Analisi delle prestazioni e ottimizzazione dei modelli PyTorch
'Performance analysis and optimization of PyTorch models'
Come Usare il Profiler di PyTorch e TensorBoard per Accelerare l’Addestramento e Ridurre i Costi
L’addestramento di modelli di deep learning, specialmente quelli grandi, può essere un costo elevato. Uno dei metodi principali a nostra disposizione per gestire questi costi è l’ottimizzazione delle prestazioni. L’ottimizzazione delle prestazioni è un processo iterativo in cui cerchiamo costantemente opportunità per aumentare le prestazioni della nostra applicazione e poi sfruttiamo queste opportunità. In post precedenti (ad esempio, qui) abbiamo sottolineato l’importanza di avere strumenti appropriati per condurre questa analisi. Gli strumenti scelti dipenderanno probabilmente da un certo numero di fattori, tra cui il tipo di acceleratore di addestramento (ad esempio, GPU, HPU o altro) e il framework di addestramento.

Il focus in questo post sarà sull’addestramento in PyTorch su GPU. Più specificamente, ci concentreremo sull’analizzatore delle prestazioni integrato di PyTorch, PyTorch Profiler, e su uno dei modi per visualizzare i suoi risultati, il plugin TensorBoard di PyTorch Profiler.
Questo post non vuole essere un sostituto della documentazione ufficiale di PyTorch su PyTorch Profiler o sull’uso del plugin TensorBoard per analizzare i risultati del profiler. La nostra intenzione è piuttosto quella di dimostrare come questi strumenti potrebbero essere utilizzati durante lo sviluppo quotidiano. Infatti, se non l’hai ancora fatto, ti consigliamo di dare un’occhiata alla documentazione ufficiale prima di leggere questo post.
Da un po’ di tempo, sono stato intrigato da una porzione in particolare del tutorial del plugin TensorBoard. Il tutorial introduce un modello di classificazione (basato sull’architettura Resnet) che viene addestrato sul popolare dataset Cifar10. Procede poi a dimostrare come PyTorch Profiler e il plugin TensorBoard possano essere utilizzati per identificare e risolvere un collo di bottiglia nel caricamento dei dati. I collo di bottiglia delle prestazioni nel pipeline dei dati di input non sono rari e li abbiamo discussi a lungo in alcuni dei nostri post precedenti (ad esempio, qui). Quello che sorprende del tutorial sono i risultati finali (dopo l’ottimizzazione) che vengono presentati (al momento di questo scritto) e che abbiamo riportato di seguito:
- Padronanza della Gestione della Configurazione nel Machine Learning con Hydra
- AI Telephone – Una Battaglia di Modelli Multimodali
- Gestione facile dei modelli di apprendimento approfondito tramite configurazioni TOML
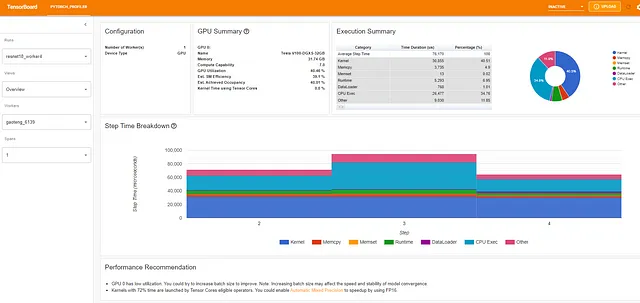
Se guardi attentamente, vedrai che l’utilizzo della GPU dopo l’ottimizzazione è del 40,46%. Non c’è modo di nascondere questo fatto: questi risultati sono assolutamente pessimi e dovrebbero impedirti di dormire la notte. Come abbiamo già discusso in passato (ad esempio, qui), la GPU è la risorsa più costosa nella nostra macchina di addestramento e il nostro obiettivo dovrebbe essere massimizzare il suo utilizzo. Un risultato di utilizzo del 40,46% rappresenta di solito una significativa opportunità per l’accelerazione dell’addestramento e il risparmio dei costi. Sicuramente, possiamo fare di meglio! In questo post cercheremo di fare di meglio. Inizieremo cercando di riprodurre i risultati presentati nel tutorial ufficiale e vedremo se possiamo utilizzare gli stessi strumenti per migliorare ulteriormente le prestazioni dell’addestramento.
