Prova queste 3 funzioni meno conosciute di Pandas
Prova 3 funzioni meno note di Pandas.
Migliora le tue competenze di elaborazione dei dati utilizzando pandas
Se chiedi a qualsiasi data scientist esperto o ingegnere di machine learning quale sia la parte che richiede più tempo nel loro lavoro? Immagino che molti di loro risponderanno: la pre-elaborazione dei dati – una fase che pulisce i dati e li prepara per l’analisi dei dati sequenziali. La ragione è semplice: spazzatura dentro, spazzatura fuori. Cioè, se non prepari correttamente i dati, le tue “insight” sui dati difficilmente avranno un significato.
Nonostante la fase di pre-elaborazione dei dati possa essere piuttosto noiosa, Pandas fornisce tutte le funzioni essenziali che ci consentono di completare facilmente il nostro lavoro di pulizia dei dati. Tuttavia, a causa della sua versatilità, non tutti gli utenti conoscono tutte le funzionalità che la libreria pandas ha da offrire. In questo articolo, vorrei condividere 3 funzioni meno conosciute, ma molto utili, che puoi provare nei tuoi progetti di data science.
Senza ulteriori indugi, iniziamo.
Nota: Per fornire contesto, supponiamo che tu sia responsabile della gestione e analisi dei dati di un negozio di abbigliamento. Gli esempi mostrati di seguito si basano su questa ipotesi.
- Tutto ciò che devi sapere sull’valutazione di grandi modelli di linguaggio
- Come implementare il clustering gerarchico per campagne di marketing diretto – con codice Python
- Top 40+ Strumenti di Intelligenza Artificiale Generativa (Settembre 2023)
1. explode
La prima funzione che voglio menzionare è explode. Questa funzione è utile quando si lavora con dati in una colonna che contiene liste. Quando si utilizza explode con questa colonna, si creano più righe e si estrae ciascuno degli elementi della lista in righe separate.
Ecco un semplice esempio di codice per mostrarti come utilizzare la funzione explode. Supponiamo che tu abbia un dataframe che memorizza le informazioni sugli ordini. In questa tabella, hai una colonna (cioè la colonna order) che contiene liste di articoli, come mostrato di seguito:
order_data = { 'customer': ['John', 'Zoe', 'Mike'], 'order': [['Scarpe', 'Pantaloni', 'Cappelli'], ['Giacche', 'Shorts'], ['Cravatte', 'Felpa con cappuccio']]}order_df = pd.DataFrame(order_data)order_df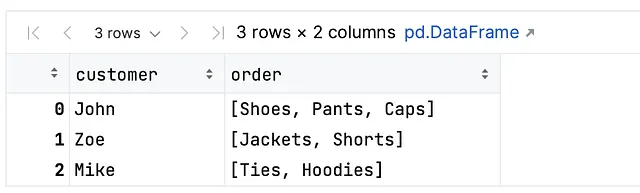
L’operazione necessaria è quella di suddividere ogni elemento della lista in una riga separata per ulteriori elaborazioni dei dati. Senza utilizzare explode, una soluzione ingenua potrebbe essere la seguente. Iteriamo semplicemente le righe originali…