AI”, forse invitandoci a vedere l’intelligenza artificiale in un contesto più ampio. Attualmente stanno emergendo molte tecnologie, e il loro impatto combinato sulla società, sul lavoro e sull’occupazione futura deriverà dallo scontro di queste molteplici tecnologie, non solo da una di esse. L’accademia svolge un ruolo vitale nel guidare questo percorso, e se è necessaria una qualche forma di regolamentazione, dico questo “letteralmente” non “spiritualmente” (battuta interna dalla lettera di moratoria di sei mesi).
Infine, la parola “Agenzia” è stata ripetuta tanto quanto “Regolamentazione” nelle sue diverse forme. Ciò suggerisce che il concetto di un'”Agenzia per l’AI” e il suo ruolo saranno probabilmente oggetto di dibattito nel prossimo futuro. Una riflessione interessante su questa sfida è stata menzionata nell’audizione dell’AI del Senato dal senatore Richard Blumenthal:
“ …La maggior parte della mia carriera è stata di applicazione della legge. E ti dirò una cosa, puoi creare 10 nuove agenzie, ma se non gli dai le risorse, e non sto parlando solo di dollari, ma di competenze scientifiche, voi ragazzi li farai girare in tondo. E non sono solo i modelli o l’AI generativa che faranno girare in tondo i modelli, ma sono gli scienziati delle vostre aziende. Per ogni storia di successo nella regolamentazione governativa, puoi pensare a cinque fallimenti…. E spero che la nostra esperienza qui sarà diversa… “
Sen. Richard Blumenthal (D-CT). Audizione del Senato degli Stati Uniti sulla sorveglianza dell’AI (2023)
Anche se per me è difficile conciliare innovazione, consapevolezza e regolamentazione, sono del tutto favorevole a sensibilizzare sul ruolo dell’AI nel nostro presente e futuro, ma anche a capire che “ricerca” e “sviluppo” sono cose diverse. La prima dovrebbe essere incoraggiata e promossa, non contenuta, la seconda è dove è necessario l’impegno extra nel “pensare” e “sapere”.
Spero che abbiate trovato interessante questa analisi NLP e ringrazio Justin Hendrix e Tech Policy Press per avermi permesso di utilizzare la loro trascrizione in questo articolo. È possibile accedere al codice completo in questo repository GitHub. (Riconoscimento anche a ChatGPT per avermi aiutato a perfezionare alcune parti del mio codice per una migliore presentazione).
Ho dimenticato qualcosa? I tuoi suggerimenti sono sempre ben accetti e mantengono la conversazione attiva.





