La velocità è tutto ciò di cui hai bisogno accelerazione on-device di grandi modelli di diffusione tramite ottimizzazioni consapevoli della GPU.
La velocità è ottenuta tramite accelerazione on-device dei grandi modelli di diffusione con ottimizzazioni GPU consapevoli.
Pubblicato da Juhyun Lee e Raman Sarokin, Ingegneri del Software, Core Systems & Experiences
La proliferazione di grandi modelli di diffusione per la generazione di immagini ha portato ad un significativo aumento delle dimensioni dei modelli e dei carichi di lavoro di inferenza. L’inferenza di ML on-device in ambienti mobili richiede una minuziosa ottimizzazione delle prestazioni e la considerazione dei compromessi dovuti ai vincoli delle risorse. L’esecuzione dell’inferenza di grandi modelli di diffusione (LDMs) on-device, guidata dalla necessità di efficienza dei costi e della privacy degli utenti, presenta ancora maggiori sfide a causa dei sostanziali requisiti di memoria e delle esigenze computazionali di questi modelli.
Affrontiamo questa sfida nel nostro lavoro intitolato “La velocità è tutto ciò di cui hai bisogno: accelerazione on-device di grandi modelli di diffusione tramite ottimizzazioni GPU-aware” (che verrà presentato presso il workshop CVPR 2023 per l’Apprendimento Profondo Efficient per la Visione Artificiale) focalizzandoci sull’esecuzione ottimizzata di un modello LDM fondamentale su una GPU mobile. In questo post del blog, riassumiamo le tecniche principali che abbiamo impiegato per eseguire con successo grandi modelli di diffusione come Stable Diffusion a piena risoluzione (512×512 pixel) e 20 iterazioni su smartphone moderni con una velocità di inferenza ad alte prestazioni del modello originale senza distillazione di meno di 12 secondi. Come discusso nel nostro precedente post del blog, l’inferenza di ML accelerata da GPU è spesso limitata dalle prestazioni della memoria, e l’esecuzione di LDM non fa eccezione. Pertanto, il tema centrale della nostra ottimizzazione è l’efficiente input/output (I/O) della memoria, anche se ciò comporta la scelta di algoritmi efficienti in termini di memoria rispetto a quelli che privilegiano l’efficienza dell’unità logica aritmetica. In definitiva, il nostro obiettivo principale è quello di ridurre la latenza complessiva dell’inferenza di ML.
 |
| Un output campione di un LDM su Mobile GPU con il testo di prompt: “un’immagine ad alta risoluzione e fotorealistica di un cucciolo carino con fiori circostanti”. |
Modulo di attenzione potenziata per l’efficienza della memoria
Un motore di inferenza di ML fornisce tipicamente una varietà di operazioni di ML ottimizzate. Tuttavia, l’ottenimento di prestazioni ottimali può ancora rappresentare una sfida in quanto esiste una certa quantità di overhead per l’esecuzione di singoli operatori di rete neurale su una GPU. Per mitigare questo overhead, i motori di inferenza di ML incorporano estese regole di fusione dell’operatore che consolidano più operatori in un singolo operatore, riducendo così il numero di iterazioni attraverso gli elementi del tensore e massimizzando il calcolo per iterazione. Ad esempio, TensorFlow Lite utilizza la fusione dell’operatore per combinare operazioni computazionalmente costose, come le convoluzioni, con funzioni di attivazione successive, come le unità rettificate lineari, in una sola.
- Rivoluzionare l’efficienza dell’AI SqueezeLLM dell’UC Berkeley presenta la quantizzazione densa e sparso, unendo qualità e velocità nella gestione di grandi modelli di linguaggio.
- Meta AI rompe le barriere con Voicebox un modello di IA generativa senza precedenti che rivoluziona il campo della sintesi del parlato.
- Meta AI svela l’innovativo I-JEPA un avanzamento rivoluzionario nella computer vision che emula l’apprendimento e il ragionamento umano e animale.
Un’opportunità chiara per l’ottimizzazione è il blocco di attenzione ampiamente utilizzato adottato nel modello del denoiser nel LDM. I blocchi di attenzione consentono al modello di concentrarsi su parti specifiche dell’input assegnando pesi più elevati alle regioni importanti. Esistono molteplici modi per ottimizzare i moduli di attenzione, e impieghiamo selettivamente una delle due ottimizzazioni spiegate di seguito a seconda di quale ottimizzazione svolga meglio la sua funzione.
