I ricercatori del Tencent AI Lab presentano IP-Adapter un adattatore di testo compatibile con le immagini per i modelli di diffusione del testo in immagine.
I ricercatori del Tencent AI Lab presentano IP-Adapter, un adattatore di testo compatibile con le immagini per modelli di diffusione del testo in immagine.


“Mela,” e subito l’immagine di una mela è apparsa nella tua mente. Ed è affascinante come funzionano i nostri cervelli, l’IA generativa ha portato lo stesso livello di creatività e potenza, consentendo alle macchine di produrre quello che chiamiamo contenuti originali. Di recente sono emersi modelli di generazione testo-immagine impressionanti che creano immagini altamente realistiche. Puoi inserire “mela” nel modello e ottenere ogni tipo di immagini di mele.
Tuttavia, rendere questi modelli generare esattamente ciò che vogliamo solo con prompt di testo può essere estremamente sfidante. Di solito richiede una cura nella creazione dei prompt giusti. Un modo alternativo per farlo è utilizzare prompt di immagini. Mentre l’attuale set di tecniche per il raffinamento diretto dei modelli da quelli preesistenti è efficace, richiedono una notevole potenza di calcolo e mancano di compatibilità con diversi modelli di base, prompt di testo e aggiustamenti strutturali.
Progressi recenti nella generazione di immagini controllabili mettono in evidenza preoccupazioni con i moduli di attenzione incrociata dei modelli di diffusione testo-immagine. Questi moduli utilizzano pesi personalizzati per proiettare i dati chiave e di valore nel livello di attenzione incrociata del modello di diffusione pre-addestrato, ottimizzato principalmente per le caratteristiche del testo. Di conseguenza, la fusione delle caratteristiche dell’immagine con quelle del testo in questo livello allinea principalmente le caratteristiche dell’immagine con quelle del testo. Tuttavia, questo può trascurare i dettagli specifici dell’immagine, portando a un controllo più ampio durante la generazione (ad esempio, gestire lo stile dell’immagine) quando si utilizza un’immagine di riferimento.
- Pricing dinamico con apprendimento per rinforzo da zero Q-Learning
- Meta AI presenta SeamlessM4T un modello fondamentale multilingue e multitasking che traduce e trascrive senza soluzione di continuità tra il linguaggio parlato e il testo.
- Incontra TADA un potente approccio di intelligenza artificiale per convertire descrizioni verbali in avatar 3D espressivi

Nell’immagine sopra, possiamo notare che gli esempi a destra mostrano i risultati di variazioni dell’immagine, generazione multimodale e inpainting con prompt di immagine, mentre gli esempi a sinistra mostrano i risultati della generazione controllabile con prompt di immagine e condizioni strutturali aggiuntive.
I ricercatori hanno introdotto un efficace adattatore di prompt di immagine chiamato IP-Adapter per affrontare le sfide poste dai metodi attuali. IP-Adapter utilizza un approccio separato per gestire le caratteristiche del testo e dell’immagine. Nel UNet del modello di diffusione, i ricercatori hanno aggiunto un ulteriore livello di attenzione incrociata specificamente per le caratteristiche dell’immagine. Durante l’addestramento, le impostazioni del nuovo livello di attenzione incrociata vengono regolate, lasciando invariato il modello UNet originale. Questo adattatore è efficiente ma potente: anche con solo 22 milioni di parametri, un adattatore IP può generare immagini altrettanto buone di un modello di prompt di immagine completamente raffinato derivato dal modello di diffusione testo-immagine.
I risultati hanno dimostrato che l’IP-Adapter è riutilizzabile e flessibile. L’IP-Adapter addestrato sul modello di diffusione di base può essere generalizzato ad altri modelli personalizzati raffinati dallo stesso modello di diffusione di base. Inoltre, l’IP-Adapter è compatibile con altri adattatori controllabili come ControlNet, consentendo una facile combinazione di prompt di immagini con controlli strutturali. Grazie alla strategia di attenzione incrociata separata, il prompt di immagine può funzionare insieme al prompt di testo, creando immagini multimodali.
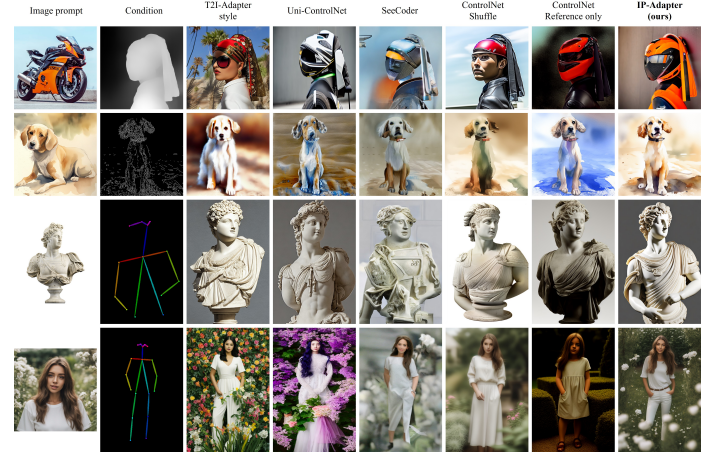
Nell’immagine sopra viene mostrato il confronto dell’IP-Adapter con altri metodi in diverse condizioni strutturali. Nonostante l’efficacia dell’IP-Adapter, può generare solo immagini che assomigliano alle immagini di riferimento nel contenuto e nello stile. In altre parole, non può sintetizzare immagini che siano altamente coerenti con il soggetto di un’immagine data come alcuni metodi esistenti, ad esempio Textual Inversion e DreamBooth. In futuro, i ricercatori mirano a sviluppare adattatori di prompt di immagine più potenti per migliorare la coerenza.





