Integrare ChatGPT nei Flussi di Lavoro della Scienza dei Dati Consigli e Migliori Pratiche
'Integrating ChatGPT into Data Science Workflows Tips and Best Practices'
Stai cercando di integrare ChatGPT nel tuo flusso di lavoro di data science? Ecco un esempio insieme a consigli e migliori pratiche per ottenere il massimo da ChatGPT per la data science.

ChatGPT, il suo successore GPT-4 e le loro alternative open-source sono stati estremamente di successo. Sviluppatori e scienziati dei dati cercano tutti di essere più produttivi e utilizzare ChatGPT per semplificare le loro attività quotidiane.
Qui vedremo come utilizzare ChatGPT per la scienza dei dati attraverso una sessione di programmazione in coppia con ChatGPT. Costruiremo un modello di classificazione del testo, visualizzeremo il set di dati, identificheremo i migliori iperparametri per il modello, proveremo diversi algoritmi di apprendimento automatico e altro ancora, utilizzando ChatGPT.
- Nisoo News, 31 maggio Bard per la Cheat Sheet di Data Science • Top 10 strumenti per la rilevazione di ChatGPT, GPT-4, Bard e altri LLM
- Linguaggi di programmazione per ruoli specifici dei dati
- 5 migliori pratiche per la collaborazione del team di Data Science
Per strada, daremo anche un’occhiata a determinati suggerimenti per strutturare le richieste in modo da ottenere risultati utili. Per seguire, è necessario avere un account OpenAI gratuito. Se sei un utente di GPT-4, puoi seguire gli stessi suggerimenti.
Costruire un modello funzionante più velocemente
Cerchiamo di costruire un modello di classificazione delle notizie utilizzando ChatGPT per il set di dati delle 20 newsgroup in scikit-learn.
Ecco la richiesta che ho usato: “Vorrei costruire un modello di classificazione delle notizie utilizzando il set di dati delle 20 newsgroups di sklearn. Ne sai qualcosa?”
Anche se la mia richiesta non è molto specifica in questo momento, ho indicato sia l’obiettivo che il set di dati:
- Obiettivo: costruire un nuovo modello di classificazione
- Set di dati da utilizzare: set di dati delle 20 newsgroup di scikit-learn
La risposta di ChatGPT ci dice di iniziare caricando il set di dati. 
# Carica il set di dati
newsgroups_train = fetch_20newsgroups(subset='train', shuffle=True)
newsgroups_test = fetch_20newsgroups(subset='test', shuffle=True)In quanto abbiamo anche indicato l’obiettivo (costruire un modello di classificazione del testo), ChatGPT ci indica come possiamo fare questo.
Vediamo che ci dà i seguenti passaggi:
- Utilizzando
TfidfVectorizerper la pre-elaborazione del testo e per ottenere una rappresentazione numerica. Questo approccio di utilizzare i punteggi TF-IDF è migliore rispetto all’utilizzo delle occorrenze di conteggio utilizzando unCountVectorizer. - Creazione di un modello di classificazione sulla rappresentazione numerica del set di dati utilizzando un classificatore Naive Bayes o Support Vector Machine (SVM).
Ha anche dato il codice per un classificatore Bayesiano Naive Multinomiale, quindi utilizzeremo questo e verificheremo se possiamo avere già un modello funzionante.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report
# Preelaborazione dei dati di testo
vectorizer = TfidfVectorizer(stop_words='english')
X_train = vectorizer.fit_transform(newsgroups_train.data)
X_test = vectorizer.transform(newsgroups_test.data)
# Allenamento di un classificatore Bayesiano Naive
clf = MultinomialNB()
clf.fit(X_train, newsgroups_train.target)
# Valutazione delle prestazioni del classificatore
y_pred = clf.predict(X_test)
print(classification_report(newsgroups_test.target, y_pred))Sono andato avanti e ho eseguito il codice sopra. E funziona come previsto, senza errori. Siamo passati da una schermata vuota a un modello di classificazione del testo – in pochi minuti – con una singola richiesta.
