Apprendi i Modelli di Attenzione da Zero
Learn Attention Models from Scratch
Introduzione
I modelli di attenzione, noti anche come meccanismi di attenzione, sono tecniche di elaborazione dell’input utilizzate nelle reti neurali. Consentono alla rete di concentrarsi su diversi aspetti dell’input complesso individualmente fino a quando l’intero set di dati viene categorizzato. L’obiettivo è suddividere compiti complessi in aree di attenzione più piccole che vengono elaborate sequenzialmente. Questo approccio è simile a come la mente umana risolve nuovi problemi suddividendoli in compiti più semplici e risolvendoli passo dopo passo. I modelli di attenzione possono adattarsi meglio a compiti specifici, ottimizzare le loro prestazioni e migliorare la loro capacità di prestare attenzione alle informazioni rilevanti.

Il meccanismo di attenzione in NLP è uno dei progressi più preziosi nel deep learning dell’ultimo decennio. L’architettura Transformer e l’elaborazione del linguaggio naturale (NLP), come il BERT di Google, hanno portato a un recente aumento di progresso.
Obiettivi di apprendimento
- Comprendere la necessità di meccanismi di attenzione nel deep learning, come funzionano e come possono migliorare le prestazioni dei modelli.
- Conoscere i tipi di meccanismi di attenzione e gli esempi del loro utilizzo.
- Esplorare la tua applicazione e i pro e i contro dell’utilizzo del meccanismo di attenzione.
- Avere esperienza pratica seguendo un esempio di attenzione implementata.
Questo articolo è stato pubblicato come parte del Data Science Blogathon.
- Presentando il Parse di Python L’alternativa definitiva alle espressioni regolari.
- Righe di Intelligenza Artificiale La Morte delle Tabelle Excel?
- Plugin di ChatGPT Tutto ciò che devi sapere
Quando utilizzare il framework di attenzione?
Il framework di attenzione è stato inizialmente utilizzato nei sistemi di traduzione automatica basati su reti neurali encoder-decoder e nella visione artificiale per migliorare le loro prestazioni. I sistemi di traduzione automatica tradizionali si basavano su grandi set di dati e funzioni complesse per gestire le traduzioni, mentre i meccanismi di attenzione semplificavano il processo. Invece di tradurre parola per parola, i meccanismi di attenzione assegnano vettori di lunghezza fissa per catturare il significato complessivo e il sentimento dell’input, con conseguenti traduzioni più accurate. Il framework di attenzione è particolarmente utile quando si affrontano le limitazioni del modello di traduzione encoder-decoder. Consente un allineamento e una traduzione precisi delle frasi e delle frasi di input.
A differenza dell’encoding dell’intera sequenza di input in un singolo vettore di contenuto fisso, il meccanismo di attenzione genera un vettore di contesto per ogni output, il che consente traduzioni più efficienti. È importante notare che sebbene i meccanismi di attenzione migliorino l’accuratezza delle traduzioni, potrebbero non sempre raggiungere la perfezione linguistica. Tuttavia, catturano efficacemente l’intenzione e il sentimento generale dell’input originale. In sintesi, i framework di attenzione sono uno strumento prezioso per superare le limitazioni dei modelli di traduzione automatica tradizionali e ottenere traduzioni più accurate e consapevoli del contesto.
Come operano i modelli di attenzione?
In termini generali, i modelli di attenzione utilizzano una funzione che mappa una query e un set di coppie chiave-valore per generare un output. Questi elementi, inclusa la query, le chiavi, i valori e l’output finale, sono tutti rappresentati come vettori. L’output viene calcolato prendendo una somma pesata dei valori, con i pesi determinati da una funzione di compatibilità che valuta la similarità tra la query e la chiave corrispondente.
In termini pratici, i modelli di attenzione consentono alle reti neurali di approssimare il meccanismo di attenzione visiva impiegato dagli esseri umani. Similmente a come gli esseri umani elaborano una nuova scena, il modello si concentra intensamente su un punto specifico in un’immagine, fornendo una comprensione “ad alta risoluzione”, mentre percepisce le aree circostanti con meno dettagli, come “a bassa risoluzione”. Man mano che la rete acquisisce una migliore comprensione della scena, regola il punto focale di conseguenza.
Implementazione del meccanismo di attenzione generale con NumPy e SciPy
In questa sezione, esamineremo l’implementazione del meccanismo di attenzione generale utilizzando le librerie Python NumPy e SciPy.
