Introduzione alla Correlazione
Introduction to Correlation.
Impara le basi della correlazione e del suo utilizzo in data science e machine learning.
Dopo aver letto questo articolo, il lettore imparerà quanto segue:
- Definizione di correlazione
- Correlazione positiva
- Correlazione negativa
- Assenza di correlazione
- Definizione matematica della correlazione
- Implementazione in Python del coefficiente di correlazione
- Matrice di covarianza
- Implementazione in Python della matrice di covarianza
Correlazione
La correlazione misura il grado di co-movimento di due variabili.
- L’IA sta mangiando la scienza dei dati.
- Paesaggio di Ingegneria dei Dati nel Mondo Guidato dall’AI
- Strumenti di analisi dati che devi conoscere nel 2023
Correlazione positiva
Se la variabile Y aumenta quando la variabile X aumenta, allora X e Y sono positivamente correlati come mostrato di seguito: 
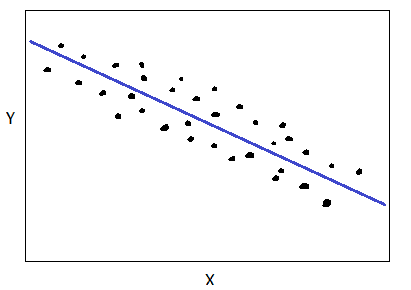
Correlazione negativa
Se la variabile Y diminuisce quando la variabile X aumenta, allora X e Y sono negativamente correlati come mostrato di seguito:
Assenza di correlazione
Quando non c’è una relazione evidente tra X e Y, diciamo che X e Y sono non correlati, come mostrato di seguito:

Definizione matematica della correlazione
Siano X e Y due caratteristiche date da
X = (X1 , X2 , . . ., Xn ) Y = (Y1 , Y2 , . . ., Yn )
Il coefficiente di correlazione tra X e Y è dato da

dove mu e sigma rappresentano la media e la deviazione standard, rispettivamente, e Xstd è la caratteristica standardizzata per la variabile X. Il coefficiente di correlazione è il prodotto scalare tra le caratteristiche standardizzate di X e Y. Il coefficiente di correlazione assume valori compresi tra -1 e 1. Un valore vicino a 1 significa una forte correlazione positiva, un valore vicino a -1 significa una forte correlazione negativa e un valore vicino a zero significa bassa correlazione o assenza di correlazione.
Implementazione in Python del coefficiente di correlazione
import numpy as np
import matplotlib.pyplot as plt
n = 100
X = np.random.uniform(1,10,n)
Y = np.random.uniform(1,10,n)
plt.scatter(X,Y)
plt.show()
X_std = (X - np.mean(X))/np.std(X)
Y_std = (Y - np.mean(Y))/np.std(Y)
np.dot(X_std, Y_std)/n
0.2756215872210571
# Usando numpy
np.corrcoef(X, Y)
array([[1. , 0.27562159],
[0.27562159, 1. ]])Matrice di covarianza
La matrice di covarianza è una matrice molto utile nell’ambito della scienza dei dati e dell’apprendimento automatico. Fornisce informazioni sulla co-movimentazione (correlazione) tra le caratteristiche di un dataset. La matrice di covarianza è data da:
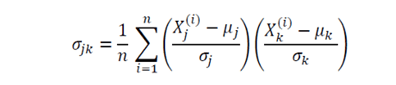
dove mu e sigma rappresentano la media e la deviazione standard di una determinata caratteristica. Qui n è il numero di osservazioni nel dataset e i pedici j e k assumono valori 1, 2, 3, . . ., m, dove m è il numero di caratteristiche del dataset. Ad esempio, se un dataset ha 4 caratteristiche con 100 osservazioni, allora n = 100 e m = 4, quindi la matrice di covarianza sarà una matrice 4 x 4. Gli elementi diagonali saranno tutti 1, poiché rappresentano la correlazione tra una caratteristica e se stessa, che per definizione è pari a uno.
Implementazione in Python della matrice di covarianza
Supponiamo di voler calcolare il grado di correlazione tra 4 titoli tecnologici (AAPL, TSLA, GOOGL e AMZN) nel corso di un periodo di 1000 giorni. Il nostro dataset ha m = 4 caratteristiche e n = 1000 osservazioni. La matrice di covarianza sarà quindi una matrice 4 x 4, come mostrato nella figura qui sotto.
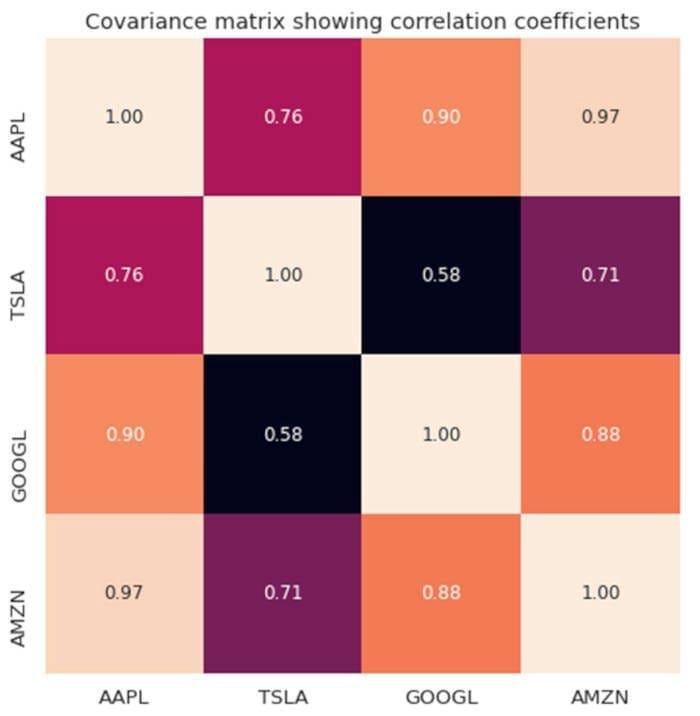 Matrice di covarianza tra i titoli tecnologici. Immagine di Author.
Matrice di covarianza tra i titoli tecnologici. Immagine di Author.
Il codice per produrre la figura sopra può essere trovato qui: Algebra Lineare Essenziale per Data Science e Machine Learning .
Sommario
In sintesi, abbiamo esaminato le basi della correlazione. La correlazione definisce il grado di co-movimento tra 2 variabili. Il coefficiente di correlazione assume valori compresi tra -1 e 1. Un valore vicino allo zero significa una bassa correlazione o non correlazione. Benjamin O. Tayo è un fisico, educatore di Data Science e scrittore, nonché proprietario di DataScienceHub. In precedenza, Benjamin insegnava ingegneria e fisica presso U. of Central Oklahoma, Grand Canyon U. e Pittsburgh State U.





