Riordinare la struttura dei cambiamenti del dataset
Riordinare i cambiamenti del dataset
Prendere un passo indietro sulle cause della degradazione del modello
In collaborazione con Marco Dalla Vecchia come creatore dell’immagine
Addestriamo modelli e li utilizziamo per prevedere determinati risultati dati un insieme di input. Sappiamo tutti che questo è il gioco del ML. Sappiamo molto su come addestrarli, tanto che ora sono evoluti in AI, il più alto livello di intelligenza mai esistito. Ma quando si tratta di usarli, non siamo così avanti e continuiamo a esplorare e comprendere ogni aspetto che conta dopo che i modelli vengono messi in funzione.
Quindi oggi parleremo del problema della deriva delle prestazioni del modello (o semplicemente deriva del modello), comunemente nota anche come fallimento del modello o degradazione del modello. Ci riferiamo al problema della qualità delle previsioni che il nostro modello ML fornisce. Che si tratti di una classe o di un numero, ci interessa il divario tra quella previsione e ciò che sarebbe la classe o il valore reale. Parliamo di deriva delle prestazioni del modello quando la qualità di quelle previsioni diminuisce rispetto al momento in cui abbiamo messo in funzione il modello. Potresti aver trovato altre terminologie per questo argomento nella letteratura, ma rimani con me sulla deriva delle prestazioni del modello o semplicemente deriva del modello, almeno per lo scopo della nostra conversazione attuale.
Quello che sappiamo
Diversi blog, libri e molti articoli hanno esplorato e spiegato i concetti fondamentali della deriva del modello, quindi entreremo subito in questa immagine attuale. Abbiamo organizzato le idee principalmente nei concetti di spostamento covariante, spostamento precedente e spostamento condizionale. Questi spostamenti sono noti come le principali cause della deriva del modello (ricorda, una diminuzione della qualità delle previsioni). Le definizioni riassunte sono le seguenti:
- Oltre LLaMA Il Potere delle LLM Aperte
- Segui le liste di TDS per scoprire i nostri migliori articoli
- L’uso della biometria come metodo di sicurezza informatica
- Spostamento covariante: Cambiamenti nella distribuzione di P(X) senza necessariamente avere cambiamenti in P(Y|X). Questo significa che la distribuzione delle caratteristiche di input cambia e alcuni di questi spostamenti possono causare la deriva del modello.
- Spostamento precedente: Cambiamenti nella distribuzione di P(Y). Qui, la distribuzione delle etichette o della variabile di output numerica cambia. Molto probabilmente, se la distribuzione di probabilità della variabile di output si sposta, il modello attuale avrà una grande incertezza sulla previsione data, quindi potrebbe facilmente deriva.
- Spostamento condizionale (aka deriva concettuale): La distribuzione condizionale P(Y|X) cambia. Questo significa che, per un determinato input, la probabilità della variabile di output è cambiata. Per quanto sappiamo finora, questa deriva di solito ci lascia poco margine per mantenere la qualità delle previsioni. È davvero così?
Esistono molte fonti che elencano esempi dell’occorrenza di questi spostamenti dei dati. Una delle opportunità principali per la ricerca è la rilevazione di questi tipi di spostamenti senza la necessità di nuove etichette [1, 2, 3]. Sono state recentemente rilasciate metriche interessanti per monitorare le prestazioni di previsione del modello in modo non supervisionato [2, 3]. Sono infatti motivate dai diversi concetti di spostamenti dei dati e riflettono abbastanza accuratamente i cambiamenti nelle reali distribuzioni di probabilità dei dati. Quindi andremo a immergerci nella teoria di questi spostamenti. Perché? Perché forse c’è un certo ordine che possiamo mettere su queste definizioni. Ordinando, potremmo essere in grado di andare avanti più facilmente o semplicemente capire più chiaramente questo intero quadro.
Per fare ciò, torniamo all’inizio e facciamo una lenta derivazione della storia. Prendi un caffè, leggi lentamente e resta con me. O semplicemente, non deriva!
Il modello reale e il modello stimato
I modelli di ML che addestriamo cercano di avvicinarci a una relazione o funzione reale, ma sconosciuta, che mappa un certo input X a un output Y. Naturalmente distinguiamo la reale relazione sconosciuta da quella stimata. Tuttavia, il modello stimato è legato al comportamento del modello reale sconosciuto. Cioè, se il modello reale cambia e il modello stimato non è robusto rispetto a questi cambiamenti, le previsioni del modello stimato saranno meno accurate.
