Potatura della rete neurale con ottimizzazione combinatoria
Neural network pruning with combinatorial optimization
Pubblicato da Hussein Hazimeh, Ricercatore Scientifico, Team Athena, e Riade Benbaki, Studente di Dottorato presso il MIT
Le moderne reti neurali hanno raggiunto prestazioni impressionanti in una varietà di applicazioni, come linguaggio, ragionamento matematico e visione. Tuttavia, queste reti spesso utilizzano architetture complesse che richiedono molte risorse computazionali. Ciò può rendere impraticabile fornire tali modelli agli utenti, specialmente in ambienti con risorse limitate come dispositivi indossabili e smartphone. Un approccio ampiamente utilizzato per ridurre i costi di inferenza delle reti preaddestrate è quello di potarle rimuovendo alcuni dei loro pesi, in modo che non influiscano significativamente sull’utilità. Nelle reti neurali standard, ogni peso definisce una connessione tra due neuroni. Quindi, dopo la potatura dei pesi, l’input si propagherà attraverso un insieme più piccolo di connessioni e richiederà quindi meno risorse computazionali.
 |
| Rete originale vs. una rete potata. |
I metodi di potatura possono essere applicati a diverse fasi del processo di addestramento della rete: dopo, durante o prima dell’addestramento (ovvero subito dopo l’inizializzazione dei pesi). In questo post, ci concentriamo sulla configurazione di post-addestramento: dato una rete preaddestrata, come possiamo determinare quali pesi devono essere potati? Un metodo popolare è la potatura per magnitudine, che rimuove i pesi con la minore magnitudine. Sebbene efficiente, questo metodo non considera direttamente l’effetto della rimozione dei pesi sulle prestazioni della rete. Un’altra paradigma popolare è la potatura basata sull’ottimizzazione, che rimuove i pesi in base all’entità del loro impatto sulla funzione di perdita. Sebbene concettualmente interessante, la maggior parte degli approcci di potatura basati sull’ottimizzazione esistenti sembrano affrontare un serio compromesso tra prestazioni e requisiti computazionali. I metodi che fanno approssimazioni approssimative (ad esempio, assumendo una matrice di Hessiana diagonale) possono scalare bene, ma hanno prestazioni relativamente basse. D’altra parte, mentre i metodi che fanno meno approssimazioni tendono a ottenere prestazioni migliori, sembrano essere molto meno scalabili.
In “Fast as CHITA: Neural Network Pruning with Combinatorial Optimization”, presentato a ICML 2023, descriviamo come abbiamo sviluppato un approccio basato sull’ottimizzazione per la potatura di reti neurali preaddestrate su larga scala. CHITA (che sta per “Combinatorial Hessian-free Iterative Thresholding Algorithm”) supera i metodi di potatura esistenti in termini di scalabilità e compromessi di prestazioni, e lo fa sfruttando i progressi provenienti da diversi campi, tra cui statistica ad alta dimensionalità, ottimizzazione combinatoria e potatura di reti neurali. Ad esempio, CHITA può essere da 20 a 1000 volte più veloce dei metodi all’avanguardia per la potatura di ResNet e migliora l’accuratezza di oltre il 10% in molti scenari.
- Un dispositivo superconduttore potrebbe ridurre drasticamente il consumo energetico nei calcoli e in altre applicazioni
- Oltre la penna l’arte dell’IA nella generazione di testo manoscritto da archetipi visivi
- Moderazione dei contenuti alla classificazione Zero Shot
Panoramica dei contributi
CHITA presenta due miglioramenti tecnici notevoli rispetto ai metodi popolari:
- Utilizzo efficiente delle informazioni di secondo ordine: I metodi di potatura che utilizzano informazioni di secondo ordine (ovvero relative alle derivate seconde) raggiungono lo stato dell’arte in molti contesti. Nella letteratura, queste informazioni vengono tipicamente utilizzate calcolando la matrice di Hessiana o la sua inversa, un’operazione molto difficile da scalare poiché la dimensione della Hessiana è quadratica rispetto al numero dei pesi. Attraverso una riformulazione accurata, CHITA utilizza le informazioni di secondo ordine senza dover calcolare o memorizzare esplicitamente la matrice di Hessiana, consentendo così una maggiore scalabilità.
- Ottimizzazione combinatoria: I metodi di ottimizzazione basati sull’ottimizzazione utilizzano una semplice tecnica di ottimizzazione che pota i pesi in modo isolato, ovvero quando si decide di potare un certo peso non si tiene conto del fatto che altri pesi siano stati potati. Ciò potrebbe portare a potare pesi importanti perché i pesi considerati non importanti in isolamento potrebbero diventare importanti quando altri pesi vengono potati. CHITA evita questo problema utilizzando un algoritmo di ottimizzazione combinatoria più avanzato che tiene conto di come la potatura di un peso influisce sugli altri.