Esempio Giocattolo
Il blocco di codice di seguito contiene il ciclo di addestramento definito dal tutorial del plugin TensorBoard, con due modifiche minori:
- Usiamo un dataset fittizio con le stesse proprietà e comportamenti del dataset CIFAR10 utilizzato nel tutorial. La motivazione per questo cambiamento può essere trovata qui.
- Inizializziamo la variabile torch.profiler.schedule con il flag di riscaldamento impostato a 3 e il flag di ripetizione impostato a 1. Abbiamo riscontrato che questo leggero aumento del numero di passaggi di riscaldamento migliora la stabilità dei risultati del profiling.
import numpy as npimport torchimport torch.nnimport torch.optimimport torch.profilerimport torch.utils.dataimport torchvision.datasetsimport torchvision.modelsimport torchvision.transforms as Tfrom torchvision.datasets.vision import VisionDatasetfrom PIL import Imageclass FakeCIFAR(VisionDataset): def __init__(self, transform): super().__init__(root=None, transform=transform) self.data = np.random.randint(low=0,high=256,size=(10000,32,32,3),dtype=np.uint8) self.targets = np.random.randint(low=0,high=10,size=(10000),dtype=np.uint8).tolist() def __getitem__(self, index): img, target = self.data[index], self.targets[index] img = Image.fromarray(img) if self.transform is not None: img = self.transform(img) return img, target def __len__(self) -> int: return len(self.data)transform = T.Compose( [T.Resize(224), T.ToTensor(), T.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])train_set = FakeCIFAR(transform=transform)train_loader = torch.utils.data.DataLoader(train_set, batch_size=32, shuffle=True)device = torch.device("cuda:0")model = torchvision.models.resnet18(weights='IMAGENET1K_V1').cuda(device)criterion = torch.nn.CrossEntropyLoss().cuda(device)optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)model.train()# passo di addestramentodef train(data): inputs, labels = data[0].to(device=device), data[1].to(device=device) outputs = model(inputs) loss = criterion(outputs, labels) optimizer.zero_grad() loss.backward() optimizer.step()# ciclo di addestramento avvolto dall'oggetto profilerwith torch.profiler.profile( schedule=torch.profiler.schedule(wait=1, warmup=4, active=3, repeat=1), on_trace_ready=torch.profiler.tensorboard_trace_handler('./log/resnet18'), record_shapes=True, profile_memory=True, with_stack=True) as prof: for step, batch_data in enumerate(train_loader): if step >= (1 + 4 + 3) * 1: break train(batch_data) prof.step() # È necessario chiamare questo alla fine di ogni passaggioLa GPU utilizzata nel tutorial era una Tesla V100-DGXS-32GB. In questo post cerchiamo di riprodurre – e migliorare – i risultati di performance del tutorial utilizzando un’istanza Amazon EC2 p3.2xlarge che contiene una GPU Tesla V100-SXM2-16GB. Anche se condividono la stessa architettura, ci sono alcune differenze tra le due GPU che puoi apprendere qui. Abbiamo eseguito lo script di formazione utilizzando un’immagine Docker AWS PyTorch 2.0. I risultati di prestazione dello script di formazione, come visualizzati nella pagina di panoramica del visualizzatore TensorBoard, sono catturati nell’immagine qui sotto:
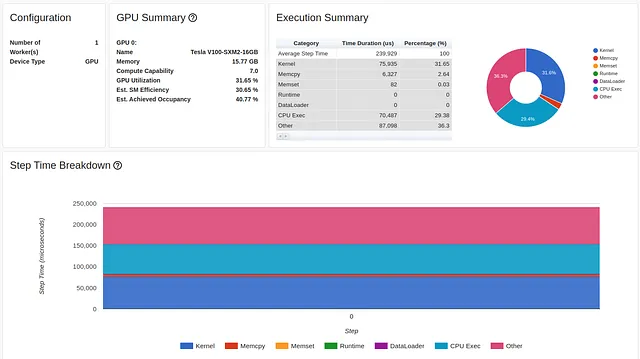
Notiamo innanzitutto che, contrariamente al tutorial, la pagina Panoramica (della versione 0.4.1 di torch-tb-profiler) nel nostro esperimento ha combinato i tre passaggi di profilazione in uno solo. Pertanto, il tempo medio complessivo del passaggio è di 80 millisecondi e non di 240 millisecondi come riportato. Questo può essere visto chiaramente nella scheda Trace (che, nella nostra esperienza, fornisce quasi sempre un rapporto più accurato) in cui ogni passaggio richiede circa 80 millisecondi.
