Perceiver IO un modello scalabile e completamente attenzionale che funziona su qualsiasi modalità.
Il modello Perceiver IO è scalabile e completamente attenzionale per qualsiasi modalità.
TLDR
Abbiamo aggiunto Perceiver IO a Transformers, la prima rete neurale basata su Transformer che funziona su tutti i tipi di modalità (testo, immagini, audio, video, nuvole di punti, …) e le loro combinazioni. Dai un’occhiata ai seguenti Spazi per visualizzare alcuni esempi:
- previsione del flusso ottico tra immagini
- classificazione delle immagini.
Forniamo anche diversi notebook.
Sotto, puoi trovare una spiegazione tecnica del modello.
Introduzione
Il Transformer, originariamente introdotto da Vaswani et al. nel 2017, ha causato una rivoluzione nella comunità dell’IA, migliorando inizialmente i risultati state-of-the-art (SOTA) nella traduzione automatica. Nel 2018 è stato rilasciato BERT, un modello basato su Transformer che ha schiacciato i benchmark nell’elaborazione del linguaggio naturale (NLP), più famosamente il benchmark GLUE.
- Gradio si unisce a Hugging Face!
- Esegui il deploy di GPT-J 6B per l’inferenza utilizzando Hugging Face Transformers e Amazon SageMaker
- Potenziamento di Wav2Vec2 con n-grammi in 🤗 Transformers
Poco dopo, i ricercatori di intelligenza artificiale hanno iniziato ad applicare l’idea di BERT ad altri ambiti. Per citare alcuni esempi:
- Wav2Vec2 di Facebook AI ha dimostrato che l’architettura poteva essere estesa all’audio
- il Vision Transformer (ViT) di Google AI ha dimostrato che l’architettura funziona molto bene per la visione
- più recentemente il Video Vision Transformer (ViViT), sempre di Google AI, ha applicato l’architettura ai video.
In tutti questi ambiti, i risultati state-of-the-art sono stati migliorati in modo significativo, grazie alla combinazione di questa potente architettura con l’addestramento su larga scala.
Tuttavia, c’è un’importante limitazione nell’architettura del Transformer: a causa del suo meccanismo di auto-attenzione, scala molto male sia in termini di calcolo che di memoria. In ogni livello, tutti gli input vengono utilizzati per produrre query e chiavi, per le quali viene calcolato un prodotto scalare tra coppie. Pertanto, non è possibile applicare l’auto-attenzione a dati ad alta dimensionalità senza una qualche forma di preelaborazione. Ad esempio, Wav2Vec2 risolve questo problema utilizzando un codificatore di caratteristiche per trasformare una forma d’onda grezza in una sequenza di caratteristiche basate sul tempo. Il Vision Transformer (ViT) divide un’immagine in una sequenza di patch non sovrapposte, che fungono da “token”. Il Video Vision Transformer (ViViT) estrae “tubi” spazio-temporali non sovrapposti da un video, che fungono da “token”. Per far funzionare il Transformer su una particolare modalità, di solito la si discretizza in una sequenza di token.
Il Perceiver
Il Perceiver mira a risolvere questa limitazione utilizzando il meccanismo di auto-attenzione su un insieme di variabili latenti, anziché sugli input. Gli input (che possono essere testo, immagini, audio, video) vengono utilizzati solo per eseguire l’attenzione incrociata con le latenti. Questo ha il vantaggio che la maggior parte del calcolo avviene in uno spazio latente, dove il calcolo è economico (di solito si utilizzano 256 o 512 latenti). L’architettura risultante non ha una dipendenza quadratica dalla dimensione dell’input: l’encoder del Transformer dipende solo linearmente dalla dimensione dell’input, mentre l’attenzione latente ne è indipendente. In un articolo successivo, chiamato Perceiver IO, gli autori estendono questa idea per consentire al Perceiver di gestire anche output arbitrari. L’idea è simile: si utilizzano solo gli output per eseguire l’attenzione incrociata con le latenti. Nota che userò i termini “Perceiver” e “Perceiver IO” in modo intercambiabile per riferirmi al modello Perceiver IO in tutto questo post del blog.
Nella sezione seguente, esamineremo in modo un po’ più dettagliato come funziona effettivamente Perceiver IO analizzando la sua implementazione in HuggingFace Transformers, una libreria popolare che inizialmente ha implementato modelli basati su Transformer per NLP, ma sta iniziando anche a implementarli per altri ambiti. Nelle sezioni seguenti, spiegheremo in dettaglio, in termini di forme di tensori, come il Perceiver effettivamente preelabora e postelabora le modalità di qualsiasi tipo.
Tutte le varianti di Perceiver in HuggingFace Transformers si basano sulla classe PerceiverModel. Per inizializzare un PerceiverModel, è possibile fornire 3 istanze aggiuntive al modello:
- un preprocessore
- un decodificatore
- un postprocessore.