Nelle sezioni seguenti, discutiamo la formulazione e gli algoritmi di potatura di CHITA.
Una formulazione di potatura adatta al calcolo
Esistono molti possibili candidati per la potatura, ottenuti trattenendo solo un sottoinsieme dei pesi della rete originale. Sia k un parametro specificato dall’utente che indica il numero di pesi da mantenere. La potatura può essere naturalmente formulata come un problema di selezione del miglior sottoinsieme (BSS): tra tutti i possibili candidati per la potatura (cioè, sottoinsiemi di pesi) con solo k pesi trattenuti, viene selezionato il candidato con la perdita più piccola.
 |
| Potatura come problema BSS: tra tutti i possibili candidati per la potatura con lo stesso numero totale di pesi, il miglior candidato è definito come quello con la minore perdita. Questa illustrazione mostra quattro candidati, ma questo numero è generalmente molto più grande. |
Risolvere il problema di potatura BSS sulla funzione di perdita originale è generalmente computazionalmente intrattabile. Pertanto, come in lavori precedenti, come OBD e OBS, approssimiamo la perdita con una funzione quadratica utilizzando una serie di Taylor di secondo ordine, in cui l’Hessiana è stimata con la matrice di informazione Fisher empirica. Mentre i gradienti possono essere tipicamente calcolati in modo efficiente, calcolare e memorizzare la matrice Hessiana è proibitivamente costoso a causa delle sue dimensioni enormi. Nella letteratura, è comune affrontare questa sfida facendo ipotesi restrittive sull’Hessiana (ad esempio, matrice diagonale) e anche sull’algoritmo (ad esempio, potatura dei pesi in isolamento).
CHITA utilizza una riformulazione efficiente del problema di potatura (BSS utilizzando la perdita quadratica) che evita il calcolo esplicito della matrice Hessiana, pur utilizzando tutte le informazioni provenienti da questa matrice. Questo è reso possibile sfruttando la struttura a basso rango della matrice di informazione Fisher empirica. Questa riformulazione può essere vista come un problema di regressione lineare sparso, in cui ogni coefficiente di regressione corrisponde a un certo peso nella rete neurale. Dopo aver ottenuto una soluzione a questo problema di regressione, i coefficienti impostati a zero corrisponderanno ai pesi che devono essere potati. La nostra matrice di dati di regressione è (n x p), dove n è la dimensione del batch (sottocampionamento) e p è il numero di pesi nella rete originale. Tipicamente n << p, quindi memorizzare e operare con questa matrice di dati è molto più scalabile rispetto agli approcci di potatura comuni che operano con l’Hessiana (p x p).
