Una nuova ricerca sull’IA da Tel Aviv e dall’Università di Copenhagen introduce un approccio plug-and-play per il rapido perfezionamento dei modelli di diffusione testo-immagine utilizzando un segnale discriminativo.
Nuova ricerca sull'IA introduce approccio plug-and-play per migliorare rapidamente modelli testo-immagine usando segnale discriminativo.


I modelli di diffusione testo-immagine hanno mostrato un notevole successo nella generazione di immagini diverse e di alta qualità basate su descrizioni di testo in input. Tuttavia, incontrano sfide quando il testo in input è ambiguo dal punto di vista lessicale o coinvolge dettagli intricati. Ciò può portare a situazioni in cui il contenuto dell’immagine desiderata, come un “ferro” per i vestiti, viene rappresentato erroneamente come il metallo “elementale”.
Per affrontare queste limitazioni, i metodi esistenti hanno impiegato classificatori pre-addestrati per guidare il processo di denoising. Un approccio coinvolge la fusione della stima del punteggio di un modello di diffusione con il gradiente della log probabilità di un classificatore pre-addestrato. In termini più semplici, questo approccio utilizza informazioni sia da un modello di diffusione che da un classificatore pre-addestrato per generare immagini che corrispondono all’obiettivo desiderato e si allineano al giudizio del classificatore su ciò che l’immagine dovrebbe rappresentare.
Tuttavia, questo metodo richiede un classificatore in grado di lavorare con dati reali e rumorosi.
- I ricercatori di Google AI presentano MADLAD-400 un dataset di domini web di 2,8T token che copre 419 lingue.
- Microsoft Research presenta BatteryML uno strumento open source per l’apprendimento automatico sulla degradazione delle batterie.
- Questo documento del Gruppo Alibaba presenta FederatedScope-LLM un pacchetto completo per il tuning fine di LLMs nel Federated Learning
Altre strategie hanno condizionato il processo di diffusione su etichette di classe utilizzando dataset specifici. Sebbene efficace, questo approccio è lontano dalla piena capacità espressiva dei modelli addestrati su ampie collezioni di coppie immagine-testo provenienti dal web.
Una direzione alternativa prevede il fine-tuning di un modello di diffusione o di alcuni dei suoi token di input utilizzando un piccolo insieme di immagini relative a un concetto o un’etichetta specifica. Tuttavia, questo approccio ha svantaggi, tra cui un addestramento lento per nuovi concetti, possibili cambiamenti nella distribuzione delle immagini e una diversità limitata catturata da un piccolo gruppo di immagini.
Questo articolo riporta un approccio proposto che affronta questi problemi, fornendo una rappresentazione più accurata delle classi desiderate, risolvendo l’ambiguità lessicale e migliorando la rappresentazione dei dettagli di alta qualità. Ciò si ottiene senza compromettere la potenza espressiva del modello di diffusione pre-addestrato originale o affrontare gli svantaggi menzionati. L’overview di questo metodo è illustrata nella figura seguente.
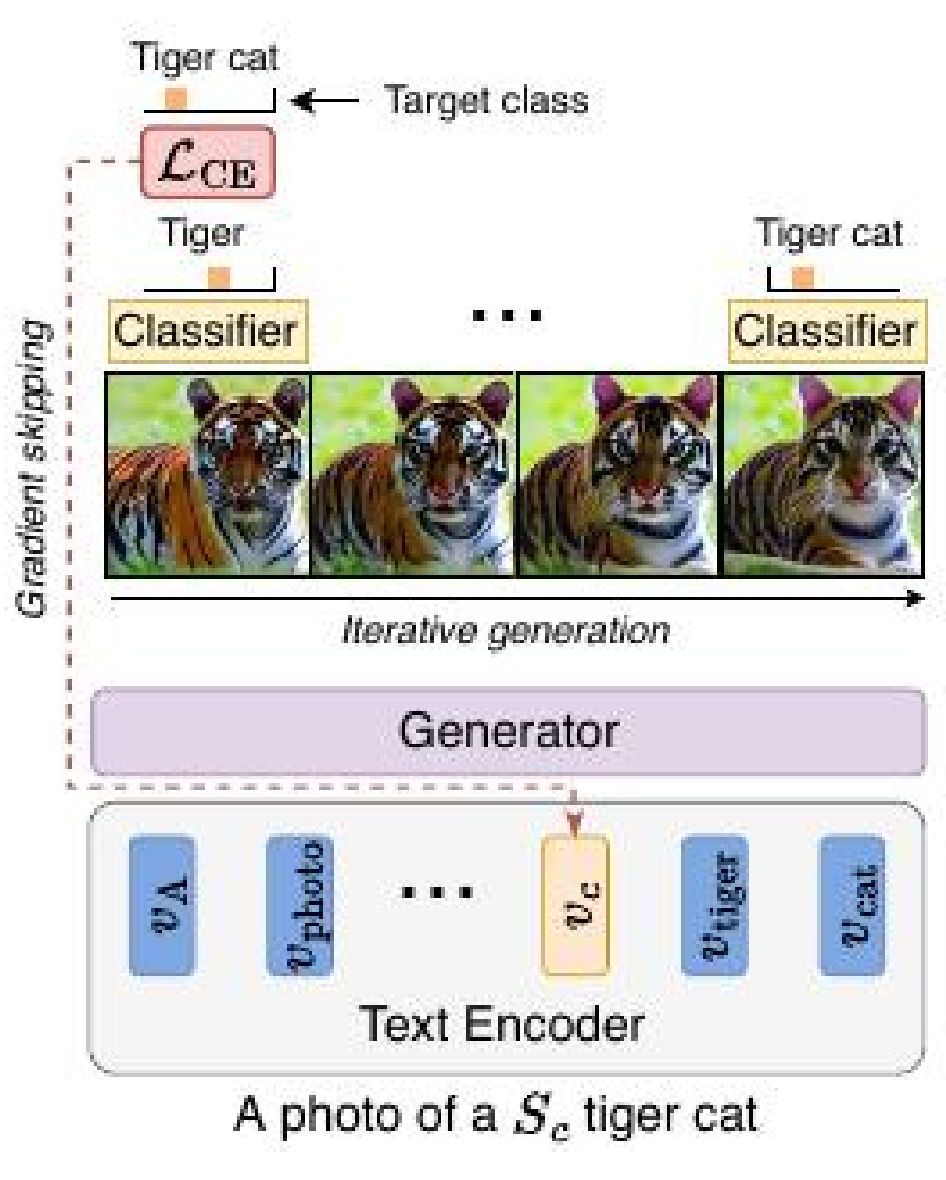