Nota che ognuno di questi è opzionale. Un preprocessore è necessario solo nel caso in cui non si sia già incorporato gli input (come testo, immagini, audio, video) stessi. Un decodificatore è necessario solo nel caso in cui si desideri decodificare l’output dell’encoder Perceiver (ovvero gli ultimi stati nascosti delle latenti) in qualcosa di più utile, come i logit di classificazione o il flusso ottico. Un postprocessore è necessario solo nel caso in cui si desideri trasformare l’output del decodificatore in una specifica caratteristica (questo è necessario solo quando si fa auto-codifica, come vedremo in seguito). Di seguito è rappresentata una panoramica dell’architettura.

L’architettura del Perceiver.
In altre parole, gli input (che possono essere di qualsiasi modalità o una loro combinazione) vengono prima opzionalmente preelaborati utilizzando un preprocessore. Successivamente, gli input preelaborati eseguono un’operazione di attenzione incrociata con le variabili latenti dell’encoder Perceiver. In questa operazione, le variabili latenti producono le query (Q), mentre gli input preelaborati producono le chiavi e i valori (KV). Dopo questa operazione, l’encoder Perceiver utilizza un blocco (ripetibile) di strati di auto-attenzione per aggiornare gli embedding delle latenti. L’encoder produrrà infine un tensore di forma (dimensione_batch, num_latenti, d_latenti), contenente gli ultimi stati nascosti delle latenti. Successivamente, c’è un decodificatore opzionale, che può essere utilizzato per decodificare gli ultimi stati nascosti delle latenti in qualcosa di più utile, come i logits di classificazione. Questo viene fatto eseguendo un’operazione di attenzione incrociata, in cui vengono utilizzati embedding addestrabili per produrre le query (Q), mentre le latenti vengono utilizzate per produrre le chiavi e i valori (KV). Infine, c’è un postprocessore opzionale, che può essere utilizzato per post-elaborare gli output del decodificatore in specifiche caratteristiche.
Iniziamo mostrando come il Perceiver è implementato per lavorare sul testo.
Perceiver per il testo
Supponiamo che si voglia applicare il Perceiver per eseguire la classificazione del testo. Poiché i requisiti di memoria e tempo del meccanismo di auto-attenzione del Perceiver non dipendono dalle dimensioni degli input, è possibile fornire direttamente byte UTF-8 grezzi al modello. Questo è vantaggioso, poiché i modelli basati su Transformer familiari (come BERT e RoBERTa) impiegano tutti una qualche forma di tokenizzazione esplicita, come WordPiece, BPE o SentencePiece, che potrebbe essere dannosa. Per un confronto equo con BERT (che utilizza una lunghezza di sequenza di 512 token di sottostringa), gli autori hanno utilizzato sequenze di input di 2048 byte. Supponiamo di aggiungere anche una dimensione batch, quindi gli input del modello hanno forma (dimensione_batch, 2048). Gli input contengono gli ID dei byte (simili agli input_ids di BERT) per un singolo pezzo di testo. È possibile utilizzare PerceiverTokenizer per trasformare un testo in una sequenza di ID di byte, riempiti fino a una lunghezza di 2048:
from transformers import PerceiverTokenizer
tokenizer = PerceiverTokenizer.from_pretrained("deepmind/language-perceiver")
text = "ciao mondo"
inputs = tokenizer(text, padding="max_length", return_tensors="pt").input_idsIn questo caso, si fornisce PerceiverTextPreprocessor come preprocessore al modello, che si occuperà di incorporare gli input (cioè trasformare ogni ID di byte in un vettore corrispondente), oltre ad aggiungere gli embedding di posizione assoluta. Come decodificatore, si fornisce PerceiverClassificationDecoder al modello (che trasformerà gli ultimi stati nascosti delle latenti in logits di classificazione). Non è richiesto alcun postprocessore. In altre parole, un modello Perceiver per la classificazione del testo (chiamato PerceiverForSequenceClassification in HuggingFace Transformers) viene implementato nel seguente modo:
from torch import nn
from transformers import PerceiverModel
from transformers.models.perceiver.modeling_perceiver import PerceiverTextPreprocessor, PerceiverClassificationDecoder
class PerceiverForSequenceClassification(nn.Module):
def __init__(self, config):
super().__init__(config)
self.perceiver = PerceiverModel(
config,
input_preprocessor=PerceiverTextPreprocessor(config),
decoder=PerceiverClassificationDecoder(
config,
num_channels=config.d_latents,
trainable_position_encoding_kwargs=dict(num_channels=config.d_latents, index_dims=1),
use_query_residual=True,
),
)Si può già vedere qui che il decodificatore viene inizializzato con argomenti di codifica di posizione addestrabili. Perché? Beh, diamo un’occhiata nel dettaglio a come funziona Perceiver IO. All’inizializzazione, PerceiverModel definisce internamente un insieme di variabili latenti, come segue:
from torch import nn
self.latents = nn.Parameter(torch.randn(config.num_latents, config.d_latents))Nel paper Perceiver IO, si utilizzano 256 latenti e si imposta la dimensionalità delle latenti su 1280. Se si aggiunge anche una dimensione batch, il Perceiver ha latenti di forma (dimensione_batch, 256, 1280). Innanzitutto, il preprocessore (fornito all’inizializzazione) si occuperà di incorporare gli ID dei byte UTF-8 in vettori di embedding. Pertanto, PerceiverTextPreprocessor trasformerà gli input di forma (dimensione_batch, 2048) in un tensore di forma (dimensione_batch, 2048, 768) – assumendo che ogni ID di byte venga trasformato in un vettore di dimensione 768 (questo è determinato dall’attributo d_model di PerceiverConfig).
