Padroneggiare l’arte della pulizia dei dati in Python
Padroneggiare l'arte della pulizia dei dati in Python Guida completa

La pulizia dei dati è una parte fondamentale di qualsiasi processo di analisi dei dati. È il passaggio in cui si eliminano gli errori, si gestiscono i dati mancanti e si verifica che i dati siano in un formato con cui si può lavorare. Senza un set di dati ben pulito, qualsiasi analisi successiva può essere distorta o errata.
Questo articolo ti introduce a diverse tecniche chiave per la pulizia dei dati in Python, utilizzando potenti librerie come pandas, numpy, seaborn e matplotlib.
- Chi è Harry Potter? All’interno del metodo di affinamento di Microsoft Research per dissociare i concetti nelle LLM
- Affinamento, Riformazione e Oltre Avanzare con LLM Personalizzati
- OpenAI mira a una presenza più audace nell’arena dello sviluppatore
Comprendere l’importanza della pulizia dei dati
Prima di entrare nei dettagli della pulizia dei dati, comprendiamo la sua importanza. I dati del mondo reale sono spesso disordinati. Possono contenere voci duplicate, tipi di dati incorretti o inconsistenti, valori mancanti, caratteristiche irrilevanti e valori anomali. Tutti questi fattori possono portare a conclusioni fuorvianti durante l’analisi dei dati. Questo rende la pulizia dei dati una parte indispensabile del ciclo di vita della scienza dei dati.
Tratteremo i seguenti compiti di pulizia dei dati. 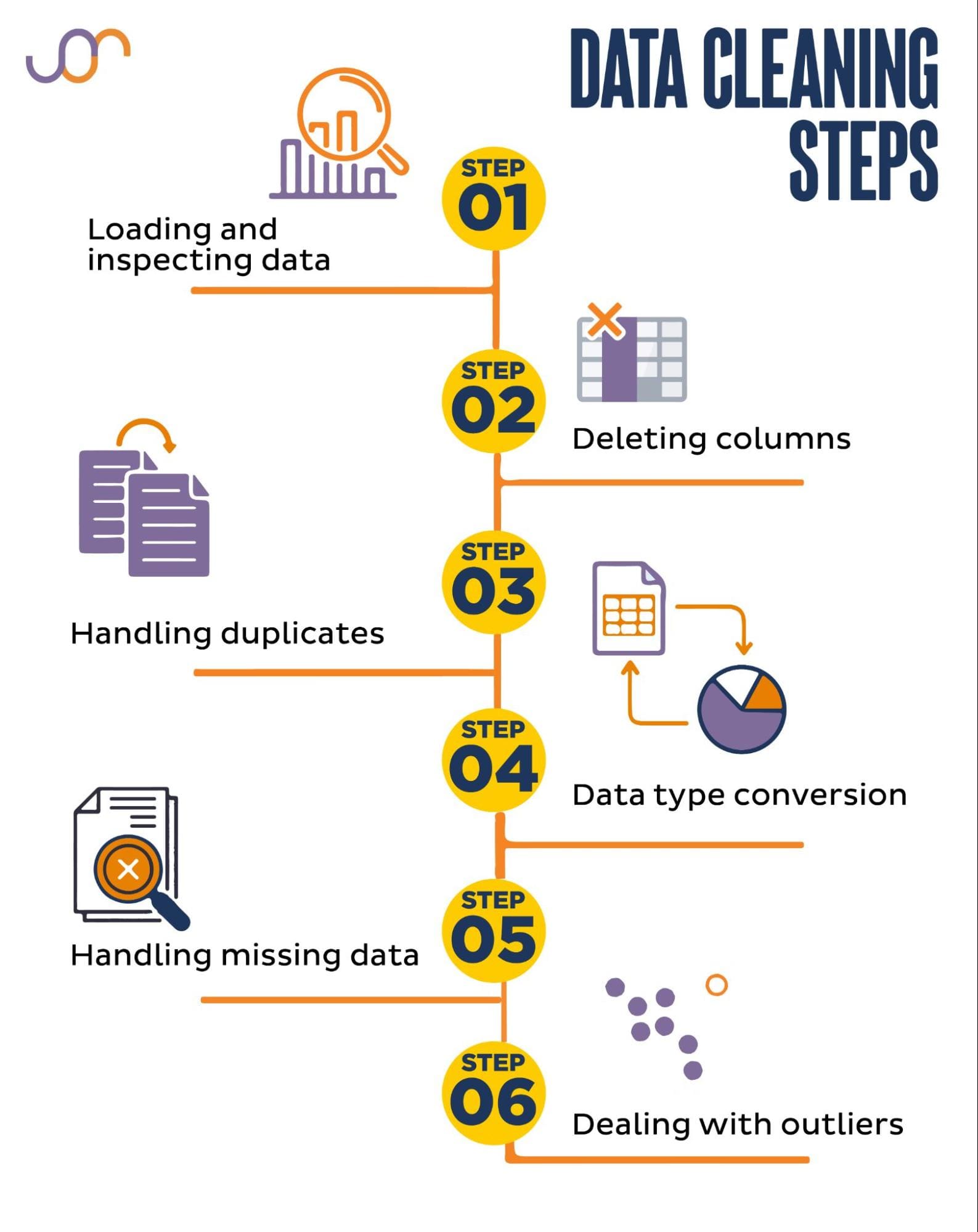
Preparazione per la pulizia dei dati in Python
Prima di iniziare, importiamo le librerie necessarie. Utilizzeremo pandas per la manipolazione dei dati e seaborn e matplotlib per le visualizzazioni.
Importeremo anche il modulo datetime di Python per la manipolazione delle date.
import pandas as pdimport seaborn as snsimport datetime as dtimport matplotlib.pyplot as pltimport matplotlib.ticker as ticker
Caricamento e ispezione dei dati
Prima di tutto, dovremo caricare i nostri dati. In questo esempio, caricheremo un file CSV utilizzando pandas. Aggiungiamo anche l’argomento delimitatore.
df = pd.read_csv('F:\\VoAGI\\KDN Mastering the Art of Data Cleaning in Python\\property.csv', delimiter= ';')
In seguito, è importante ispezionare i dati per comprendere la loro struttura, con quali tipi di variabili stiamo lavorando e se vi sono valori mancanti. Poiché i dati importati non sono enormi, diamo un’occhiata all’intero dataset.
