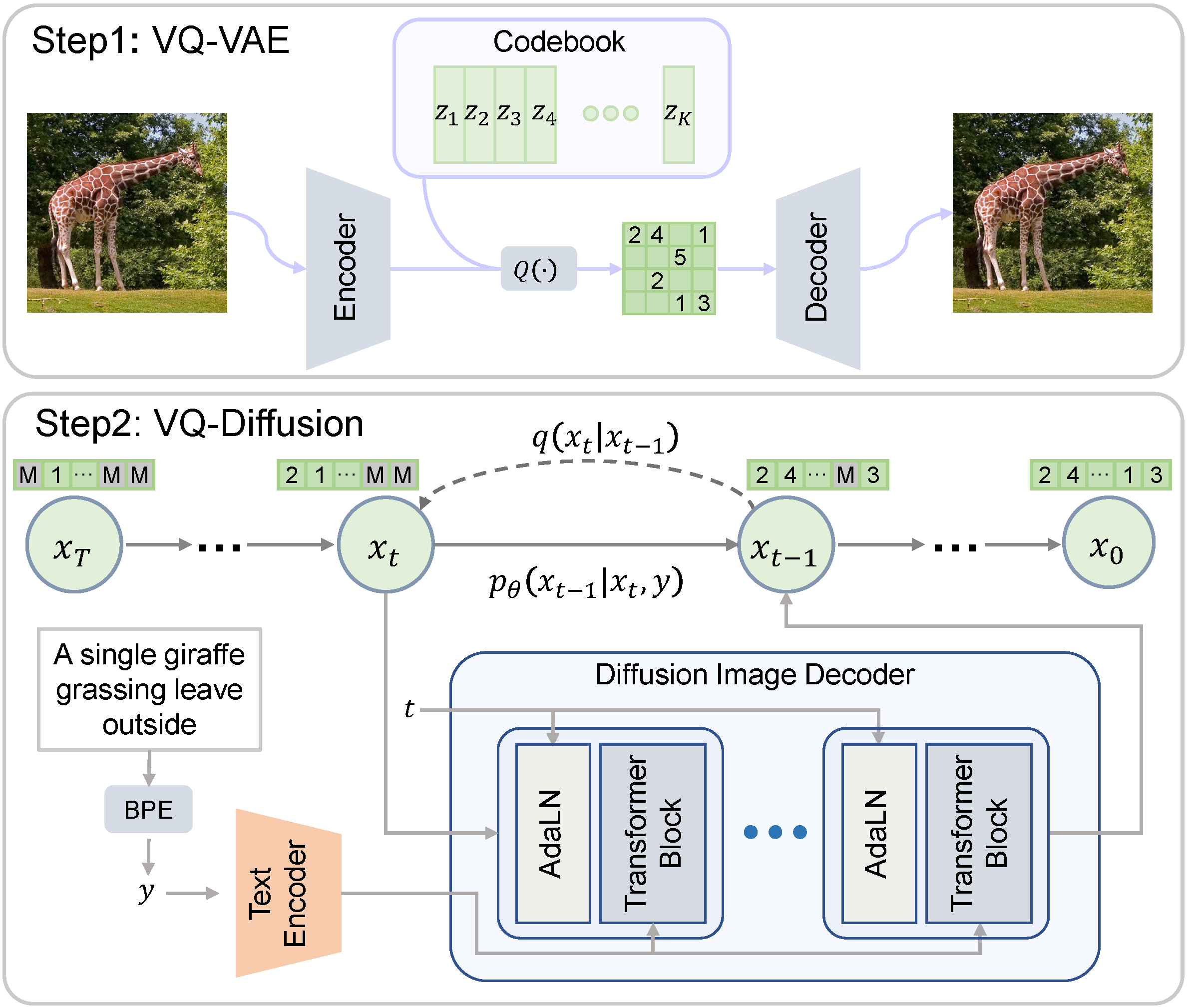
Una panoramica delle soluzioni di inferenza su Hugging Face
Panoramica delle soluzioni di inferenza su Hugging Face.
Ogni giorno, sviluppatori e organizzazioni stanno adottando modelli ospitati su Hugging Face per trasformare idee in demo di proof-of-concept e demo in applicazioni di grado di produzione. Ad esempio, i modelli Transformer sono diventati un’architettura popolare per una vasta gamma di applicazioni di apprendimento automatico (ML), tra cui l’elaborazione del linguaggio naturale, la visione artificiale, il riconoscimento vocale e altro. Recentemente, i diffuser sono diventati un’architettura popolare per la generazione di testo-immagine o immagine-immagine. Altre architetture sono popolari per altre attività e le ospitiamo tutte su HF Hub!
Da Hugging Face, siamo ossessionati dalla semplificazione dello sviluppo e delle operazioni di ML senza compromettere la qualità all’avanguardia. In questo senso, la capacità di testare e distribuire i modelli più recenti con un attrito minimo è fondamentale, lungo tutto il ciclo di vita di un progetto di ML. Ottimizzare il rapporto costo-prestazioni è altrettanto importante e vorremmo ringraziare i nostri amici di Intel per il sostegno alle nostre soluzioni gratuite di inferenza basate su CPU. Questo rappresenta un altro passo importante nel nostro partenariato. È anche una grande notizia per la nostra community di utenti, che ora possono godere dell’accelerazione fornita dall’architettura Intel Xeon Ice Lake senza costi aggiuntivi.
