Llama 2 impara a programmare
L2 impara a programmare
Introduzione
Code Llama è una famiglia di versioni all’avanguardia e ad accesso aperto di Llama 2 specializzate in compiti di codice, e siamo entusiasti di rilasciare l’integrazione nell’ecosistema Hugging Face! Code Llama è stato rilasciato con la stessa licenza comunitaria permissiva di Llama 2 ed è disponibile per un uso commerciale.
Oggi, siamo entusiasti di rilasciare:
- Modelli nell’Hub con le loro schede modello e licenza
- Integrazione con Transformers
- Integrazione con Inferenza di Generazione di Testo per inferenze rapide ed efficienti pronte per la produzione
- Integrazione con Endpoints di Inferenza
- Code benchmarks
I Code LLM rappresentano un’evoluzione entusiasmante per gli ingegneri del software perché possono aumentare la produttività attraverso il completamento del codice negli IDE, occuparsi di attività ripetitive o fastidiose come la scrittura di docstring o la creazione di test unitari.
Indice
- Introduzione
- Indice
- Cos’è Code Llama?
- Come utilizzare Code Llama?
- Demo
- Transformers
- Completamento del Codice
- Riempimento del Codice
- Istruzioni Conversazionali
- Caricamento a 4 bit
- Utilizzo di inferenza di generazione di testo e Endpoints di Inferenza
- Valutazione
- Risorse Aggiuntive
Cos’è Code Llama?
Il rilascio di Code Llama introduce una famiglia di modelli di 7, 13 e 34 miliardi di parametri. I modelli di base sono inizializzati da Llama 2 e quindi addestrati su 500 miliardi di token di codice. Meta ha affinato ulteriormente questi modelli di base per due varianti diverse: una specializzata in Python (100 miliardi di token aggiuntivi) e una versione affinata per l’inserimento di istruzioni, in grado di comprendere istruzioni in linguaggio naturale.
- Come confrontare un processore quantistico rumoroso con un computer classico
- Attacco informatico chiude i telescopi principali finanziati dalla NSF per più di 2 settimane
- Gli scienziati sequenziano l’ultimo pezzo del genoma umano il cromosoma Y
I modelli mostrano prestazioni all’avanguardia in Python, C++, Java, PHP, C#, TypeScript e Bash. Le varianti base da 7B e 13B e quelle con istruzioni supportano il riempimento in base al contenuto circostante, rendendoli ideali per l’utilizzo come assistenti di codice.
Code Llama è stato addestrato su una finestra di contesto di 16k. Inoltre, le tre varianti del modello hanno avuto ulteriori affinamenti su contesti lunghi, consentendo loro di gestire una finestra di contesto fino a 100.000 token.
L’aumento della finestra di contesto di Llama 2 da 4k a 16k di Code Llama (che può arrivare fino a 100k) è stato possibile grazie agli sviluppi recenti in RoPE scaling. La comunità ha scoperto che i posizionamenti di Llama possono essere interpolati linearmente o nel dominio delle frequenze, il che facilita la transizione a una finestra di contesto più ampia attraverso l’affinamento. Nel caso di Code Llama, lo scaling nel dominio delle frequenze avviene con una flessibilità: la lunghezza dell’affinamento è una frazione della lunghezza preaddestrata scalata, conferendo al modello potenti capacità di interpolazione.