# Guarda tutte le righe del dataframe
display(df)
Ecco come appare il dataset.
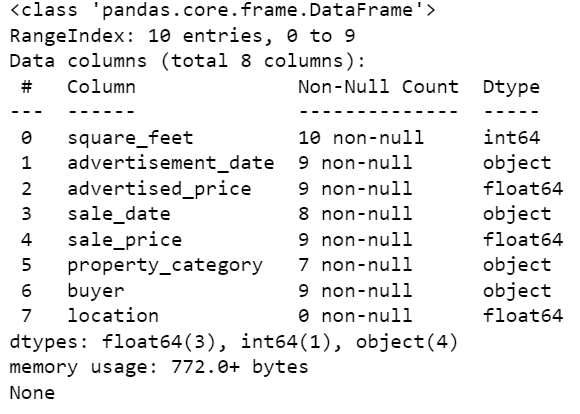
Puoi immediatamente vedere che ci sono alcuni valori mancanti. Inoltre, i formati delle date sono inconsistenti.
Ora, diamo un’occhiata al riepilogo del DataFrame utilizzando il metodo info().
# Ottieni un riepilogo sintetico del dataframe
print(df.info())
Ecco l’output del codice.
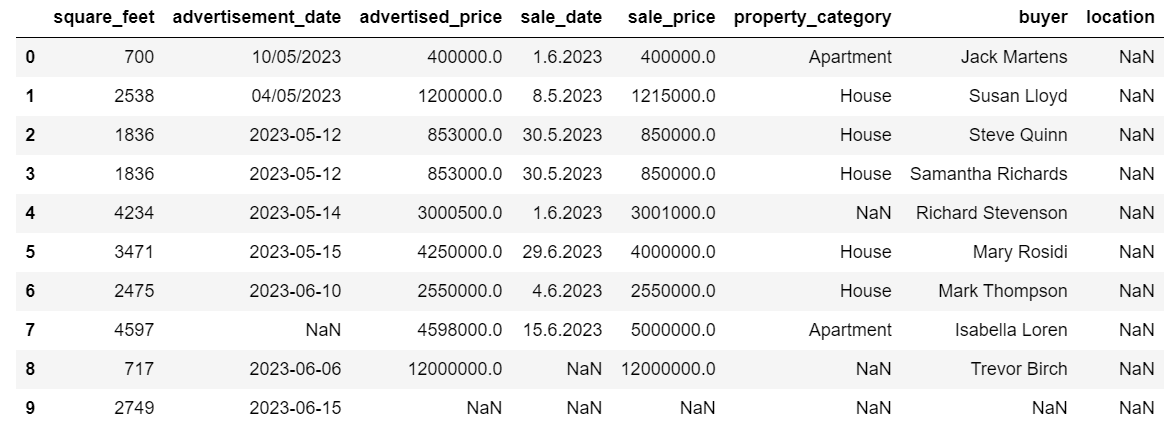
Possiamo vedere che solo la colonna square_feet non ha valori NULL, quindi dovremo gestire in qualche modo questo. Inoltre, le colonne advertisement_date e sale_date sono di tipo di dati object, anche se dovrebbero essere date.
La colonna location è completamente vuota. Ne abbiamo bisogno?
Ti mostreremo come gestire questi problemi. Inizieremo imparando come eliminare colonne non necessarie.
Eliminazione delle colonne non necessarie
Nel dataset ci sono due colonne che non ci servono per l’analisi dei dati, quindi le rimuoveremo.
La prima colonna è acquirente. Non ne abbiamo bisogno, in quanto il nome dell’acquirente non influisce sull’analisi.
Utilizziamo il metodo drop() con il nome specificato della colonna. Impostiamo l’asse su 1 per specificare che vogliamo eliminare una colonna. Inoltre, l’argomento inplace è impostato su True in modo che modifichiamo il DataFrame esistente e non creiamo un nuovo DataFrame senza la colonna rimossa.
df.drop('acquirente', axis = 1, inplace = True)
La seconda colonna che vogliamo rimuovere è la posizione. Anche se potrebbe essere utile avere queste informazioni, questa è una colonna completamente vuota, quindi rimuoviamola semplicemente.
Prendiamo lo stesso approccio della prima colonna.
df.drop('location', axis = 1, inplace = True)
Ovviamente, puoi rimuovere contemporaneamente queste due colonne.
df = df.drop(['buyer', 'location'], axis=1)
Entrambi gli approcci restituiscono il seguente dataframe.
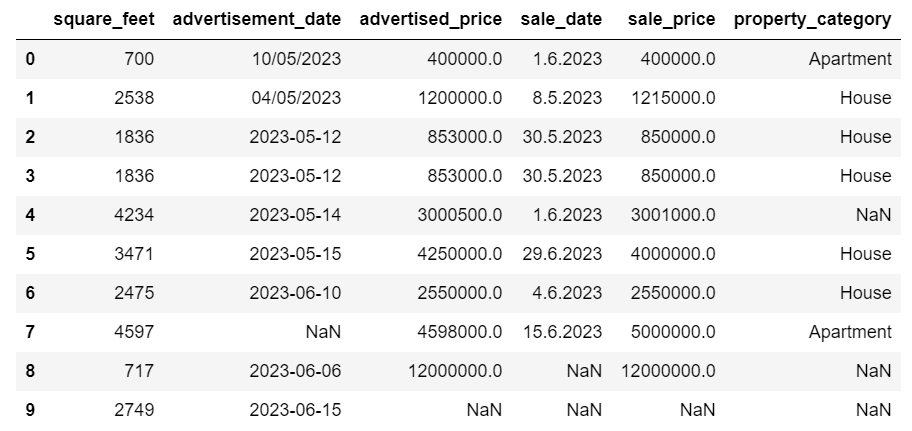
Gestione dei dati duplicati
I dati duplicati possono verificarsi nel tuo dataset per vari motivi e possono alterare la tua analisi.
