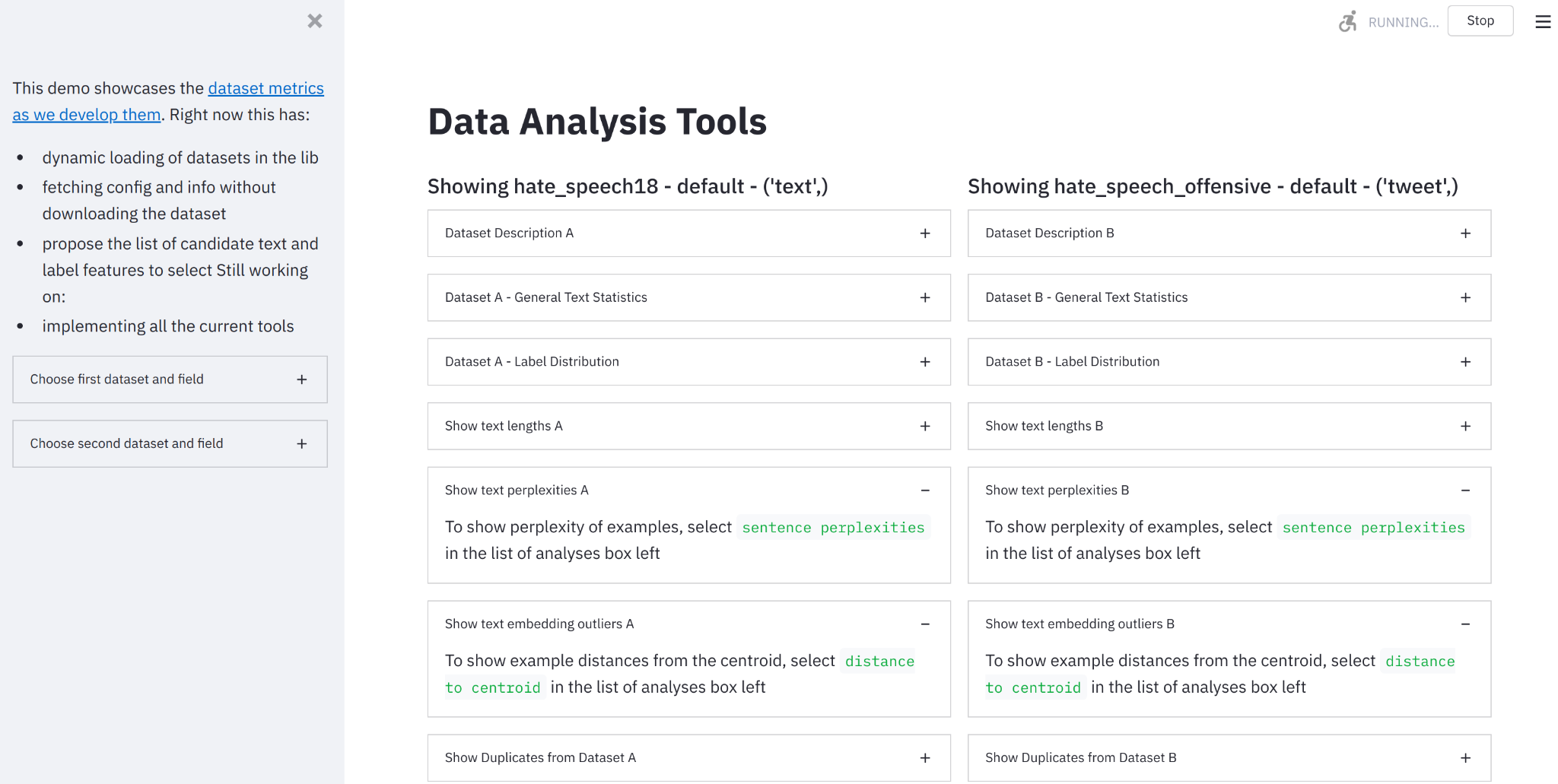
L’era del Machine Learning come Codice è arrivata
Machine Learning come Codice è qui.