Le prestazioni che possiamo monitorare riguardano la funzione stimata, ma le cause della deriva del modello si trovano nei cambiamenti del modello reale.
- Che cos’è il modello reale? Il modello reale si basa sulla cosiddetta distribuzione condizionale P(Y|X). Questa è la distribuzione di probabilità di un output dato un input.
- Che cos’è il modello stimato? Questo è una funzione ê(x) che specificamente stimando il valore atteso di P(Y|X=x). Questa funzione è quella collegata al nostro modello di ML.
Ecco una rappresentazione visiva di questi elementi:
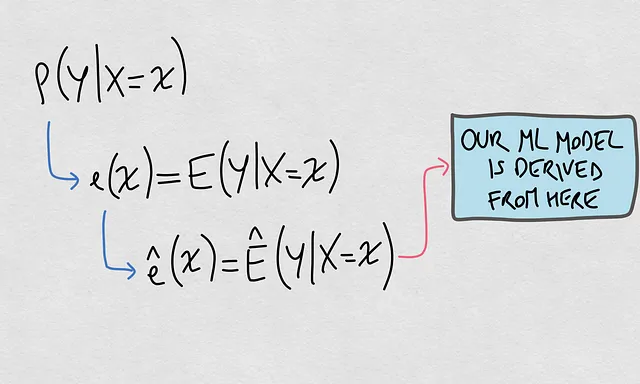
Bene, ora che abbiamo chiarito questi due elementi, siamo pronti per organizzare le idee dietro i cosiddetti cambiamenti dei dataset e come i concetti si collegano tra loro.
Il nuovo ordine
La causa globale della deriva del modello
Il nostro obiettivo principale è capire le cause della deriva del modello per il nostro modello stimato. Poiché abbiamo già compreso la connessione tra il modello stimato e la distribuzione di probabilità condizionale, possiamo affermare qui quello che sapevamo già: La causa globale della deriva del nostro modello stimato è il cambiamento in P(Y|X).
Elementare e apparentemente semplice, ma più fondamentale di quanto pensiamo. Assumiamo che il nostro modello stimato sia un buon riflesso del modello reale. Il modello reale è governato da P(Y|X). Quindi, se P(Y|X) cambia, è probabile che il nostro modello stimato deriva. Dobbiamo prestare attenzione al percorso che stiamo seguendo in quel ragionamento che abbiamo mostrato nella figura sopra.
Questo lo sapevamo già, quindi cosa c’è di nuovo? La cosa nuova è che ora battezziamo qui i cambiamenti in P(Y|X) come la causa globale, non solo una causa. Questo imporrà una gerarchia rispetto alle altre cause. Questa gerarchia ci aiuterà a posizionare bene i concetti sulle altre cause.
Le cause specifiche: Elementi della causa globale
Sapendo che la causa globale risiede nei cambiamenti in P(Y|X), diventa naturale approfondire quali elementi costituiscono questa probabilità. Una volta identificati questi elementi, continueremo a parlare delle cause della deriva del modello. Quindi quali sono quegli elementi?
Lo abbiamo sempre saputo. La probabilità condizionale è teoricamente definita come P(Y|X) = P(Y, X) / P(X), cioè la probabilità congiunta divisa per la probabilità marginale di X. Ma possiamo aprire nuovamente la probabilità congiunta e otteniamo la formula magica che conosciamo da secoli:
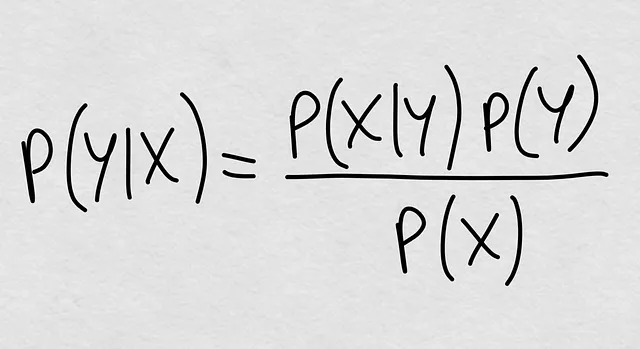
Vedi già dove stiamo andando? La probabilità condizionale è qualcosa che è completamente definito da tre elementi:
- P(X|Y): La probabilità condizionale inversa
- P(Y): La probabilità a priori
- P(X): La probabilità marginale delle covariate
Perché questi sono i tre elementi che definiscono la probabilità condizionale P(Y|X), siamo pronti a fare una seconda affermazione: Se P(Y|X) cambia, quei cambiamenti derivano da almeno uno dei tre elementi che lo definiscono. In altre parole, i cambiamenti in P(Y|X) sono definiti da qualsiasi cambiamento in P(X|Y), P(Y) o P(X).
