Da molti a pochi affrontare i dati ad alta dimensionalità con la riduzione della dimensionalità nell’apprendimento automatico
Riduzione dimensionalità per dati ad alta dimensionalità nell'apprendimento automatico
Questo articolo discuterà del problema della dimensionalità nel machine learning e della riduzione dimensionale come soluzione al problema.
Cos’è la maledizione della dimensionalità?
A volte un problema di machine learning può consistere in migliaia o addirittura milioni di caratteristiche per ogni istanza di addestramento. Addestrare il nostro modello di machine learning su dati del genere richiede una quantità di risorse e tempo estremamente elevata. Questo problema è spesso definito come la ‘maledizione della dimensionalità’.
Risolvere il problema dell’alta dimensionalità
- Trovare il giusto equilibrio comprendere l’underfitting e l’overfitting nei modelli di apprendimento automatico
- Sii sicuro dei tuoi modelli di Machine Learning con l’aiuto della Cross-Validation
- Conoscere le diverse misure di performance per il problema di classificazione del Machine Learning
Per affrontare la maledizione della dimensionalità, spesso adottiamo diversi metodi che riducono il numero di caratteristiche (in altre parole, il numero di dimensioni) dei dati.
L’utilità dei metodi di riduzione dimensionale
I metodi di riduzione dimensionale aiutano a risparmiare risorse e tempo. In casi rari, la riduzione può persino aiutare a filtrare il rumore superfluo dai dati. Un altro utilizzo della riduzione dimensionale è la visualizzazione dei dati. Dal momento che la visualizzazione dei dati ad alta dimensionalità è difficile da realizzare e anche difficile da comprendere anche se riusciamo a visualizzarla, ridurre la dimensione a 2 o 3 ci aiuta spesso a visualizzare i dati in modo più chiaro.
Limiti della riduzione dimensionale dei dati
I metodi di riduzione dimensionale non sono privi di limiti. Si verifica una perdita di informazioni quando si esegue la riduzione dimensionale dei dati. Inoltre, l’utilizzo del metodo di riduzione dimensionale sui dati non garantisce un aumento delle prestazioni del modello. Si noti che questi metodi sono solo un modo per addestrare il modello più rapidamente o preservare le nostre risorse, ma non un modo per aumentare le prestazioni del modello. Nella maggior parte dei casi, le prestazioni del modello addestrato sui dati ridotti saranno inferiori rispetto al modello addestrato sui dati originali.
Ci sono due approcci famosi alla riduzione dimensionale.
- Proiezione
- Apprendimento di varietà
Proiezione
Nella maggior parte dei problemi del mondo reale, le caratteristiche dei dati non sono distribuite in modo uniforme su tutte le dimensioni. Alcune sono quasi costanti e altre sono correlate. Pertanto, queste istanze di addestramento si trovano all’interno o molto vicino al sottospazio molto inferiore dello spazio ad alta dimensionalità originale. In altre parole, esiste una rappresentazione dimensionale inferiore dei dati che è quasi equivalente alla rappresentazione dei dati nel loro spazio originale.
Ma questo approccio non è il migliore per tutti i tipi di dataset. Per alcuni dataset, utilizzare il metodo di proiezione comprimerà insieme i diversi strati di istanze e tale proiezione non rappresenterà i dati originali nelle dimensioni inferiori. Per questo tipo di dati, i metodi di apprendimento di varietà sono più adatti.
Apprendimento di varietà
Nel metodo di apprendimento di varietà, srotoliamo i dati anziché proiettarli sul sottospazio inferiore.
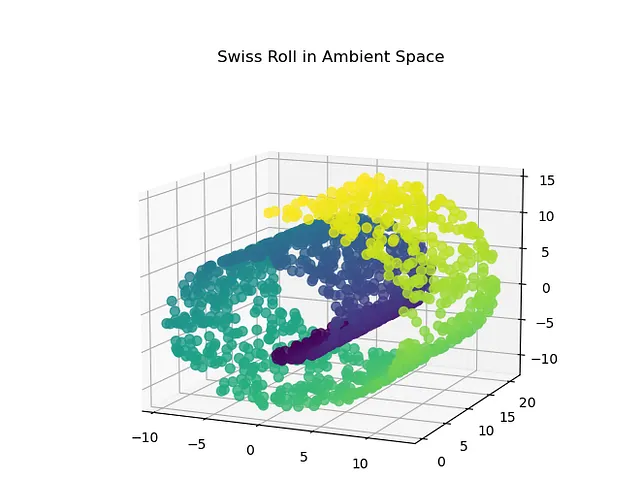
Consideriamo un esempio del dataset Swiss Roll per comprendere l’apprendimento di varietà. Come mostrato nella visualizzazione del dataset Swiss Roll sopra, non è possibile trovare la proiezione dei dati senza sovrapporre molte istanze di dati tra loro. Quindi, in questo tipo di caso, anziché proiettare sul sottospazio inferiore, srotoliamo questi dati. Ciò significa che srotoleremo i punti dati mostrati sopra in un piano 2D e poi ne trarremo un senso.