Dopo di ciò, Perceiver IO applica l’attenzione incrociata tra i latenti (che producono query) di forma (batch_size, 256, 1280) e gli input preelaborati (che producono chiavi e valori) di forma (batch_size, 2048, 768). L’output di questa operazione di attenzione incrociata iniziale è un tensore che ha la stessa forma delle query (che sono i latenti, in questo caso). In altre parole, l’output dell’operazione di attenzione incrociata è di forma (batch_size, 256, 1280).
Successivamente, un blocco (ripetibile) di livelli di auto-attenzione viene applicato per aggiornare le rappresentazioni dei latenti. Si noti che questi non dipendono dalla lunghezza degli input (cioè dai byte) forniti, in quanto questi sono stati utilizzati solo durante l’operazione di attenzione incrociata. Nel paper di Perceiver IO è stato utilizzato un singolo blocco di 26 livelli di auto-attenzione (ciascuno dei quali ha 8 testine di attenzione) per aggiornare le rappresentazioni dei latenti del modello di testo. Si noti che l’output dopo questi 26 livelli di auto-attenzione ha ancora la stessa forma di ciò che è stato inizialmente fornito in input all’encoder: (batch_size, 256, 1280). Questi sono anche chiamati “ultimi stati nascosti” dei latenti. Questo è molto simile agli “ultimi stati nascosti” dei token forniti a BERT.
Ora, si hanno gli ultimi stati nascosti finali di forma (batch_size, 256, 1280). Fantastico, ma in realtà si desidera trasformarli in logit di classificazione di forma (batch_size, num_labels). Come possiamo ottenere che il Perceiver li produca?
Questo viene gestito da PerceiverClassificationDecoder. L’idea è molto simile a quanto fatto durante la mappatura degli input nello spazio latente: si utilizza l’attenzione incrociata. Ma ora, le variabili latenti produrranno chiavi e valori, e si fornisce un tensore di qualsiasi forma desiderata – in questo caso forniremo un tensore di forma (batch_size, 1, num_labels) che fungerà da query (gli autori si riferiscono a queste come “query del decoder”, perché vengono utilizzate nel decoder). Questo tensore verrà inizializzato casualmente all’inizio dell’addestramento e addestrato end-to-end. Come si può vedere, si fornisce semplicemente una dimensione di lunghezza della sequenza fittizia pari a 1. Si noti che l’output di un livello di attenzione QKV ha sempre la stessa forma della forma delle query – quindi il decoder produrrà un tensore di forma (batch_size, 1, num_labels). Il decoder quindi semplicemente riduce questo tensore per ottenere forma (batch_size, num_labels) e boom, si hanno i logit di classificazione 1.
Fantastico, vero? Gli autori di Perceiver mostrano anche che è semplice eseguire il pre-training del Perceiver per il masked language modeling, simile a BERT. Questo modello è anche disponibile in HuggingFace Transformers e chiamato PerceiverForMaskedLM. L’unica differenza con PerceiverForSequenceClassification è che non utilizza PerceiverClassificationDecoder come decoder, ma piuttosto PerceiverBasicDecoder, per decodificare i latenti in un tensore di forma (batch_size, 2048, 1280). Dopo di ciò, viene aggiunto un modulo di language modeling, che lo trasforma in un tensore di forma (batch_size, 2048, vocab_size). La dimensione del vocabolario del Perceiver è solo 262, ovvero i 256 ID di byte UTF-8, oltre a 6 token speciali. Pre-addestrando il Perceiver su English Wikipedia e C4, gli autori mostrano che è possibile ottenere un punteggio complessivo di 81.8 su GLUE dopo il fine-tuning.
Perceiver per immagini
Ora che abbiamo visto come applicare il Perceiver per eseguire la classificazione del testo, è semplice applicare il Perceiver per eseguire la classificazione delle immagini. L’unica differenza è che forniremo un diverso preprocessor al modello, che incorporerà gli inputs delle immagini. Gli autori di Perceiver hanno effettivamente provato 3 diversi modi di preelaborazione:
- appiattendo i valori dei pixel, applicando un livello convoluzionale con dimensione del kernel pari a 1 e aggiungendo embedding di posizione assoluta 1D appresi.
- appiattendo i valori dei pixel e aggiungendo embedding di posizione 2D di Fourier fissati.
- applicando un livello convoluzionale 2D + maxpool e aggiungendo embedding di posizione 2D di Fourier fissati.