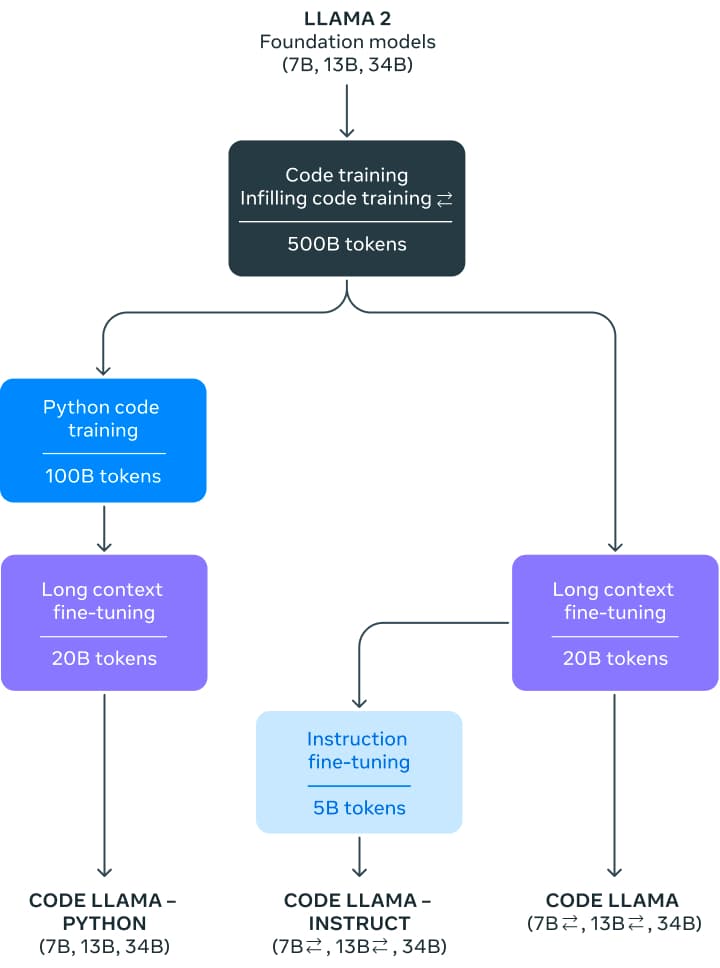
Tutti i modelli sono stati inizialmente addestrati con 500 miliardi di token su un dataset quasi deduplicato di codice disponibile pubblicamente. Il dataset contiene anche alcuni dataset di linguaggio naturale, come discussioni sul codice e frammenti di codice. Sfortunatamente, non ci sono altre informazioni sul dataset.
Per il modello di istruzioni, sono stati utilizzati due dataset: il dataset di accordatura delle istruzioni raccolto per Llama 2 Chat e un dataset auto-istruttivo. Il dataset auto-istruttivo è stato creato utilizzando Llama 2 per creare domande di programmazione per un’intervista e poi utilizzando Code Llama per generare test unitari e soluzioni, che vengono successivamente valutati eseguendo i test.
Come utilizzare Code Llama?
Code Llama è disponibile nell’ecosistema Hugging Face, a partire dalla versione transformers 4.33. Fino al rilascio di transformers 4.33, è necessario installarlo dal ramo principale.
Demo
Puoi facilmente provare il Modello di Code Llama (13 miliardi di parametri!) in questo Spazio o nel playground incorporato di seguito:
Nel backstage, questo playground utilizza l’Inferenza di Generazione di Testo di Hugging Face, la stessa tecnologia che alimenta HuggingChat, e condivideremo ulteriori informazioni nelle sezioni seguenti.
Transformers
Con il prossimo rilascio di transformers 4.33, puoi utilizzare Code Llama e sfruttare tutti gli strumenti all’interno dell’ecosistema HF, come ad esempio:
- script e esempi per l’addestramento e l’inferenza
- formato di file sicuro (
safetensors) - integrazioni con strumenti come
bitsandbytes(quantizzazione a 4 bit) e PEFT (fine-tuning efficiente dei parametri) - utility e assistenti per eseguire la generazione con il modello
- meccanismi per esportare i modelli per il deploy
Fino al rilascio di transformers 4.33, installalo dalla branch principale.
!pip install git+https://github.com/huggingface/transformers.git@main accelerateCompletamento del Codice
I modelli 7B e 13B possono essere utilizzati per il completamento del testo/codice o l’inserimento. Il seguente frammento di codice utilizza l’interfaccia pipeline per mostrare un esempio di completamento del testo. Funziona sulla versione gratuita di Colab, purché selezioni un runtime con GPU.
from transformers import AutoTokenizer
import transformers
import torch
tokenizer = AutoTokenizer.from_pretrained("codellama/CodeLlama-7b-hf")
pipeline = transformers.pipeline(
"text-generation",
model="codellama/CodeLlama-7b-hf",
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'def fibonacci(',
do_sample=True,
temperature=0.2,
top_p=0.9,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=100,
)
for seq in sequences:
print(f"Risultato: {seq['generated_text']}")Ciò potrebbe produrre un output simile al seguente:
Risultato: def fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fibonacci(n-1) + fibonacci(n-2)
def fibonacci_memo(n, memo={}):
if n == 0:
return 0
elif n == 1:
returnCode Llama è specializzato nella comprensione del codice, ma è anche un modello di linguaggio a sé stante. Puoi utilizzare la stessa strategia di generazione per completare commenti o testo generale.
