LLM Apocalypse Now La Vendetta dei Cloni Open Source
LLM Apocalypse Now La Vendetta dei Cloni is an Open Source project.
Questa è una storia su come i progetti open-source stiano affrontando l’industria LLM.

“Eravamo troppi. Avevamo accesso a troppi soldi, troppa attrezzatura, e poco alla volta, siamo impazziti.”
Francis Ford Coppola non stava facendo una metafora per le aziende di intelligenza artificiale che spendono troppo e perdono la strada, ma avrebbe potuto farlo. Apocalypse Now è stato epico ma anche un progetto lungo, difficile e costoso da realizzare, molto simile a GPT-4. Suggerirei che lo sviluppo delle LLM si sia gravitato verso troppi soldi e troppa attrezzatura. E alcune delle esagerazioni del tipo “abbiamo appena inventato l’intelligenza generale” sono un po’ folli. Ma ora è il turno delle comunità open source di fare ciò che sanno fare meglio: fornire software gratuito concorrente utilizzando molto meno denaro e attrezzature.
- Apprendimento Profondo con R
- I migliori framework di AutoML da considerare nel 2023
- Progetto RedPajama un’iniziativa open-source per democratizzare gli LLM
OpenAI ha ricevuto oltre $11 miliardi di finanziamenti ed è stato stimato che GPT-3.5 costa $5-6 milioni per esecuzione di training. Sappiamo molto poco su GPT-4 perché OpenAI non lo dice, ma penso sia sicuro presumere che non sia più piccolo di GPT-3.5. Attualmente c’è una carenza mondiale di GPU e, per cambiare, non è a causa dell’ultima criptovaluta. Le start-up di intelligenza artificiale generativa stanno ricevendo round di serie A da $100 milioni a valutazioni enormi quando non possiedono alcuna delle proprietà intellettuali per le LLM che utilizzano per alimentare il loro prodotto. La moda delle LLM è in piena marcia e i soldi stanno fluendo.
Sembra che il destino fosse stato segnato: solo le aziende ricche come Microsoft/OpenAI, Amazon e Google potevano permettersi di addestrare modelli di centinaia di miliardi di parametri. Modelli più grandi venivano considerati come modelli migliori. GPT-3 ha commesso un errore? Basta aspettare fino a quando non ci sarà una versione più grande e tutto andrà bene! Le piccole aziende che cercano di competere dovevano raccogliere molto più capitale o rimanere a costruire integrazioni di commodità nel mercato ChatGPT. L’accademia, con budget di ricerca ancora più limitati, è stata relegata ai margini.
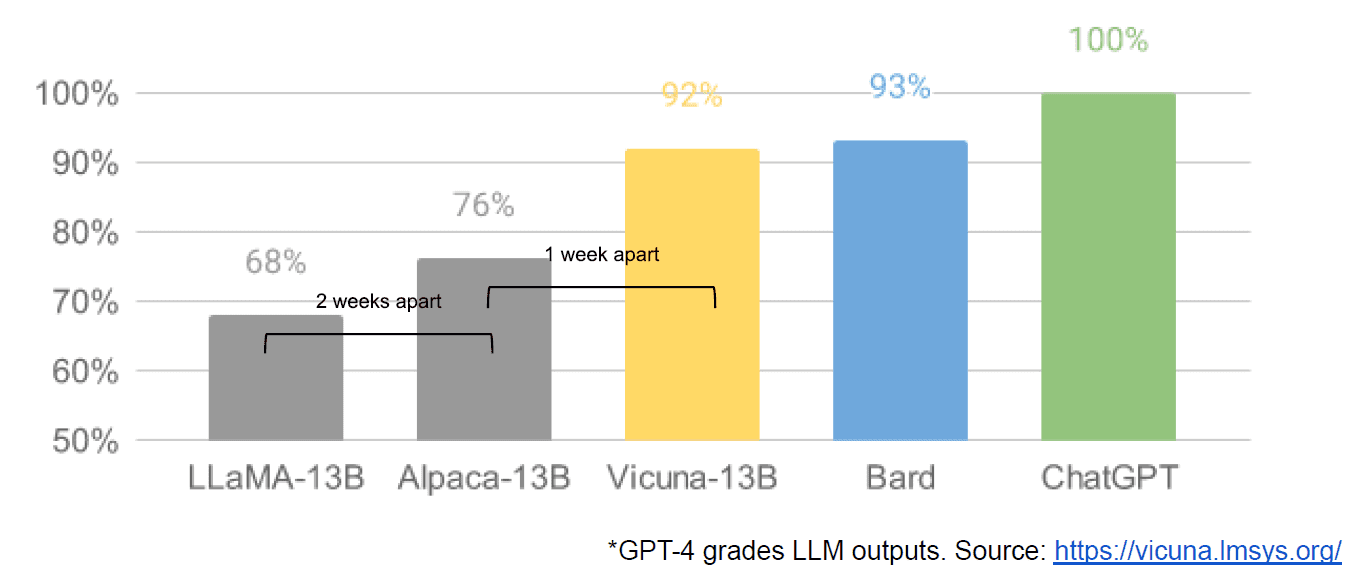
Fortunatamente, un gruppo di persone intelligenti e progetti open source ha preso ciò come una sfida anziché come una restrizione. I ricercatori di Stanford hanno rilasciato Alpaca, un modello di 7 miliardi di parametri il cui rendimento si avvicina al modello di 175 miliardi di parametri di GPT-3.5. Non avendo le risorse per costruire un set di addestramento delle dimensioni utilizzate da OpenAI, hanno intelligentemente scelto di prendere un LLM open source addestrato, LLaMA, e affinarlo su una serie di prompt e output di GPT-3.5. In sostanza, il modello ha imparato ciò che fa GPT-3.5, il che si è rivelato una strategia molto efficace per replicare il suo comportamento.