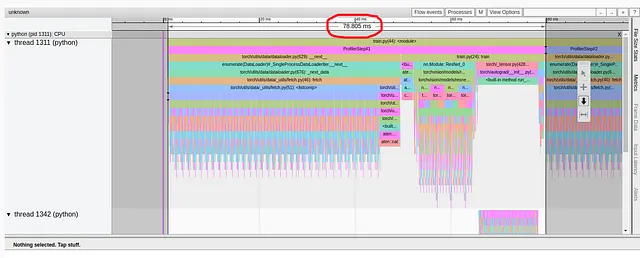
Si noti che il nostro punto di partenza del 31,65% di utilizzo della GPU e un tempo di passaggio di 80 millisecondi è diverso dal punto di partenza presentato nel tutorial del 23,54% e 132 millisecondi, rispettivamente. Questo è probabilmente il risultato di differenze nell’ambiente di formazione, compreso il tipo di GPU e la versione di PyTorch. Notiamo anche che mentre i risultati di base del tutorial diagnosticano chiaramente il problema di prestazione come un collo di bottiglia nella DataLoader, i nostri risultati non lo fanno. Spesso abbiamo riscontrato che i collo di bottiglia di caricamento dati si mascherano come un alto percentuale di “CPU Exec” o “Altro” nella scheda Panoramica.
Ottimizzazione n. 1: Caricamento Dati Multiprocesso
Iniziamo applicando il caricamento dati multiprocesso come descritto nel tutorial. Essendo che l’istanza Amazon EC2 p3.2xlarge ha 8 vCPUs, abbiamo impostato il numero di lavoratori DataLoader a 8 per massime prestazioni:
train_loader = torch.utils.data.DataLoader(train_set, batch_size=32, shuffle=True, num_workers=8)I risultati di questa ottimizzazione sono visualizzati di seguito:
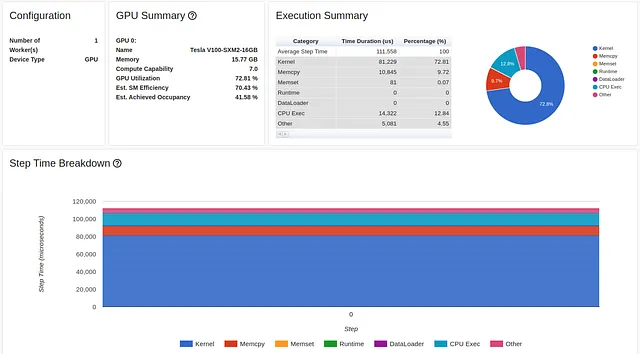
Il cambiamento di una sola riga di codice ha aumentato l’utilizzo della GPU di oltre il 200% (dal 31,65% al 72,81%), e ha più che dimezzato il tempo di passaggio di formazione (da 80 millisecondi a 37).
Questo è dove il processo di ottimizzazione nel tutorial termina. Anche se il nostro utilizzo della GPU (72,81%) è abbastanza più alto dei risultati del tutorial (40,46%), non ho dubbi che, come noi, troverai questi risultati ancora abbastanza insoddisfacenti.
Commento personale che puoi tranquillamente saltare: Immagina quanto denaro globale potrebbe essere risparmiato se PyTorch applicasse il caricamento dati multiprocesso per impostazione predefinita durante la formazione sulla GPU! È vero, potrebbero esserci alcuni effetti collaterali indesiderati nell’uso del multiprocessing. Tuttavia, deve esistere una qualche forma di algoritmo di auto-rilevamento che potrebbe essere eseguito per escludere la presenza di scenari potenzialmente problematici e applicare questa ottimizzazione di conseguenza.