Output >>
precision recall f1-score support
0 0.80 0.69 0.74 319
1 0.78 0.72 0.75 389
2 0.79 0.72 0.75 394
3 0.68 0.81 0.74 392
4 0.86 0.81 0.84 385
5 0.87 0.78 0.82 395
6 0.87 0.80 0.83 390
7 0.88 0.91 0.90 396
8 0.93 0.96 0.95 398
9 0.91 0.92 0.92 397
10 0.88 0.98 0.93 399
11 0.75 0.96 0.84 396
12 0.84 0.65 0.74 393
13 0.92 0.79 0.85 396
14 0.82 0.94 0.88 394
15 0.62 0.96 0.76 398
16 0.66 0.95 0.78 364
17 0.95 0.94 0.94 376
18 0.94 0.52 0.67 310
19 0.95 0.24 0.38 251
accuracy 0.82 7532
macro avg 0.84 0.80 0.80 7532
weighted avg 0.83 0.82 0.81 7532Anche se abbiamo ottenuto un modello funzionante per risolvere il problema in questione, ecco alcuni consigli che possono aiutarti durante la richiesta. La richiesta avrebbe potuto essere migliore e suddivisa in passaggi più piccoli, come ad esempio:
- Per favore, dimmi di più sul dataset delle 20 nuove categorie di scikit-learn.
- Quali sono i possibili compiti che posso svolgere con questo dataset? Posso costruire un modello di classificazione del testo?
- Puoi dirmi quale algoritmo di apprendimento automatico sarà più adatto per questa applicazione?
Visualizza il Dataset
Va bene, abbiamo già costruito un modello di classificazione del testo. Ma è successo molto rapidamente, quindi rallentiamo e cerchiamo di creare una semplice visualizzazione del dataset.
In particolare, cerchiamo di comprendere la distribuzione dei campioni di addestramento tra le 20 categorie di notizie e identificare se esiste un qualsiasi squilibrio di classe.
Ecco la richiesta che ho usato: “Vorrei visualizzare il dataset per comprendere la distribuzione di classe e identificare eventuali squilibri di classe. Puoi aiutarmi con la visualizzazione?”
 ChatGPT ha suggerito che un grafico a barre o un istogramma del numero di campioni in ciascuna delle classi sarebbe una buona visualizzazione. Sembra ragionevole.
ChatGPT ha suggerito che un grafico a barre o un istogramma del numero di campioni in ciascuna delle classi sarebbe una buona visualizzazione. Sembra ragionevole.
Ecco il codice che ChatGPT ha generato per creare un semplice grafico a barre in matplotlib:
import matplotlib.pyplot as plt
# Carica il dataset
newsgroups_train = fetch_20newsgroups(subset='train', shuffle=True)
# Conta il numero di campioni per ogni classe
class_counts = {}
for label in newsgroups_train.target:
class_name = newsgroups_train.target_names[label]
if class_name in class_counts:
class_counts[class_name] += 1
else:
class_counts[class_name] = 1
# Disegna la distribuzione di classe
plt.bar(class_counts.keys(), class_counts.values())
plt.xticks(rotation=90)
plt.xlabel('Classe')
plt.ylabel('Numero di Campioni')
plt.title('Distribuzione di Classe')
plt.show()Ecco il grafico. È ordinato, le etichette sono leggibili. Possiamo anche vedere il numero di campioni in ciascuna delle 20 classi. 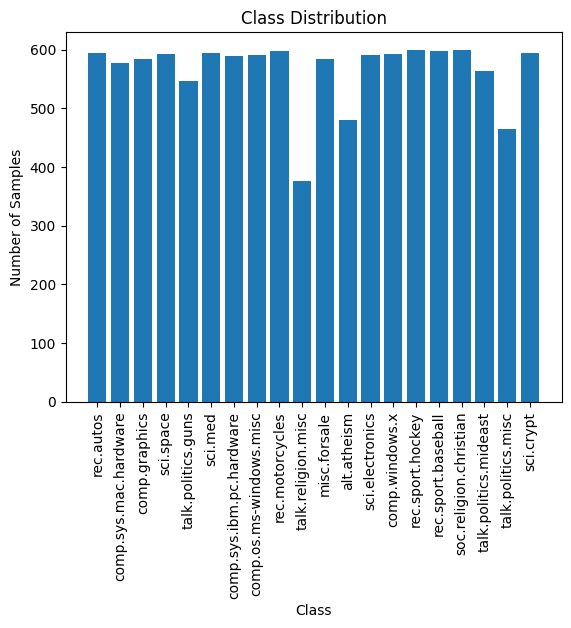
La distribuzione dei campioni di addestramento tra le 20 classi è approssimativamente uniforme e non vi è alcuno squilibrio di classe evidente. Pertanto, il modello che abbiamo ottenuto nel passaggio precedente è utile. E non abbiamo bisogno di utilizzare tecniche di ridimensionamento innovative per affrontare lo squilibrio di classe.