Scopriamo i duplicati nel nostro dataset. Ecco come fare.
Il codice seguente utilizza il metodo duplicated() per considerare i duplicati nell’intero dataset. L’impostazione predefinita è quella di considerare la prima occorrenza di un valore come unica e le occorrenze successive come duplicati. Puoi modificare questo comportamento utilizzando il parametro keep. Ad esempio, df.duplicated(keep=False) segnalerà tutti i duplicati come True, inclusa la prima occorrenza.
# Rilevare i duplicatiduplicates = df[df.duplicated()]duplicates
Ecco l’output.

La riga con indice 3 è stata segnalata come duplicata perché la riga 2 con gli stessi valori è la sua prima occorrenza.
Ora dobbiamo rimuovere i duplicati, che facciamo con il seguente codice.
# Rilevare i duplicatiduplicates = df[df.duplicated()]duplicates
La funzione drop_duplicates() considera tutte le colonne durante l’identificazione dei duplicati. Se vuoi considerare solo determinate colonne, puoi passarle come elenco a questa funzione in questo modo: df.drop_duplicates(subset=[‘colonna1’, ‘colonna2’]).
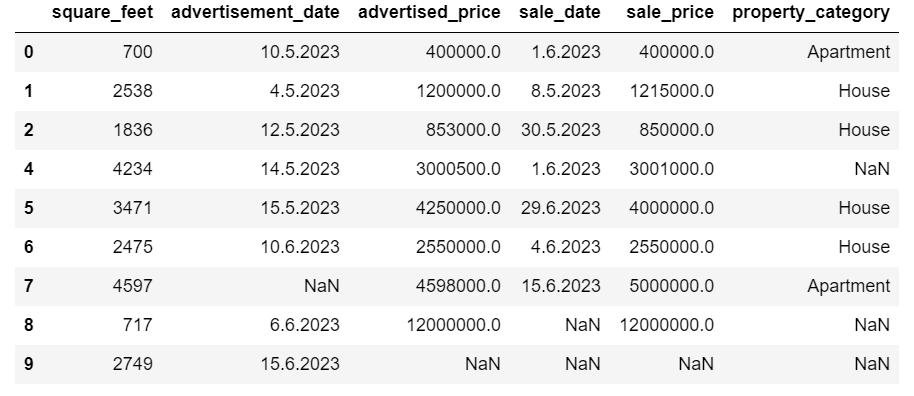
Come puoi vedere, la riga duplicata è stata eliminata. Tuttavia, l’indicizzazione è rimasta invariata, con l’indice 3 mancante. Rimedieremo a questo resettando gli indici.
df = df.reset_index(drop=True)
Questa operazione viene eseguita utilizzando la funzione reset_index(). L’argomento drop=True viene utilizzato per eliminare l’indice originale. Se non includi questo argomento, il vecchio indice verrà aggiunto come nuova colonna nel tuo DataFrame. Impostando drop=True, indichi a pandas di dimenticare il vecchio indice e ripristinarlo all’indice intero predefinito.
Per fare pratica, prova a rimuovere i duplicati da questo dataset di Microsoft.
Conversione dei tipi di dati
A volte, i tipi di dati potrebbero essere impostati in modo errato. Ad esempio, una colonna di date potrebbe essere interpretata come stringhe. È necessario convertirle nei tipi appropriati.
Nel nostro dataset, lo faremo per le colonne advertisement_date e sale_date, in quanto sono mostrate come tipo di dati oggetto. Inoltre, le date sono formattate in modo diverso tra le righe. Dobbiamo renderle coerenti e convertirle in date.
Il modo più semplice è utilizzare il metodo to_datetime(). Di nuovo, puoi farlo colonna per colonna, come mostrato di seguito.
Nel farlo, impostiamo l’argomento dayfirst su True perché alcune date iniziano con il giorno.
# Convertire la colonna advertisement_date in datetimedf['advertisement_date'] = pd.to_datetime(df['advertisement_date'], dayfirst = True)# Convertire la colonna sale_date in datetimedf['sale_date'] = pd.to_datetime(df['sale_date'], dayfirst = True)
Puoi anche convertire entrambe le colonne contemporaneamente utilizzando il metodo apply() con to_datetime().
# Convertire le colonne advertisement_date e sale_date in datetimedf[['advertisement_date', 'sale_date']] = df[['advertisement_date', 'sale_date']].apply(pd.to_datetime, dayfirst = True)
Entrambi gli approcci ti danno lo stesso risultato.
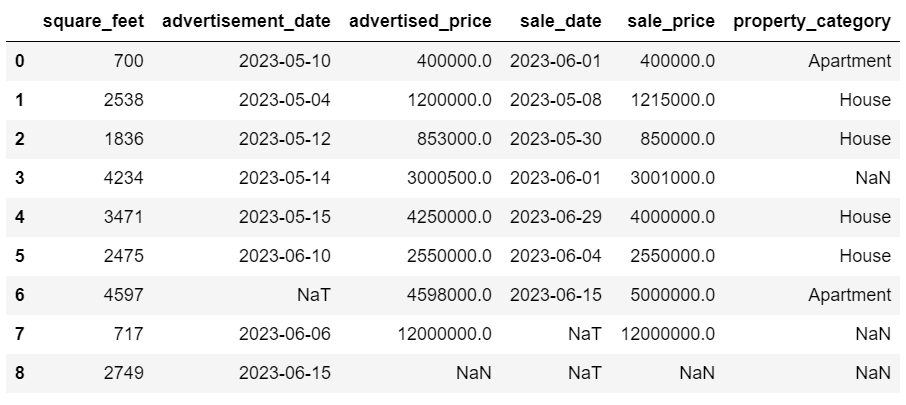
Ora le date sono in un formato coerente. Vediamo che non tutti i dati sono stati convertiti. C’è un valore NaT in advertisement_date e due in sale_date. Ciò significa che la data manca.