La edizione 2021 del State of AI Report è uscita la scorsa settimana. Anche il Kaggle State of Machine Learning and Data Science Survey è uscito nello stesso periodo. Ci sono molte cose da imparare e discutere in questi rapporti, e un paio di punti chiave hanno attirato la mia attenzione.
“L’AI viene sempre più applicata a infrastrutture critiche come le reti elettriche nazionali e i calcoli automatizzati per i magazzini dei supermercati durante le pandemie. Tuttavia, ci sono dubbi sul fatto che la maturità dell’industria sia all’altezza dell’enormità della sua crescente implementazione.”
Non si può negare che le applicazioni basate sull’apprendimento automatico stiano raggiungendo ogni angolo dell’informatica. Ma cosa significa tutto ciò per le aziende e le organizzazioni? Come costruiamo flussi di lavoro di apprendimento automatico affidabili? Dovremmo assumere tutti 100 scienziati dei dati? O 100 ingegneri DevOps?
“I Transformer sono emersi come un’architettura a uso generale per l’apprendimento automatico. Non solo per l’elaborazione del linguaggio naturale, ma anche per il riconoscimento vocale, la visione artificiale o addirittura la previsione della struttura delle proteine.”
Gli esperti del settore hanno imparato a fatica che non esiste una soluzione miracolosa nell’informatica. Tuttavia, l’architettura Transformer è effettivamente molto efficiente in una vasta gamma di compiti di apprendimento automatico. Ma come possiamo tenere il passo con il ritmo frenetico dell’innovazione nell’apprendimento automatico? Abbiamo davvero bisogno di competenze specialistiche per sfruttare questi modelli all’avanguardia? O esiste un percorso più breve per creare valore commerciale in meno tempo?
Bene, ecco cosa penso.
Apprendimento automatico per le masse!
L’apprendimento automatico è ovunque, o almeno ci sta provando. Qualche anno fa, Forbes ha scritto che “Il software ha mangiato il mondo, ora l’IA sta mangiando il software”, ma cosa significa davvero? Se significa che i modelli di apprendimento automatico dovrebbero sostituire migliaia di righe di codice obsoleto, sono completamente d’accordo. Muori, malvagi regolamenti aziendali, muori!
Ora, significa che l’apprendimento automatico sostituirà effettivamente l’ingegneria del software? Al momento ci sono sicuramente molte fantasie riguardo al codice generato dall’IA, e alcune tecniche sono sicuramente interessanti, come la ricerca di bug e problemi di performance. Tuttavia, non solo non dovremmo neanche considerare di eliminare gli sviluppatori, ma dovremmo lavorare per dare potere al maggior numero possibile di sviluppatori in modo che l’apprendimento automatico diventi solo un altro noioso carico di lavoro informatico (e la tecnologia noiosa è fantastica). In altre parole, ciò di cui abbiamo veramente bisogno è che il software mangi l’apprendimento automatico!
Le cose non sono diverse questa volta
Da anni sostengo che le migliori pratiche decennali per l’ingegneria del software si applichino anche alla scienza dei dati e all’apprendimento automatico: versioning, riutilizzabilità, testabilità, automazione, distribuzione, monitoraggio, performance, ottimizzazione, ecc. Per un po’ mi sono sentito solo, e poi è arrivata inaspettatamente la cavalleria di Google:
“Fai l’apprendimento automatico come il grande ingegnere che sei, non come il grande esperto di apprendimento automatico che non sei.” – Regole dell’apprendimento automatico, Google
Non c’è nemmeno bisogno di reinventare la ruota. Il movimento DevOps ha risolto questi problemi più di 10 anni fa. Ora, la comunità della scienza dei dati e dell’apprendimento automatico dovrebbe adottare e adattare questi strumenti e processi provati senza indugi. Questo è l’unico modo per riuscire a costruire sistemi di apprendimento automatico robusti, scalabili e ripetibili in produzione. Se chiamarlo MLOps aiuta, va bene: non discuterò su un altro termine di moda.