Invece di guidare il processo di diffusione o alterare l’intero modello, questo approccio si concentra sull’aggiornamento della rappresentazione di un singolo token aggiunto corrispondente a ciascuna classe di interesse. È importante sottolineare che questo aggiornamento non prevede l’addestramento del modello su immagini etichettate.
Il metodo apprende la rappresentazione del token per una classe target specifica attraverso un processo iterativo di generazione di nuove immagini con una probabilità di classe più alta secondo un classificatore pre-addestrato. Il feedback del classificatore guida l’evoluzione del token della classe designata in ogni iterazione. Viene utilizzata una nuova tecnica di ottimizzazione chiamata “gradient skipping”, in cui il gradiente viene propagato solo attraverso l’ultima fase del processo di diffusione. Il token ottimizzato viene quindi incorporato come parte dell’input del testo condizionato per generare immagini utilizzando il modello di diffusione originale.
Secondo gli autori, questo metodo offre diversi vantaggi chiave. Richiede solo un classificatore pre-addestrato e non richiede un classificatore addestrato esplicitamente su dati rumorosi, distinguendosi da altre tecniche condizionate dalla classe. Inoltre, eccelle in velocità, consentendo miglioramenti immediati alle immagini generate una volta che un token di classe è addestrato, a differenza di metodi più lenti.
Nell’immagine seguente sono mostrati alcuni risultati campionati dallo studio. Questi studi di caso forniscono una panoramica comparativa degli approcci proposti e di quelli di stato dell’arte.

Questo è stato il riassunto di una nuova tecnica AI non invasiva che sfrutta un classificatore pre-addestrato per ottimizzare i modelli di diffusione testo-immagine. Se sei interessato e vuoi saperne di più, non esitare a fare riferimento ai link citati di seguito.