Parliamo di pregiudizi nell’apprendimento automatico! Newsletter sull’etica e la società #2
'Pregiudizi nell'apprendimento automatico! Newsletter etica e società #2'
Il pregiudizio nell’apprendimento automatico (ML) è ubiquo e complesso; così complesso, infatti, che nessuna singola intevenzione tecnica è in grado di affrontare in modo significativo i problemi che genera. I modelli di ML, come sistemi sociotecnici, amplificano le tendenze sociali che possono esacerbare le disuguaglianze e i pregiudizi dannosi in modi che dipendono dal contesto in cui sono utilizzati e che sono in costante evoluzione.
Ciò significa che lo sviluppo di sistemi di ML con cura richiede vigilanza e risposta ai feedback provenienti dai contesti in cui vengono utilizzati, cosa che possiamo facilitare condividendo lezioni tra contesti diversi e sviluppando strumenti per analizzare segni di pregiudizio ad ogni livello della fase di sviluppo di ML.
Questo post del blog scritto dai membri della comunità @🤗 di Etica e Società condivide alcune delle lezioni apprese insieme agli strumenti che abbiamo sviluppato per supportare noi stessi e gli altri nei nostri sforzi per affrontare in modo migliore il pregiudizio nell’apprendimento automatico. La prima parte è una riflessione più ampia sul pregiudizio e il suo contesto. Se l’hai già letto e stai tornando specificamente per gli strumenti, puoi passare direttamente alla sezione dataset o modelli!
 Selezione degli strumenti sviluppati dai membri del team 🤗 per affrontare il pregiudizio nel ML
Selezione degli strumenti sviluppati dai membri del team 🤗 per affrontare il pregiudizio nel ML
- Schede dei modelli
- Segmentazione delle immagini senza etichette con CLIPSeg
- Segmentazione universale dell’immagine con Mask2Former e OneFormer
Indice:
- Sui pregiudizi dei sistemi di apprendimento automatico
- Pregiudizio dei sistemi di apprendimento automatico: dai sistemi di ML ai rischi
- Inquadramento del pregiudizio
- Strumenti e raccomandazioni
- Affrontare il pregiudizio durante lo sviluppo di ML
- Definizione del compito
- Curazione dei dati
- Addestramento del modello
- Panoramica degli strumenti bias 🤗
- Affrontare il pregiudizio durante lo sviluppo di ML
Pregiudizio dei sistemi di apprendimento automatico: dai sistemi di ML ai rischi personali e sociali
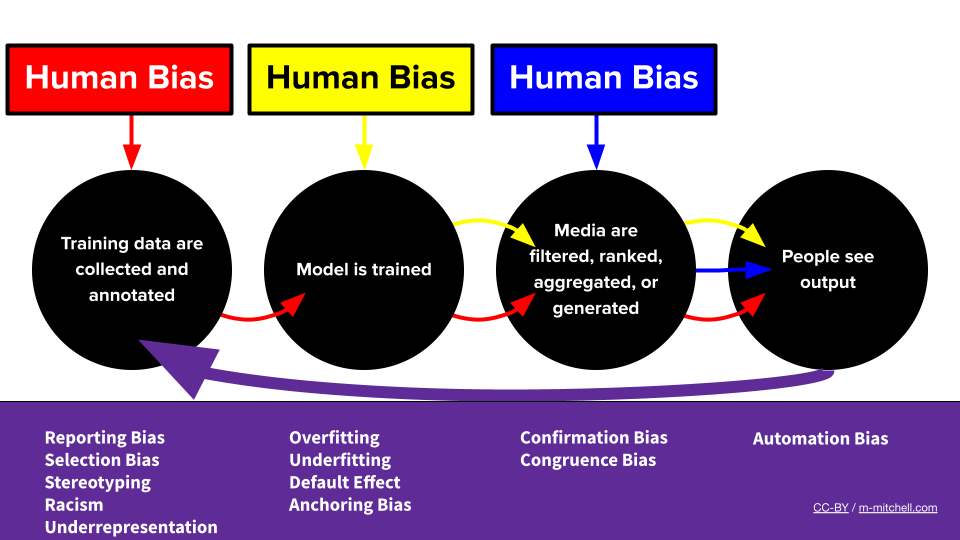
I sistemi di ML ci permettono di automatizzare compiti complessi su una scala mai vista prima, poiché vengono utilizzati in molti settori e casi d’uso. Quando la tecnologia funziona al meglio, può aiutare a facilitare le interazioni tra le persone e i sistemi tecnici, eliminare la necessità di lavori altamente ripetitivi o sbloccare nuovi modi di elaborare informazioni per supportare la ricerca.
Gli stessi sistemi tendono anche a riprodurre comportamenti discriminatori e abusivi rappresentati nei dati di addestramento, specialmente quando i dati codificano comportamenti umani. La tecnologia ha quindi il potenziale per aggravare significativamente questi problemi. L’automazione e l’utilizzo su larga scala possono infatti:
- conservare comportamenti nel tempo e ostacolare il progresso sociale che si riflette nella tecnologia,
- diffondere comportamenti dannosi al di là del contesto dei dati di addestramento originali,
- amplificare le disuguaglianze enfatizzando associazioni stereotipate durante le previsioni,
- rimuovere possibilità di ricorso nascondendo i pregiudizi all’interno di sistemi “black-box”.