Tuning degli iperparametri
Successivamente, vorrei sintonizzare gli iperparametri del modello. Innanzitutto, vorrei capire i diversi iperparametri che possono essere sintonizzati. Poi, possiamo fare una semplice ricerca a griglia se non ci sono troppi iperparametri.
Ecco la richiesta: “Ci sono degli iperparametri che posso sintonizzare per migliorare il modello del classificatore?”
Nel codice che abbiamo ottenuto, anche max_df per il TfidfVectorizer è sintonizzabile. Sappiamo che il punteggio TF-IDF funziona assegnando un peso maggiore ai termini che si verificano frequentemente in un documento particolare, mentre assegna un peso sostanzialmente inferiore ai termini che si verificano frequentemente in tutti i documenti. Il max_df utilizza la percentuale di occorrenza per ignorare un termine particolare.
Ad esempio, un max_df di 0,5 indica che tutti i termini che si verificano in almeno il 50% dei documenti saranno ignorati. Se lo desideri, puoi rimuoverlo. Ma lo manterrò solo per vedere quale max_df posso utilizzare.
Il codice utilizza una semplice ricerca a griglia e sceglie i valori ottimali in base ai punteggi di convalida incrociata.
from sklearn.model_selection import GridSearchCV
from sklearn.pipeline import Pipeline
# Definisci la pipeline con TF-IDF e Naive Bayes multinomiale
pipeline = Pipeline([
('tfidf', TfidfVectorizer(stop_words='english')),
('clf', MultinomialNB())
])
# Definisci la griglia degli iperparametri
param_grid = {
'tfidf__max_df': [0.5, 0.75, 1.0],
'clf__alpha': [0.1, 0.5, 1.0],
'clf__fit_prior': [True, False],
}
# Esegui la ricerca a griglia con la convalida incrociata
grid_search = GridSearchCV(pipeline, param_grid, cv=5)
grid_search.fit(newsgroups_train.data, newsgroups_train.target)
# Stampa i migliori iperparametri e il punteggio di convalida incrociata
print("Migliori iperparametri: ", grid_search.best_params_)
print("Punteggio di convalida incrociata: ", grid_search.best_score_)
Output >>
Migliori iperparametri: {'clf__alpha': 0.1, 'clf__fit_prior': False, 'tfidf__max_df': 0.5}
Punteggio di convalida incrociata: 0.9088736147919108Inserendo i valori di questi iperparametri, ho ottenuto circa il 2% di miglioramento nell’accuratezza della classificazione.
Qui non avevamo molti iperparametri da sintonizzare. Se hai molti iperparametri in cui ognuno può assumere un insieme di valori, l’esecuzione della ricerca a griglia potrebbe essere costosa. E potrebbe avere senso eseguire invece una ricerca casuale.
Iterazione più veloce su diversi modelli
Abbiamo visto in uno dei primi passaggi che un SVM funziona bene anche per un problema di classificazione del genere.
Ora vorrei costruire un classificatore a vettori di supporto per lo stesso set di dati.
La richiesta che ho usato: “Puoi farmi sapere se posso usare un SVM per risolvere lo stesso problema? Puoi generare il codice per farlo?”
Ecco qui:
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
# Carica il set di dati
newsgroups_train = fetch_20newsgroups(subset='train', shuffle=True)
# Converti i dati di testo in una matrice di funzionalità TF-IDF
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(newsgroups_train.data)
y = newsgroups_train.target
# Dividi i dati in set di addestramento e di prova
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Definisci il classificatore SVM
clf = SVC(kernel='linear')
# Addestra il classificatore SVM
clf.fit(X_train, y_train)
# Prevedi le etichette di classe per il set di test
y_pred = clf.predict(X_test)
# Calcola l'accuratezza del classificatore SVM
accuratezza = accuracy_score(y_test, y_pred)
print('Accuracy:', accuratezza)Dato che abbiamo un punteggio di accuratezza di oltre il 90%, SVM sembra essere una buona scelta per questo set di dati.