Detto questo, abbiamo posizionato gli altri elementi dalla nostra conoscenza attuale come cause specifiche della deriva del modello anziché semplicemente cause parallele a P(Y|X).
Tornando all’inizio di questo post, abbiamo elencato il cambiamento della covariata e il cambiamento della probabilità a priori. Notiamo, quindi, che c’è un’altra causa specifica: i cambiamenti nella distribuzione condizionale inversa P(X|Y). Di solito troviamo qualche menzione di questa distribuzione quando si parla dei cambiamenti in P(Y) come se in generale stessimo considerando la relazione inversa da Y a X [1,4].
La nuova gerarchia dei concetti
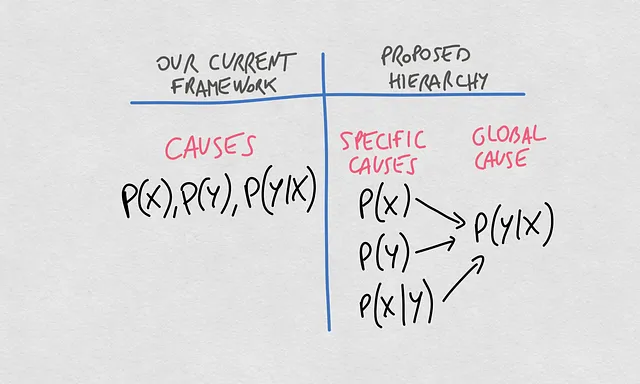
Ora possiamo fare un confronto chiaro tra il pensiero attuale su questi concetti e la gerarchia proposta. Fino ad ora, abbiamo parlato delle cause della deriva del modello identificando diverse distribuzioni di probabilità. Le tre principali distribuzioni, P(X), P(Y) e P(Y|X), sono note come le principali cause della deriva nella qualità delle previsioni restituite dal nostro modello di machine learning.
La svolta che propongo qui impone una gerarchia sui concetti. In essa, la causa globale della deriva di un modello che stima la relazione X -> Y sono i cambiamenti nella probabilità condizionata P(Y|X). Questi cambiamenti in P(Y|X) possono derivare da cambiamenti in P(X), P(Y) o P(X|Y).
Elenchiamo alcune delle implicazioni di questa gerarchia:
- Potremmo avere casi in cui P(X) cambia, ma se anche P(Y) e P(X|Y) cambiano di conseguenza, allora P(Y|X) rimane lo stesso.
- Potremmo anche avere casi in cui P(X) cambia, ma se P(Y) o P(X|Y) non cambiano di conseguenza, P(Y|X) cambierà. Se hai già riflettuto su questo argomento in precedenza, avrai probabilmente notato che in alcuni casi potremmo vedere X cambiare e quei cambiamenti non sembrano del tutto indipendenti da Y|X, quindi alla fine anche Y|X cambia. Qui, P(X) è la causa specifica dei cambiamenti in P(Y|X), che a sua volta è la causa globale della deriva del nostro modello.
- Le due affermazioni precedenti sono vere anche per P(Y).
Poiché le tre cause specifiche possono cambiare o non cambiare indipendentemente, nel complesso i cambiamenti in P(Y|X) possono essere spiegati dai cambiamenti di questi elementi specifici nel loro insieme. Potrebbe essere perché P(X) si è spostato un po’ qui e P(Y) si è spostato un po’ là, poi questi due fanno cambiare anche P(X|Y), che alla fine causa il cambiamento complessivo di P(Y|X).
P(X) e P(Y|X) non devono essere considerati in modo indipendente, P(X) è una causa di P(Y|X)
Dove si trova il modello di ML stimato in tutto questo?