È davvero arrivato il momento di smettere di considerare le prove di concetto e i test A/B nel sandbox come risultati rilevanti. Sono solo una piccola pietra miliare verso la produzione, che è l’unico luogo in cui si possono convalidare le ipotesi e l’impatto commerciale. Ogni scienziato dei dati e ingegnere di apprendimento automatico dovrebbe concentrarsi nel portare i propri modelli in produzione, il più rapidamente e il più spesso possibile. Un modello di produzione sufficiente batte sempre un modello di sandbox eccezionale.
Infrastruttura? E allora?
Siamo nel 2021. L’infrastruttura IT non dovrebbe più essere un ostacolo. Il software l’ha già divorata tempo fa, astratta con API cloud, infrastruttura come codice, Kubeflow e così via. Sì, anche in locale.
Lo stesso sta accadendo rapidamente per l’infrastruttura di apprendimento automatico. Secondo il sondaggio Kaggle, il 75% dei partecipanti utilizza servizi cloud e oltre il 45% utilizza una piattaforma Enterprise ML, con Amazon SageMaker, Databricks e Azure ML Studio ai primi tre posti.

Con MLOps, infrastruttura definita dal software e piattaforme, non è mai stato così facile tirare fuori tutti questi ottimi concetti dal sandbox e spostarli in produzione. Per rispondere alla mia domanda originale, sono abbastanza sicuro che è necessario assumere più ingegneri di software e DevOps esperti di apprendimento automatico, non più scienziati dei dati. Ma nel profondo, lo sapevate già, giusto?
Ora, parliamo dei Transformers.
Transformers! Transformers! Transformers! (Stile Ballmer)
Riporta lo State of AI report: “L’architettura dei Transformers si è estesa ben oltre l’NLP ed è emersa come un’architettura a scopo generale per l’Apprendimento Automatico”. Ad esempio, modelli recenti come il Vision Transformer di Google, un’architettura di transformer senza convoluzione, e CoAtNet, che combina transformer e convoluzione, hanno stabilito nuovi benchmark per la classificazione delle immagini su ImageNet, richiedendo meno risorse di calcolo per il training.
![]()
I Transformers si comportano anche molto bene nell’audio (ad esempio, nel riconoscimento vocale), così come nelle nuvole di punti, una tecnica utilizzata per modellare ambienti 3D come le scene di guida autonoma.
Il sondaggio Kaggle riflette questa crescita dei Transformers. Il loro utilizzo continua a crescere di anno in anno, mentre le reti neurali ricorrenti (RNNs), le reti neurali convoluzionali (CNNs) e gli algoritmi di boosting del gradiente (Gradient Boosting) stanno diminuendo.
![]()
Oltre all’aumento dell’accuratezza, i Transformers continuano a mantenere la promessa del transfer learning, consentendo alle squadre di risparmiare tempo di training e costi di calcolo, e di fornire valore aziendale più rapidamente.