Per comprendere e affrontare meglio questi rischi, i ricercatori e sviluppatori di ML hanno iniziato a studiare il pregiudizio dei sistemi di apprendimento automatico o il pregiudizio algoritmico, meccanismi che potrebbero portare i sistemi, ad esempio, a codificare stereotipi o associazioni negative o a avere prestazioni diverse per diversi gruppi di popolazione nel contesto di utilizzo.
Queste questioni sono profondamente personali per molti di noi ricercatori e sviluppatori di ML presso Hugging Face e nell’ampia comunità di ML. Hugging Face è un’azienda internazionale, con molti di noi che esistono tra paesi e culture diverse. È difficile esprimere pienamente il nostro senso di urgenza quando vediamo la tecnologia su cui lavoriamo sviluppata senza una sufficiente attenzione per la protezione di persone come noi; specialmente quando questi sistemi portano a arresti discriminatori ingiusti o a gravi difficoltà finanziarie e vengono sempre più venduti a servizi di immigrazione e forze dell’ordine in tutto il mondo. Allo stesso modo, vedere le nostre identità sistematicamente sopprime nei set di dati di addestramento o sono sottorappresentate nelle uscite dei sistemi di “intelligenza artificiale generativa” collega queste preoccupazioni alle nostre esperienze quotidiane in modo illuminante e gravoso contemporaneamente.
Sebbene le nostre esperienze personali non riescano a coprire le innumerevoli modalità in cui la discriminazione mediata da ML può danneggiare in modo sproporzionato le persone le cui esperienze differiscono dalle nostre, esse offrono un punto di ingresso per considerare i compromessi intrinseci alla tecnologia. Lavoriamo su questi sistemi perché crediamo fermamente nel potenziale del ML – pensiamo che possa brillare come uno strumento prezioso a condizione che venga sviluppato con cura e input da persone nel contesto di utilizzo, anziché come una panacea unica per tutti. In particolare, per consentire questa cura è necessario sviluppare una migliore comprensione dei meccanismi del pregiudizio dei sistemi di apprendimento automatico lungo il processo di sviluppo di ML e sviluppare strumenti che supportino persone con diversi livelli di conoscenza tecnica di questi sistemi nel partecipare alle necessarie conversazioni su come i loro benefici e danni sono distribuiti.
Il presente post del blog da parte degli esperti di Etica e Società di Hugging Face fornisce una panoramica di come abbiamo lavorato, stiamo lavorando o raccomandiamo agli utenti dell’ecosistema di librerie HF di affrontare il bias nelle varie fasi del processo di sviluppo di ML, e gli strumenti che sviluppiamo per supportare questo processo. Speriamo che lo troverete una risorsa utile per guidare considerazioni concrete sull’impatto sociale del vostro lavoro e potete sfruttare gli strumenti citati qui per aiutare a mitigare questi problemi quando si presentano.
Inquadramento del Bias
Il primo e forse il concetto più importante da considerare quando si affronta il bias delle macchine è il contesto. Nel loro lavoro fondamentale sul bias in NLP, Su Lin Blodgett et al. sottolineano che: “[La] maggior parte delle [opere accademiche sul bias delle macchine] non si confronta criticamente con ciò che costituisce” bias “in primo luogo”, incluso costruendo il loro lavoro su “assunzioni non espresse su quali tipi di comportamenti del sistema siano dannosi, in che modo, per chi e perché”.
Questo potrebbe non sorprendere molto dato l’accento della comunità di ricerca di ML sul valore della “generalizzazione” – la motivazione più citata per il lavoro nel campo dopo le “prestazioni”. Tuttavia, sebbene gli strumenti per la valutazione del bias che si applicano a una vasta gamma di contesti siano preziosi per consentire un’analisi più ampia delle tendenze comuni nei comportamenti dei modelli, la loro capacità di mirare ai meccanismi che portano alla discriminazione in casi d’uso concreti è intrinsecamente limitata. Utilizzarli per guidare decisioni specifiche all’interno del ciclo di sviluppo di ML di solito richiede uno o due passaggi aggiuntivi per prendere in considerazione il contesto specifico di utilizzo del sistema e le persone interessate.
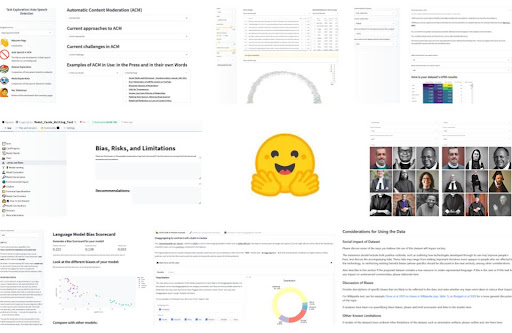
 Estratto sulle considerazioni del contesto d’uso di ML e delle persone dalla Guida alle Model Card
Estratto sulle considerazioni del contesto d’uso di ML e delle persone dalla Guida alle Model Card
Ora approfondiamo la questione del collegamento tra i bias presenti negli artefatti di ML autonomi/senza contesto e i danni specifici. Può essere utile pensare ai bias delle macchine come fattori di rischio per danni basati sulla discriminazione. Prendiamo ad esempio un modello di testo-immagine che sovrarappresenta le tonalità della pelle chiara quando viene sollecitato a creare un’immagine di una persona in un contesto professionale, ma produce tonalità della pelle più scure quando le sollecitazioni menzionano la criminalità. Queste tendenze sarebbero ciò che chiamiamo bias delle macchine a livello di modello. Ora pensiamo a alcuni sistemi che utilizzano un tale modello di testo-immagine:
- Il modello è integrato in un servizio di creazione di siti web (ad esempio, SquareSpace, Wix) per aiutare gli utenti a generare sfondi per le loro pagine. Il modello disabilita esplicitamente le immagini di persone nello sfondo generato.