Ora sappiamo che i cosiddetti spostamenti di covariate e priori sono cause di spostamenti condizionali piuttosto che paralleli ad essi. Gli spostamenti condizionali comprendono l’insieme delle cause specifiche per il degrado delle prestazioni di previsione del modello stimato. Ma il modello stimato è piuttosto un confine di decisione o una funzione, non realmente una stima diretta delle probabilità in gioco. Quindi, cosa significano le cause per i confini di decisione reali e stimati?
Riuniamo tutti i pezzi e tracciamo il percorso completo che collega tutti gli elementi:

Nota che il nostro modello di ML può essere ottenuto in modo analitico o numerico. Inoltre, può essere una rappresentazione parametrica o non parametrica. Quindi, alla fine, i nostri modelli di ML sono una stima del confine di decisione o della funzione di regressione che possiamo derivare dal valore condizionale atteso.
Questo fatto ha un’importante implicazione per le cause che abbiamo discusso. Mentre la maggior parte dei cambiamenti che avvengono in P(X), P(Y) e P(X|Y) comporteranno cambiamenti in P(Y|X) e quindi in E(Y|X), non tutti necessariamente implicano un cambiamento nel confine di decisione o nella funzione reale. In tal caso, il confine di decisione o la funzione stimata rimarranno validi se questa è stata originariamente una stima accurata. Guarda questo esempio qui sotto:
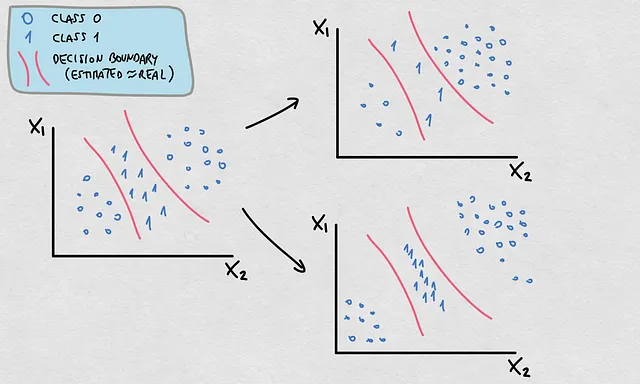
- Vedi che P(Y) e P(X) sono cambiate. La densità e la posizione dei punti rappresentano una distribuzione di probabilità diversa
- Questi cambiamenti fanno cambiare P(Y|X)
- Tuttavia, il confine di decisione è rimasto valido
Ecco un aspetto importante. Immagina di osservare i cambiamenti in P(X) senza informazioni sulle etichette reali. Vorremmo sapere quanto sono buone le previsioni. Se P(X) si sposta verso aree in cui il confine di decisione stimato ha una grande incertezza, le previsioni sono probabilmente inaccurate. Quindi, nel caso di uno spostamento di covariata verso regioni incerte del confine di decisione, molto probabilmente sta avvenendo anche uno spostamento condizionale. Ma non sapremmo se il confine di decisione sta cambiando o no. In tal caso, possiamo quantificare un cambiamento che si verifica in P(X), il quale può indicare un cambiamento in P(Y|X), ma non sapremmo cosa sta accadendo al confine di decisione o alla funzione di regressione. Ecco una rappresentazione di questo problema:

Quindi ora che abbiamo detto tutto questo, è ora di fare un’altra affermazione. Parliamo di shift condizionale quando ci riferiamo ai cambiamenti in P(Y|X). È possibile che ciò che abbiamo chiamato drift concettuale si riferisca specificamente ai cambiamenti nel confine decisionale reale o nella funzione di regressione. Ecco qui di seguito un tipico esempio di shift condizionale con un cambiamento nel confine decisionale ma senza un cambio nelle covariate o nelle precedenti. Infatti, il cambiamento è avvenuto a causa del cambiamento nella probabilità condizionale inversa P(X|Y).