Ottimizzazione n. 2: Memory Pinning
Se analizziamo la vista Trace del nostro ultimo esperimento, possiamo vedere che una quantità significativa di tempo (10 su 37 millisecondi) è ancora impiegata nel caricamento dei dati di formazione nella GPU.

Per risolvere questo problema, applicheremo un’altra ottimizzazione consigliata da PyTorch per ottimizzare il flusso di input dei dati, ovvero il memory pinning . L’utilizzo della memoria pinnata può aumentare la velocità della copia dei dati da host a GPU e, cosa più importante, ci consente di renderli asincroni. Questo significa che possiamo preparare il prossimo batch di formazione nella GPU in parallelo all’esecuzione del passaggio di formazione sul batch corrente. Per maggiori dettagli e potenziali effetti collaterali del memory pinning, consultare la documentazione PyTorch .
Questa ottimizzazione richiede modifiche a due righe di codice. In primo luogo, impostiamo il flag pin_memory del DataLoader su True.
train_loader = torch.utils.data.DataLoader(train_set, batch_size=32, shuffle=True, num_workers=8, pin_memory=True)Poi modifichiamo il trasferimento di memoria da host a dispositivo (nella funzione di formazione) in modo non bloccante:
inputs, labels = data[0].to(device=device, non_blocking=True), \ data[1].to(device=device, non_blocking=True)I risultati dell’ottimizzazione del memory pinning sono visualizzati di seguito:
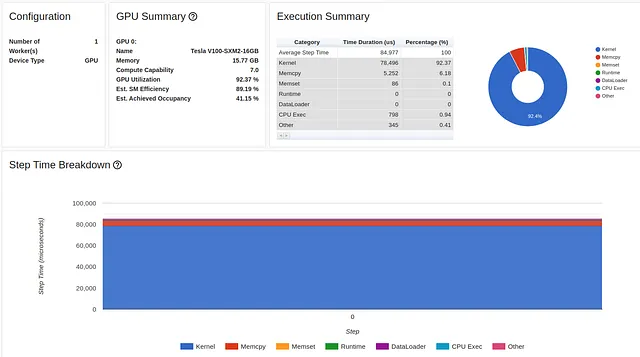
L’utilizzo della nostra GPU ora è del 92,37% e il tempo di esecuzione è ulteriormente diminuito. Ma possiamo ancora fare meglio. Notare che nonostante questa ottimizzazione, il rapporto delle prestazioni continua a indicare che stiamo impiegando molto tempo per copiare i dati nella GPU. Torniamo su questo punto nel passaggio 4 qui sotto.
Ottimizzazione #3: Aumentare la Dimensione del Batch
Per la nostra prossima ottimizzazione, prestiamo attenzione alla vista Memory dell’ultimo esperimento:
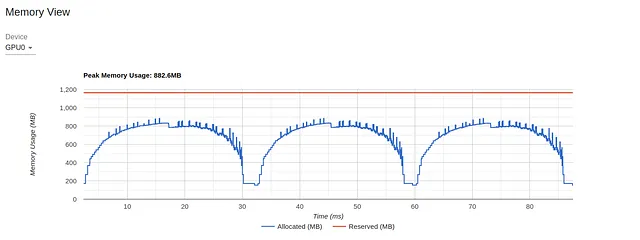
Il grafico mostra che su 16 GB di memoria GPU, raggiungiamo meno di 1 GB di utilizzo massimo. Questo è un esempio estremo di sottoutilizzo delle risorse che spesso (anche se non sempre) indica l’opportunità di migliorare le prestazioni. Un modo per controllare l’utilizzo della memoria è aumentare la dimensione del batch. Nell’immagine qui sotto mostriamo i risultati delle prestazioni quando aumentiamo la dimensione del batch a 512 (e l’utilizzo della memoria a 11,3 GB).
