Semplificazione dei Transformers NLP all’avanguardia utilizzando parole comprensibili – parte 2 – Input
Semplificazione dei Transformers NLP utilizzando parole comprensibili - parte 2 - Input
Approfondimento su come vengono costruiti gli input dei transformer
Input
Il drago esce dall’uovo, i bambini nascono dai ventri, il testo generato dall’IA parte dagli input. Tutti dobbiamo cominciare da qualche parte. Che tipo di input? Dipende dal compito che hai tra le mani. Se stai costruendo un modello linguistico, un software che sa come generare testo rilevante (l’architettura dei transformer è utile in diversi scenari), l’input è il testo. Tuttavia, può un computer ricevere qualsiasi tipo di input (testo, immagine, suono) e sapere magicamente come elaborarlo? No.
Sono sicuro che conosci persone che non sono molto brave con le parole ma sono ottime con i numeri. Il computer è un po’ così. Non può elaborare il testo direttamente nella CPU/GPU (dove avvengono i calcoli), ma può sicuramente lavorare con i numeri! Come vedrai presto, il modo di rappresentare queste parole come numeri è un ingrediente cruciale nella ricetta segreta.
Tokenizer
La tokenizzazione è il processo di trasformazione del corpus (tutto il testo che hai) in parti più piccole utili per la macchina. Supponiamo di avere un dataset di 10.000 articoli di Wikipedia. Prendiamo ogni carattere e lo trasformiamo (tokenizziamo). Ci sono molti modi per tokenizzare il testo, vediamo come lo fa il tokenizer di OpenAI con il seguente testo:
“Molte parole si mappano in un token, ma alcune no: indivisibile.
- Il Cantilever v/s ChatGPT
- Introduzione agli algoritmi di ranking
- 3 errori silenziosi su Pandas di cui dovresti essere consapevole
I caratteri Unicode come gli emoji possono essere divisi in molti token contenenti i byte sottostanti: 🤚🏾
Le sequenze di caratteri comuni che si trovano vicino l’uno all’altro possono essere raggruppate insieme: 1234567890″
Ecco il risultato della tokenizzazione:

Come puoi vedere, ci sono circa 40 parole (a seconda di come conti i segni di punteggiatura). Di queste 40 parole, sono stati generati 64 token. A volte il token è l’intera parola, come “Molte, parole, si mappano” e a volte è una parte di una parola, come “Unicode”. Perché spezziamo le parole intere in parti più piccole? Perché dividere anche le frasi? Potremmo averle tenute unite. Alla fine, vengono comunque convertite in numeri, quindi qual è la differenza dal punto di vista del computer se il token è lungo 3 o 30 caratteri? I token aiutano il modello a imparare perché, dato che il testo è il nostro dato, sono le caratteristiche del dato. Diverse modalità di progettazione di queste caratteristiche porteranno a variazioni delle prestazioni. Ad esempio, nella frase: “Esci!!!!!!!”, dobbiamo decidere se più “!” sono diversi da uno solo, o se hanno lo stesso significato. Tecnicamente potremmo aver tenuto le frasi intere, ma immagina di guardare una folla vs ogni persona singolarmente, in quale scenario otterrai migliori intuizioni?
Ora che abbiamo i token possiamo costruire un dizionario di ricerca che ci permetterà di eliminare le parole e utilizzare invece gli indici (numeri). Ad esempio, se tutto il nostro dataset è la frase: “Dov’è Dio”, potremmo costruire questo tipo di vocabolario, che è solo una coppia chiave:valore delle parole e un singolo numero che le rappresenta. Non dovremo usare l’intera parola ogni volta, possiamo utilizzare il numero. Ad esempio: {Dov’è: 0, Dio: 1}. Ogni volta che incontriamo la parola “Dio”, la sostituiamo con 1. Per ulteriori esempi di tokenizzatori, puoi controllare quello sviluppato da Google o giocare ancora con TikToken di OpenAI.
Word2Vec
IntuizioneStiamo facendo grandi progressi nel nostro viaggio per rappresentare le parole come numeri. Il prossimo passo sarà quello di generare rappresentazioni numeriche, semantiche, da quei token. Per farlo, possiamo utilizzare un algoritmo chiamato Word2Vec. I dettagli non sono molto importanti al momento, ma l’idea principale è che si prende un vettore (semplifichiamo per ora, pensa a una lista regolare) di numeri di qualsiasi dimensione desideri (gli autori del paper ne hanno utilizzati 512) e questa lista di numeri dovrebbe rappresentare il significato semantico di una parola. Immagina una lista di numeri come [-2, 4, -3.7, 41… -0.98] che rappresenta effettivamente il significato semantico di una parola. Dovrebbe essere creata in modo tale che, se plottiamo questi vettori su un grafico 2D, termini simili saranno più vicini di termini dissimili.