- In questo caso, il “fattore di rischio” del bias delle macchine non porta a danni discriminatori perché il focus del bias (immagini di persone) è assente nel caso d’uso.
- Non sono richieste ulteriori strategie di mitigazione del bias delle macchine, anche se gli sviluppatori dovrebbero essere consapevoli delle discussioni in corso sulla legalità dell’integrazione di sistemi addestrati su dati raccolti in sistemi commerciali.
- Il modello è integrato in un sito web di immagini di stock per fornire agli utenti immagini sintetiche di persone (ad esempio, in contesti professionali) che possono utilizzare con minori preoccupazioni sulla privacy, ad esempio come illustrazioni per gli articoli di Wikipedia
- In questo caso, il bias delle macchine agisce per rinforzare e amplificare i bias sociali esistenti. Rinforza gli stereotipi sulle persone (“i CEO sono tutti uomini bianchi”) che poi si ripercuotono su sistemi sociali complessi in cui un aumento del bias porta a un aumento della discriminazione in molti modi diversi (come il rafforzamento del bias implicito sul luogo di lavoro).
- Le strategie di mitigazione possono includere l’educazione degli utenti delle immagini di stock su questi bias, oppure il sito web di immagini di stock può selezionare immagini generate per proporre intenzionalmente un insieme più variegato di rappresentazioni.
- Il modello è integrato in un software di “artista virtuale” per schizzi commercializzato presso i dipartimenti di polizia che lo utilizzeranno per generare immagini di sospetti basandosi su testimonianze verbali
- In questo caso, i bias delle macchine causano direttamente discriminazione indirizzando sistematicamente i dipartimenti di polizia a persone dalla pelle più scura, mettendole a rischio di danni, inclusi lesioni fisiche e detenzioni illegali.
- In casi come questo, potrebbe non esistere un livello di mitigazione del bias che renda il rischio accettabile. In particolare, un caso d’uso del genere sarebbe strettamente correlato al riconoscimento facciale nel contesto delle forze dell’ordine, dove problemi di bias simili hanno portato diverse entità commerciali e legislatori ad adottare moratorie che sospendono o vietano il suo utilizzo in generale.
Quindi, chi è responsabile dei bias delle macchine in ML? Questi tre casi illustrano una delle ragioni per cui le discussioni sulla responsabilità degli sviluppatori di ML nel affrontare il bias possono diventare così complesse: a seconda delle decisioni prese in altri punti del processo di sviluppo del sistema di ML da altre persone, i bias in un dataset o modello di ML possono finire ovunque tra essere irrilevanti per le impostazioni dell’applicazione e portare direttamente a danni gravi. Tuttavia, in tutti questi casi, biases più forti nel modello/dataset aumentano il rischio di risultati negativi. L’Unione Europea ha iniziato a sviluppare quadri che affrontano questo fenomeno negli ultimi sforzi normativi: in breve, un’azienda che implementa un sistema AI basato su un modello misurabilmente bias è responsabile dei danni causati dal sistema.
Concettualizzare il pregiudizio come un fattore di rischio ci consente di comprendere meglio la responsabilità condivisa per i pregiudizi delle macchine tra gli sviluppatori in tutte le fasi. Il pregiudizio non può mai essere completamente eliminato, anche perché le definizioni di pregiudizi sociali e le dinamiche di potere che li legano alla discriminazione variano notevolmente nei contesti sociali. Tuttavia:
- Ogni fase del processo di sviluppo, dalla specifica del compito, alla cura del dataset e all’addestramento del modello, all’integrazione del modello e alla distribuzione del sistema, può intraprendere misure per ridurre al minimo gli aspetti del pregiudizio delle macchine** che dipendono più direttamente dalle sue scelte** e decisioni tecniche, e
- La comunicazione chiara e il flusso di informazioni tra le varie fasi dello sviluppo di machine learning possono fare la differenza tra fare scelte che si basano l’una sull’altra per attenuare il potenziale negativo del pregiudizio (approccio multipronged alla mitigazione del pregiudizio, come nello scenario di distribuzione 1 sopra) rispetto a fare scelte che aggravano questo potenziale negativo per aumentare il rischio di danni (come nello scenario di distribuzione 3).
Nella sezione successiva, esamineremo queste varie fasi insieme a alcuni strumenti che possono aiutarci ad affrontare il pregiudizio delle macchine in ognuna di esse.