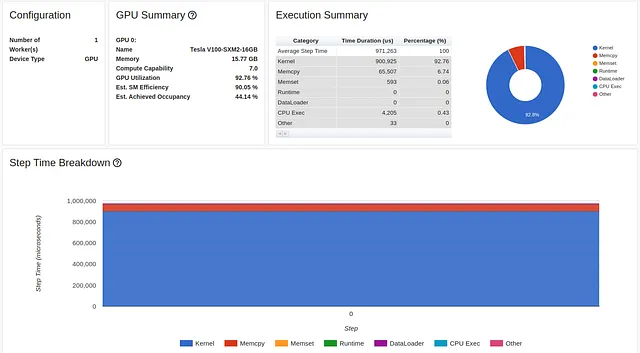
Anche se la misura dell’utilizzo della GPU non è cambiata molto, la velocità di formazione è aumentata considerevolmente, da 1200 campioni al secondo (46 millisecondi per batch di dimensione 32) a 1584 campioni al secondo (324 millisecondi per batch di dimensione 512).
Attenzione : Contrariamente alle nostre precedenti ottimizzazioni, l’aumento della dimensione del batch potrebbe influire sul comportamento della vostra applicazione di formazione. Diversi modelli mostrano diversi livelli di sensibilità a un cambiamento nella dimensione del batch. Alcuni potrebbero richiedere solo qualche regolazione delle impostazioni dell’ottimizzatore. Per altri, l’adattamento a una grande dimensione del batch potrebbe essere più difficile o addirittura impossibile. Consultare questo post precedente per alcune delle sfide coinvolte nella formazione su grandi batch.
Ottimizzazione n. 4: Ridurre la Copia da Host a Dispositivo
Probabilmente avrai notato il grande fastidio rappresentato dalla copia dei dati da host a dispositivo nella visualizzazione a torta dei nostri risultati precedenti. Il modo più diretto per cercare di affrontare questo tipo di collo di bottiglia è vedere se possiamo ridurre la quantità di dati in ogni batch. Si noti che nel caso del nostro input di immagine, convertiamo il tipo di dati da un intero non segnato a 8 bit a un float a 32 bit e applichiamo la normalizzazione prima di eseguire la copia dei dati. Nel blocco di codice qui sotto, proponiamo una modifica al flusso di dati di input in cui ritardiamo la conversione del tipo di dati e la normalizzazione fino a quando i dati non sono sulla GPU:
# manteniamo l'input dell'immagine come tensore uint8 a 8 bittransform = T.Compose( [T.Resize(224), T.PILToTensor() ])train_set = FakeCIFAR(transform=transform)train_loader = torch.utils.data.DataLoader(train_set, batch_size=1024, shuffle=True, num_workers=8, pin_memory=True)device = torch.device("cuda:0")model = torch.compile(torchvision.models.resnet18(weights='IMAGENET1K_V1').cuda(device), fullgraph=True)criterion = torch.nn.CrossEntropyLoss().cuda(device)optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)model.train()# passo di addestramentodef train(data): inputs, labels = data[0].to(device=device, non_blocking=True), \ data[1].to(device=device, non_blocking=True) # converti in float32 e normalizza inputs = (inputs.to(torch.float32) / 255. - 0.5) / 0.5 outputs = model(inputs) loss = criterion(outputs, labels) optimizer.zero_grad() loss.backward() optimizer.step()Come risultato di questa modifica, la quantità di dati che vengono copiati dalla CPU alla GPU viene ridotta di 4 volte e il fastidio rosso scompare praticamente:
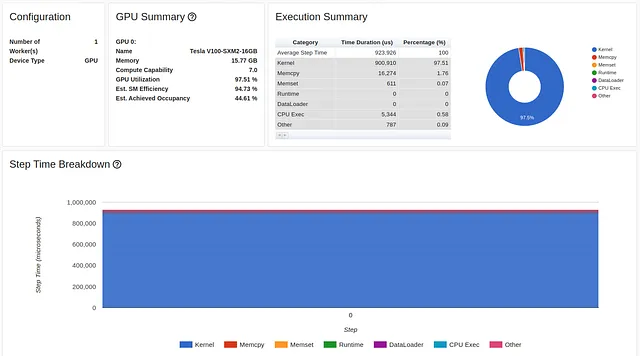
Siamo ora a un nuovo massimo del 97,51% (!!) di utilizzo della GPU e di una velocità di addestramento di 1670 campioni al secondo! Vediamo cos’altro possiamo fare.