Ora, esaminiamo le tue opzioni di inferenza con Hugging Face.
Widget di Inferenza Gratuito
Una delle mie funzionalità preferite su Hugging Face Hub è il Widget di Inferenza. Situato nella pagina del modello, il Widget di Inferenza ti consente di caricare dati di esempio e predirli in un solo clic.
Ecco un esempio di similarità delle frasi con il modello sentence-transformers/all-MiniLM-L6-v2:

È il modo migliore per avere rapidamente un’idea di cosa fa un modello, il suo output e come si comporta su alcuni campioni dal tuo dataset. Il modello viene caricato su richiesta sui nostri server e scaricato quando non è più necessario. Non devi scrivere alcun codice e la funzione è gratuita. Cosa c’è da non amare?
API di Inferenza Gratuita
L’API di Inferenza è ciò che alimenta il Widget di Inferenza sotto il cofano. Con una semplice richiesta HTTP, puoi caricare qualsiasi modello dal hub e prevedere i tuoi dati in pochi secondi. L’URL del modello e un token hub valido sono tutto ciò di cui hai bisogno.
Ecco come posso caricare e prevedere con il modello xlm-roberta-base in una sola riga:
curl https://api-inference.huggingface.co/models/xlm-roberta-base \
-X POST \
-d '{"inputs": "La risposta all'universo è <mask>."}' \
-H "Authorization: Bearer HF_TOKEN"L’API di Inferenza è il modo più semplice per creare un servizio di previsione che puoi chiamare immediatamente dalla tua applicazione durante lo sviluppo e i test. Non c’è bisogno di un’API personalizzata o di un server di modelli. Inoltre, puoi passare istantaneamente da un modello all’altro e confrontare le loro prestazioni nella tua applicazione. E indovina un po’? L’API di Inferenza è gratuita.
Poiché viene applicato un limite di velocità, non consigliamo di utilizzare l’API di Inferenza per la produzione. Invece, dovresti considerare gli Endpoint di Inferenza.
Produzione con Endpoint di Inferenza
Una volta soddisfatto delle prestazioni del tuo modello di ML, è il momento di distribuirlo per la produzione. Purtroppo, quando si lascia il sandbox, tutto diventa una preoccupazione: sicurezza, scalabilità, monitoraggio, ecc. Ed è qui che molti progetti di ML inciampano e talvolta cadono. Abbiamo creato gli Endpoint di Inferenza per risolvere questo problema.
In pochi clic, gli Endpoint di Inferenza ti consentono di distribuire qualsiasi modello dal hub su infrastrutture sicure e scalabili, ospitate nella tua regione AWS o Azure di scelta. Le impostazioni aggiuntive includono l’hosting CPU e GPU, il ridimensionamento automatico integrato e altro ancora. Ciò rende facile trovare il giusto rapporto costo/prestazioni, con prezzi a partire da soli $0.06 all’ora.
Gli Endpoint di Inferenza supportano tre livelli di sicurezza:
-
Pubblico: l’endpoint viene eseguito in una subnet pubblica di Hugging Face e chiunque su Internet può accedervi senza alcuna autenticazione.
-
Protetto: l’endpoint viene eseguito in una subnet pubblica di Hugging Face e chiunque su Internet con il token Hugging Face appropriato può accedervi.
-
Privato: l’endpoint viene eseguito in una subnet privata di Hugging Face e non è accessibile su Internet. È disponibile solo attraverso una connessione privata nel tuo account AWS o Azure. Questo soddisferà i requisiti di conformità più rigorosi.

Per saperne di più sugli Endpoint di Inferenza, leggi questo tutorial e la documentazione .
Spazi
Infine, Spazi è un’altra opzione pronta per la produzione per distribuire il tuo modello per l’inferenza su una semplice interfaccia utente (ad esempio, Gradio), e supportiamo anche l’aggiornamento hardware come i processori Intel avanzati e le GPU NVIDIA. Non c’è modo migliore di presentare i tuoi modelli!
Per saperne di più su Spazi, dai un’occhiata alla documentazione e non esitare a consultare i post o a fare domande nel nostro forum .
Per iniziare
Non potrebbe essere più semplice. Accedi al portale di Hugging Face e sfoglia i nostri modelli . Una volta trovato quello che ti piace, puoi provare direttamente il Widget di Inferenza sulla pagina. Cliccando sul pulsante “Deploy”, otterrai il codice generato automaticamente per distribuire il modello sull’API di Inferenza gratuita per la valutazione e un collegamento diretto per distribuirlo in produzione con gli Endpoint di Inferenza o Spazi.
Provalo e facci sapere cosa ne pensi. Ci piacerebbe leggere il tuo feedback sul forum di Hugging Face .
Grazie per aver letto!