Incontra Gorilla L’LLM arricchito da API di UC Berkeley e Microsoft supera GPT-4, Chat-GPT e Claude.
'Incontra Gorilla L'LLM è un modello arricchito da API di UC Berkeley e Microsoft che supera GPT-4, Chat-GPT e Claude.'
Il modello è arricchito con le API di Torch Hub, TensorFlow Hub e HuggingFace.

Recentemente ho avviato una newsletter educativa incentrata sull’AI, che conta già oltre 160.000 abbonati. TheSequence è una newsletter orientata al ML senza fronzoli (cioè senza hype, senza notizie, ecc.) che richiede solo 5 minuti di lettura. L’obiettivo è tenerti aggiornato sui progetti di machine learning, sui paper di ricerca e sui concetti. Ti preghiamo di provarla iscrivendoti qui sotto:
Gli ultimi progressi nei grandi modelli di linguaggio (LLM) hanno rivoluzionato il settore, dotandoli di nuove capacità come il dialogo naturale, il ragionamento matematico e la sintesi dei programmi. Tuttavia, i LLM affrontano ancora limitazioni intrinseche. La loro capacità di memorizzare le informazioni è limitata dai pesi fissi e le loro capacità di calcolo sono limitate a un grafico statico e a un contesto ristretto. Inoltre, man mano che il mondo evolve, i LLM hanno bisogno di essere ritrattati per aggiornare le loro conoscenze e le loro capacità di ragionamento. Per superare queste limitazioni, i ricercatori hanno iniziato a dotare i LLM di strumenti. Concedendo l’accesso a basi di conoscenza estese e dinamiche e abilitando compiti di calcolo complessi, i LLM possono sfruttare tecnologie di ricerca, database e strumenti di calcolo. I principali fornitori di LLM hanno iniziato a integrare plugin che consentono ai LLM di invocare strumenti esterni attraverso API. Questa transizione da un insieme limitato di strumenti codificati a mano all’accesso a una vasta gamma di API cloud ha il potenziale per trasformare i LLM nell’interfaccia primaria per l’infrastruttura di calcolo e il web. Compiti come la prenotazione di vacanze o l’organizzazione di conferenze potrebbero essere semplici come conversare con un LLM che ha accesso alle API web di voli, noleggio auto, hotel, catering e intrattenimento.
- Bootcamp LLM Full Stack gratuito
- Allenare il tuo primo agente RL basato su Deep Q Learning Una guida passo-passo
- Costruisci modelli di ML ad alte prestazioni utilizzando PyTorch 2.0 su AWS – Parte 1.
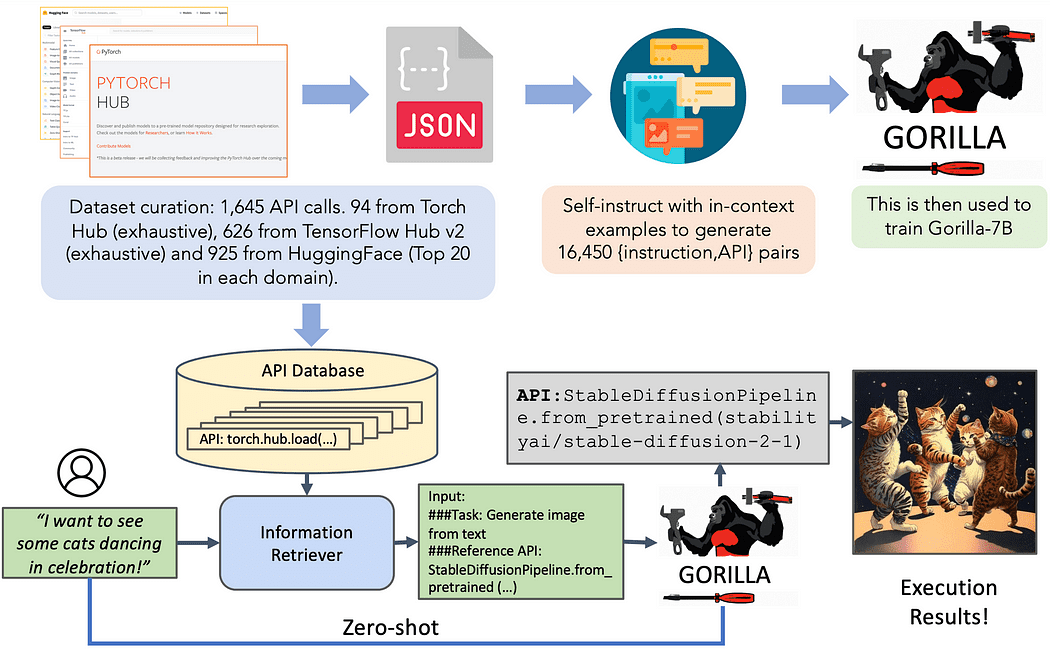
Recentemente, i ricercatori dell’UC Berkeley e di Microsoft hanno presentato Gorilla, un modello LLaMA-7B progettato appositamente per le chiamate API. Gorilla si basa sul self-instruct fine-tuning e sulle tecniche di recupero per consentire ai LLM di selezionare con precisione un ampio e in continuo sviluppo insieme di strumenti espressi attraverso le loro API e la documentazione. Gli autori costruiscono un ampio corpus di API, chiamato APIBench, raschiando API di machine learning dai principali hub di modelli come TorchHub, TensorHub e HuggingFace. Utilizzando la tecnologia self-instruct, generano coppie di istruzioni e API corrispondenti. Il processo di finetuning comporta la conversione dei dati in un formato di conversazione stile chat dell’utente-agente e l’esecuzione di un istruzioni standard di finetuning sul modello LLaMA-7B di base.