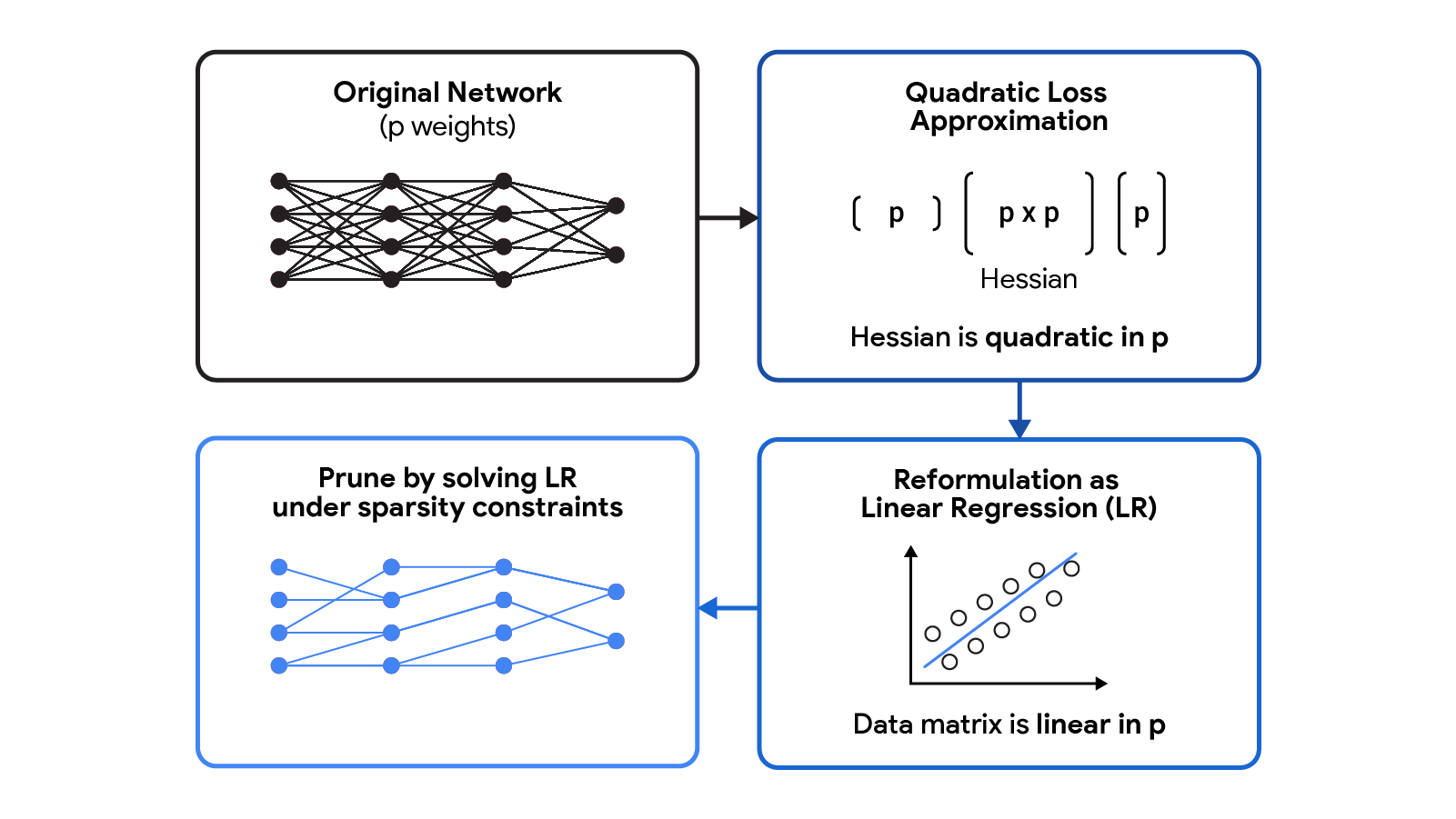 |
| CHITA riformula l’approssimazione della perdita quadratica, che richiede una costosa matrice Hessiana, come un problema di regressione lineare (LR). La matrice di dati LR è lineare in p, il che rende la riformulazione più scalabile rispetto all’approssimazione quadratica originale. |
Algoritmi di ottimizzazione scalabili
CHITA riduce la potatura a un problema di regressione lineare con il seguente vincolo di sparsità: al massimo k coefficienti di regressione possono essere diversi da zero. Per ottenere una soluzione a questo problema, consideriamo una modifica dell’algoritmo di thresholding duro iterativo (IHT) ben noto. IHT esegue una discesa del gradiente in cui dopo ogni aggiornamento viene eseguito il seguente passaggio di post-elaborazione: tutti i coefficienti di regressione al di fuori dei Top-k (cioè, i k coefficienti con la magnitudine più grande) vengono impostati a zero. IHT tipicamente fornisce una buona soluzione al problema e lo fa esplorando iterativamente diversi candidati per la potatura e ottimizzando congiuntamente i pesi.
A causa dell’entità del problema, l’IHT standard con una costante velocità di apprendimento può soffrire di una convergenza molto lenta. Per una convergenza più veloce, abbiamo sviluppato un nuovo metodo di ricerca della linea che sfrutta la struttura del problema per trovare una velocità di apprendimento adatta, cioè una che porti a una diminuzione sufficientemente grande della perdita. Abbiamo anche utilizzato diversi schemi computazionali per migliorare l’efficienza di CHITA e la qualità dell’approssimazione di secondo ordine, portando a una versione migliorata che chiamiamo CHITA++.
Esperimenti
Confrontiamo il tempo di esecuzione e l’accuratezza di CHITA con diversi metodi di potatura all’avanguardia utilizzando diverse architetture, tra cui ResNet e MobileNet.
Tempo di esecuzione: CHITA è molto più scalabile rispetto ai metodi comparabili che eseguono l’ottimizzazione congiunta (invece di potare i pesi in modo isolato). Ad esempio, l’accelerazione di CHITA può raggiungere oltre 1000 volte quando si pota ResNet.
Accuratezza dopo la potatura: Di seguito, confrontiamo le prestazioni di CHITA e CHITA++ con la potatura per magnitudine (MP), Woodfisher (WF) e Combinatorial Brain Surgeon (CBS), per la potatura del 70% dei pesi del modello. Nel complesso, vediamo buoni miglioramenti da parte di CHITA e CHITA++.