Output >> Accuracy: 0.9019001325673884Come si può vedere, è possibile utilizzare ChatGPT per provare rapidamente diversi modelli per risolvere lo stesso problema.
Esplorazione della riduzione della dimensionalità
Dopo aver raddoppiato la costruzione di un modello funzionante, è possibile esplorare altre direzioni disponibili. Vediamo la riduzione della dimensionalità come esempio.
In questo momento, non sono interessato ad eseguire algoritmi di riduzione della dimensionalità perché ho già un modello funzionante. E lo spazio delle funzionalità non è molto ad alta dimensionalità. Quindi non è necessario ridurre il numero di dimensioni prima della costruzione del modello.
Tuttavia, vediamo gli approcci alla riduzione della dimensionalità per questo specifico set di dati.
La richiesta che ho usato: “Puoi dirmi le tecniche di riduzione della dimensionalità che posso usare per questo set di dati?”

Le seguenti tecniche sono state suggerite da ChatGPT:
- Analisi semantica latente o SVD
- Analisi delle componenti principali (PCA)
- Fattorizzazione di matrici non negative (NMF)
Concludiamo la nostra discussione elencando le migliori pratiche per utilizzare ChatGPT.
Migliori pratiche per utilizzare ChatGPT per la scienza dei dati
Ecco alcune delle migliori pratiche da tenere a mente quando si utilizza ChatGPT per la scienza dei dati:
- Non inserire dati sensibili e codice sorgente: non inserire dati sensibili in ChatGPT. Quando si lavora in team di dati nelle organizzazioni, spesso si costruiscono modelli su dati dei clienti – che devono essere mantenuti confidenziali. Puoi invece provare a costruire prototipi per set di dati pubblici simili e cercare di trasporlo sul tuo set di dati o problema. Allo stesso modo, evita di inserire il codice sorgente sensibile o qualsiasi informazione che non dovrebbe essere divulgata.
- Sii specifico con le tue richieste: senza richieste specifiche, è abbastanza difficile ottenere risposte utili da ChatGPT. Pertanto, struttura la tua richiesta in modo che sia abbastanza specifica. Le richieste dovrebbero almeno comunicare chiaramente l’obiettivo. Un passo alla volta.
- Decomponi richieste più lunghe in richieste più semplici: se hai una catena di pensiero su come compiere un particolare compito, cerca di suddividerlo in passaggi più semplici e richiedi a ChatGPT di svolgere ciascuno dei passaggi.
- Effettua il debug in modo efficace utilizzando ChatGPT: in questo esempio, tutto il codice che abbiamo ottenuto è stato eseguito senza errori; ma questo potrebbe non essere sempre il caso. Potresti incontrare errori a causa di funzionalità deprecate, riferimenti API non validi e altro ancora. Quando incontri errori, puoi inserire il messaggio di errore e la traccia degli errori pertinenti nella tua richiesta. E guarda le soluzioni offerte, quindi procedi con il debug del tuo codice.
- Tieni traccia delle richieste: se usi (o hai intenzione di usare) ChatGPT molto nel tuo flusso di lavoro quotidiano per la scienza dei dati, potrebbe essere una buona idea tenere traccia delle richieste. Questo può aiutare a raffinare le richieste nel tempo e identificare le tecniche di ingegneria delle richieste per ottenere risultati migliori da ChatGPT.
Conclusion
Quando si utilizza ChatGPT per applicazioni di data science, comprendere il problema aziendale è il primo e il più importante passo. Pertanto, ChatGPT è solo uno strumento per semplificare e automatizzare determinati compiti e non è un sostituto dell’esperienza tecnica degli sviluppatori.
Tuttavia, è comunque uno strumento prezioso per aumentare la produttività aiutando a creare e testare rapidamente diversi modelli e algoritmi. Quindi, sfruttiamo ChatGPT per affinare le nostre competenze e diventare migliori sviluppatori! Bala Priya C è una sviluppatrice e scrittrice tecnica proveniente dall’India. Le piace lavorare all’intersezione tra matematica, programmazione, data science e creazione di contenuti. Le sue aree di interesse e competenza includono DevOps, data science e elaborazione del linguaggio naturale. Ama leggere, scrivere, programmare e bere caffè! Attualmente, sta lavorando per imparare e condividere la sua conoscenza con la comunità degli sviluppatori attraverso la stesura di tutorial, guide pratiche, articoli di opinione e altro ancora.