Verifichiamo se le colonne sono convertite in date utilizzando il metodo info().
# Ottieni un riassunto conciso del dataframeprint(df.info())
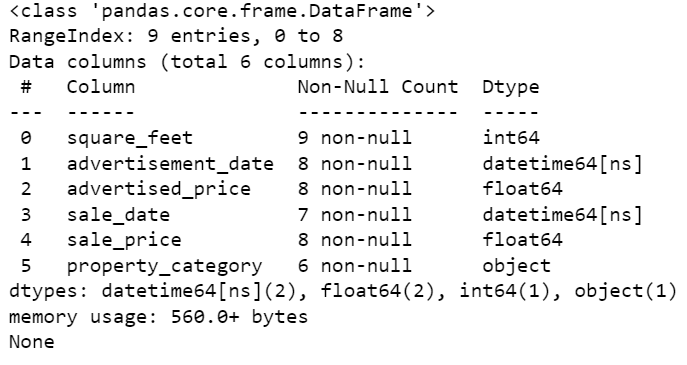
Come puoi vedere, entrambe le colonne non sono nel formato datetime64[ns].
Ora, prova a convertire i dati da TEXT a NUMERIC in questo dataset Airbnb.
Gestione dei dati mancanti
I dataset del mondo reale spesso hanno valori mancanti. La gestione dei dati mancanti è fondamentale, poiché alcuni algoritmi non possono gestire tali valori.
Il nostro esempio ha anche alcuni valori mancanti, quindi diamo un’occhiata agli approcci più comuni per gestire i dati mancanti.
Eliminare le righe con valori mancanti
Se il numero di righe con dati mancanti è insignificante rispetto al numero totale di osservazioni, potresti considerare l’eliminazione di queste righe.
Nel nostro esempio, l’ultima riga non ha valori eccetto i piedi quadrati e la data di inserzione. Non possiamo utilizzare tali dati, quindi rimuoviamo questa riga.
Ecco il codice in cui indichiamo l’indice della riga.
df = df.drop(8)
Ora il DataFrame appare così.
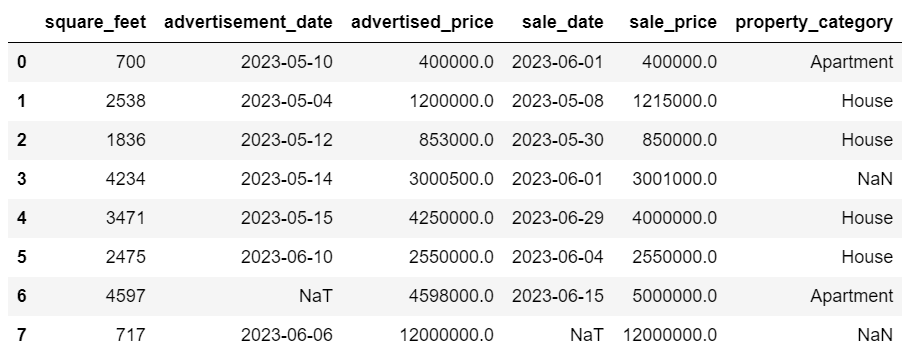
L’ultima riga è stata eliminata e il nostro DataFrame ora appare migliore. Tuttavia, ci sono ancora dei dati mancanti che affronteremo utilizzando un altro approccio.
Imputazione dei valori mancanti
Se hai dati mancanti significativi, una strategia migliore rispetto all’eliminazione potrebbe essere l’imputazione. Questo processo comporta il riempimento dei valori mancanti basandosi su altri dati. Per i dati numerici, i metodi comuni di imputazione prevedono l’utilizzo di una misura di centralità (media, mediana, moda).
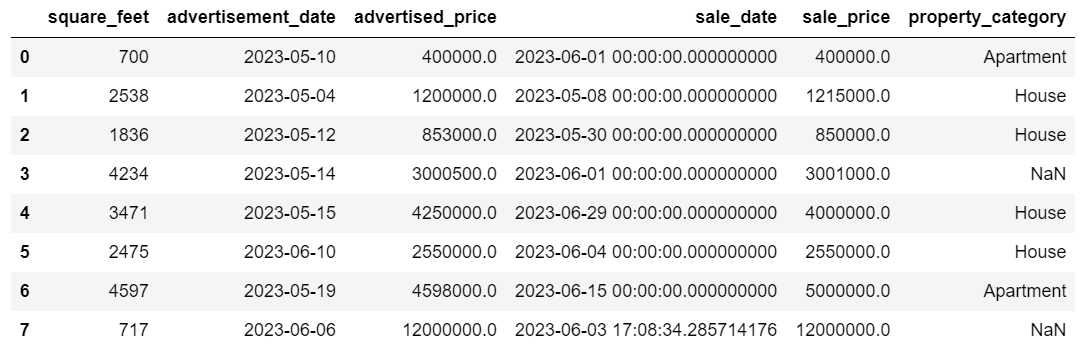
Nel nostro DataFrame già modificato, abbiamo valori NaT (Not a Time) nelle colonne advertisement_date e sale_date. Imputeremo questi valori mancanti utilizzando il metodo mean().
Il codice utilizza il metodo fillna() per trovare e compilare i valori null con il valore medio.
# Imputazione dei valori per le colonne numeriche
df['advertisement_date'] = df['advertisement_date'].fillna(df['advertisement_date'].mean())
df['sale_date'] = df['sale_date'].fillna(df['sale_date'].mean())
Puoi anche fare la stessa cosa in una riga di codice. Utilizziamo apply() per applicare la funzione definita utilizzando lambda. Come sopra, questa funzione utilizza i metodi fillna() e mean() per compilare i valori mancanti.
# Imputazione dei valori per più colonne numeriche
df[['advertisement_date', 'sale_date']] = df[['advertisement_date', 'sale_date']].apply(lambda x: x.fillna(x.mean()))
L’output in entrambi i casi appare così.