![]()
Con i Transformers, il mondo dell’Apprendimento Automatico si sta gradualmente spostando da ” Yeehaa!! Costruiamo e addestriamo il nostro modello di Deep Learning da zero ” a ” Prendiamo un modello provato e già fatto, lo perfezioniamo con i nostri dati e siamo a casa presto per cena. “
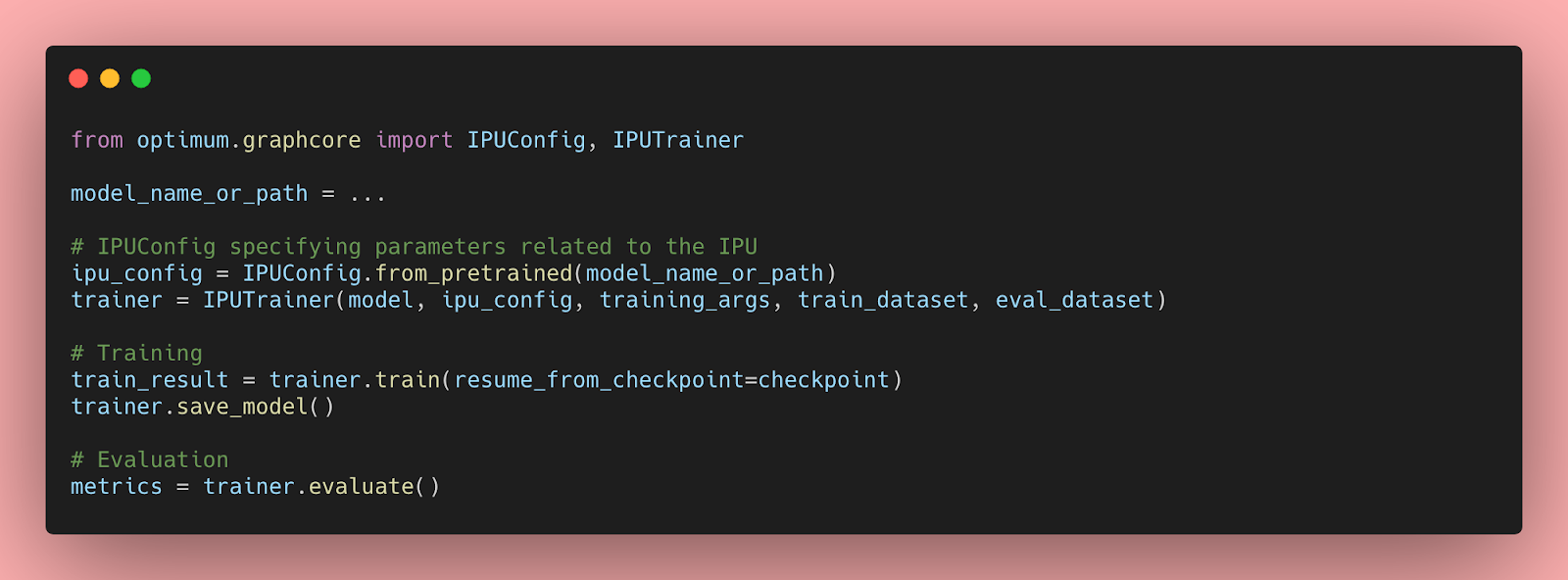
È una grande cosa in molti modi. Lo stato dell’arte avanza costantemente e quasi nessuno può tenere il passo con il suo ritmo incessante. Ricordi quel modello Google Vision Transformer che ho menzionato prima? Vorresti provarlo qui e ora? Con Hugging Face, è la cosa più semplice .
![]()
Cosa ne pensi degli ultimi modelli di generazione di testo zero-shot del progetto Big Science ?

Puoi fare lo stesso con altri 16.000+ modelli e 1.600+ set di dati , con strumenti aggiuntivi per l’inferenza , AutoNLP , ottimizzazione della latenza e accelerazione hardware . Possiamo anche aiutarti a avviare il tuo progetto, dalla modellazione alla produzione .
La nostra missione in Hugging Face è rendere l’Apprendimento Automatico il più amichevole e produttivo possibile, sia per i principianti che per gli esperti.
Crediamo nel scrivere il minor numero possibile di codice per addestrare, ottimizzare e distribuire modelli.
Crediamo nelle migliori pratiche integrate.
Crediamo nel rendere l’infrastruttura il più trasparente possibile.
Crediamo che niente possa battere modelli di alta qualità in produzione, veloci.
Apprendimento Automatico come codice, qui e ora!
Molti di voi sembrano essere d’accordo. Abbiamo più di 52.000 stelle su Github . Per il primo anno, Hugging Face è anche presente nel sondaggio Kaggle, con un utilizzo già superiore al 10%.

Grazie a tutti . E sì, stiamo appena iniziando.
Interessato a come Hugging Face può aiutare la tua organizzazione a costruire e distribuire soluzioni di Apprendimento Automatico di produzione? Contattaci a [email protected] (nessun reclutatore, nessuna vendita, per favore).