Le chiamate API spesso presentano vincoli, aggiungendo complessità alla comprensione e alla categorizzazione delle chiamate LLM. Ad esempio, una richiesta potrebbe richiedere l’invocazione di un modello di classificazione delle immagini con vincoli specifici sulle dimensioni dei parametri e sull’accuratezza. Queste sfide evidenziano la necessità per i LLM di comprendere non solo la descrizione funzionale di una chiamata API, ma anche di ragionare sui vincoli incorporati.
Il Dataset
Il set di dati incentrato sulla tecnologia a disposizione comprende tre domini distinti: Torch Hub, Tensor Hub e HuggingFace. Ogni dominio contribuisce con una ricchezza di informazioni, illuminando la natura diversa del set di dati. Torch Hub, ad esempio, offre 95 API, fornendo una solida base. In confronto, Tensor Hub va oltre con una vasta collezione di 696 API. Infine, HuggingFace guida il gruppo con un’enorme raccolta di 925 API, rendendolo il dominio più completo.
Per amplificare il valore e l’usabilità del set di dati, è stato intrapreso un ulteriore sforzo. Ogni API nel set di dati è accompagnata da un insieme di 10 istruzioni meticolosamente elaborate e appositamente cucite. Queste istruzioni servono come guide indispensabili sia per gli scopi di formazione che di valutazione. Questa iniziativa garantisce che ogni API vada oltre la mera rappresentazione, consentendo un utilizzo e un’analisi più robusti.
L’Architettura
Gorilla introduce il concetto di formazione consapevole del recupero, in cui il set di dati sintonizzato sull’istruzione include un campo aggiuntivo con la documentazione delle API recuperate per riferimento. Questo approccio mira a insegnare al LLM a analizzare e rispondere a domande basate sulla documentazione fornita. Gli autori dimostrano che questa tecnica consente al LLM di adattarsi alle modifiche nella documentazione delle API, migliora le prestazioni e riduce gli errori di allucinazione.
In fase di inferenza, gli utenti forniscono promemoria in linguaggio naturale. Gorilla può operare in due modalità: zero-shot e recupero. In modalità zero-shot, il promemoria viene direttamente alimentato al modello Gorilla LLM, che restituisce la chiamata API consigliata per svolgere il compito o raggiungere l’obiettivo. In modalità di recupero, il recupero (BM25 o GPT-Index) recupera la documentazione API più aggiornata dal database API. Questa documentazione viene concatenata con la promemoria dell’utente, insieme a un messaggio che indica il riferimento alla documentazione API. L’input concatenato viene quindi passato a Gorilla, che restituisce l’API da invocare. In questo sistema, la messa a punto del prompt non viene eseguita oltre la fase di concatenazione.
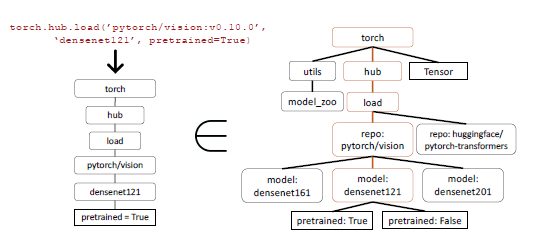
La sintesi di programmi induttivi ha ottenuto successo in vari domini sintetizzando programmi che soddisfano test specifici. Tuttavia, quando si tratta di valutare le chiamate API, affidarsi esclusivamente ai test non è sufficiente poiché diventa difficile verificare la correttezza semantica del codice. Consideriamo l’esempio della classificazione delle immagini, dove ci sono più di 40 modelli diversi disponibili per il compito. Anche se li riduciamo ad una famiglia specifica, come Densenet, ci sono quattro possibili configurazioni. Di conseguenza, esistono molteplici risposte corrette, rendendo difficile determinare se l’API utilizzata sia funzionalmente equivalente all’API di riferimento tramite i test unitari. Per valutare le prestazioni del modello, viene effettuato un confronto della loro equivalenza funzionale utilizzando il dataset raccolto. Per identificare l’API chiamata dal LLM nel dataset, viene utilizzata una strategia di matching degli alberi AST (Abstract Syntax Tree). Verificando se l’AST di una chiamata API candidata è un sotto-albero della chiamata API di riferimento, diventa possibile tracciare quale API viene utilizzata.
