Progetto RedPajama un’iniziativa open-source per democratizzare gli LLM
RedPajama project open-source initiative to democratize LLM.
Guidare il progetto per potenziare la comunità attraverso modelli di linguaggio ampi accessibili.

Nel recente passato, i Large Language Models o LLM hanno dominato il mondo. Con l’introduzione di ChatGPT, ora tutti possono beneficiare del modello di generazione di testo. Ma molti modelli potenti sono disponibili solo a pagamento, lasciando molto della grande ricerca e personalizzazione dietro.
Ci sono, naturalmente, molti progetti che cercano ora di rendere completamente open-source molti dei LLMs. Progetti come Pythia, Dolly, DLite e molti altri sono alcuni esempi. Ma perché cercare di rendere open-source i LLMs? È un sentimento della comunità che ha spinto tutti questi progetti a colmare la limitazione che il modello chiuso porta. Tuttavia, i modelli open-source sono inferiori rispetto a quelli chiusi? Certo che no. Molti modelli possono competere con i modelli commerciali e mostrare risultati promettenti in molte aree.
- Tecniche avanzate di selezione delle caratteristiche per i modelli di apprendimento automatico.
- Falcon LLM Il nuovo re degli LLM open-source.
- AI Grandi Modelli Linguistici e Visivi
Per seguire questo movimento, uno dei progetti open-source per democratizzare i LLMs è il RedPajama. Che cos’è questo progetto e come può beneficiare la comunità? Esploriamo questo ulteriormente.
RedPajama
RedPajama è un progetto di collaborazione tra Ontocord.ai, ETH DS3Lab, Stanford CRFM e Hazy Research per sviluppare LLMs open-source riproducibili. Il progetto RedPajama contiene tre traguardi, tra cui:
- Dati di pre-formazione
- Modelli base
- Dati di sintonizzazione dell’istruzione e modelli
Quando questo articolo è stato scritto, il progetto RedPajama aveva sviluppato i dati di pre-formazione e i modelli, compresi le versioni di base, istruite e chat.
Dati pre-formazione RedPajama
Nel primo passaggio, RedPajama cerca di replicare l’insieme di dati LLaMa del modello semi-aperto. Ciò significa che RedPajama cerca di costruire dati di pre-formazione con 1,2 trilioni di token e renderlo completamente open-source per la comunità. Attualmente, i dati completi e i dati di esempio possono essere scaricati su HuggingFace.
Le fonti di dati per l’insieme di dati RedPajama sono riassunte nella tabella qui sotto. 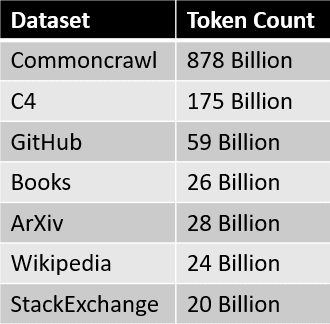 Dove ogni fetta di dati è pre-elaborata e filtrata con cura, il numero di token corrisponde approssimativamente al numero riportato nella carta LLaMa.
Dove ogni fetta di dati è pre-elaborata e filtrata con cura, il numero di token corrisponde approssimativamente al numero riportato nella carta LLaMa.
Il passo successivo dopo la creazione dell’insieme di dati è lo sviluppo dei modelli base.
Modelli RedPajama
Nelle settimane successive alla creazione dell’insieme di dati RedPajama, è stato rilasciato il primo modello addestrato sull’insieme di dati. I modelli base hanno due versioni: un modello con 3 miliardi di parametri e un modello con 7 miliardi di parametri. Il progetto RedPajama rilascia anche due varianti di ciascun modello di base: modelli sintonizzati sull’istruzione e modelli di chat.
Il riassunto di ogni modello può essere visto nella tabella qui sotto. 
Puoi accedere ai modelli sopra utilizzando i seguenti link:
- RedPajama-INCITE-Base-3B-v1
- RedPajama-INCITE-Chat-3B-v1
- RedPajama-INCITE-Instruct-3B-v1
- RedPajama-INCITE-Base-7B-v0.1
- RedPajama-INCITE-Chat-7B-v0.1
- RedPajama-INCITE-Instruct-7B-v0.1
Proviamo il modello di base RedPajama. Ad esempio, proveremo il modello di base RedPajama 3B con il codice adattato da HuggingFace.
import torch
import transformers
from transformers import AutoTokenizer, AutoModelForCausalLM
# init
tokenizer = AutoTokenizer.from_pretrained(
"togethercomputer/RedPajama-INCITE-Base-3B-v1"
)
model = AutoModelForCausalLM.from_pretrained(
"togethercomputer/RedPajama-INCITE-Base-3B-v1", torch_dtype=torch.bfloat16
)
# infer
prompt = "Madre Teresa è"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
input_length = inputs.input_ids.shape[1]
outputs = model.generate(
**inputs,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.7,
top_k=50,
return_dict_in_generate=True
)
token = outputs.sequences[0, input_length:]
output_str = tokenizer.decode(token)
print(output_str)
una santa cattolica nota per il suo lavoro con i poveri e i morenti a Calcutta, in India. Nata a Skopje, in Macedonia, nel 1910, era la più giovane di tredici figli. I suoi genitori morirono quando aveva solo otto anni, e fu cresciuta dal fratello maggiore, che era un prete. Nel 1928, entrò nell'Ordine delle Suore di Loreto in Irlanda. Diventò insegnante e poi suora, e si dedicò a prendersi cura dei poveri e dei malati. Era nota per il suo lavoro con i poveri e i morenti a Calcutta, in India.Il risultato del modello di base 3B è promettente, ma potrebbe essere ancora migliore se utilizziamo il modello di base 7B. Poiché lo sviluppo è ancora in corso, il progetto potrebbe avere in futuro un modello ancora migliore.
Conclusioni
L’IA generativa sta emergendo, ma purtroppo molti ottimi modelli sono ancora bloccati negli archivi delle aziende. RedPajama è uno dei principali progetti che cercano di replicare il modello semi-aperto LLama per democratizzare gli LLM. Sviluppando un dataset simile a LLama, RedPajama è riuscito a creare un dataset open-source di 1,2 trilioni di token che molti progetti open-source hanno utilizzato.
RedPajama rilascia anche due tipi di modelli: modelli di base con parametri 3B e 7B, dove ogni modello di base contiene modelli di istruzioni e di chat. Cornellius Yudha Wijaya è un assistente responsabile della scienza dei dati e scrittore di dati. Mentre lavora a tempo pieno presso Allianz Indonesia, ama condividere consigli su Python e dati tramite i social media e i media scritti.