Affrontare il pregiudizio durante il ciclo di sviluppo di machine learning
Pronto per alcuni consigli pratici? Eccoci 🤗
Non c’è un unico modo per sviluppare sistemi di machine learning; l’ordine delle fasi dipende da diversi fattori, tra cui l’ambiente di sviluppo (università, grande azienda, startup, organizzazione di base, ecc…), la modalità (testo, dati tabulari, immagini, ecc…) e la predominanza o la scarsità di risorse di machine learning disponibili pubblicamente. Tuttavia, possiamo identificare tre fasi comuni di particolare interesse per affrontare il pregiudizio. Queste sono la definizione del compito, la cura dei dati e l’addestramento del modello. Vediamo come l’approccio al pregiudizio può differire in queste varie fasi.
 Il flusso di lavoro del pregiudizio nelle macchine di Meg
Il flusso di lavoro del pregiudizio nelle macchine di Meg
Sto definendo il compito del mio sistema di machine learning, come posso affrontare il pregiudizio?
Se e in che misura il pregiudizio nel sistema influenza concretamente le persone dipende in definitiva da come il sistema viene utilizzato. Pertanto, il primo passo che gli sviluppatori possono compiere per mitigare il pregiudizio è decidere come il machine learning si integra nel loro sistema, ad esempio decidendo quale obiettivo di ottimizzazione utilizzare.
Ad esempio, torniamo a uno dei primi casi molto pubblicizzati di un sistema di machine learning utilizzato in produzione per la raccomandazione di contenuti algoritmici. Dal 2006 al 2009, Netflix ha organizzato il Netflix Prize, una competizione con un premio in denaro di 1 milione di dollari che ha sfidato squadre di tutto il mondo a sviluppare sistemi di machine learning per prevedere accuratamente la valutazione di un utente per un nuovo film in base alle sue valutazioni passate. La presentazione vincente ha migliorato l’RMSE (errore quadratico medio) delle previsioni su coppie utente-film non viste di oltre il 10% rispetto all’algoritmo CineMatch di Netflix, il che significa che è diventato molto più bravo a prevedere come gli utenti valuteranno un nuovo film in base alla loro storia. Questo approccio ha aperto la strada a gran parte della moderna raccomandazione di contenuti algoritmici portando alla conoscenza pubblica il ruolo del machine learning nella modellazione delle preferenze degli utenti nei sistemi di raccomandazione.
Quindi, cosa ha a che fare tutto questo con il pregiudizio? Non sembra che mostrare alle persone contenuti che probabilmente apprezzeranno sia un buon servizio da parte di una piattaforma di contenuti? Beh, si scopre che mostrare alle persone più esempi di ciò che hanno apprezzato in passato finisce per ridurre la diversità dei media che consumano. Non solo porta gli utenti a essere meno soddisfatti a lungo termine, ma significa anche che eventuali pregiudizi o stereotipi catturati dai modelli iniziali, come quando si modellano le preferenze degli utenti afroamericani o le dinamiche che svantaggiano sistematicamente alcuni artisti, sono probabilmente rafforzati se il modello viene ulteriormente addestrato su interazioni utente continua mediata da machine learning. Questo riflette due dei tipi di preoccupazioni legate al pregiudizio che abbiamo menzionato in precedenza: l’obiettivo di addestramento agisce come un fattore di rischio per danni legati al pregiudizio, poiché rende molto più probabile che i pregiudizi preesistenti si manifestino nelle previsioni, e la definizione del compito ha l’effetto di consolidare ed esacerbare i pregiudizi passati.
Una strategia promettente per mitigare il pregiudizio in questa fase è quella di ridefinire il compito per modellare esplicitamente sia l’interesse che la diversità quando si applica il machine learning alla raccomandazione di contenuti algoritmici. Gli utenti probabilmente ottengono una maggiore soddisfazione a lungo termine e si riduce il rischio di esacerbazione dei pregiudizi come descritto in precedenza!
Questo esempio serve ad illustrare che l’impatto dei pregiudizi delle macchine in un prodotto supportato dall’ML dipende non solo da dove decidiamo di utilizzare l’ML, ma anche da come le tecniche di ML sono integrate nel sistema tecnico più ampio e con quale obiettivo. Quando si esplora per la prima volta come l’ML può integrarsi in un prodotto o in un caso d’uso di interesse, consigliamo innanzitutto di cercare i modi in cui il sistema può fallire attraverso il prisma del pregiudizio, prima ancora di approfondire i modelli o i dataset disponibili – quali comportamenti dei sistemi esistenti nello spazio saranno particolarmente dannosi o più probabili da verificarsi se il pregiudizio viene esacerbato dalle previsioni ML?
Abbiamo creato uno strumento per guidare gli utenti attraverso queste domande in un altro caso di gestione automatizzata dei contenuti algoritmici: rilevamento dei discorsi di odio nella moderazione automatica dei contenuti. Abbiamo scoperto, ad esempio, che cercare tra notizie e articoli scientifici che non si concentravano particolarmente sulla parte di tecnologia dell’apprendimento automatico era già un ottimo modo per capire dove si manifesta già il pregiudizio. Dai un’occhiata per vedere un esempio di come i modelli e i set di dati si adattano al contesto di utilizzo e in che modo possono essere correlati ai danni legati al pregiudizio noto!