Ognuno di questi è implementato nella libreria Transformers e chiamato rispettivamente PerceiverForImageClassificationLearned, PerceiverForImageClassificationFourier e PerceiverForImageClassificationConvProcessing. Differiscono solo nella configurazione di PerceiverImagePreprocessor. Diamo uno sguardo più da vicino a PerceiverForImageClassificationLearned. Esso inizializza un PerceiverModel nel seguente modo:
dalla torcia importa nn
dai trasformatori importa PerceiverModel
dai trasformatori.models.perceiver.modeling_perceiver import PerceiverImagePreprocessor, PerceiverClassificationDecoder
class PerceiverPerClassificazioneImmagineAppresa(nn.Module):
def __init__(self, config):
super().__init__(config)
self.perceiver = PerceiverModel(
config,
input_preprocessor=PerceiverImagePreprocessor(
config,
prep_type="conv1x1",
spatial_downsample=1,
out_channels=256,
position_encoding_type="trainable",
concat_or_add_pos="concat",
project_pos_dim=256,
trainable_position_encoding_kwargs=dict(num_channels=256, index_dims=config.image_size ** 2),
),
decoder=PerceiverClassificationDecoder(
config,
num_channels=config.d_latents,
trainable_position_encoding_kwargs=dict(num_channels=config.d_latents, index_dims=1),
use_query_residual=True,
),
)Si può vedere che PerceiverImagePreprocessor viene inizializzato con prep_type = "conv1x1" e che vengono aggiunti argomenti per le codifiche di posizione addestrabili. Quindi come funziona questo preprocessore nel dettaglio? Supponiamo che si fornisca un batch di immagini al modello. Diciamo che si applica un ritaglio al centro con una risoluzione di 224 e una normalizzazione dei canali di colore prima, in modo che gli inputs abbiano una forma (batch_size, num_channels, height, width) = (batch_size, 3, 224, 224). Per questo si può utilizzare PerceiverFeatureExtractor, come segue:
dai trasformatori importa PerceiverFeatureExtractor
importa richieste
dalla PIL import Image
feature_extractor = PerceiverFeatureExtractor.from_pretrained("deepmind/vision-perceiver")
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
inputs = feature_extractor(image, return_tensors="pt").pixel_valuesPerceiverImagePreprocessor (con le impostazioni definite sopra) applicherà prima uno strato convolutivo con dimensione del kernel (1, 1) per trasformare gli inputs in un tensore di forma (batch_size, 256, 224, 224) – aumentando quindi la dimensione del canale. Successivamente posizionerà l’ultima dimensione del canale – quindi ora si ha un tensore di forma (batch_size, 224, 224, 256). Successivamente appiattirà le dimensioni spaziali (altezza + larghezza) in modo da ottenere un tensore di forma (batch_size, 50176, 256). Successivamente, lo concatenerà con delle codifiche di posizione 1D addestrabili. Poiché la dimensionalità delle codifiche di posizione è definita come 256 (vedere l’argomento num_channels sopra), si otterrà un tensore di forma (batch_size, 50176, 512). Questo tensore sarà utilizzato per l’operazione di attenzione incrociata con i latenti.
Gli autori utilizzano 512 latenti per tutti i modelli di immagini, e impostano la dimensionalità dei latenti a 1024. Quindi, i latenti sono un tensore di forma (batch_size, 512, 1024) – assumendo che si aggiunga una dimensione di batch. Lo strato di attenzione incrociata prende le query di forma (batch_size, 512, 1024) e le chiavi + valori di forma (batch_size, 50176, 512) come input, e produce un tensore che ha la stessa forma delle query, quindi restituisce un nuovo tensore di forma (batch_size, 512, 1024). Successivamente, viene applicato un blocco di 6 strati di auto-attenzione ripetutamente (8 volte), per produrre stati nascosti finali dei latenti di forma (batch_size, 512, 1024). Per trasformarli in logit di classificazione, viene utilizzato PerceiverClassificationDecoder, che funziona in modo simile a quello per la classificazione del testo: utilizza i latenti come chiavi + valori, e utilizza codifiche di posizione addestrabili di forma (batch_size, 1, num_labels) come query. L’output dell’operazione di attenzione incrociata è un tensore di forma (batch_size, 1, num_labels), che viene ridotto di dimensione per ottenere logit di classificazione di forma (batch_size, num_labels).
Gli autori del Perceiver mostrano che il modello è in grado di ottenere risultati eccellenti rispetto ai modelli progettati principalmente per la classificazione delle immagini (come ResNet o ViT ). Dopo un addestramento su larga scala su JFT , il modello che utilizza una elaborazione con convoluzione+maxpooling ( PerceiverPerClassificazioneImmagineElaborazioneConvoluzione ) raggiunge una precisione top-1 dell’84,5% su ImageNet. Notevolmente, PerceiverPerClassificazioneImmagineAppresa , il modello che utilizza solo una codifica di posizione completamente appresa 1D, raggiunge una precisione top-1 del 72,7% nonostante non abbia informazioni privilegiate sulla struttura 2D delle immagini.