Per iniziare, definiamo le incapsulazioni di parole per una sequenza di quattro parole. Per semplicità, definiremo manualmente le incapsulazioni di parole, anche se nella pratica verrebbero generate da un encoder.
import numpy as np
# rappresentazioni dell'encoder di quattro parole diverse
word_1 = np.array([1, 0, 0])
word_2 = np.array([0, 1, 0])
word_3 = np.array([1, 1, 0])
word_4 = np.array([0, 0, 1])Successivamente, generiamo le matrici di peso che verranno moltiplicate con le incapsulazioni di parole per ottenere le query, le chiavi e i valori. Per questo esempio, generiamo casualmente queste matrici di peso, ma in scenari reali, sarebbero apprese durante la formazione.
np.random.seed(42)
W_Q = np.random.randint(3, size=(3, 3))
W_K = np.random.randint(3, size=(3, 3))
W_V = np.random.randint(3, size=(3, 3))Calcoliamo quindi i vettori di query, chiave e valore per ogni parola eseguendo moltiplicazioni tra le word embeddings e le rispettive matrici di peso.
query_1 = np.dot(word_1, W_Q)
key_1 = np.dot(word_1, W_K)
value_1 = np.dot(word_1, W_V)
query_2 = np.dot(word_2, W_Q)
key_2 = np.dot(word_2, W_K)
value_2 = np.dot(word_2, W_V)
query_3 = np.dot(word_3, W_Q)
key_3 = np.dot(word_3, W_K)
value_3 = np.dot(word_3, W_V)
query_4 = np.dot(word_4, W_Q)
key_4 = np.dot(word_4, W_K)
value_4 = np.dot(word_4, W_V)Procediamo quindi valutando il vettore di query della prima parola rispetto a tutte le chiavi utilizzando un’operazione di prodotto scalare.
scores = np.array([np.dot(query_1,key_1),
np.dot(query_1,key_2),np.dot(query_1,key_3),np.dot(query_1,key_4)])Per generare i pesi, applichiamo l’operazione softmax ai punteggi.
weights = np.softmax(scores / np.sqrt(key_1.shape[0]))Infine, calcoliamo l’output dell’attenzione prendendo la somma pesata di tutti i vettori di valore.
attention=(weights[0]*value_1)+(weights[1]*value_2)+(weights[2]*value_3)+(weights[3]*value_4)
print(attention)Per una computazione più veloce, questi calcoli possono essere eseguiti in forma di matrice per ottenere l’output di attenzione per tutte le quattro parole contemporaneamente. Ecco un esempio:
import numpy as np
from scipy.special import softmax
# Rappresentazione delle rappresentazioni encoder di quattro parole diverse
word_1 = np.array([1, 0, 0])
word_2 = np.array([0, 1, 0])
word_3 = np.array([1, 1, 0])
word_4 = np.array([0, 0, 1])
# word embeddings
words = np.array([word_1, word_2, word_3, word_4])
# Generazione delle matrici di peso
np. random.seed(42)
W_Q = np. random.randint(3, size=(3, 3))
W_K = np. random.randint(3, size=(3, 3))
W_V = np. random.randint(3, size=(3, 3))
# Generazione delle query, chiavi e valori
Q = np.dot(words, W_Q)
K = np.dot(words, W_K)
V = np.dot(words, W_V)
# Calcolo del vettore di punteggio della query
scores = np.dot(Q, K.T)
# Calcolo dei pesi applicando l'operazione softmax
weights = softmax(scores / np.sqrt(K.shape[1]), axis=1)
# Calcolo dell'attenzione mediante la somma pesata dei vettori di valore
attention = np.dot(weights, V)
print(attention)Tipi di modelli di attenzione
- Attenzione globale e locale (local-m, local-p)
- Attenzione rigida e morbida
- Autoattenzione
Modello di attenzione globale
Il modello di attenzione globale considera l’input da ogni stato di origine (encoder) e lo stato del decoder precedente allo stato corrente per calcolare l’output. Considera la relazione tra le sequenze di origine e di destinazione. Qui sotto c’è un diagramma che illustra il modello di attenzione globale.
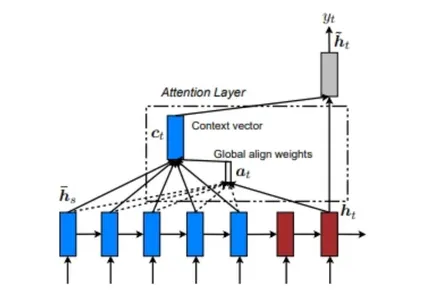
Nel modello di attenzione globale, i pesi di allineamento o i pesi di attenzione (a <t>) vengono calcolati utilizzando ogni passaggio dell’encoder e lo step precedente del decoder (h <t>). Il vettore di contesto (c <t>) viene quindi calcolato prendendo la somma pesata delle uscite dell’encoder utilizzando i pesi di allineamento. Questo vettore di riferimento viene alimentato nella cella RNN per determinare l’output del decoder.