Ottimizzazione n. 5: Impostare i Gradienti su Nulla
In questa fase sembra che stiamo utilizzando completamente la GPU, ma questo non significa che non possiamo utilizzarla in modo più efficace. Una popolare ottimizzazione che si dice riduca le operazioni di memoria nella GPU è impostare i gradienti dei parametri del modello su Nulla anziché su zero in ogni passaggio di addestramento. Si prega di consultare la documentazione di PyTorch per ulteriori dettagli su questa ottimizzazione. Tutto ciò che è necessario per implementare questa ottimizzazione è impostare il set_to_none della chiamata optimizer.zero_grad a True:
optimizer.zero_grad(set_to_none=True)Nel nostro caso, questa ottimizzazione non ha migliorato significativamente le nostre prestazioni.
Ottimizzazione n. 6: Precisione Mista Automatica
La vista del kernel GPU mostra il tempo in cui i kernel GPU erano attivi e può essere una risorsa utile per migliorare l’utilizzo della GPU:
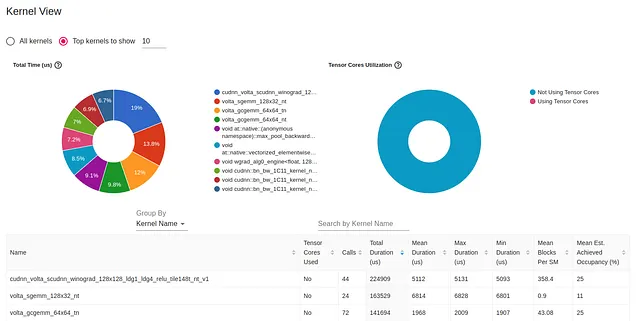
Uno dei dettagli più evidenti in questo rapporto è la mancanza di utilizzo dei Tensor Core della GPU. Disponibili su architetture GPU relativamente recenti, i Tensor Core sono unità di elaborazione dedicate alla moltiplicazione di matrici che possono aumentare significativamente le prestazioni delle applicazioni di intelligenza artificiale. La loro mancanza di utilizzo potrebbe rappresentare una grande opportunità per l’ottimizzazione.
Essendo che i Tensor Core sono progettati specificamente per il calcolo a precisione mista, un modo semplice per aumentare la loro utilizzazione è modificare il nostro modello per utilizzare la Precisione Mista Automatica (AMP). In modalità AMP, porzioni del modello vengono automaticamente convertite in float a 16 bit a precisione inferiore ed eseguite sui Tensor Core della GPU.
È importante notare che una completa implementazione di AMP potrebbe richiedere la scalatura del gradiente, che non è inclusa nella nostra dimostrazione. Assicurati di consultare la documentazione sulla formazione a precisione mista prima di adattarla.
La modifica al passo di addestramento richiesta per abilitare AMP è dimostrata nel blocco di codice qui sotto.
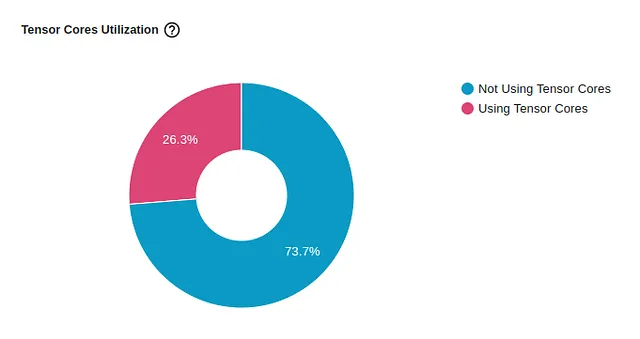
def train(data): inputs, labels = data[0].to(device=device, non_blocking=True), \ data[1].to(device=device, non_blocking=True) inputs = (inputs.to(torch.float32) / 255. - 0.5) / 0.5 with torch.autocast(device_type='cuda', dtype=torch.float16): outputs = model(inputs) loss = criterion(outputs, labels) # Nota - potrebbe essere necessario torch.cuda.amp.GradScaler() optimizer.zero_grad(set_to_none=True) loss.backward() optimizer.step()L’impatto sull’utilizzo di Tensor Core è visualizzato nell’immagine qui sotto. Anche se continua a indicare opportunità per ulteriori miglioramenti, con una sola riga di codice l’utilizzo è passato dallo 0% al 26,3%.