Perceiver per flusso ottico
Gli autori dimostrano che è facile rendere il Perceiver funzionare anche per il flusso ottico, che è un problema di vecchia data nella visione artificiale, con molte applicazioni più ampie. Per una introduzione al flusso ottico, si rimanda a questo articolo del blog. Dati due immagini della stessa scena (ad esempio, due fotogrammi consecutivi di un video), il compito è stimare lo spostamento bidimensionale per ogni pixel nella prima immagine. Gli algoritmi esistenti sono piuttosto complessi e basati su regole predefinite, tuttavia con il Perceiver, questo diventa relativamente semplice. Il modello è implementato nella libreria Transformers, ed è disponibile come PerceiverForOpticalFlow. Ecco come è implementato:
from torch import nn
from transformers import PerceiverModel
from transformers.models.perceiver.modeling_perceiver import PerceiverImagePreprocessor, PerceiverOpticalFlowDecoder
class PerceiverForOpticalFlow(nn.Module):
def __init__(self, config):
super().__init__(config)
fourier_position_encoding_kwargs_preprocessor = dict(
num_bands=64,
max_resolution=config.train_size,
sine_only=False,
concat_pos=True,
)
fourier_position_encoding_kwargs_decoder = dict(
concat_pos=True, max_resolution=config.train_size, num_bands=64, sine_only=False
)
image_preprocessor = PerceiverImagePreprocessor(
config,
prep_type="patches",
spatial_downsample=1,
conv_after_patching=True,
conv_after_patching_in_channels=54,
temporal_downsample=2,
position_encoding_type="fourier",
# position_encoding_kwargs
fourier_position_encoding_kwargs=fourier_position_encoding_kwargs_preprocessor,
)
self.perceiver = PerceiverModel(
config,
input_preprocessor=image_preprocessor,
decoder=PerceiverOpticalFlowDecoder(
config,
num_channels=image_preprocessor.num_channels,
output_image_shape=config.train_size,
rescale_factor=100.0,
use_query_residual=False,
output_num_channels=2,
position_encoding_type="fourier",
fourier_position_encoding_kwargs=fourier_position_encoding_kwargs_decoder,
),
)Come si può vedere, PerceiverImagePreprocessor viene utilizzato come preprocessore (cioè per preparare le 2 immagini per l’operazione di cross-attenzione con i latenti) e PerceiverOpticalFlowDecoder viene utilizzato come decodificatore (cioè per decodificare gli stati nascosti finali dei latenti in un flusso previsto effettivo). Per ogni dei 2 fotogrammi, gli autori estraggono una patch 3 x 3 intorno a ciascun pixel, ottenendo così 3 x 3 x 3 = 27 valori per ogni pixel (poiché ogni pixel ha anche 3 canali di colore). Gli autori utilizzano una risoluzione di allenamento di (368, 496). Se si impilano 2 fotogrammi di dimensioni (368, 496) di ogni esempio di allenamento uno sopra l’altro, gli input per il modello avranno forma (dimensione_batch, 2, 27, 368, 496).
Il preprocessore (con le impostazioni definite sopra) concatenerà prima i fotogrammi lungo la dimensione dei canali, ottenendo un tensore di forma (dimensione_batch, 368, 496, 54) – assumendo che si sposti anche la dimensione dei canali per essere l’ultima. Gli autori spiegano nel loro articolo (pagina 8) perché la concatenazione lungo la dimensione dei canali ha senso. Successivamente, le dimensioni spaziali vengono appiattite, ottenendo un tensore di forma (dimensione_batch, 368*496, 54) = (dimensione_batch, 182528, 54). Quindi, gli embeddings di posizione (ciascuno dei quali ha dimensionalità 258) vengono concatenati, ottenendo un input preprocessato finale di forma (dimensione_batch, 182528, 322). Questi verranno utilizzati per eseguire l’operazione di cross-attenzione con i latenti.
Gli autori utilizzano 2048 latenti per il modello di flusso ottico (sì, 2048!), con una dimensionalità di 512 per ogni latente. Quindi, i latenti hanno forma (dimensione_batch, 2048, 512). Dopo l’operazione di cross-attenzione, si ottiene di nuovo un tensore della stessa forma (poiché i latenti fungono da query). Successivamente, viene applicato un singolo blocco di 24 livelli di auto-attenzione (ciascuno dei quali ha 16 testate di attenzione) per aggiornare gli embeddings dei latenti.
Per decodificare gli stati nascosti finali dei latenti in un flusso previsto effettivo, PerceiverOpticalFlowDecoder utilizza semplicemente gli input preprocessati di forma (dimensione_batch, 182528, 322) come query per l’operazione di cross-attenzione. Successivamente, queste vengono proiettate su un tensore di forma (dimensione_batch, 182528, 2). Infine, questo viene ridimensionato e modellato di nuovo alle dimensioni dell’immagine originale per ottenere un flusso previsto di forma (dimensione_batch, 368, 496, 2). Gli autori affermano di ottenere risultati all’avanguardia su importanti benchmark, inclusi Sintel e KITTI, quando si allenano su AutoFlow, un ampio dataset sintetico di 400.000 coppie di immagini annotate.
Il video qui sotto mostra il flusso previsto su 2 esempi.