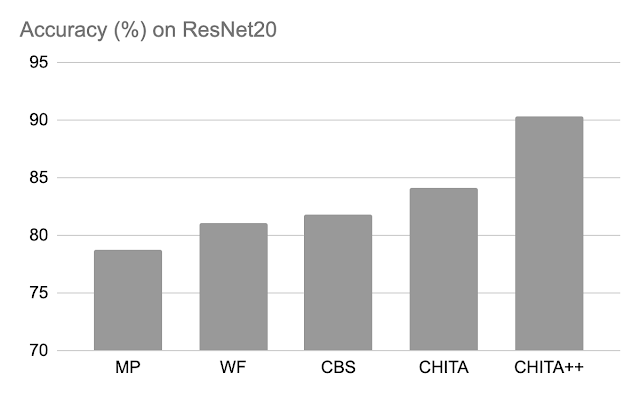 |
| Accuratezza dopo la potatura di vari metodi su ResNet20. I risultati sono riportati per la potatura del 70% dei pesi del modello. |
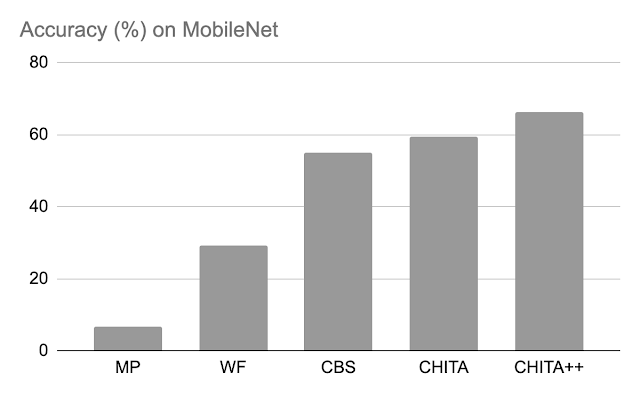 |
| Accuratezza dopo la potatura di vari metodi su MobileNet. I risultati sono riportati per la potatura del 70% dei pesi del modello. |
In seguito, riportiamo i risultati per la potatura di una rete più grande: ResNet50 (su questa rete, alcuni dei metodi elencati nella figura di ResNet20 non potevano essere scalati). Qui confrontiamo la potatura per magnitudine e M-FAC. La figura sottostante mostra che CHITA ottiene una migliore accuratezza di test per una vasta gamma di livelli di sparsità.
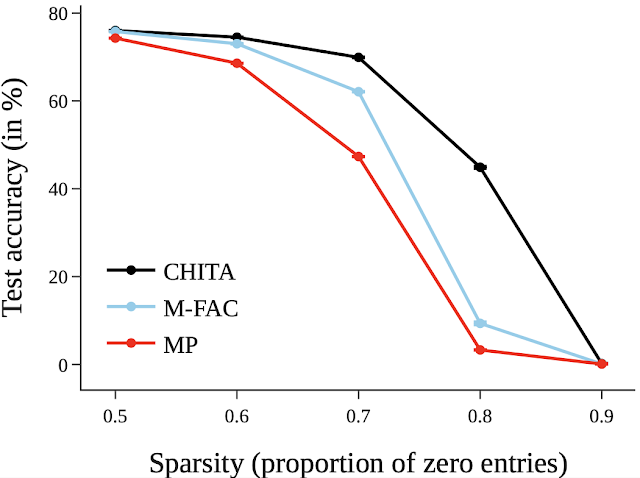 |
| Accuratezza di test di reti potate, ottenute utilizzando diversi metodi. |
Conclusioni, limitazioni e lavori futuri
Abbiamo presentato CHITA, un approccio basato sull’ottimizzazione per la potatura delle reti neurali pre-addestrate. CHITA offre scalabilità e prestazioni competitive utilizzando efficientemente informazioni di secondo ordine e attingendo a idee dall’ottimizzazione combinatoria e dalle statistiche ad alta dimensionalità.
CHITA è progettato per la potatura non strutturata in cui è possibile rimuovere qualsiasi peso. In teoria, la potatura non strutturata può ridurre significativamente i requisiti computazionali. Tuttavia, per realizzare tali riduzioni nella pratica, è necessario un software speciale (e eventualmente hardware) che supporti calcoli sparsi. Al contrario, la potatura strutturata, che rimuove intere strutture come i neuroni, potrebbe offrire miglioramenti più facili da ottenere su software e hardware generici. Sarebbe interessante estendere CHITA alla potatura strutturata.
Ringraziamenti
Questo lavoro fa parte di una collaborazione di ricerca tra Google e MIT. Grazie a Rahul Mazumder, Natalia Ponomareva, Wenyu Chen, Xiang Meng, Zhe Zhao e Sergei Vassilvitskii per il loro aiuto nella preparazione di questo post e del paper. Grazie anche a John Guilyard per la creazione delle grafiche in questo post.