Ora la nostra colonna sale_date ha tempi che non ci servono. Rimuoviamoli.
Utilizzeremo il metodo strftime(), che converte le date nella loro rappresentazione in stringa e un formato specifico.
df['sale_date'] = df['sale_date'].dt.strftime('%Y-%m-%d') 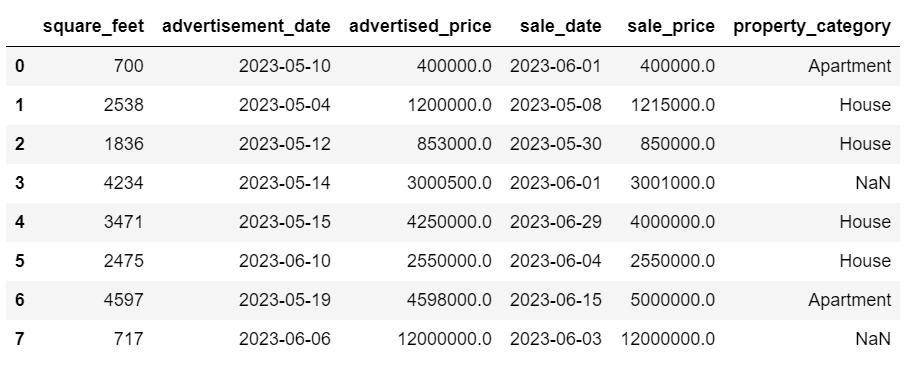
Le date ora sembrano tutte ordinate.
Se è necessario utilizzare strftime() su più colonne, è possibile utilizzare nuovamente lambda nel seguente modo.
df[['data_trasformata1', 'data_trasformata2']] = df[['data1', 'data2']].apply(lambda x: x.dt.strftime('%Y-%m-%d'))Ora, vediamo come possiamo imputare i valori categorici mancanti.
I dati categorici sono un tipo di dati utilizzato per raggruppare informazioni con caratteristiche simili. Ogni gruppo è una categoria. I dati categorici possono assumere valori numerici (come “1” che indica “maschio” e “2” che indica “femmina”), ma questi numeri non hanno un significato matematico. Ad esempio, non è possibile sommarli insieme.
I dati categorici sono tipicamente divisi in due categorie:
- Dati nominali: Questo accade quando le categorie sono solo etichettate e non possono essere ordinate in un ordine particolare. Esempi includono il genere (maschio, femmina), il gruppo sanguigno (A, B, AB, O) o il colore (rosso, verde, blu).
- Dati ordinali: Questo accade quando le categorie possono essere ordinate o classificate. Sebbene gli intervalli tra le categorie non siano equidistanti, l’ordine delle categorie ha un significato. Esempi includono scale di valutazione (valutazione da 1 a 5 di un film), livello di istruzione (scuola superiore, laurea, laurea magistrale) o stadi del cancro (stadio I, stadio II, stadio III).
Per imputare i dati categorici mancanti, di solito viene utilizzata la moda. Nel nostro esempio, la colonna property_category è una categoria di dati categorici (nominali) e ci sono dati mancanti in due righe.
Sostituiamo i valori mancanti con la moda.
# Per colonne categorichedf['property_category'] = df['property_category'].fillna(df['property_category'].mode()[0])Questo codice utilizza la funzione fillna() per sostituire tutti i valori NaN nella colonna property_category. Lo sostituisce con la moda.
Inoltre, la parte [0] viene utilizzata per estrarre il primo valore da questa serie. Se ci sono più mode, selezionerà la prima. Se c’è solo una moda, funziona comunque bene.
Ecco il risultato.
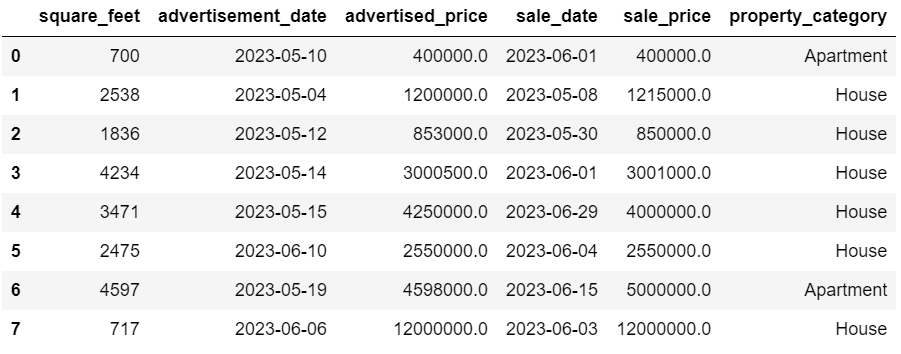
I dati ora sembrano abbastanza buoni. L’unica cosa che resta è vedere se ci sono degli outlier.
Puoi praticare la gestione dei valori nulli su questadomanda di colloquio Meta, in cui dovrai sostituire i NULL con zeri.
Gestione degli Outlier
Gli outlier sono punti dati in un dataset che sono nettamente diversi dalle altre osservazioni. Possono trovarsi eccezionalmente lontani dai valori degli altri dati, al di fuori di un modello generale. Sono considerati insoliti a causa del fatto che i loro valori sono significativamente più alti o più bassi rispetto al resto dei dati.
Gli outlier possono verificarsi per vari motivi come:
- Errori di misurazione o input
- Corruzione dei dati
- Veri anomalie statistiche
Gli outlier possono influire significativamente sui risultati dell’analisi dei dati e sulla modellazione statistica. Possono portare a una distribuzione distorta, a un bias, o invalidate le premesse statistiche sottostanti, distorcere l’adattamento del modello stimato, ridurre l’accuratezza predittiva dei modelli predittivi e portare a conclusioni errate.
Alcuni metodi comunemente utilizzati per rilevare gli outlier sono lo Z-score, l’IQR (Intervallo interquartile), i box plot, i scatter plot e le tecniche di visualizzazione dei dati. In alcuni casi avanzati, vengono utilizzati anche metodi di apprendimento automatico.