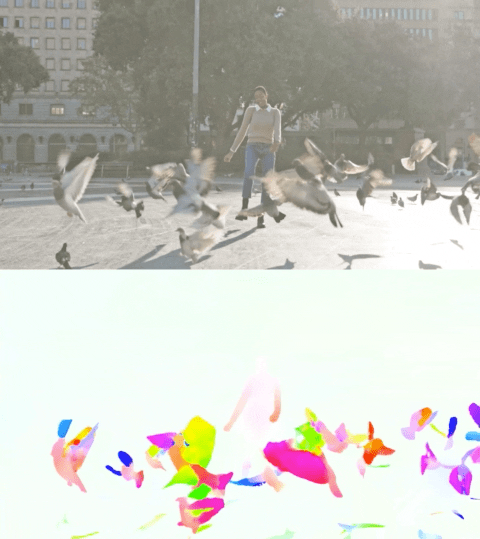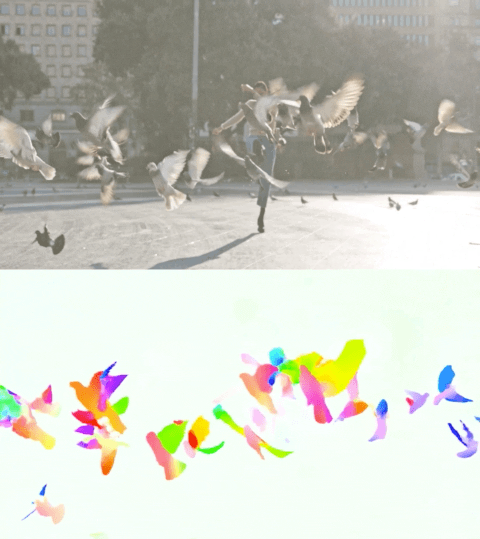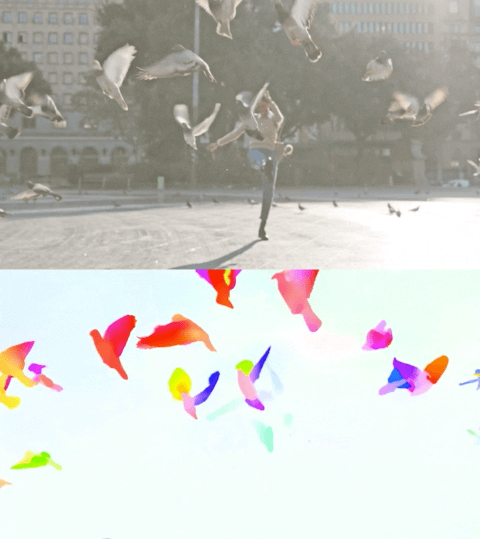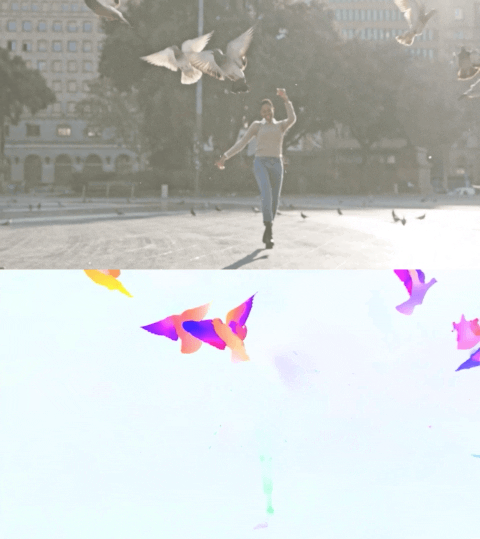

Stima del flusso ottico tramite Perceiver IO. Il colore di ogni pixel mostra la direzione e la velocità del movimento stimato dal modello, come indicato nella legenda a destra.
Perceiver per autoencoders multimodali
Gli autori utilizzano anche il Perceiver per l’autoencoding multimodale. L’obiettivo dell’autoencoding multimodale è quello di apprendere un modello che possa ricostruire accuratamente input multimodali in presenza di un collo di bottiglia indotto da un’architettura. Gli autori addestrano il modello sul dataset Kinetics-700, in cui ogni esempio è costituito da una sequenza di immagini (ovvero fotogrammi), audio e una classe (una delle 700 possibili). Questo modello è anche implementato in HuggingFace Transformers ed è disponibile come PerceiverForMultimodalAutoencoding. Per brevità, ometterò il codice di definizione di questo modello, ma è importante notare che utilizza PerceiverMultimodalPreprocessor per preparare gli input per il modello. Questo preprocessor utilizza prima il preprocessor rispettivo per ogni modalità (immagine, audio, etichetta) separatamente. Supponiamo di avere un video di 16 fotogrammi di risoluzione 224×224 e 30.720 campioni audio, quindi le modalità vengono preprocessate come segue:
- Le immagini – in realtà una sequenza di fotogrammi – di forma (batch_size, 16, 3, 224, 224) vengono convertite in un tensore di forma (batch_size, 50176, 243) utilizzando
PerceiverImagePreprocessor. Si tratta di una trasformazione “spazio in profondità”, dopo la quale vengono concatenate le incorporazioni fisse dei posizionamenti di Fourier 2D. - L’audio ha forma (batch_size, 30720, 1) e viene convertito in un tensore di forma (batch_size, 1920, 401) utilizzando
PerceiverAudioPreprocessor(che concatena incorporazioni fisse di posizionamento di Fourier all’audio grezzo). - L’etichetta di classe di forma (batch_size, 700) viene convertita in un tensore di forma (batch_size, 1, 700) utilizzando
PerceiverOneHotPreprocessor. In altre parole, questo preprocessor aggiunge semplicemente una dimensione temporale (indice) fittizia. Si noti che si inizializza l’etichetta di classe con un tensore di zeri durante la valutazione, in modo che il modello agisca come un classificatore video.