La prima ottimizzazione, che chiamiamo softmax parzialmente fuso, elimina la necessità di ampie scritture e letture di memoria tra il softmax e la moltiplicazione della matrice nel modulo di attenzione. Facciamo in modo che il blocco di attenzione sia solo una semplice moltiplicazione della matrice della forma Y = softmax( X ) * W dove X e W sono matrici 2D di forma a × b e b × c, rispettivamente (mostrate di seguito nella metà superiore).
Per la stabilità numerica, T = softmax( X ) viene generalmente calcolato in tre passaggi:
- Determinare il valore massimo nell’elenco, ossia per ogni riga nella matrice X
- Sommare le differenze dell’esponenziale di ogni elemento dell’elenco e il valore massimo (dal passaggio 1)
- Dividere l’esponenziale degli elementi meno il valore massimo per la somma dal passaggio 2
Svolgere in modo ingenuo questi passaggi risultarebbe in una grande scrittura di memoria per il tensore intermedio temporaneo T che tiene l’output dell’intera funzione softmax. Possiamo evitare questa grande scrittura di memoria se memorizziamo solo i risultati dei passaggi 1 e 2, etichettati rispettivamente m e s, che sono piccoli vettori, con a elementi ciascuno, rispetto a T che ha a·b elementi. Con questa tecnica siamo in grado di ridurre di diverse decine o anche centinaia di megabyte il consumo di memoria in modo significativo (come mostrato nella metà inferiore dell’immagine qui sotto).
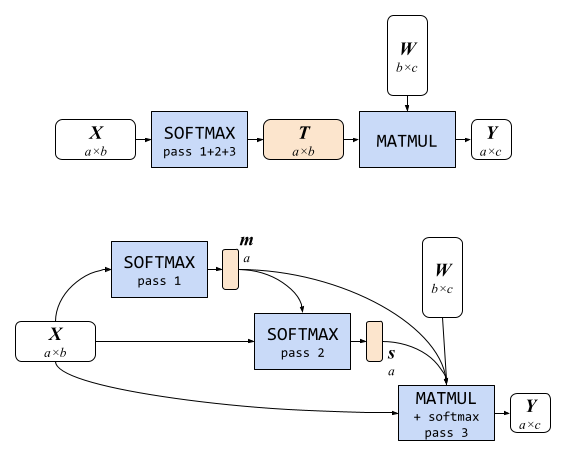 |
| Moduli di attenzione. In alto: un blocco di attenzione ingenuo, composto da una SOFTMAX (con tutti e tre i passaggi) e una MATMUL, richiede una grande scrittura di memoria per il grande tensore intermedio T. In basso: il nostro blocco di attenzione efficiente in termini di memoria grazie alla softmax parzialmente fusa in MATMUL ha bisogno di memorizzare solo due piccoli tensori intermedi per m e s. |
L’altra ottimizzazione consiste nell’utilizzare FlashAttention, un algoritmo di attenzione esatto consapevole dell’I/O. Questo algoritmo riduce il numero di accessi alla memoria ad alta larghezza di banda della GPU, rendendolo adatto al nostro caso d’uso con limitazioni di larghezza di banda della memoria. Tuttavia, abbiamo scoperto che questa tecnica funziona solo per SRAM con determinate dimensioni e richiede un gran numero di registri. Di conseguenza, utilizziamo questa tecnica solo per le matrici di attenzione con determinate dimensioni su un insieme selezionato di GPU.
Convoluzione rapida di Winograd per i layer di convoluzione 3×3
La struttura di base dei modelli di apprendimento automatico dipende pesantemente dai layer di convoluzione 3×3 (convoluzioni con dimensione del filtro 3×3), che costituiscono oltre il 90% dei layer del decoder. Nonostante il maggior consumo di memoria e gli errori numerici, abbiamo scoperto che la convoluzione rapida di Winograd è efficace per velocizzare le convoluzioni. Diversamente dalla dimensione del filtro 3×3 utilizzata nelle convoluzioni, la dimensione della mattonella si riferisce alla dimensione di una sotto-regione del tensore di input che viene elaborata in un momento. L’aumento della dimensione della mattonella aumenta l’efficienza della convoluzione in termini di utilizzo dell’unità logica aritmetica (ALU). Tuttavia, questo miglioramento avviene a spese di un maggiore consumo di memoria. I nostri test indicano che una dimensione della mattonella di 4×4 raggiunge il giusto compromesso tra l’efficienza computazionale e l’utilizzo della memoria.