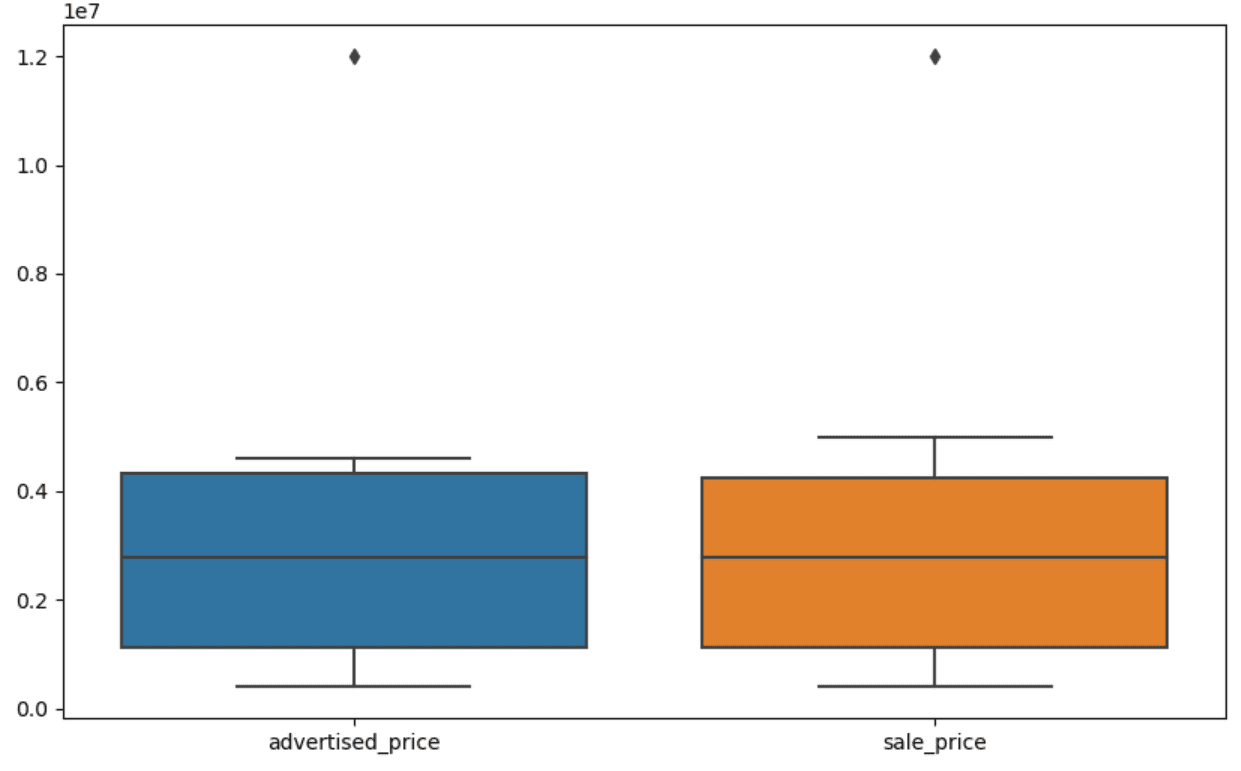
La visualizzazione dei dati può aiutare a identificare gli outlier. Il boxplot di Seaborn è utile per questo.
plt.figure(figsize=(10, 6))
sns.boxplot(data=df[['prezzo_pubblicizzato', 'prezzo_vendita']])Utilizziamo plt.figure() per impostare la larghezza e l’altezza della figura in pollici.
Poi creiamo il boxplot per le colonne prezzo_pubblicizzato e prezzo_vendita, che appare così.
Il grafico può essere migliorato per un uso più semplice aggiungendo questo al codice sopra.
plt.xlabel ('Prezzi') plt.ylabel ('USD') plt.ticklabel_format (style = 'plain', asse = 'y') formatter = ticker.FuncFormatter (lambda x, p: format (x, ',.2f')) plt.gca (). yaxis.set_major_formatter (formatter)
Usiamo il codice sopra per impostare le etichette per entrambi gli assi. Notiamo anche che i valori sull’asse y sono nella notazione scientifica e non possiamo usarla per i valori dei prezzi. Quindi cambiamo questo stile in uno stile normale usando la funzione plt.ticklabel_format ().
Poi creiamo il formato che mostrerà i valori sull’asse y con virgole come separatore delle migliaia e punti decimali. L’ultima riga di codice applica questo all’asse.
Ora l’output appare così.