Successivamente, PerceiverMultimodalPreprocessor aggiungerà incorporazioni addestrabili specifiche della modalità alle modalità preprocessate per rendere possibile la concatenazione lungo la dimensione temporale. In questo caso, la modalità con la dimensione del canale più alta è l’etichetta di classe (ha 700 canali). Gli autori impongono una dimensione di padding minima di 4, quindi ogni modalità verrà riempita fino ad avere 704 canali. Possono quindi essere concatenate, quindi l’input preprocessato finale è un tensore di forma (batch_size, 50176 + 1920 + 1, 704) = (batch_size, 52097, 704).
Gli autori utilizzano 784 latenti, con una dimensionalità di 512 per ogni latente. Quindi, i latenti hanno forma (batch_size, 784, 512). Dopo l’attenzione incrociata, si ottiene nuovamente un tensore della stessa forma (poiché i latenti agiscono come query). Successivamente, viene applicato un singolo blocco di 8 livelli di autoattenzione (ciascuno dei quali ha 8 testate di attenzione) per aggiornare le incorporazioni dei latenti.
Successivamente, c’è PerceiverMultimodalDecoder, che creerà prima le query di output per ogni modalità separatamente. Tuttavia, poiché non è possibile decodificare un intero video in un singolo passaggio in avanti, gli autori invece eseguono l’auto-encoding a tratti. Ogni tratto sottocampionerà determinate dimensioni di indice per ogni modalità. Supponiamo che processiamo il video in 128 tratti, quindi le query del decoder verranno prodotte come segue:
- Per la modalità immagine, la dimensione totale della query del decoder è 16x3x224x224 = 802.816. Tuttavia, durante la codifica automatica del primo chunk, si sottocampiona solo i primi 802.816/128 = 6.272 valori. La forma della query di output dell’immagine è (dimensione_batch, 6.272, 195) – il 195 deriva dall’utilizzo di posizionamenti fissi di Fourier.
- Per la modalità audio, l’input totale ha 30.720 valori. Tuttavia, si sottocampiona solo i primi 30.720/128/16 = 15 valori. Pertanto, la forma della query audio è (dimensione_batch, 15, 385). Qui, il 385 deriva dall’utilizzo di posizionamenti fissi di Fourier.
- Per la modalità delle etichette di classe, non c’è bisogno di sottocampionare. Pertanto, l’indice sottocampionato viene impostato su 1. La forma della query di output dell’etichetta è (dimensione_batch, 1, 1024). Si utilizzano posizionamenti incorporabili addestrabili (di dimensione 1024) per le query.
Allo stesso modo del preelaboratore, PerceiverMultimodalDecoder aggiunge padding alle diverse modalità per avere lo stesso numero di canali, in modo da rendere possibile la concatenazione delle query specifiche delle modalità lungo la dimensione temporale. Qui, l’etichetta di classe ha di nuovo il numero più alto di canali (1024), e gli autori impongono una dimensione minima del padding di 2, quindi ogni modalità sarà riempita con 1026 canali. Dopo la concatenazione, la query del decoder finale ha forma (dimensione_batch, 6.272 + 15 + 1, 1026) = (dimensione_batch, 6.288, 1026). Questo tensore produce query nell’operazione di attenzione incrociata, mentre i latenti agiscono come chiavi e valori. Pertanto, l’output dell’operazione di attenzione incrociata è un tensore di forma (dimensione_batch, 6.288, 1026). Successivamente, PerceiverMultimodalDecoder utilizza un livello lineare per ridurre i canali di output e ottenere un tensore di forma (dimensione_batch, 6.288, 512).
Infine, c’è PerceiverMultimodalPostprocessor. Questa classe post-elabora l’output del decoder per produrre una ricostruzione effettiva di ogni modalità. Prima divide la dimensione temporale dell’output del decoder in base alle diverse modalità: (dimensione_batch, 6.272, 512) per l’immagine, (dimensione_batch, 15, 512) per l’audio e (dimensione_batch, 1, 512) per l’etichetta di classe. Successivamente, vengono applicati i rispettivi postelaboratori per ogni modalità:
- Il postelaboratore dell’immagine (chiamato
PerceiverProjectionPostprocessorin Transformers) semplicemente trasforma il tensore (dimensione_batch, 6.272, 512) in un tensore di forma (dimensione_batch, 6.272, 3) – cioè proietta l’ultima dimensione ai valori RGB. PerceiverAudioPostprocessortrasforma il tensore (dimensione_batch, 15, 512) in un tensore di forma (dimensione_batch, 240).PerceiverClassificationPostprocessorsemplicemente prende il primo (ed unico) indice, ottenendo un tensore di forma (dimensione_batch, 700).