Come puoi vedere nell’immagine (tratta da qui), “Baby” è vicino a “Aww” e “Asleep” mentre “Citizen”/”State”/”America’s” sono anche raggruppati tra loro. *I vettori di parole 2D (chiamati anche lista con 2 numeri) non saranno in grado di avere un significato accurato nemmeno per una singola parola, come hanno menzionato gli autori hanno utilizzato 512 numeri. Poiché non possiamo rappresentare nulla con 512 dimensioni, utilizziamo un metodo chiamato PCA per ridurre il numero di dimensioni a due, preservando sperabilmente gran parte del significato originale. Nella terza parte di questa serie approfondiremo un po’ come avviene tutto ciò.
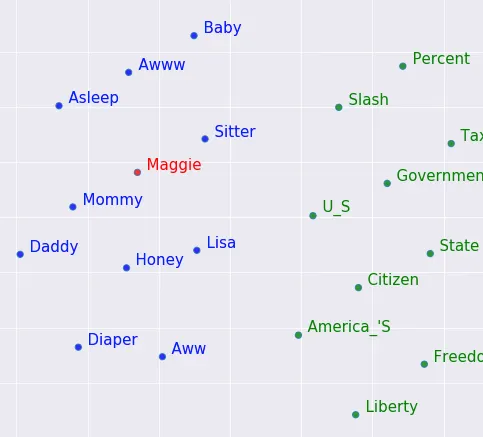
Funziona! È possibile addestrare un modello in grado di produrre liste di numeri che contengono significati semantici. Il computer non sa che un bambino è un umano piccolo che urla e priva di sonno (ma super dolce), ma sa che di solito vede la parola “baby” vicino a “aww”, più spesso che a “State” e “Government”. Scriverò ulteriormente su come avviene esattamente tutto ciò, ma fino ad allora, se sei interessato, potrebbe essere un buon punto di partenza da esplorare.
Queste “liste di numeri” sono piuttosto importanti, quindi hanno il loro nome nella terminologia dell’apprendimento automatico, che è Embeddings. Perché embeddings? Perché stiamo effettuando un embedding (quindi creativo), che è il processo di mappatura (traduzione) di un termine da una forma (parole) a un’altra (lista di numeri). Queste sono un sacco di (). Da qui in poi chiameremo le parole embeddings, che come spiegato sono liste di numeri che contengono il significato semantico di qualsiasi parola per cui sono addestrati a rappresentare.
Creazione degli Embeddings con Pytorch
Prima calcoliamo il numero di token unici che abbiamo, per semplicità diciamo 2. La creazione del layer degli embeddings, che è la prima parte dell’architettura Transformer, sarà semplicemente scrivere questo codice:
*Osservazione generale sul codice – non prendere questo codice e le sue convenzioni come uno stile di programmazione corretto, è scritto in modo particolare per renderlo facile da capire.
Codice
import torch.nn as nnvocabulary_size = 2num_dimensions_per_word = 2embds = nn.Embedding(vocabulary_size, num_dimensions_per_word)print(embds.weight)---------------------output:Parameter containing:tensor([[-1.5218, -2.5683], [-0.6769, -0.7848]], requires_grad=True)Ora abbiamo una matrice di embedding che in questo caso è una matrice 2×2, generata con numeri casuali derivati dalla distribuzione normale N(0,1) (ad es. una distribuzione con media 0 e varianza 1). Nota il requires_grad=True, questo è il linguaggio di Pytorch per dire che questi 4 numeri sono pesi apprendibili. Possono e saranno personalizzati nel processo di apprendimento per rappresentare meglio i dati che il modello riceve.
In uno scenario più realistico, possiamo aspettarci qualcosa di più vicino a una matrice 10k x 512 che rappresenta l’intero dataset in numeri.
vocabulary_size = 10_000num_dimensions_per_word = 512embds = nn.Embedding(vocabulary_size, num_dimensions_per_word)print(embds)---------------------output:Embedding(10000, 512)*Dato curioso (possiamo pensare a cose più divertenti), a volte si sente parlare di modelli di linguaggio che utilizzano miliardi di parametri. Questo strato iniziale, non troppo complesso, contiene 10_000 x 512 parametri che sono 5 milioni di parametri. Questo modello di linguaggio di grandi dimensioni (LLM) è roba difficile, richiede molti calcoli. Qui i parametri è un termine sofisticato per quei numeri (-1.525 ecc.), solo che sono soggetti a cambiamenti e cambieranno durante l’addestramento. Questi numeri sono l’apprendimento della macchina, è ciò che la macchina sta imparando. Successivamente, quando diamo in input, moltiplichiamo l’input con quei numeri e speriamo di ottenere un buon risultato. Cosa sai, i numeri contano. Quando sei importante, hai il tuo nome, quindi quei numeri non sono solo numeri, sono parametri.