Ora cerchiamo di capire uno dei metodi di riduzione dimensionale più popolari e ampiamente utilizzati noto come Principal Component Analysis (PCA).
PCA è un metodo di proiezione. Trova prima l’iperpiano più vicino ad esso e poi proietta i dati su di esso.
Ci sono due modi per trovare l’iperpiano corretto per la proiezione:
- Trovare l’iperpiano che preserva la massima quantità di varianza del dataset originale dopo averlo proiettato sull’iperpiano.
- Trovare l’iperpiano che fornisce il valore più basso della distanza quadratico media tra il dataset originale e la sua proiezione sull’iperpiano.
Nota che utilizziamo la varianza come misura perché la varianza del dataset rappresenta la quantità di informazione che contiene.
PCA trova gli assi (ovvero i componenti principali) dell’iperpiano che contribuiscono alla maggior quantità di varianza.
Capiremo il modo in cui si può eseguire questo. Per la dimostrazione di PCA, utilizzeremo il dataset sulla qualità del vino.
Metodo 1
In questo metodo, addestreremo la classe PCA con le sue impostazioni predefinite e poi scopriremo la varianza contribuita da ciascuno dei componenti principali. Quindi scopriremo il numero di componenti principali che forniscono la maggior quantità di varianza con la loro aggiunta. Successivamente, utilizzeremo questo numero ideale di componenti principali per addestrare nuovamente la classe PCA.
## Importazione delle librerie richiesteimport numpy as npimport pandas as pdfrom sklearn.decomposition import PCAimport matplotlib.pyplot as pltimport seaborn as sns## Lettura dei datiwine = pd.read_csv('percorso-del-dataset')wine.head()
## Suddivisione dei dati in caratteristiche indipendenti e dipendentiX, y = wine.drop('qualità', axis=1), wine['qualità']## Metodo 1pca = PCA()pca.fit(X)cumsum = np.cumsum(pca.explained_variance_ratio_)no_of_principal_components = np.argmax(cumsum >= 0.95) + 1print(f"Numero di componenti principali: {no_of_principal_components}\n\nSomma cumulativa del rapporto di varianza: {cumsum}.")
sns.set_style('darkgrid')plt.plot(list(range(1, 12)), cumsum, color='c', marker='x')plt.xlabel("Numero di componenti principali")plt.ylabel("Rapporto cumulativo di varianza")plt.title("Trovare un numero ideale di componenti principali")plt.grid(True)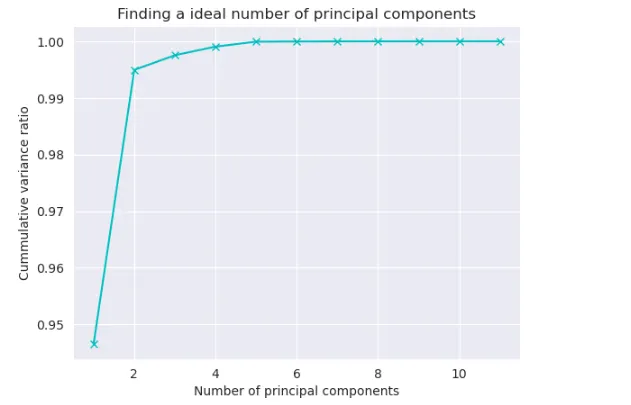
pca = PCA(n_components=2)X_reduced = pca.fit_transform(X)X_reduced
Metodo 2
Invece di trovare il numero ideale di componenti principali, possiamo impostare il valore di n_components come un valore float tra 0 e 1. Questo valore indica la quantità di varianza che si desidera preservare dopo la riduzione.
pca = PCA(n_components = 0.95)X_reduced = pca.fit_transform(X)X_reduced
Decomprimere i dati
È anche possibile decomprimere i dati nelle loro dimensioni originali utilizzando la funzione inverse_transform. Ovviamente, questo non ci darà il dataset originale poiché abbiamo perso una parte delle informazioni (circa il 5%) nel processo di riduzione. Tuttavia, questa decompressione ci darà un dataset molto simile al dataset originale.
pseudo_original_data = pca.inverse_transform(X_reduced)pseudo_original_data
Esistono molte varianti dell’algoritmo PCA: Randomized PCA, Incremental PCA, Kernel PCA, ecc. Inoltre, oltre a questo popolare algoritmo PCA, esistono molti altri algoritmi di riduzione della dimensionalità come isomap, t-distributed stochastic neighbor embedding (t-SNE), linear discriminant analysis (LDA), ecc.
Spero che ti piaccia l’articolo. Se hai qualche pensiero sull’articolo, fammelo sapere. Ogni feedback costruttivo è molto apprezzato. Collegati con me su LinkedIn. Scrivimi a [email protected]. Buona giornata!