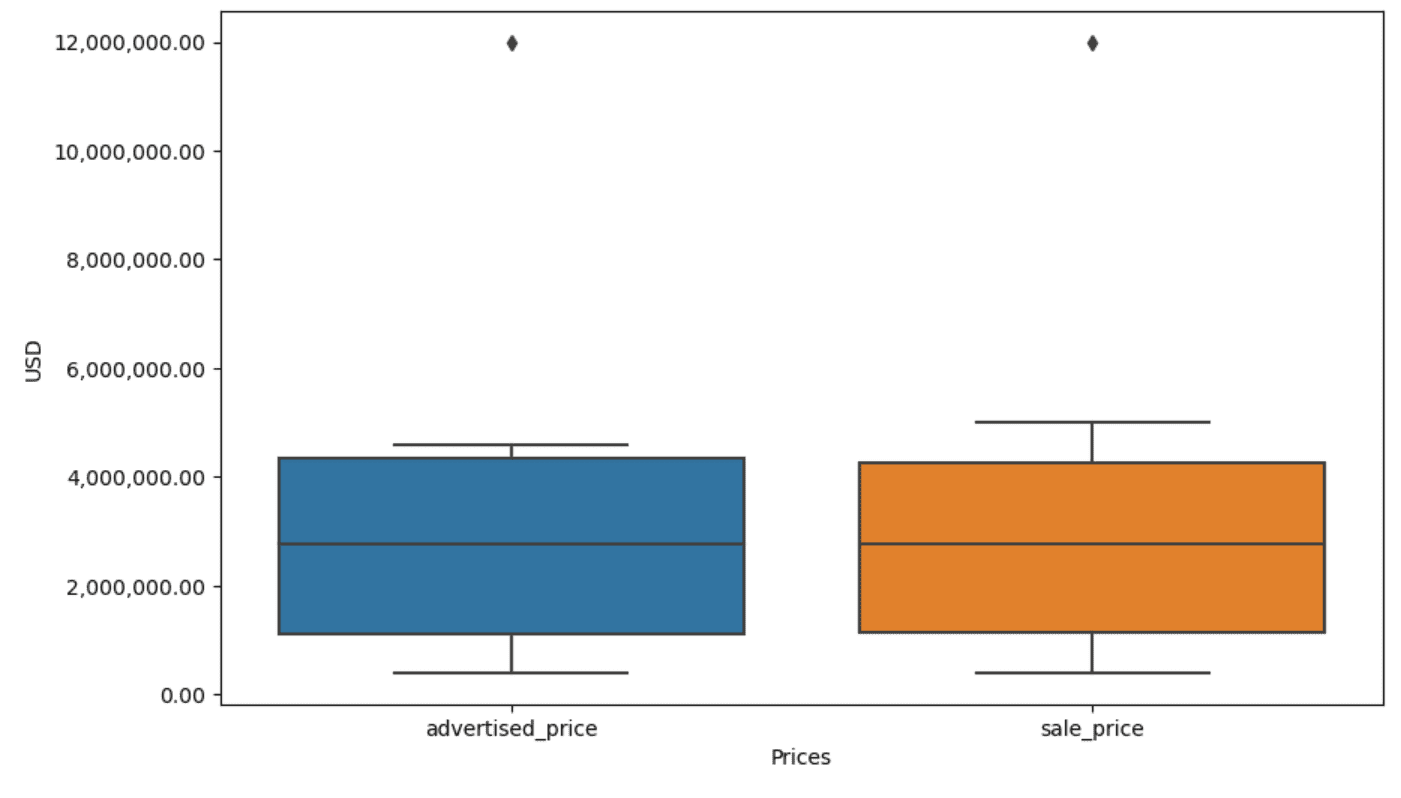
Ora, come identifichiamo e rimuoviamo l’outlier?
Uno dei modi è usare il metodo IQR.
IQR, o gamma interquartile, è un metodo statistico utilizzato per misurare la variabilità dividendo un set di dati in quartili. I quartili dividono un set di dati ordinati per rango in quattro parti uguali e i valori all’interno dell’intervallo del primo quartile (25 ° percentile) e del terzo quartile (75 ° percentile) costituiscono il range interquartile.
L’intervallo interquartile viene utilizzato per identificare gli outlier nei dati. Ecco come funziona:
- Prima, calcola il primo quartile (Q1), il terzo quartile (Q3) e quindi determina l’IQR. L’IQR è calcolato come Q3 – Q1.
- Qualsiasi valore inferiore a Q1 – 1,5 IQR o superiore a Q3 + 1,5 IQR è considerato un outlier.
Nel nostro boxplot, la scatola rappresenta effettivamente l’IQR. La linea all’interno della scatola è la mediana (o secondo quartile). Le ‘whiskers’ del boxplot rappresentano l’intervallo all’interno di 1,5 * IQR da Q1 e Q3.
I punti dati al di fuori di queste whiskers possono essere considerati outlier. Nel nostro caso, è il valore di $ 12.000.000. Se guardi il boxplot, vedrai quanto chiaramente questo è rappresentato, il che mostra perché la visualizzazione dei dati è importante per individuare gli outlier.
Ora, rimuoviamo gli outlier utilizzando il metodo IQR nel codice Python. Prima, rimuoviamo gli outlier del prezzo pubblicizzato.
Q1 = df ['advertised_price']. quantile (0.25) Q3 = df ['advertised_price']. quantile (0.75) IQR = Q3 - Q1 df = df [~ ((df ['advertised_price'] & lt; (Q1 - 1,5 * IQR)) | (df ['advertised_price'] & gt; (Q3 + 1,5 * IQR)))]
Calcoliamo prima il primo quartile (o il 25 ° percentile) utilizzando la funzione quantile () . Facciamo lo stesso per il terzo quartile o il 75 ° percentile.
Questi mostrano i valori al di sotto dei quali cade il 25% e il 75% dei dati, rispettivamente.
Quindi calcoliamo la differenza tra i quartili. Fino ad ora si tratta solo di tradurre i passaggi IQR nel codice Python.
Come ultimo passaggio, rimuoviamo gli outlier. In altre parole, tutti i dati inferiori a Q1 – 1,5 * IQR o superiori a Q3 + 1,5 * IQR.
L’operatore ‘~’ nega la condizione, quindi rimaniamo solo con i dati che non sono outlier.
Poi possiamo fare lo stesso con il prezzo di vendita.
Q1 = df ['sale_price']. quantile (0.25) Q3 = df ['sale_price']. quantile (0.75) IQR = Q3 - Q1 df = df [~ ((df ['sale_price'] & lt; (Q1 - 1,5 * IQR)) | (df ['sale_price'] & gt; (Q3 + 1,5 * IQR)))]
Certo, puoi farlo in modo più succinto utilizzando il for loop.
for column in ['advertised_price', 'sale_price']: Q1 = df[column].quantile(0.25) Q3 = df[column].quantile(0.75) IQR = Q3 - Q1 df = df[~((df[column] < (Q1 - 1.5 * IQR)) |(df[column] > (Q3 + 1.5 * IQR)))]
Il loop itera su due colonne. Per ogni colonna, calcola l’IQR e quindi rimuove le righe nel DataFrame.
Si prega di notare che questa operazione viene eseguita in modo sequenziale, prima per advertised_price e poi per sale_price. Di conseguenza, il DataFrame viene modificato sul posto per ogni colonna e possono essere rimossi la righe considerate come outlier in una qualsiasi delle colonne. Pertanto, questa operazione potrebbe risultare in meno righe rispetto alla rimozione indipendente degli outlier per advertised_price e sale_price e alla combinazione dei risultati in seguito.