Oltre ad aumentare l’utilizzo di Tensor Core, l’utilizzo di AMP riduce l’utilizzo della memoria GPU, liberando più spazio per aumentare la dimensione del batch. L’immagine qui sotto cattura i risultati delle prestazioni di addestramento dopo l’ottimizzazione AMP e la dimensione del batch impostata a 1024:
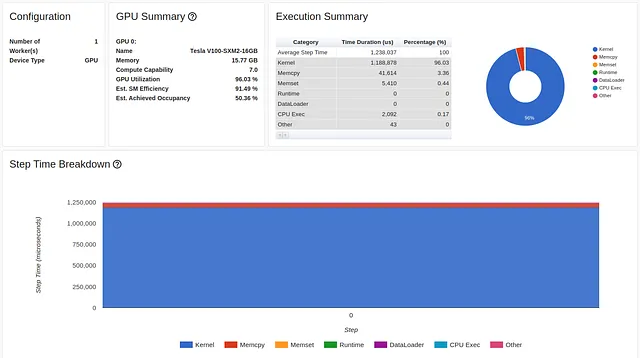
Anche se l’utilizzo della GPU è leggermente diminuito, la nostra principale metrica di throughput è aumentata di quasi il 50%, da 1670 campioni al secondo a 2477. Siamo sulla buona strada!
Attenzione: la riduzione della precisione di porzioni del tuo modello potrebbe avere un effetto significativo sulla sua convergenza. Come nel caso dell’aumento della dimensione del batch (vedi sopra), l’impatto dell’utilizzo della precisione mista varierà a seconda del modello. In alcuni casi, AMP funzionerà con poco o nessuno sforzo. Altre volte potresti dover lavorare un po’ di più per regolare l’autoscaler. Altre volte potresti dover impostare esplicitamente i tipi di precisione di diverse porzioni del modello (cioè, precisione mista manuale).
Per ulteriori dettagli sull’utilizzo della precisione mista come metodo per l’ottimizzazione della memoria, consulta il nostro post precedente sull’argomento.
Ottimizzazione #7: Formazione in Modalità Grafica
L’ultima ottimizzazione che applicheremo è la compilazione del modello. Contrariamente alla modalità di esecuzione immediata predefinita di PyTorch in cui ogni operazione PyTorch viene eseguita “immediatamente”, l’API di compilazione converte il tuo modello in un grafo di calcolo intermedio che viene quindi compilato in kernel di calcolo a basso livello in modo ottimale per l’acceleratore di formazione sottostante. Per maggiori informazioni sulla compilazione del modello in PyTorch 2, dai un’occhiata al nostro post precedente sull’argomento.
Il blocco di codice seguente mostra la modifica richiesta per applicare la compilazione del modello:
model = torchvision.models.resnet18(weights='IMAGENET1K_V1').cuda(device)model = torch.compile(model)I risultati dell’ottimizzazione della compilazione del modello sono mostrati di seguito:

La compilazione del modello aumenta ulteriormente il nostro throughput a 3268 campioni al secondo rispetto a 2477 nell’esperimento precedente, un ulteriore aumento delle prestazioni del 32% (!!).
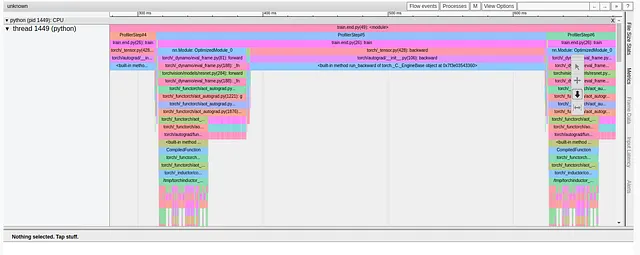
Il modo in cui la compilazione del grafico cambia il passo di addestramento è molto evidente nelle diverse visualizzazioni del plug-in TensorBoard. La visualizzazione del Kernel, ad esempio, indica l’uso di nuovi kernel GPU (fusi), e la visualizzazione della Traccia (mostrata di seguito) mostra un modello del tutto diverso rispetto a quello visto in precedenza.