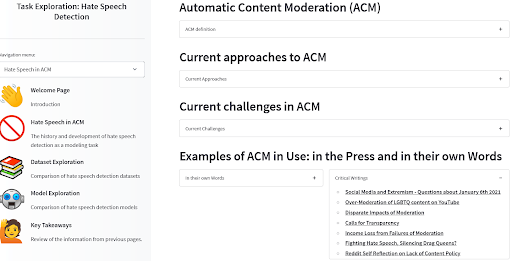 Strumento di Esplorazione delle Attività ACM di Angie, Amandalynne e Yacine
Strumento di Esplorazione delle Attività ACM di Angie, Amandalynne e Yacine
Definizione dell’attività: raccomandazioni
Ci sono tanti modi in cui la definizione e la distribuzione dell’attività di apprendimento automatico possono influire sul rischio di danni legati al pregiudizio, quanti sono le applicazioni per i sistemi di apprendimento automatico. Come nei precedenti esempi, alcuni passaggi comuni che possono aiutare a decidere se e come applicare l’apprendimento automatico in modo da ridurre al minimo il rischio legato al pregiudizio includono:
- Investigare:
- Segnalazioni di pregiudizi nel campo prima dell’apprendimento automatico
- Categorie demografiche a rischio per il tuo caso d’uso specifico
- Esaminare:
- L’impatto del tuo obiettivo di ottimizzazione nel rafforzare i pregiudizi
- Obiettivi alternativi che favoriscono la diversità e gli impatti positivi a lungo termine
Sto curando/selezionando un set di dati per il mio sistema di apprendimento automatico, come posso affrontare il pregiudizio?
Anche se i set di dati di addestramento non sono l’unica fonte di pregiudizio nel ciclo di sviluppo dell’apprendimento automatico, svolgono un ruolo significativo. Il tuo set di dati associa in modo sproporzionato le biografie delle donne agli eventi della vita, ma quelle degli uomini ai successi? Questi stereotipi probabilmente si rifletteranno nel tuo sistema di apprendimento automatico completo! Il tuo set di dati per il riconoscimento vocale presenta solo specifici accenti? Non è un buon segno per l’inclusività della tecnologia che stai costruendo in termini di prestazioni disparate! Che tu stia curando un set di dati per applicazioni di apprendimento automatico o selezionando un set di dati per addestrare un modello di apprendimento automatico, scoprire, mitigare e comunicare in che misura i dati presentano questi fenomeni sono tutti passaggi necessari per ridurre i rischi legati al pregiudizio.
Di solito puoi avere un’idea abbastanza precisa dei pregiudizi probabili in un set di dati riflettendo su dove proviene, chi sono le persone rappresentate nei dati e qual è stato il processo di cura. Sono stati proposti diversi quadri di riflessione e documentazione come Data Statements for NLP o Datasheets for Datasets. L’Hugging Face Hub include un modello di Scheda del Set di Dati e una guida ispirata a queste opere; la sezione sulle considerazioni per l’uso dei dati è di solito un buon punto di riferimento per informazioni sui pregiudizi rilevanti se stai esaminando i set di dati, o per scrivere un paragrafo condividendo le tue intuizioni sull’argomento se stai condividendo un nuovo set di dati. E se cerchi ispirazione su cosa mettere lì, dai un’occhiata a queste sezioni scritte dagli utenti del Hub nell’organizzazione BigLAM per set di dati storici di procedimenti giudiziari, classificazione delle immagini e giornali.
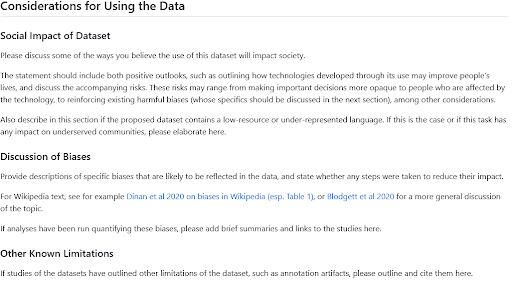 Guida alla Scheda del Set di Dati HF per le Sezioni sull’Impatto Sociale e sul Pregiudizio
Guida alla Scheda del Set di Dati HF per le Sezioni sull’Impatto Sociale e sul Pregiudizio
Anche se descrivere l’origine e il contesto di un set di dati è sempre un buon punto di partenza per capire i pregiudizi in gioco, misurare quantitativamente i fenomeni che codificano quei pregiudizi può essere altrettanto utile. Se devi scegliere tra due diversi set di dati per un determinato compito o tra due modelli di apprendimento automatico addestrati su diversi set di dati, sapere quale rappresenta meglio la composizione demografica della base utenti del tuo sistema di apprendimento automatico può aiutarti a prendere una decisione informata per ridurre al minimo i rischi legati al pregiudizio. Se stai curando un set di dati in modo iterativo, filtrando punti dati da una fonte o selezionando nuove fonti di dati da aggiungere, misurare come queste scelte influenzano la diversità e i pregiudizi presenti nel tuo set di dati complessivo può renderlo più sicuro da utilizzare in generale.