Inserimento del Codice
Questa è una task specializzata particolare per i modelli di codice. Il modello è addestrato per generare il codice (compresi i commenti) che meglio corrisponde a un prefisso e un suffisso esistenti. Questa è la strategia tipicamente utilizzata dagli assistenti per il codice: vengono chiesti di completare la posizione corrente del cursore, considerando il contenuto che appare prima e dopo di essa.
Questa task è disponibile nelle varianti base e instruction dei modelli 7B e 13B. Non è disponibile per nessuno dei modelli 34B o le versioni di Python.
Per utilizzare questa funzionalità con successo, devi prestare attenzione al formato utilizzato per addestrare il modello per questa task, poiché utilizza separatori speciali per identificare le diverse parti dell’input. Vediamo un esempio:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "codellama/CodeLlama-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16
).to("cuda")
prefix = 'def remove_non_ascii(s: str) -> str:\n """ '
suffix = "\n return result\n"
prompt = f"<PRE> {prefix} <SUF>{suffix} <MID>"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(
inputs["input_ids"],
max_new_tokens=200,
do_sample=False,
)
output = output[0].to("cpu")
print(tokenizer.decode(output))
<s> <PRE> def remove_non_ascii(s: str) -> str:
""" <SUF>
return result
<MID>
Rimuove i caratteri non-ASCII da una stringa.
:param s: La stringa da cui rimuovere i caratteri non-ASCII.
:return: La stringa con i caratteri non-ASCII rimossi.
"""
result = ""
for c in s:
if ord(c) < 128:
result += c <EOT></s>Per utilizzare il completamento, sarà necessario elaborare l’output per tagliare il testo compreso tra i token <MID> e <EOT> – è quello che va tra il prefisso e il suffisso che abbiamo fornito.
Istruzioni Conversazionali
Il modello di base può essere utilizzato sia per completamento che per riempimento, come descritto. Il rilascio di Code Llama include anche un modello addestrato sulle istruzioni che può essere utilizzato nelle interfacce conversazionali.
Per preparare gli input per questo compito, è necessario utilizzare un template di prompt come quello descritto nel nostro post sul blog Llama 2, che riproduciamo qui di seguito:
<s>[INST] <<SYS>>
{{ system_prompt }}
<</SYS>>
{{ user_msg_1 }} [/INST] {{ model_answer_1 }} </s><s>[INST] {{ user_msg_2 }} [/INST]Si noti che il prompt di sistema è opzionale: il modello funzionerà anche senza di esso, ma è possibile utilizzarlo per configurare ulteriormente il suo comportamento o stile. Ad esempio, se si desidera sempre ottenere risposte in JavaScript, è possibile specificarlo qui. Dopo il prompt di sistema, è necessario fornire tutte le interazioni precedenti nella conversazione: ciò che è stato chiesto dall’utente e ciò che è stato risposto dal modello. Come nel caso del riempimento, è necessario prestare attenzione ai delimitatori utilizzati. L’ultimo componente dell’input deve essere sempre un’istruzione utente nuova, che sarà il segnale per il modello di fornire una risposta.
I seguenti frammenti di codice dimostrano come funziona il template nella pratica.
- Prima richiesta dell’utente, senza prompt di sistema
user = 'In Bash, come faccio a elencare tutti i file di testo nella directory corrente (escludendo le sottodirectory) che sono stati modificati nell\'ultimo mese?'
prompt = f"<s>[INST] {user.strip()} [/INST]"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")- Prima richiesta dell’utente con prompt di sistema
system = "Fornisci risposte in JavaScript"
user = "Scrivi una funzione che calcola l'insieme delle somme di tutte le sottoliste contigue di una data lista."