Risultati Intermedi
Nella tabella sottostante riassumiamo i risultati delle successive ottimizzazioni che abbiamo applicato.
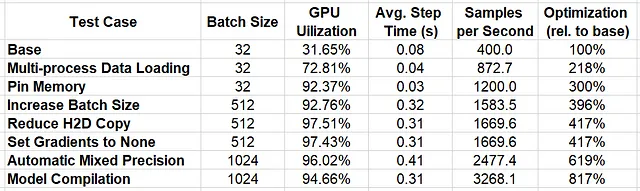
Applicando il nostro approccio iterativo di analisi e ottimizzazione utilizzando il Profiler di PyTorch e il plugin di TensorBoard, siamo riusciti ad aumentare le performance del 817% !!
Il nostro lavoro è completo? Assolutamente no! Ogni ottimizzazione che implementiamo scopre nuove opportunità potenziali per il miglioramento delle performance. Queste opportunità si presentano sotto forma di risorse che vengono liberate (ad esempio, il modo in cui il passaggio alla precisione mista ci ha permesso di aumentare la dimensione del batch) o sotto forma di nuovi colli di bottiglia delle performance scoperti (ad esempio, il modo in cui la nostra ultima ottimizzazione ha scoperto un collo di bottiglia nel trasferimento di dati da host a dispositivo). Inoltre, ci sono molte altre forme di ottimizzazione ben note che non abbiamo tentato in questo post (ad esempio, vedere qui e qui). E infine, nuove ottimizzazioni delle librerie (ad esempio, la funzione di compilazione del modello che abbiamo dimostrato nel passaggio 7), vengono rilasciate continuamente, consentendo ulteriori obiettivi di miglioramento delle performance. Come abbiamo sottolineato nell’introduzione, per sfruttare appieno tali opportunità, l’ottimizzazione delle performance deve essere una parte iterativa e coerente del tuo flusso di lavoro di sviluppo.
Riassunto
In questo post abbiamo dimostrato il significativo potenziale dell’ottimizzazione delle performance su un modello di classificazione giocattolo. Sebbene ci siano altri analizzatori delle performance che puoi utilizzare, ognuno con i suoi vantaggi e svantaggi, abbiamo scelto il Profiler di PyTorch e il plugin di TensorBoard per la loro facilità di integrazione.
Dovremmo sottolineare che il percorso per un’ottimizzazione di successo varierà notevolmente in base ai dettagli del progetto di formazione, compresa l’architettura del modello e l’ambiente di formazione. Nella pratica, raggiungere i tuoi obiettivi potrebbe essere più difficile che nell’esempio che abbiamo presentato qui. Alcune delle tecniche descritte potrebbero avere poco impatto sulle tue performance o potrebbero addirittura peggiorarle. Notiamo anche che le precise ottimizzazioni che abbiamo scelto e l’ordine in cui abbiamo scelto di applicarle erano in qualche modo arbitrari. Ti incoraggiamo vivamente a sviluppare i tuoi strumenti e tecniche per raggiungere i tuoi obiettivi di ottimizzazione in base ai dettagli specifici del tuo progetto.
L’ottimizzazione delle performance dei carichi di lavoro di apprendimento automatico è talvolta vista come secondaria, non critica e odiosa. Speriamo di averti convinto che il potenziale per il risparmio di tempo e costi di sviluppo giustifichi un investimento significativo nell’analisi e nell’ottimizzazione delle performance. E, ehilà, potresti persino trovarlo divertente :).
Cosa Seguirà?
Questo è solo la punta dell’iceberg. C’è molto di più nell’ottimizzazione delle performance di quanto abbiamo coperto qui. In un seguito di questo post, ci immergeremo in un problema di performance abbastanza comune nei modelli PyTorch in cui viene eseguita un’eccessiva quantità di calcolo sulla CPU anziché sulla GPU, spesso in un modo che è ignoto allo sviluppatore. Ti incoraggiamo anche a dare un’occhiata ai nostri altri post su Nisoo, molti dei quali coprono diversi elementi dell’ottimizzazione delle performance dei carichi di lavoro di apprendimento automatico.