Abbiamo recentemente rilasciato due strumenti che puoi utilizzare per valutare i tuoi dati da una prospettiva informativa sui pregiudizi. La libreria disaggregators🤗 fornisce strumenti per quantificare la composizione del tuo set di dati, utilizzando metadati o sfruttando modelli per dedurre le proprietà dei punti dati. Questo può essere particolarmente utile per ridurre i rischi di danni legati al pregiudizio nella rappresentazione o nelle prestazioni disparate dei modelli addestrati. Dai un’occhiata alla demo per vedere come viene applicata ai set di dati LAION, MedMCQA e The Stack!
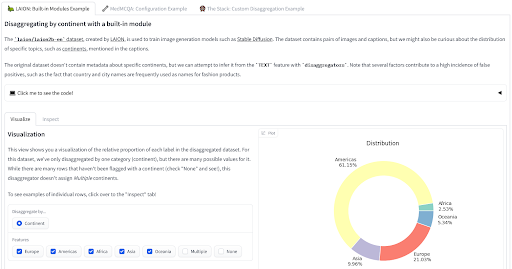 Strumento Disaggregator di Nima
Strumento Disaggregator di Nima
Una volta ottenute alcune statistiche utili sulla composizione del tuo dataset, vorrai anche analizzare le associazioni tra le caratteristiche dei tuoi dati, in particolare le associazioni che possono codificare stereotipi derogatori o negativi. Lo strumento di misurazione dei dati che abbiamo introdotto originariamente l’anno scorso ti consente di farlo analizzando l’Informazione Mutua Puntiforme Normalizzata (nPMI) tra i termini nel tuo dataset basato su testo; in particolare le associazioni tra pronomi di genere che possono indicare stereotipi di genere. Provalo tu stesso o provaci qui su alcuni dataset pre-calcolati!
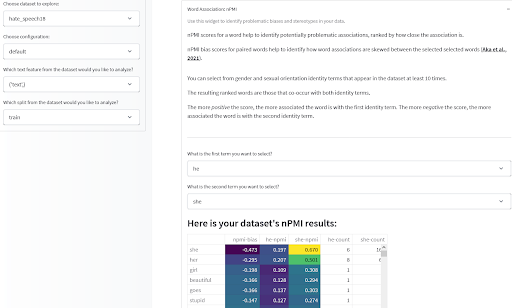 Strumento di misurazione dei dati di Meg, Sasha, Bibi e il team di Gradio
Strumento di misurazione dei dati di Meg, Sasha, Bibi e il team di Gradio
Selezione/curazione del dataset: raccomandazioni
Questi strumenti non sono soluzioni complete di per sé, ma sono progettati per supportare l’esame critico e il miglioramento dei dataset attraverso diverse prospettive, tra cui la prospettiva del bias e dei rischi correlati al bias. In generale, ti incoraggiamo a tenere presente i seguenti passaggi quando utilizzi questi e altri strumenti per mitigare i rischi di bias nella fase di cura/selezione del dataset:
- Identifica:
- Aspetti della creazione del dataset che possono accentuare specifici bias
- Categorie demografiche e variabili sociali particolarmente importanti per il compito e il dominio del dataset
- Misura:
- La distribuzione demografica nel tuo dataset
- Gli stereotipi negativi pre-identificati rappresentati
- Documenta:
- Condividi ciò che hai identificato e misurato nella tua Scheda del Dataset in modo che possa beneficiare altri utenti, sviluppatori e persone interessate in altri modi
- Adatta:
- Scegliendo il dataset meno probabile di causare danni legati al bias
- Migliorando iterativamente il tuo dataset in modi che riducano i rischi di bias
Sto allenando/selezionando un modello per il mio sistema di apprendimento automatico, come posso affrontare il bias?
Similmente alla fase di cura/selezione del dataset, documentare e misurare i fenomeni legati al bias nei modelli può aiutare sia gli sviluppatori di apprendimento automatico che selezionano un modello da usare così com’è o da ottimizzare, sia gli sviluppatori di apprendimento automatico che vogliono addestrare i propri modelli. Per questi ultimi, le misure dei fenomeni legati al bias nel modello possono aiutarli a imparare da ciò che ha funzionato o non ha funzionato per altri modelli e servire come segnale per guidare le loro scelte di sviluppo.
Le Model Cards sono state originariamente proposte da (Mitchell et al., 2019) e forniscono un framework per la segnalazione dei modelli che mostra informazioni rilevanti per i rischi di bias, inclusi ampi considerazioni etiche, valutazione disaggregata e raccomandazioni per casi d’uso. L’Hugging Face Hub fornisce ancora più strumenti per la documentazione dei modelli, con una guida per la creazione di Model Cards nel documento Hub e un’app che ti consente di creare facilmente estese Model Cards per il tuo nuovo modello.