Alpaca è autorizzato solo per uso non commerciale sia nel codice che nei dati in quanto utilizza il modello open source non commerciale LLaMA, e OpenAI vieta esplicitamente qualsiasi utilizzo delle sue API per creare prodotti concorrenti. Ciò crea la prospettiva allettante di affinare un diverso LLM open source sui prompt e gli output di Alpaca… creando un terzo modello simile a GPT-3.5 con diverse possibilità di licenza.
C’è un altro livello di ironia qui, nel fatto che tutti i principali LLM sono stati addestrati su testo e immagini protetti da copyright disponibili su Internet e non hanno pagato un centesimo ai titolari dei diritti. Le aziende sostengono l’esenzione di “uso leale” in base alla legge sul copyright statunitense con l’argomento che l’uso è “trasformativo”. Tuttavia, quando si tratta dell’output dei modelli che costruiscono con dati gratuiti, non vogliono davvero che qualcuno faccia la stessa cosa con loro. Penso che questo cambierà man mano che i detentori dei diritti si renderanno conto, e potrebbe finire in tribunale in qualche momento.
Questo è un punto separato e distinto da quello sollevato dagli autori di open source con licenze restrittive che, per i prodotti di intelligenza artificiale generativa per il codice come CoPilot, si oppongono all’utilizzo del loro codice per l’addestramento perché la licenza non viene seguita. Il problema per gli autori di open source individuali è che devono dimostrare la loro posizione – copia sostanziale – e che hanno subito danni. E poiché i modelli rendono difficile collegare il codice di output all’input (le righe di codice sorgente dell’autore) e non c’è perdita economica (dovrebbe essere gratuito), è molto più difficile fare una causa. Questo è diverso per i creatori a scopo di lucro (ad esempio, i fotografi) il cui intero modello di business consiste nella licenza/vendita del loro lavoro, e che sono rappresentati dagli aggregatori come Getty Images che possono dimostrare la copia sostanziale.
Un’altra cosa interessante di LLaMA è che è uscita da Meta. Inizialmente è stata rilasciata solo per i ricercatori e poi trapelata nel mondo via BitTorrent. Meta è in un business fondamentalmente diverso da quello di OpenAI, Microsoft, Google e Amazon in quanto non sta cercando di venderti servizi cloud o software, e quindi ha incentivi molto diversi. Ha open-sourcato i suoi progetti di calcolo in passato (OpenCompute) e ha visto la comunità migliorarli – capisce il valore dell’open source.
Meta potrebbe rivelarsi uno dei più importanti contributori di intelligenza artificiale open-source. Non solo dispone di risorse enormi, ma trae beneficio dalla proliferazione di una tecnologia AI generativa eccellente: ci sarà più contenuto da monetizzare sui social media. Meta ha rilasciato altri tre modelli di AI open-source: ImageBind (indicizzazione di dati multidimensionali), DINOv2 (visione artificiale) e Segment Anything. Quest’ultimo identifica oggetti unici nelle immagini ed è rilasciato sotto la licenza Apache altamente permissiva.
Infine, abbiamo anche la presunta divulgazione di un documento interno di Google “We Have No Moat, and Neither Does OpenAI”, che guarda con sfavore ai modelli chiusi rispetto all’innovazione delle comunità che producono modelli molto più piccoli e economici che si comportano vicini o meglio delle loro controparti closed source. Dico presunta perché non c’è modo di verificare che l’articolo provenga dall’interno di Google. Tuttavia, contiene questo grafico convincente:
Stable Diffusion, che sintetizza immagini da testo, è un altro esempio in cui l’intelligenza artificiale generativa open source è stata in grado di avanzare più rapidamente rispetto ai modelli proprietari. Una recente iterazione di quel progetto (ControlNet) lo ha migliorato in modo tale da superare le capacità di Dall-E2. Questo è stato il risultato di molti esperimenti in tutto il mondo, che hanno portato ad un ritmo di avanzamento difficile per qualsiasi singola istituzione da eguagliare. Alcuni di quei sperimentatori hanno scoperto come rendere Stable Diffusion più veloce da allenare ed eseguire su hardware meno costoso, consentendo cicli di iterazione più brevi per più persone.
E così siamo tornati al punto di partenza. Non avere troppi soldi e troppa attrezzatura ha ispirato un livello astuto di innovazione da una comunità di persone comuni. Che tempo meraviglioso per essere uno sviluppatore di intelligenza artificiale. Mathew Lodge è CEO di Diffblue, una startup di AI per il codice. Ha un’esperienza diversificata di oltre 25 anni nella leadership di prodotto in aziende come Anaconda e VMware. Lodge è attualmente membro del consiglio della Good Law Project e vicepresidente del Consiglio di Amministrazione della Royal Photographic Society.