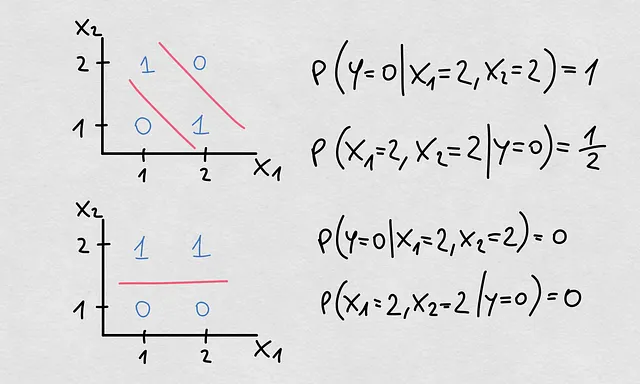
Implicazioni per i nostri metodi di monitoraggio attuali
Ci interessa capire queste cause in modo da poter sviluppare metodi per monitorare le prestazioni dei nostri modelli di apprendimento automatico nel modo più accurato possibile. Nessuna delle idee proposte è una brutta notizia per le soluzioni pratiche disponibili. Anzi, con questa nuova gerarchia di concetti, potremmo essere in grado di spingere ancora più avanti i nostri tentativi di individuare le cause del degrado delle prestazioni del modello. Abbiamo metodi e metriche che sono state proposte per monitorare le prestazioni di previsione dei nostri modelli, principalmente proposti alla luce dei diversi concetti che abbiamo elencato qui. Tuttavia, è possibile che abbiamo mescolato i concetti nelle assunzioni delle metriche [2]. Ad esempio, potremmo aver fatto riferimento a un’assunzione come “nessun shift condizionale”, quando in realtà potrebbe essere specificamente “nessun cambiamento nel confine decisionale” o “nessun cambiamento nella funzione di regressione”. Dobbiamo continuare a riflettere su questo.
Ulteriori informazioni sul degrado delle prestazioni di previsione
Ingrandendo e riducendo. Ci siamo addentrati nel framework per riflettere sulle cause del degrado delle prestazioni di previsione. Ma abbiamo un’altra dimensione per discutere questo argomento, che riguarda i tipi di spostamenti delle prestazioni di previsione. I nostri modelli soffrono a causa delle cause elencate, e quelle cause si riflettono come diverse forme di disallineamento delle previsioni. Troviamo principalmente quattro tipi: Bias, Slope, Variance e Non-linear shifts. Dai un’occhiata a questo post per saperne di più su quest’altro lato della medaglia.
Riassunto
In questo post abbiamo studiato le cause del degrado delle prestazioni del modello e proposto un framework basato sulle connessioni teoriche dei concetti che già conoscevamo. Ecco i punti principali:
- La probabilità P(Y|X) governa il confine decisionale o la funzione reale.
- Il confine decisionale o la funzione stimati sono considerati la migliore approssimazione di quelli reali.
- Il confine decisionale o la funzione stimati sono il modello di apprendimento automatico.
- Il modello di apprendimento automatico può subire un degrado delle prestazioni di previsione.
- Tale degrado è causato dai cambiamenti in P(Y|X).
- P(Y|X) cambia perché ci sono cambiamenti in almeno uno di questi elementi: P(X), P(Y) o P(X|Y).
- Può esserci un cambiamento in P(X) e P(Y) senza avere cambiamenti nel confine decisionale o nella funzione di regressione.
La dichiarazione generale è: se il modello di apprendimento automatico sta driftando, allora P(Y|X) sta cambiando. Il contrario non è necessariamente vero.
Questo framework di concetti è sperabilmente nient’altro che un seme dell’argomento cruciale del degrado delle prestazioni di previsione dell’apprendimento automatico. Mentre la discussione teorica è semplicemente un piacere, sono convinto che questa connessione ci aiuterà a spingere ancora più avanti l’obiettivo di misurare questi cambiamenti nella pratica, ottimizzando le risorse necessarie (campioni ed etichette). Partecipa alla discussione se hai altri contributi alla tua conoscenza.
Cosa sta causando lo shift del tuo modello nelle prestazioni di previsione?
Auguri per una felice riflessione!
Riferimenti
[1] https://huyenchip.com/2022/02/07/data-distribution-shifts-and-monitoring.html
[2] https://www.sciencedirect.com/science/article/pii/S016974392300134X
[3]https://nannyml.readthedocs.io/en/stable/how_it_works/performance_estimation.html#performance-estimation-deep-dive
[4] https://medium.com/towards-data-science/understanding-dataset-shift-f2a5a262a766