prompt = f"<s><<SYS>>\\n{system}\\n<</SYS>>\\n\\n{user}"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")- Conversazione in corso con risposte precedenti
Il processo è lo stesso di Llama 2. Non abbiamo utilizzato cicli o generalizzato questo codice di esempio per massima chiarezza:
system = "Prompt di sistema"
user_1 = "Prompt utente 1"
answer_1 = "Risposta 1"
user_2 = "Prompt utente 2"
answer_2 = "Risposta 2"
user_3 = "Prompt utente 3"
prompt = f"<<SYS>>\\n{system}\\n<</SYS>>\\n\\n{user_1}"
prompt = f"<s>[INST] {prompt.strip()} [/INST] {answer_1.strip()} </s>"
prompt += f"<s>[INST] {user_2.strip()} [/INST] {answer_2.strip()} </s>"
prompt += f"<s>[INST] {user_3.strip()} [/INST]"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")Caricamento a 4 bit
L’integrazione di Code Llama in Transformers significa che si ottiene un supporto immediato per funzionalità avanzate come il caricamento a 4 bit. Ciò consente di eseguire modelli con grandi parametri da 32 miliardi su GPU per consumatori come le schede Nvidia 3090!
Ecco come è possibile eseguire l’inferenza in modalità a 4 bit:
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import torch
model_id = "codellama/CodeLlama-34b-hf"
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=quantization_config,
device_map="auto",
)
prompt = 'def remove_non_ascii(s: str) -> str:\n """ '
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(
inputs["input_ids"],
max_new_tokens=200,
do_sample=True,
top_p=0.9,
temperature=0.1,
)
output = output[0].to("cpu")
print(tokenizer.decode(output))Utilizzo di text-generation-inference e Inference Endpoints
Text Generation Inference è un contenitore di inferenza pronto per la produzione sviluppato da Hugging Face per consentire un facile deployment di grandi modelli linguistici. Ha funzionalità come batching continuo, token streaming, parallelismo dei tensori per l’inferenza veloce su più GPU e logging e tracciamento pronti per la produzione.
Puoi provare Text Generation Inference sulla tua infrastruttura oppure puoi utilizzare gli Inference Endpoints di Hugging Face. Per distribuire un modello Codellama 2, vai alla pagina del modello e clicca sul widget Deploy -> Inference Endpoints.
- Per i modelli da 7B, ti consigliamo di selezionare “GPU [VoAGI] – 1x Nvidia A10G”.
- Per i modelli da 13B, ti consigliamo di selezionare “GPU [xlarge] – 1x Nvidia A100”.
- Per i modelli da 34B, ti consigliamo di selezionare “GPU [1xlarge] – 1x Nvidia A100” con quantizzazione
bitsandbytesabilitata o “GPU [2xlarge] – 2x Nvidia A100”.
Nota: Potrebbe essere necessario richiedere un upgrade di quota tramite email a [email protected] per accedere alle A100.
Puoi saperne di più su come distribuire LLM con gli Inference Endpoints di Hugging Face nel nostro blog. Il blog include informazioni su iperparametri supportati e su come effettuare lo streaming della risposta utilizzando Python e Javascript.
Valutazione
I modelli linguistici per il codice vengono tipicamente valutati su dataset come HumanEval. Esso consiste in sfide di programmazione in cui al modello viene presentata una firma di funzione e una descrizione e viene incaricato di completare il corpo della funzione. La soluzione proposta viene quindi verificata eseguendo un insieme di test unitari predefiniti. Infine, viene riportata una percentuale di successo che descrive quante soluzioni hanno superato tutti i test. La percentuale pass@1 descrive quanto spesso il modello genera una soluzione che supera il test al primo tentativo, mentre la percentuale pass@10 descrive quanto spesso almeno una soluzione supera su 10 candidati proposti.
Sebbene HumanEval sia un benchmark Python, sono stati fatti notevoli sforzi per tradurlo in più linguaggi di programmazione e consentire una valutazione più olistica. Un approccio del genere è MultiPL-E, che traduce HumanEval in oltre una dozzina di lingue. Ospitiamo una classifica di codice multilingue basata su di esso per consentire alla comunità di confrontare i modelli in diverse lingue e valutare quale modello si adatta meglio al proprio caso d’uso.
Nota: I punteggi presentati nella tabella sopra sono tratti dalla nostra classifica di codice, dove valutiamo tutti i modelli con le stesse impostazioni. Per ulteriori dettagli, consulta la classifica.
Risorse aggiuntive
- Modelli su Hub
- Pagina del paper
- Annuncio ufficiale di Meta
- Guida all’uso responsabile
- Demo


