Presentiamo ⚔️ AI vs. AI ⚔️ un sistema di competizione di apprendimento profondo di rinforzo multi-agente.
Presentiamo AI vs. AI, un sistema di competizione di apprendimento profondo di rinforzo multi-agente.
Siamo entusiasti di presentare un nuovo strumento che abbiamo creato: ⚔️ AI vs. AI ⚔️, un sistema di competizione multi-agente di deep reinforcement learning.
Questo strumento, ospitato su Spaces, ci permette di creare competizioni multi-agente. È composto da tre elementi:
- Uno Spazio con un algoritmo di matchmaking che esegue le battaglie tra i modelli utilizzando un task in background.
- Un Dataset che contiene i risultati.
- Una Classifica che prende i risultati della cronologia degli incontri e mostra l’ELO dei modelli.
Quando un utente carica un modello addestrato nell’Hub, viene valutato e classificato rispetto agli altri. Grazie a questo, possiamo valutare i tuoi agenti in un ambiente multi-agente rispetto agli agenti degli altri.
Oltre ad essere uno strumento utile per ospitare competizioni multi-agente, pensiamo che questo strumento possa essere anche una robusta tecnica di valutazione in ambienti multi-agente. Giocando contro molte politiche, i tuoi agenti vengono valutati rispetto a una vasta gamma di comportamenti. Questo dovrebbe darti un’idea della qualità della tua politica.
- Generazione di storie AI per lo sviluppo di giochi #5
- Sintesi del parlato, riconoscimento e altro con SpeechT5
- Sintonizzazione fine efficiente dei parametri utilizzando 🤗 PEFT
Vediamo come funziona con il nostro primo ospite della competizione: SoccerTwos Challenge.
Come funziona AI vs. AI?
AI vs. AI è uno strumento open-source sviluppato da Hugging Face per classificare la forza dei modelli di apprendimento per rinforzo in un ambiente multi-agente.
L’idea è ottenere una misura relativa di abilità anziché una misura oggettiva facendo giocare i modelli l’uno contro l’altro continuamente e utilizzando i risultati degli incontri per valutare le loro prestazioni rispetto a tutti gli altri modelli e ottenere quindi una visione della qualità delle loro politiche senza richiedere metriche classiche.
Più agenti vengono presentati per un dato compito o ambiente, più rappresentativo diventa il rating.
Per generare un rating basato sui risultati degli incontri in un ambiente competitivo, abbiamo deciso di basare la classifica sul sistema di rating ELO.
Il concetto principale è che dopo la fine di un incontro, il rating di entrambi i giocatori viene aggiornato in base al risultato e ai rating che avevano prima della partita. Quando un utente con un rating alto batte uno con un rating basso, non otterranno molti punti. Allo stesso modo, il perdente non perderà molti punti in questo caso.
Al contrario, se un giocatore con un rating basso vince contro un giocatore con un rating alto, avrà un effetto più significativo sui loro rating.
Nel nostro contesto, abbiamo mantenuto il sistema il più semplice possibile senza aggiungere alcuna modifica alle quantità guadagnate o perse in base ai rating iniziali del giocatore. Pertanto, il guadagno e la perdita saranno sempre l’opposto perfetto (+10 / -10, ad esempio), e il rating ELO medio rimarrà costante al rating iniziale. La scelta di un rating ELO di partenza di 1200 è completamente arbitraria.
Se vuoi saperne di più sull’ELO e vedere alcuni esempi di calcolo, abbiamo scritto una spiegazione nel nostro corso di Deep Reinforcement Learning qui
Utilizzando questo rating, è possibile generare incontri tra modelli con forze simili in modo automatico. Ci sono diversi modi per creare un sistema di matchmaking, ma qui abbiamo deciso di mantenerlo abbastanza semplice garantendo al contempo una quantità minima di diversità negli incontri e mantenendo la maggior parte degli incontri con rating opposti abbastanza vicini.
Ecco come funziona l’algoritmo:
- Raccogli tutti i modelli disponibili nell’Hub. I nuovi modelli ottengono un rating di partenza di 1200, mentre gli altri mantengono il rating ottenuto o perso attraverso i loro incontri precedenti.
- Crea una coda con tutti questi modelli.