Nel nostro esempio, l’output sarà lo stesso in entrambi i casi. Per vedere come cambia il box plot, è necessario plottarlo di nuovo utilizzando lo stesso codice di prima.
plt.figure(figsize=(10, 6))sns.boxplot(data=df[['advertised_price', 'sale_price']])plt.xlabel('Prezzi')plt.ylabel('USD')plt.ticklabel_format(style='plain', axis='y')formatter = ticker.FuncFormatter(lambda x, p: format(x, ',.2f'))plt.gca().yaxis.set_major_formatter(formatter)
Ecco l’output.
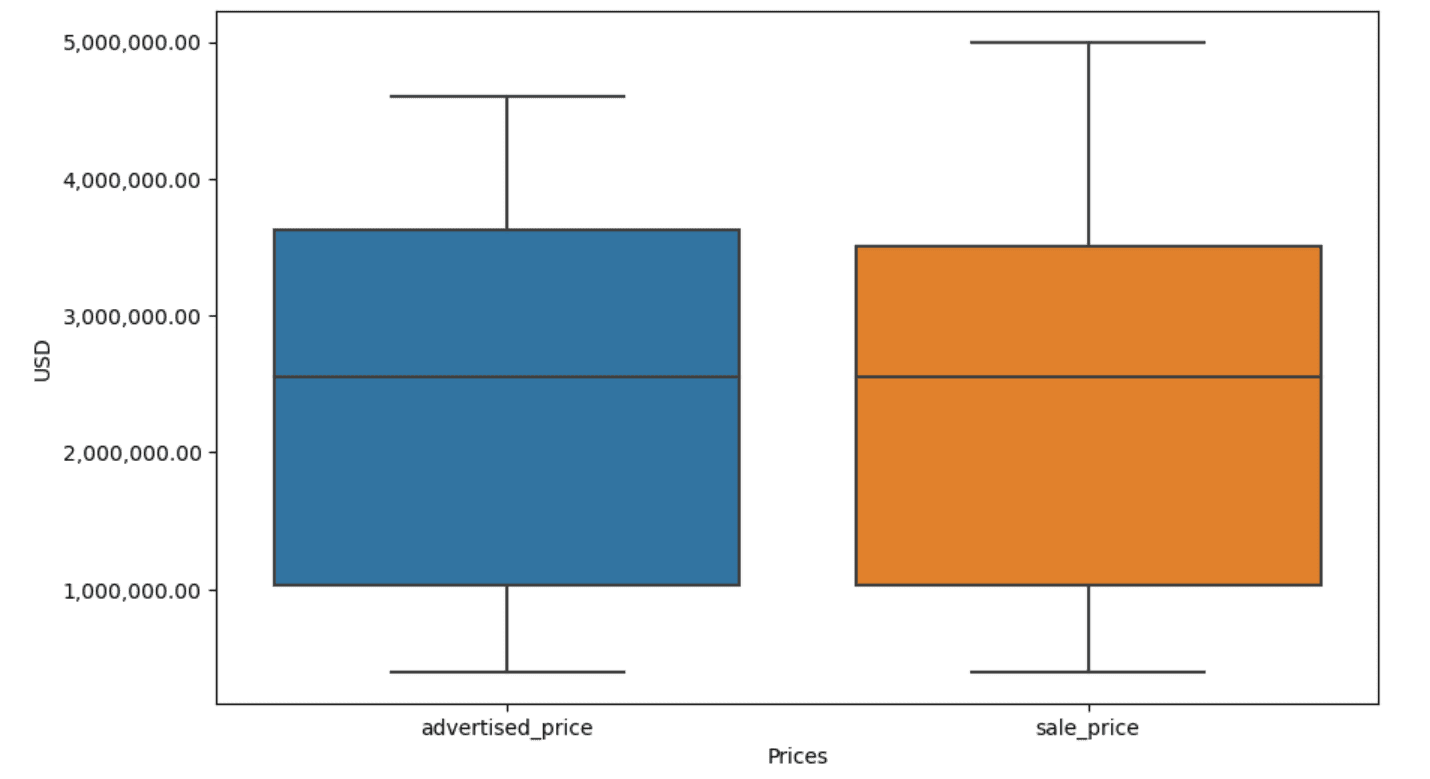
Puoi esercitarti nel calcolo dei percentile in Python risolvendo la domanda di intervista di General Assembly.
Conclusioni
La pulizia dei dati è un passo cruciale nel processo di analisi dei dati. Anche se può richiedere molto tempo, è essenziale per garantire l’accuratezza dei tuoi risultati.
Fortunatamente, l’ampio ecosistema di librerie di Python rende questo processo più gestibile. Abbiamo imparato come rimuovere righe e colonne superflue, riformattare i dati e gestire i valori mancanti e gli outlier. Questi sono i passaggi usuali che devono essere eseguiti su quasi tutti i dati. Tuttavia, a volte sarà necessario anche combunare due colonne in una, verificare i dati esistenti, assegnare etichette ad esso o eliminare gli spazi bianchi.
Tutto ciò è pulizia dei dati, perché ti consente di trasformare dati disordinati e reali in un dataset ben strutturato che puoi analizzare con fiducia. Basta confrontare il dataset con cui abbiamo iniziato con quello che abbiamo ottenuto alla fine.
Se non vedi la soddisfazione di questo risultato e i dati puliti non ti fanno stranamente eccitare, cosa stai facendo nel campo della scienza dei dati!?
****[Nate Rosidi](https://twitter.com/StrataScratch)**** è un data scientist con esperienza nella strategia del prodotto. È anche un professore a contratto che insegna analisi dati ed è il fondatore di StrataScratch, una piattaforma che aiuta i data scientist a prepararsi per i colloqui di lavoro con vere domande di intervista delle migliori aziende. Connettiti con lui su Twitter: StrataScratch o LinkedIn.