Modello di attenzione locale
Il modello di attenzione locale differisce dal modello di attenzione globale in quanto considera solo un sottoinsieme di posizioni della sorgente (encoder) quando calcola i pesi di allineamento (a <t>). Qui sotto c’è un diagramma che illustra il modello di attenzione locale.

Il modello di attenzione locale può essere compreso dal diagramma fornito. Coinvolge la ricerca di una posizione singola allineata (p<t>) e quindi l’utilizzo di una finestra di parole provenienti dal livello di origine (codificatore), insieme a (h<t>), per calcolare i pesi di allineamento e il vettore di contesto.
Ci sono due tipi di attenzione locale: allineamento monotono ed allineamento predittivo. Nell’allineamento monotono, la posizione (p<t>) è semplicemente impostata come “t”, mentre nell’allineamento predittivo, la posizione (p<t>) è predetta da un modello predittivo invece di assumere che sia “t”.
Attenzione dura e morbida
L’attenzione morbida e il modello di attenzione globale condividono similitudini nella loro funzionalità. Tuttavia, ci sono differenze distinte tra i modelli di attenzione locale e di attenzione dura. La distinzione principale risiede nella proprietà di differenziabilità. Il modello di attenzione locale è differenziabile in ogni punto, mentre l’attenzione dura manca di differenziabilità. Ciò implica che il modello di attenzione locale consente l’ottimizzazione basata sul gradiente in tutto il modello, mentre l’attenzione dura presenta sfide per l’ottimizzazione a causa di operazioni non differenziabili.
Modello di auto-attenzione
Il modello di auto-attenzione comporta l’instaurazione di relazioni tra diverse posizioni nella stessa sequenza di input. In principio, l’auto-attenzione può utilizzare una qualsiasi delle funzioni di punteggio precedentemente menzionate, ma la sequenza di destinazione viene sostituita con la stessa sequenza di input.
Rete trasformatrice
La rete trasformatrice è costruita interamente basandosi sui meccanismi di auto-attenzione, senza l’uso dell’architettura di rete ricorrente. Il trasformatore utilizza modelli di auto-attenzione multi-head.

Vantaggi e svantaggi dei meccanismi di attenzione
I meccanismi di attenzione sono un potente strumento per migliorare le prestazioni dei modelli di apprendimento profondo e presentano diversi vantaggi chiave. Alcuni dei principali vantaggi del meccanismo di attenzione sono:
- Aumento dell’accuratezza: i meccanismi di attenzione contribuiscono a migliorare l’accuratezza delle previsioni consentendo al modello di concentrarsi sulle informazioni più pertinenti.
- Aumento dell’efficienza: elaborando solo i dati più importanti, i meccanismi di attenzione migliorano l’efficienza del modello. Ciò riduce le risorse computazionali richieste e migliora la scalabilità del modello.
- Miglioramento dell’interpretabilità: i pesi di attenzione appresi dal modello forniscono preziose informazioni sugli aspetti più critici dei dati. Ciò aiuta a migliorare l’interpretabilità del modello e aiuta a comprendere il suo processo decisionale.
Tuttavia, il meccanismo di attenzione ha anche degli svantaggi che devono essere considerati. I principali svantaggi sono:
- Difficoltà di addestramento: addestrare i meccanismi di attenzione può essere difficile, soprattutto per compiti grandi e complessi. L’apprendimento dei pesi di attenzione dai dati richiede spesso una quantità considerevole di dati e risorse computazionali.
- Overfitting: i meccanismi di attenzione possono essere suscettibili all’overfitting. Sebbene il modello possa funzionare bene sui dati di addestramento, potrebbe avere difficoltà a generalizzarsi efficacemente ai nuovi dati. L’utilizzo di tecniche di regolarizzazione può mitigare questo problema, ma rimane difficile per compiti grandi e complessi.
- Bias di esposizione: i meccanismi di attenzione possono soffrire di problemi di bias di esposizione durante l’addestramento. Ciò si verifica quando il modello viene addestrato per generare la sequenza di output un passo alla volta, ma viene valutato producendo l’intera sequenza in una volta sola. Questa discrepanza può comportare una scarsa performance sui dati di test, poiché il modello potrebbe avere difficoltà a riprodurre con precisione l’intera sequenza di output.