Identificare e definire le allucinazioni rappresenta una sfida significativa. Il processo di matching AST viene utilizzato per identificare direttamente le allucinazioni. In questo contesto, un’allucinazione si riferisce ad una chiamata API che non è un sotto-albero di alcuna API nel database, essenzialmente invocando uno strumento completamente immaginato. È importante notare che questa definizione di allucinazione differisce dall’invocazione di un’API in modo errato, che è definita come un errore.
Il matching del sotto-albero AST gioca un ruolo cruciale nell’identificare la specifica API chiamata all’interno del dataset. Poiché le chiamate API possono avere più argomenti, ognuno di questi argomenti deve essere associato. Inoltre, considerando che Python consente argomenti predefiniti, è essenziale definire quali argomenti associare per ogni API nel database.
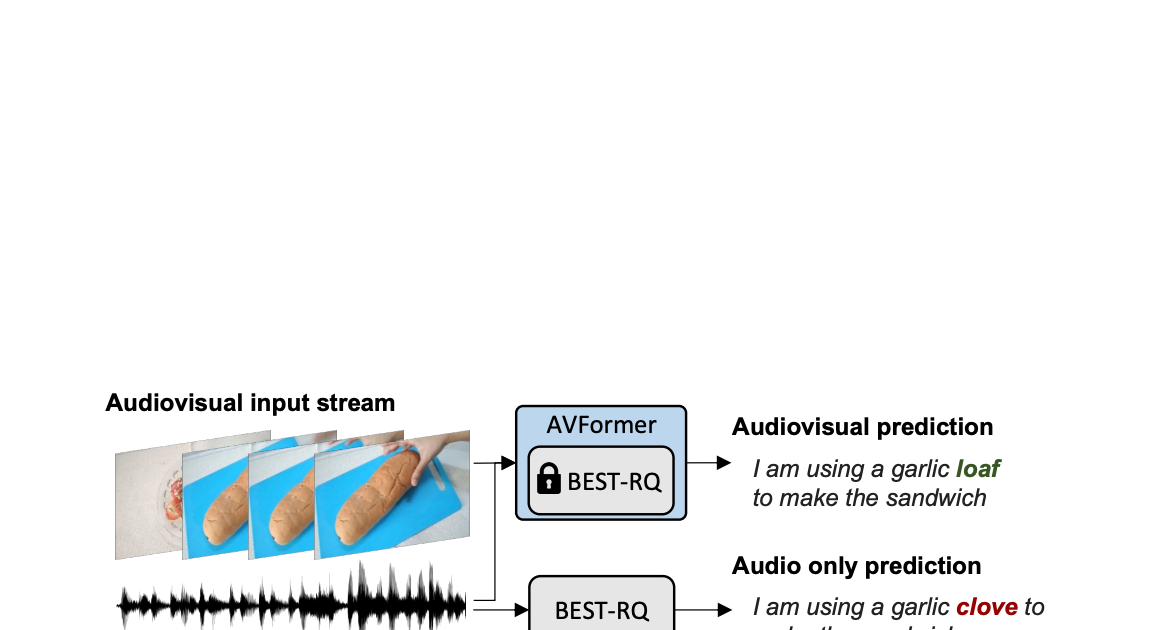
Gorilla in Azione
Insieme al paper, i ricercatori hanno rilasciato una versione open source di Gorilla. La release include un notebook con molti esempi. Inoltre, il seguente video mostra chiaramente alcune delle magie di Gorilla.
gorilla_720p.mp4
Gorilla è uno degli approcci più interessanti nello spazio degli LLM tool-augmented. Speriamo di vedere il modello distribuito in alcuni dei principali hub di ML nello spazio.
Jesus Rodriguez attualmente è CTO presso Intotheblock. È un esperto di tecnologia, investitore esecutivo e consulente di startup. Jesus ha fondato Tellago, una premiata società di sviluppo software focalizzata nell’aiutare le aziende a diventare grandi organizzazioni di software sfruttando le nuove tendenze del software enterprise.
Originale. Ripubblicato con il permesso dell’autore.