Perché usare 512 e non 5? Perché più numeri significano probabilmente una generazione di significato più accurata. Ottimo, smetti di pensare in piccolo, usiamo un milione allora! Perché no? Perché più numeri significano più calcoli, più potenza di calcolo, più costoso da addestrare, ecc. Si è scoperto che 512 è un buon punto intermedio.
Lunghezza della sequenza
Quando alleniamo il modello, mettiamo insieme un sacco di parole. È più efficiente dal punto di vista computazionale e aiuta il modello a imparare più contesto. Come accennato, ogni parola verrà rappresentata da un vettore di 512 dimensioni (una lista con 512 numeri) e ogni volta che passiamo gli input al modello (chiamato anche passaggio in avanti), invieremo un insieme di frasi, non solo una. Ad esempio, abbiamo deciso di supportare una sequenza di 50 parole. Questo significa che prenderemo un certo numero di parole in una frase, se x > 50 la divideremo e prenderemo solo le prime 50, se x < 50, avremo comunque bisogno che la dimensione sia esattamente la stessa (spiegherò presto perché). Per risolvere questo problema, aggiungiamo del padding che sono stringhe speciali fittizie, al resto della frase. Ad esempio, se supportiamo una frase di 7 parole e abbiamo la frase "Dov'è Dio", aggiungiamo 4 padding, quindi l'input per il modello sarà "Dov'è Dio “. In realtà, di solito aggiungiamo almeno altri 2 padding speciali in modo che il modello sappia dove inizia e dove finisce la frase, quindi sarà effettivamente qualcosa del genere ” Dov’è Dio “.
* Perché tutti i vettori di input devono avere la stessa dimensione? Perché il software ha “aspettative” e le matrici hanno aspettative ancora più rigorose. Non puoi fare calcoli “matematici” come vuoi, devi rispettare determinate regole e una di queste regole riguarda le dimensioni dei vettori.
Codifiche posizionali
Intuizione Ora abbiamo un modo per rappresentare (e imparare) le parole nel nostro vocabolario. Rendiamolo ancora migliore codificando la posizione delle parole. Perché è importante? Perché se prendiamo queste due frasi:
1. L’uomo giocava con il mio gatto2. Il gatto giocava con il mio uomo
Possiamo rappresentare le due frasi usando le stesse rappresentazioni, ma le frasi hanno significati diversi. Possiamo pensare a dati in cui l’ordine non conta. Se sto facendo una somma di qualcosa, non importa da dove inizio. Nel linguaggio, l’ordine conta di solito. Le rappresentazioni contengono significati semantici, ma nessun significato di ordine esatto. Tuttavia, mantengono un ordine in un certo senso perché queste rappresentazioni sono state create originariamente secondo una certa logica linguistica (babbo appare più vicino a dormire che a stato), ma la stessa parola può avere più di un significato in sé e, cosa più importante, un significato diverso quando è in un contesto diverso.
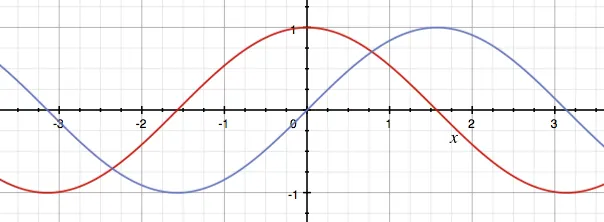
Rappresentare le parole come testo senza ordine non è sufficiente, possiamo migliorare questo. Gli autori suggeriscono di aggiungere una codifica posizionale alle rappresentazioni. Facciamo questo calcolando un vettore di posizione per ogni parola e aggiungendolo (sommandolo) ai due vettori. I vettori di codifica posizionale devono avere la stessa dimensione in modo che possano essere sommati. La formula per la codifica posizionale utilizza due funzioni: il seno per le posizioni pari (ad esempio, la parola 0, la parola 2, la parola 4, la parola 6, ecc.) e il coseno per le posizioni dispari (ad esempio, la parola 1, la parola 3, la parola 5, ecc.).