- Prendi il primo elemento (modello) dalla coda e poi prendi un altro modello casuale in questa coda tra i n modelli con i rating più vicini al primo modello.
- Simula questo incontro caricando entrambi i modelli nell’ambiente (ad esempio un eseguibile Unity) e raccogliendo i risultati. Per questa implementazione, abbiamo inviato i risultati a un Dataset di Hugging Face sull’Hub.
- Calcola il nuovo rating di entrambi i modelli in base al risultato ricevuto e alla formula ELO.
- Continua ad estrarre modelli a coppie e a simulare gli incontri fino a quando nella coda rimane solo un modello o nessuno.
- Salva i rating ottenuti e torna al passaggio 1
Per eseguire questo processo di matchmaking continuamente, utilizziamo l’hardware gratuito di Hugging Face Spaces con uno Scheduler per mantenere in esecuzione il processo di matchmaking come task in background.
Spaces viene utilizzato anche per recuperare i punteggi ELO di ogni modello che è già stato giocato e, da esso, visualizzare una classifica a cui tutti possono controllare il progresso dei modelli.
Il processo utilizza generalmente diversi set di dati di Hugging Face per fornire persistenza dei dati (qui, la cronologia delle partite e i punteggi dei modelli).
Poiché il processo salva anche la cronologia delle partite, è possibile vedere precisamente i risultati di un determinato modello. Ciò può, ad esempio, consentirti di verificare perché il tuo modello ha difficoltà con un altro, soprattutto utilizzando un altro spazio demo per visualizzare le partite come questa.
Per ora, questo esperimento viene eseguito con l’ambiente MLAgent SoccerTwos per il corso Hugging Face Deep RL. Tuttavia, il processo e l’implementazione, in generale, sono molto agnostici rispetto all’ambiente e potrebbero essere utilizzati per valutare gratuitamente una vasta gamma di impostazioni avversariali multi-agente.
Ovviamente, è importante ricordare ancora una volta che questa valutazione è una valutazione relativa tra le capacità degli agenti inviati e i punteggi di per sé non hanno un significato oggettivo contrario ad altre metriche. Rappresenta solo quanto bene o male un modello si comporta rispetto agli altri modelli nel pool. Tuttavia, data una quantità sufficiente di modelli nel pool (e abbastanza partite giocate), questa valutazione diventa un modo molto solido per rappresentare le prestazioni generali di un modello.
La nostra prima sperimentazione di sfida AI vs. AI: SoccerTwos Challenge ⚽
Questa sfida è l’Unità 7 del nostro corso gratuito di Deep Reinforcement Learning. È iniziata il 1º febbraio e terminerà il 30 aprile.
Se sei interessato, non è necessario partecipare al corso per partecipare alla competizione. Puoi iniziare qui 👉 https://huggingface.co/deep-rl-course/unit7/introduction
In questa unità, i lettori hanno imparato le basi del reinforcement learning multi-agente (MARL) addestrando una squadra di calcio 2vs2. ⚽
L’ambiente utilizzato è stato creato dal team Unity ML-Agents. L’obiettivo è semplice: la tua squadra deve segnare un gol. Per farlo, devono battere la squadra avversaria e collaborare con il proprio compagno di squadra.