 Strumento di scrittura delle Model Cards di Ezi, Marissa e Meg
Strumento di scrittura delle Model Cards di Ezi, Marissa e Meg
La documentazione è un ottimo primo passo per condividere informazioni generali sul comportamento di un modello, ma di solito è statica e presenta le stesse informazioni a tutti gli utenti. In molti casi, specialmente per i modelli generativi che possono generare output per approssimare la distribuzione dei dati di addestramento, possiamo ottenere una comprensione più contestuale dei fenomeni legati al bias e agli stereotipi negativi visualizzando e confrontando gli output del modello. L’accesso alle generazioni del modello può aiutare gli utenti a portare problemi intersezionali nel comportamento del modello corrispondenti alla loro esperienza vissuta e valutare fino a che punto un modello riproduce stereotipi di genere per diversi aggettivi. Per agevolare questo processo, abbiamo creato uno strumento che ti consente di confrontare le generazioni non solo su un insieme di aggettivi e professioni, ma anche su modelli diversi! Provalo per farti un’idea di quale modello potrebbe comportare il minor rischio di bias nel tuo caso d’uso.
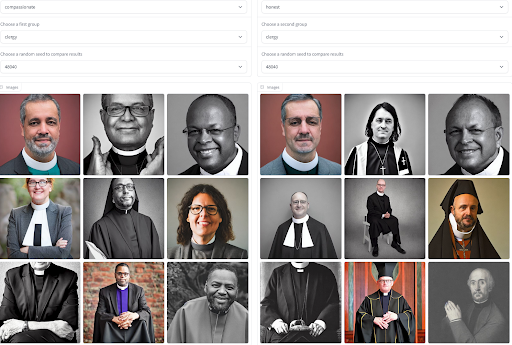 Visualizza i Bias degli Aggettivi e delle Occupazioni nella Generazione di Immagini di Sasha
Visualizza i Bias degli Aggettivi e delle Occupazioni nella Generazione di Immagini di Sasha
La visualizzazione degli output del modello non è riservata solo ai modelli generativi! Per i modelli di classificazione, vogliamo anche prestare attenzione ai danni legati al bias causati da una performance disomogenea del modello su diverse categorie demografiche. Se sai quali classi protette sono più a rischio di discriminazione e le hai annotate in un set di valutazione, allora puoi segnalare la performance disaggregata sulle diverse categorie nella Model Card del tuo modello come sopra menzionato, in modo che gli utenti possano prendere decisioni informate. Se però sei preoccupato di non aver identificato tutte le popolazioni a rischio di danni legati al bias, o se non hai accesso a esempi di test annotati per misurare i bias che sospetti, è qui che entrano in gioco le visualizzazioni interattive di dove e come il modello fallisce! Per aiutarti in questo, l’app SEAL raggruppa errori simili del tuo modello e ti mostra alcune caratteristiche comuni in ogni cluster. Se vuoi andare oltre, puoi anche combinarlo con la libreria disaggregators che abbiamo introdotto nella sezione dei dataset per trovare cluster che sono indicativi di modalità di fallimento legate al bias!
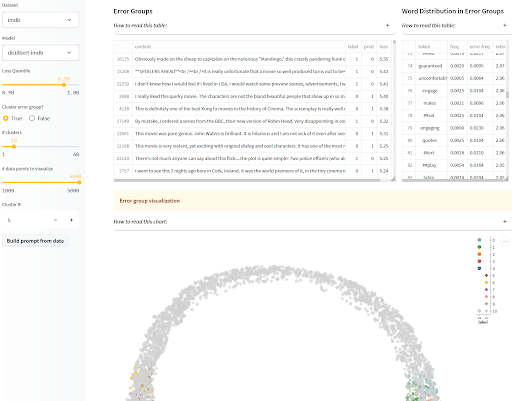 Analisi e etichettatura degli errori sistematici (SEAL) di Nazneen
Analisi e etichettatura degli errori sistematici (SEAL) di Nazneen
Infine, esistono alcuni benchmark che possono misurare fenomeni legati al bias nei modelli. Per i modelli linguistici, benchmark come BOLD, HONEST o WinoBias forniscono valutazioni quantitative di comportamenti mirati che sono indicativi di bias nei modelli. Sebbene i benchmark abbiano le loro limitazioni, forniscono una visione limitata di alcuni rischi di bias pre-identificati che possono aiutare a descrivere il funzionamento dei modelli o a scegliere tra modelli diversi. Puoi trovare queste valutazioni pre-calcolate su una serie di modelli linguistici comuni in questo spazio di esplorazione per avere una prima idea di come si confrontano!
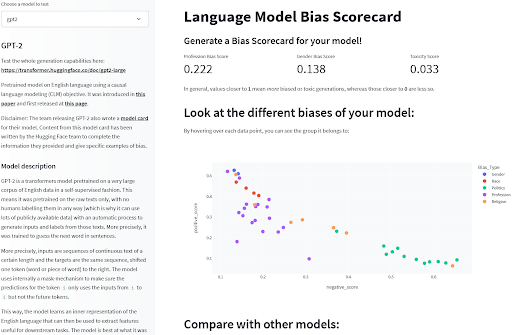 Rilevamento del bias nei modelli di linguaggio di Sasha
Rilevamento del bias nei modelli di linguaggio di Sasha
Anche avendo accesso a un benchmark per i modelli che stai considerando, potresti scoprire che l’esecuzione di valutazioni sui modelli di linguaggio più grandi che stai considerando può essere proibitivamente costosa o altrimenti tecnicamente impossibile con le tue risorse informatiche. Lo strumento Evaluation on the Hub che abbiamo rilasciato quest’anno può aiutarti: non solo eseguirà le valutazioni per te, ma ti aiuterà anche a collegarle alla documentazione del modello in modo che i risultati siano disponibili una volta per tutte, in modo che tutti possano vedere, ad esempio, che la dimensione aumenta misurabilmente i rischi di bias nei modelli come OPT!
