Sbloccare il potenziale del testo Un’analisi più approfondita dei metodi di pulizia del testo pre-embedding
Sbloccare il potenziale del testo un'analisi approfondita dei metodi di pulizia pre-embedding
Questo articolo discuterà delle diverse tecniche di pulizia che sono essenziali per ottenere prestazioni ottimali dai dati testuali.
Per la dimostrazione dei metodi di pulizia del testo, utilizzeremo il set di dati testuali chiamato ‘metamorphosis’ da Kaggle.
Iniziamo importando le librerie Python necessarie per il processo di pulizia.
import nltk, re, stringfrom nltk.corpus import stopwordsfrom nltk.stem.porter import PorterStemmerOra carichiamo il set di dati.
file_directory = 'link-al-direttorio-locale-del-dataset'file = open(file_directory, 'rt', encoding='utf-8')text = file.read()file.close()nota che perché il codice sopra funzioni, è necessario inserire il percorso del direttorio locale del file di dati.
- Da grezzo a raffinato un viaggio attraverso la pre-elaborazione dei dati – Parte 1
- I migliori podcast sull’IA del 2023
- Incontra RAP e LLM Reasoners Due Framework basati su concetti simili per un ragionamento avanzato con LLMs
Suddividiamo i dati di testo in parole in base agli spazi vuoti.
words = text.split()print(words[:120])
Qui vediamo che la punteggiatura è preservata (ad esempio, armour-like e wasn’t), il che è bello. Possiamo anche vedere che la punteggiatura di fine frase è mantenuta con l’ultima parola (ad esempio, thought.), il che non è ottimo.
Quindi, questa volta proviamo a suddividere i dati utilizzando caratteri non di parole.
words = re.split(r'\W+', text)print(words[:120])
Qui vediamo che parole come ‘thought.’ sono state convertite in ‘thought’. Ma il problema è che le parole come ‘wasn’t’ vengono convertite in due parole come ‘wasn’ e ‘t’. Dobbiamo sistemarlo.
In Python, possiamo usare string.punctuation per ottenere una serie di punteggi contemporaneamente. Useremo questo per rimuovere la punteggiatura dal nostro testo.
print(string.punctuation)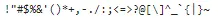
Quindi ora divideremo le parole in base agli spazi vuoti e rimuoveremo tutta la punteggiatura che è stata registrata nei dati.
words = text.split()re_punc = re.compile('[%s]' % re.escape(string.punctuation))stripped = [re_punc.sub('', word) for word in words]print(stripped[:120])
Qui vediamo che non abbiamo più parole come ‘thought.’, ma abbiamo ancora parole come ‘wasn’t’, il che è corretto.
A volte il testo contiene anche caratteri non stampabili. Dobbiamo filtrarli anche. Per farlo, possiamo usare ‘string.printable’ di Python che ci fornisce una serie di caratteri che possono essere stampati. Quindi, rimuoveremo i caratteri che non sono presenti in questo elenco.
re_print = re.compile('[^%s]' % re.escape(string.printable))result = [re_print.sub('', word) for word in stripped]print(result[:120])
Ora mettiamo tutte le parole in minuscolo. Questo ridurrà il nostro vocabolario. Ma ha anche alcuni svantaggi. Dopo aver fatto questo, due parole come ‘Apple’, come azienda, e ‘apple’, come frutto, saranno considerate la stessa entità.
result = [parola.lower() for parola in result]print(result[:120])
Inoltre, le parole con un solo carattere non contribuiranno alla maggior parte dei compiti NLP. Quindi le rimuoveremo anche.
result = [parola for parola in result if len(parola) > 1]print(result[:120])
Nell’NLP, parole frequenti come ‘è’, ‘come’, ‘il’ non contribuiscono molto all’addestramento del modello. Quindi tali parole sono conosciute come stop words e si consiglia di rimuoverle nel processo di pulizia del testo.
import nltkfrom nltk.corpus import stopwordsstop_words = stopwords.words('english')print(stop_words)
result = [parola for parola in result if parola not in set(stop_words)]print(parole[:110])
Ora, a questo punto, ridurremo le parole con lo stesso significato ad una sola parola. Ad esempio, ridurremo le parole ‘running’, ‘run’ e ‘runs’ alla parola ‘run’ solo perché tutte e tre le parole danno lo stesso significato al modello durante l’addestramento. Ciò può essere fatto utilizzando la classe PorterStemmer nella libreria nltk.
from nltk.stem.porter import PorterStemmerps = PorterStemmer()result = [ps.stem(parola) for parola in result]print(parole[:110])
Le parole stemmate possono avere o meno un significato. Se vuoi che le parole abbiano un significato, allora invece di utilizzare la tecnica di stemming, puoi utilizzare una tecnica di lemmatizzazione che garantisce che le parole abbiano significato dopo la trasformazione.
Adesso rimuoviamo le parole che non sono composte solo da lettere dell’alfabeto.
result = [parola for parola in result if parola.isalpha()]print(result[:110])
In questa fase, i dati testuali sembrano abbastanza buoni per essere utilizzati nelle tecniche di embedding delle parole. Ma si nota anche che potrebbero essere necessari alcuni passaggi aggiuntivi per questo processo per alcuni tipi speciali di dati (ad esempio, codice HTML).
Spero che l’articolo ti sia piaciuto. Se hai qualche pensiero sull’articolo, fammelo sapere. Ogni feedback costruttivo è molto apprezzato.
Connettiti con me su LinkedIn.
Scrivimi a [email protected]
Buona giornata!