Ora si ottengono i tensori contenenti la ricostruzione delle modalità immagine, audio ed etichetta di classe rispettivamente. Poiché si codifica automaticamente un intero video a tratti, è necessario concatenare la ricostruzione di ogni tratto per ottenere una ricostruzione finale di un intero video. La figura qui sotto mostra un esempio:



In alto: video originale (a sinistra), ricostruzione dei primi 16 frame (a destra). Video tratto dal dataset UCF101. In basso: audio ricostruito (tratto dal paper).

Le prime 5 etichette previste per il video sopra. Mascherando l’etichetta di classe, il Perceiver diventa un classificatore video.
Con questo approccio, il modello apprende una distribuzione congiunta attraverso 3 modalità. Gli autori notano che poiché le variabili latenti sono condivise tra le modalità e non assegnate esplicitamente tra di esse, la qualità delle ricostruzioni per ogni modalità è sensibile al peso del suo termine di perdita e ad altri iperparametri di addestramento. Mettendo maggior enfasi sull’accuratezza della classificazione, sono in grado di raggiungere un’accuratezza del 45% al top-1 mantenendo un PSNR (rapporto segnale-rumore massimo) di 20,7 per i video.
Altre applicazioni del Perceiver
Note che non ci sono limiti alle applicazioni del Perceiver! Nel paper originale del Perceiver, gli autori hanno dimostrato che l’architettura può essere utilizzata per elaborare nuvole di punti 3D – una preoccupazione comune per le auto a guida autonoma equipaggiate con sensori Lidar. Hanno addestrato il modello su ModelNet40, un dataset di nuvole di punti derivate da mesh triangolari 3D che coprono 40 categorie di oggetti. Il modello ha dimostrato di raggiungere un’accuratezza top-1 del 85,7% sul set di test, competendo con PointNet++, un modello altamente specializzato che utilizza ulteriori caratteristiche geometriche e svolge maggiori avanzamenti.
Gli autori hanno anche utilizzato il Perceiver per sostituire il Transformer originale in AlphaStar, il sistema di apprendimento per rinforzo all’avanguardia per il complesso gioco di StarCraft II. Senza regolare alcun parametro aggiuntivo, gli autori hanno osservato che l’agente risultante ha raggiunto lo stesso livello di prestazioni dell’agente AlphaStar originale, raggiungendo un tasso di vittoria dell’87% rispetto all’Elite bot dopo il clonaggio comportamentale sui dati umani.
È importante notare che i modelli attualmente implementati (come PerceiverForImageClassificationLearned, PerceiverForOpticalFlow) sono solo esempi di ciò che è possibile fare con il Perceiver. Ognuno di questi è un’istanza diversa di PerceiverModel, solo con un preprocessore e/o decodificatore diverso (e facoltativamente, un postprocessore come nel caso dell’autoencoding multimodale). Le persone possono inventare nuovi preprocessori, decodificatori e postprocessori per far sì che il modello risolva problemi diversi. Ad esempio, si potrebbe estendere il Perceiver per eseguire il riconoscimento delle entità denominate (NER) o la risposta alle domande simile a BERT, la classificazione audio simile a Wav2Vec2 o il rilevamento degli oggetti simile a DETR.
Conclusione
In questo post del blog, abbiamo esaminato l’architettura di Perceiver IO, un’estensione del Perceiver di Google Deepmind, e mostrato la sua capacità di gestire tutte le tipologie di modalità. Il grande vantaggio del Perceiver è che i requisiti di calcolo e memoria del meccanismo di self-attention non dipendono dalle dimensioni degli input e degli output, in quanto la maggior parte del calcolo avviene in uno spazio latente (un insieme di vettori non troppo grande). Nonostante la sua architettura agnostica al compito, il modello è in grado di ottenere ottimi risultati su modalità come il linguaggio, la visione, i dati multimodali e le nuvole di punti. In futuro, potrebbe essere interessante addestrare un singolo encoder Perceiver (condiviso) su diverse modalità contemporaneamente e utilizzare preprocessori e postprocessori specifici per ciascuna modalità. Come afferma Karpathy, potrebbe benissimo essere che questa architettura possa unificare tutte le modalità in uno spazio condiviso, con una libreria di encoder/decodificatori.
Parlando di una libreria, il modello è disponibile in HuggingFace Transformers a partire da oggi. Sarà emozionante vedere cosa costruiranno le persone con esso, poiché le sue applicazioni sembrano infinite!
Appendice
L’implementazione in HuggingFace Transformers si basa sull’implementazione originale JAX/Haiku che può essere trovata qui.
La documentazione del modello Perceiver IO in HuggingFace Transformers è disponibile qui.
È possibile trovare i notebook tutorial relativi al Perceiver su diverse modalità qui.
Note a piè di pagina
1 Nota che nel paper ufficiale, gli autori hanno utilizzato un MLP a due strati per generare i logit di output, che è stato omesso qui per brevità. ↩︎