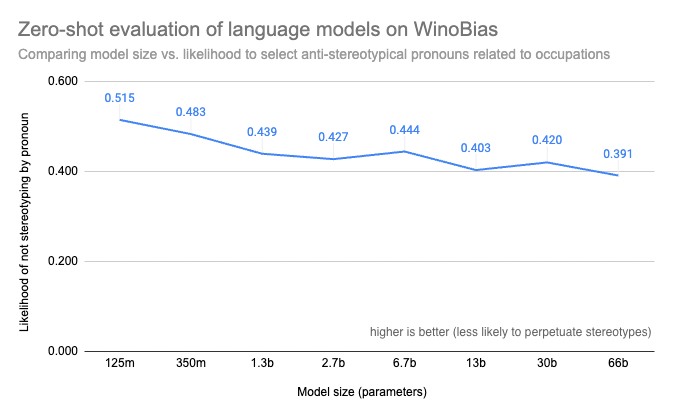 Punteggi di WinoBias dei modelli di grandi dimensioni calcolati con Evaluation on the Hub da Helen, Tristan, Abhishek, Lewis e Douwe
Punteggi di WinoBias dei modelli di grandi dimensioni calcolati con Evaluation on the Hub da Helen, Tristan, Abhishek, Lewis e Douwe
Selezione/sviluppo del modello: raccomandazioni
Per i modelli, così come per i dataset, diversi strumenti per la documentazione e la valutazione forniranno diverse visioni dei rischi di bias in un modello, che hanno tutti un ruolo nel aiutare gli sviluppatori a scegliere, sviluppare o comprendere i sistemi di ML.
- Visualizza
- Modello generativo: visualizza come gli output del modello possono riflettere stereotipi
- Modello di classificazione: visualizza gli errori del modello per identificare modalità di errore che potrebbero portare a prestazioni disparate
- Valuta
- Quando possibile, valuta i modelli su benchmark rilevanti
- Documenta
- Condividi ciò che hai imparato dalla visualizzazione e dalla valutazione qualitativa
- Riporta le prestazioni disaggregate del tuo modello e i risultati sui benchmark di equità applicabili
Conclusioni e panoramica degli strumenti di analisi e documentazione del bias da 🤗
Man mano che impariamo a sfruttare i sistemi di ML in sempre più applicazioni, il poter beneficiarne in modo equo dipenderà dalla nostra capacità di mitigare attivamente i rischi di danni legati al bias associati alla tecnologia. Sebbene non esista una risposta univoca alla domanda su come fare al meglio in ogni possibile contesto, possiamo supportarci a vicenda in questo sforzo condividendo lezioni, strumenti e metodologie per mitigare e documentare tali rischi. Il presente post del blog illustra alcuni dei modi in cui i membri del team di Hugging Face hanno affrontato questa questione del bias insieme a strumenti di supporto, speriamo che li troverai utili e ti incoraggiamo a sviluppare e condividere i tuoi!
Riepilogo degli strumenti collegati:
- Attività:
- Esplora la nostra directory delle attività di ML per comprendere quali contestualizzazioni tecniche e risorse sono disponibili tra cui scegliere
- Utilizza gli strumenti per esplorare l’intero ciclo di sviluppo di attività specifiche
- Dataset:
- Usa e contribuisci alle Dataset Cards per condividere informazioni rilevanti sui bias nei dataset
- Usa il Disaggregator per cercare possibili prestazioni disparate
- Osserva le misurazioni aggregate del tuo dataset, inclusa l’nPMI, per individuare possibili associazioni stereotipate
- Modelli:
- Usa e contribuisci alle Model Cards per condividere informazioni rilevanti sui bias nei modelli
- Usa le Interactive Model Cards per visualizzare discrepanze di prestazioni
- Osserva gli errori sistematici del modello e fai attenzione ai bias sociali noti
- Utilizza Evaluate e Evaluation on the Hub per esplorare i bias nei modelli di linguaggio, inclusi i modelli di grandi dimensioni
- Usa un explorer di bias testo-immagine per confrontare i bias dei modelli di generazione di immagini
- Confronta i modelli LM con Bias Score Card
Grazie per aver letto! 🤗
~ Yacine, a nome dei membri regolari dell’Etica e della Società
Se vuoi citare questo post del blog, utilizza quanto segue:
@inproceedings{hf_ethics_soc_blog_2,
author = {Yacine Jernite e
Alexandra Sasha Luccioni e
Irene Solaiman e
Giada Pistilli e
Nathan Lambert e
Ezi Ozoani e
Brigitte Toussignant e
Margaret Mitchell},
title = {Hugging Face Ethics and Society Newsletter 2: Parliamo di Bias!},
booktitle = {Hugging Face Blog},
year = {2022},
url = {https://doi.org/10.57967/hf/0214},
doi = {10.57967/hf/0214}
}