| Utilizzo della memoria | |||
| Dimensione della mattonella | Risparmio di FLOPS | Tensori intermedi | Pesi |
| 2×2 | 2.25× | 4.00× | 1.77× |
| 4×4 | 4.00× | 2.25× | 4.00× |
| 6×6 | 5.06× | 1.80× | 7.12× |
| 8×8 | 5.76× | 1.56× | 11.1× |
| Impatto di Winograd con dimensioni di blocco variabili per convoluzioni 3×3. |
Fusione di operatori specializzata per l’efficienza della memoria
Abbiamo scoperto che per inferire performantemente LDM su una GPU mobile è necessario utilizzare finestre di fusione significativamente più grandi per i livelli e le unità comunemente impiegati in LDM rispetto a quanto offrono attualmente i motori di inferenza ML accelerati su GPU disponibili in commercio. Di conseguenza, abbiamo sviluppato implementazioni specializzate in grado di eseguire un’ampia gamma di operatori neurali rispetto alle regole di fusione tipiche. In particolare, ci siamo concentrati su due specializzazioni: la Gaussian Error Linear Unit (GELU) e il livello di normalizzazione di gruppo.
Un’approssimazione di GELU con la funzione tangente iperbolica richiede la scrittura e la lettura di sette tensori intermedi ausiliari (mostrati di seguito come rettangoli arrotondati arancioni chiari nella figura sottostante), la lettura dal tensore di input x tre volte e la scrittura nel tensore di output y una volta in otto programmi GPU che implementano l’operazione etichettata (rettangoli blu chiari). Una implementazione GELU personalizzata che esegue le otto operazioni in un singolo shader (mostrato di seguito in basso) può bypassare tutte le operazioni di I/O in memoria per i tensori intermedi.
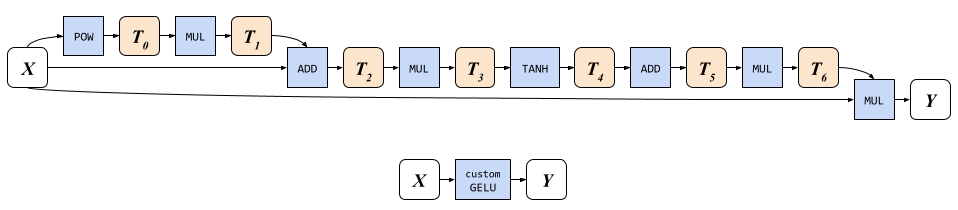 |
| Implementazioni GELU. In alto: Un’implementazione ingenua con operazioni integrate richiederebbe 8 scritture in memoria e 10 letture. In basso: La nostra implementazione GELU personalizzata richiede solo 1 lettura in memoria (per x) e 1 scrittura (per y). |
Risultati
Dopo aver applicato tutte queste ottimizzazioni, abbiamo condotto test di Stable Diffusion 1.5 (risoluzione dell’immagine 512×512, 20 iterazioni) su dispositivi mobili di alta gamma. L’esecuzione di Stable Diffusion con il nostro modello di inferenza ML accelerato su GPU utilizza 2.093 MB per i pesi e 84 MB per i tensori intermedi. Con gli ultimi smartphone di alta gamma, Stable Diffusion può essere eseguito in meno di 12 secondi.
 |
| Stable Diffusion viene eseguito su smartphone moderni in meno di 12 secondi. Si noti che l’esecuzione del decodificatore dopo ogni iterazione per visualizzare l’output intermedio in questo GIF animato comporta un rallentamento di circa 2x. |
Conclusione
L’esecuzione dell’inferenza ML su dispositivi di grandi dimensioni si è rivelata una sfida sostanziale, che comprende limitazioni nella dimensione del file del modello, requisiti di memoria di runtime estesi e latenza di inferenza prolungata. Riconoscendo l’utilizzo della larghezza di banda della memoria come il principale collo di bottiglia, abbiamo diretto i nostri sforzi verso l’ottimizzazione dell’utilizzo della larghezza di banda della memoria e la ricerca di un equilibrio delicato tra efficienza dell’ALU ed efficienza della memoria. Di conseguenza, abbiamo raggiunto una latenza di inferenza all’avanguardia per grandi modelli di diffusione. È possibile approfondire questo lavoro nel paper.
Ringraziamenti
Desideriamo ringraziare Yu-Hui Chen, Jiuqiang Tang, Frank Barchard, Yang Zhao, Joe Zou, Khanh LeViet, Chuo-Ling Chang, Andrei Kulik, Lu Wang e Matthias Grundmann.