È importante riconoscere sia i vantaggi che gli svantaggi dei meccanismi di attenzione al fine di prendere decisioni informate riguardo al loro utilizzo nei modelli di apprendimento profondo.
Suggerimenti per l’utilizzo dei framework di attenzione
Quando si implementa un framework di attenzione, considerare i seguenti suggerimenti per migliorare la sua efficacia:
- Comprendere i diversi modelli: Familiarizzarsi con i vari modelli di framework di attenzione disponibili. Ogni modello ha caratteristiche e vantaggi unici, quindi la valutazione di essi aiuterà a scegliere il framework più adatto per ottenere risultati accurati.
- Fornire un addestramento coerente: l’addestramento coerente della rete neurale è cruciale. Utilizzare tecniche come il back-propagation e il reinforcement learning per migliorare l’efficacia e l’accuratezza del framework di attenzione. Ciò consente di identificare eventuali errori nel modello e aiuta a perfezionare e migliorare le sue prestazioni.
- Applicare i meccanismi di attenzione a progetti di traduzione: sono particolarmente adatti per le traduzioni di lingue. Incorporando i meccanismi di attenzione nelle attività di traduzione, è possibile migliorare l’accuratezza delle traduzioni. Il meccanismo di attenzione assegna pesi appropriati alle diverse parole, catturando la loro rilevanza e migliorando la qualità generale della traduzione.
Applicazione dei meccanismi di attenzione
Alcuni dei principali utilizzi del meccanismo di attenzione sono:
- Utilizzare i meccanismi di attenzione in compiti di elaborazione del linguaggio naturale (NLP), tra cui la traduzione automatica, il riassunto del testo e la risposta alle domande. Questi meccanismi svolgono un ruolo cruciale nell’aiutare i modelli a comprendere il significato delle parole all’interno di un testo e ad enfatizzare le informazioni più pertinenti.
- Anche i compiti di visione artificiale, come la classificazione delle immagini e il riconoscimento degli oggetti, traggono vantaggio dai meccanismi di attenzione. Utilizzando l’attenzione, i modelli possono identificare porzioni di un’immagine e concentrarsi sull’analisi di oggetti specifici.
- I compiti di riconoscimento della voce implicano la trascrizione dei suoni registrati e il riconoscimento dei comandi vocali. I meccanismi di attenzione si dimostrano utili in questi compiti, consentendo ai modelli di concentrarsi su segmenti del segnale audio e riconoscere con precisione le parole pronunciate.
- I meccanismi di attenzione sono anche utili nei compiti di produzione musicale, come la generazione di melodie e progressioni di accordi. Utilizzando l’attenzione, i modelli possono enfatizzare gli elementi musicali essenziali e generare composizioni coerenti ed espressive.
Conclusione
I meccanismi di attenzione hanno acquisito un’ampia diffusione in vari settori, tra cui la visione artificiale. Tuttavia, la maggior parte della ricerca e dello sviluppo sui meccanismi di attenzione si è concentrata sulla traduzione automatica neurale (NMT). I sistemi di traduzione automatica convenzionali si basano pesantemente su ampi set di dati etichettati con caratteristiche complesse che mappano le proprietà statistiche di ogni parola.
In contrasto, i meccanismi di attenzione offrono un approccio più semplice per la NMT. In questo approccio, codifichiamo il significato di una frase in un vettore di lunghezza fissa e lo utilizziamo per generare una traduzione. Piuttosto che tradurre parola per parola, il meccanismo di attenzione si concentra sulla cattura del sentimento generale o delle informazioni di alto livello di una frase. Adottando questo approccio basato sull’apprendimento, i sistemi NMT non solo ottengono miglioramenti significativi in termini di accuratezza, ma beneficiano anche di processi di costruzione più semplici e di addestramento più veloci.
Punti salienti
- Il meccanismo di attenzione è uno strato di rete neurale che si integra nei modelli di apprendimento profondo.
- Consente al modello di concentrarsi su parti specifiche dell’input assegnando pesi in base alla loro rilevanza per il compito.
- I meccanismi di attenzione si sono dimostrati altamente efficaci in vari compiti, tra cui la traduzione automatica, la descrizione delle immagini e il riconoscimento della voce.
- Sono particolarmente vantaggiosi quando si tratta di sequenze di input lunghe, poiché consentono al modello di concentrarsi selettivamente sulle parti più rilevanti.
- I meccanismi di attenzione possono migliorare l’interpretabilità del modello rappresentando visivamente le parti dell’input a cui il modello sta prestano attenzione.
Domande frequenti
I media mostrati in questo articolo non sono di proprietà di Analytics Vidhya e sono utilizzati a discrezione dell’autore.