Visualizzazione Osservando queste funzioni (seno in rosso, coseno in blu), puoi forse immaginare perché sono state scelte proprio queste due funzioni. C’è una certa simmetria tra le funzioni, come c’è tra una parola e la parola che la precede, il che aiuta il modello a rappresentare queste posizioni correlate. Inoltre, producono valori da -1 a 1, che sono numeri molto stabili con cui lavorare (non diventano molto grandi o molto piccoli).
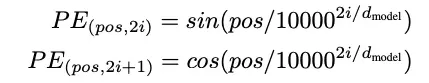
Nella formula sopra, la riga superiore rappresenta i numeri pari a partire da 0 (i = 0) e continua ad essere numerata pari (2*1, 2*2, 2*3). La seconda riga rappresenta i numeri dispari allo stesso modo.
Ogni vettore posizionale è un vettore di numeri di dimensioni (512 nel nostro caso) con numeri da 0 a 1.
Codice
from math import sin, cosmax_seq_len = 50 number_of_model_dimensions = 512positions_vector = np.zeros((max_seq_len, number_of_model_dimensions))for position in range(max_seq_len): for index in range(number_of_model_dimensions//2): theta = pos / (10000 ** ((2*i)/number_of_model_dimensions)) positions_vector[position, 2*index ] = sin(theta) positions_vector[position, 2*index + 1] = cos(theta)print(positions_vector)---------------------output:(50, 512)Se stampiamo la prima parola, vediamo che otteniamo solo 0 e 1 alternativamente.
print(positions_vector[0][:10])---------------------output:array([0., 1., 0., 1., 0., 1., 0., 1., 0., 1.])Il secondo numero è già molto più diverso.
print(positions_vector[1][:10])---------------------output:array([0.84147098, 0.54030231, 0.82185619, 0.56969501, 0.8019618 , 0.59737533, 0.78188711, 0.62342004, 0.76172041, 0.64790587])*L’ispirazione per il codice viene da qui.
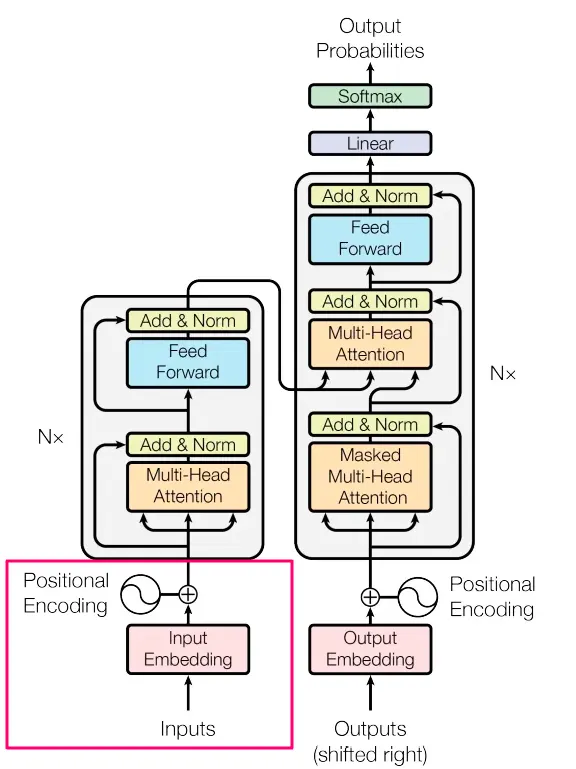
Abbiamo visto che diverse posizioni producono rappresentazioni diverse. Per finalizzare la sezione di input nel suo insieme (quadrata in rosso nell’immagine sottostante), aggiungiamo i numeri nella matrice delle posizioni alla nostra matrice di embedding di input. Otteniamo così una matrice delle stesse dimensioni dell’embedding, ma questa volta i numeri contengono significato semantico + ordine.

Riassunto Questo conclude la nostra prima parte della serie (Rettangolata in rosso). Abbiamo parlato di come il modello ottiene i suoi input. Abbiamo visto come scomporre il testo nelle sue caratteristiche (token), rappresentarle come numeri (embedding) e un modo intelligente per aggiungere l’encoding posizionale a questi numeri.
La prossima parte si concentrerà sulle diverse meccaniche del blocco Encoder (il primo rettangolo grigio), con ogni sezione che descrive un rettangolo di colore diverso (ad esempio Multi head attention, Add & Norm, ecc.)