Oltre alla classifica, abbiamo creato una demo dello spazio in cui le persone possono scegliere due squadre e visualizzarle giocare 👉 https://huggingface.co/spaces/unity/SoccerTwos
Questa sperimentazione sta procedendo bene poiché abbiamo già 48 modelli nella classifica 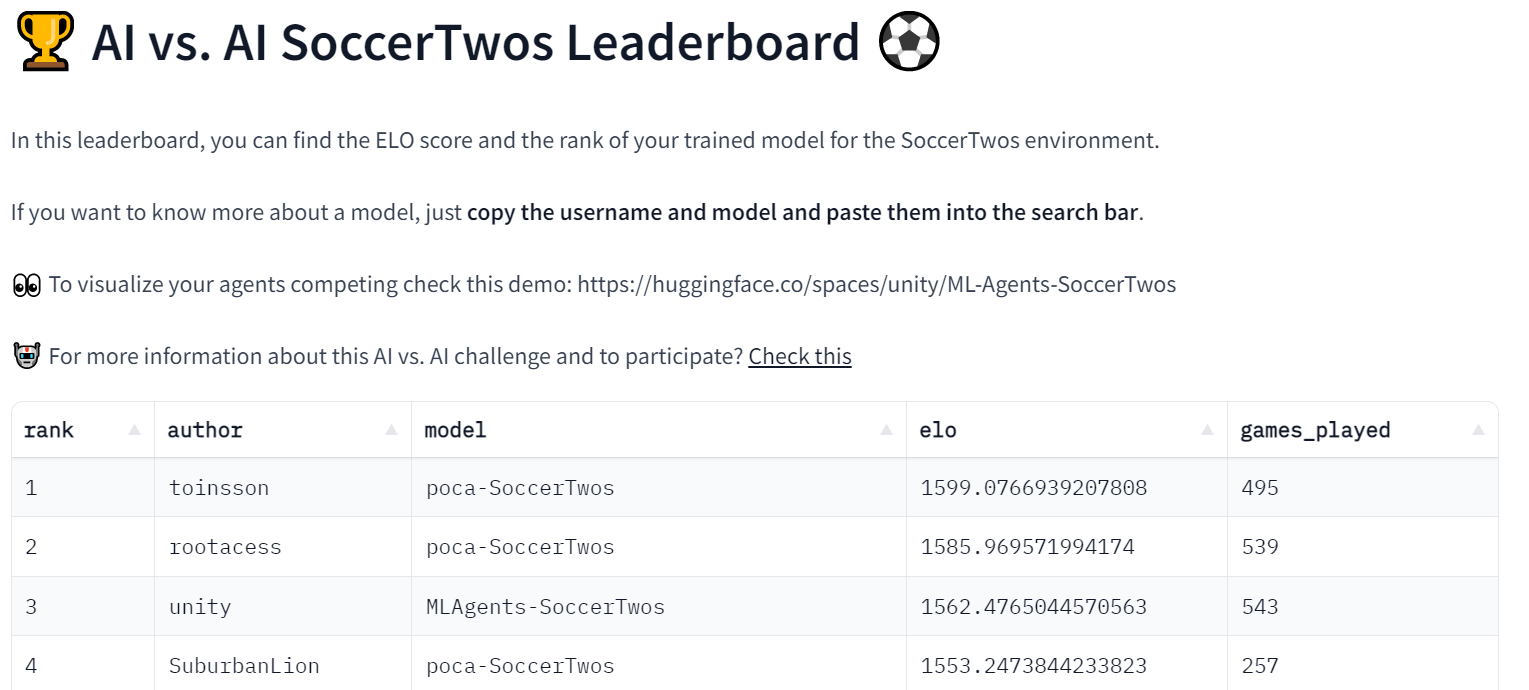
Abbiamo anche creato un canale discord chiamato ai-vs-ai-competition in modo che le persone possano scambiarsi opinioni e consigliare.
Conclusioni e cosa succederà dopo?
Dato che lo strumento che abbiamo sviluppato è agnostico rispetto all’ambiente, vogliamo ospitare più sfide in futuro con PettingZoo e altri ambienti multi-agente. Se hai degli ambienti o delle sfide che vuoi fare, non esitare a contattarci.
In futuro, ospiteremo molte competizioni multi-agente con questo strumento e gli ambienti che abbiamo creato, come SnowballFight.
Oltre ad essere uno strumento utile per ospitare competizioni multi-agente, pensiamo che questo strumento possa anche essere una robusta tecnica di valutazione in ambienti multi-agente: giocando contro molte politiche, i tuoi agenti vengono valutati in base a una vasta gamma di comportamenti e otterrai una buona idea della qualità della tua politica.
Il modo migliore per rimanere in contatto è unirsi al nostro server Discord per interagire con noi e con la community.
****************Citazione****************
Citazione: se hai trovato utile questo lavoro per la tua ricerca accademica, considera di citare il nostro lavoro, nel testo:
Cochet, Simonini, "Introducing AI vs. AI a deep reinforcement learning multi-agents competition system", Hugging Face Blog, 2023.
Citazione BibTeX:
@article{cochet-simonini2023,
author = {Cochet, Carl and Simonini, Thomas},
title = {Introducing AI vs. AI a deep reinforcement learning multi-agents competition system},
journal = {Hugging Face Blog},
year = {2023},
note = {https://huggingface.co/blog/aivsai},
}