Come gestire MLOps come un professionista Una guida al Machine Learning senza lacrime.
How to manage MLOps like a professional A guide to Machine Learning without tears.
Se hai mai inviato via email un file .pickle agli ingegneri per il deployment, questo è per TE!

Il mercato di MLOps è stato stimato a 23,2 miliardi di dollari nel 2019 e si prevede che raggiungerà i 126 miliardi di dollari entro il 2025 grazie all’adozione rapida.
Introduzione
Molti progetti di data science non vedono mai la luce del giorno. MLOps è un processo che si estende dalla fase dei dati alla fase di distribuzione e garantisce il successo dei modelli di machine learning. In questo post, imparerai le fasi chiave di MLOps (dalla prospettiva di uno scienziato dei dati) insieme ad alcuni problemi comuni.
- Incontra Gorilla L’LLM arricchito da API di UC Berkeley e Microsoft supera GPT-4, Chat-GPT e Claude.
- Bootcamp LLM Full Stack gratuito
- Allenare il tuo primo agente RL basato su Deep Q Learning Una guida passo-passo
Motivazione per MLOps
MLOps è una pratica che si concentra sull’operazionalizzazione dei modelli di data science. Di solito, nella maggior parte delle imprese, gli scienziati dei dati sono responsabili della creazione dei dataset di modellizzazione, della pre-elaborazione dei dati, dell’ingegneria delle funzionalità e infine della costruzione del modello. Quindi il modello viene “gettato” oltre il muro al team di ingegneria per essere distribuito nell’API/Endpoint. La scienza e l’ingegneria spesso accadono in silos, il che porta a ritardi nella distribuzione o a distribuzioni non corrette nel peggiore dei casi.
MLOps affronta la sfida di distribuire modelli ML su scala enterprise in modo preciso e veloce.
L’equivalente di data science del detto “più facile a dirsi che a farsi” dovrebbe probabilmente essere “più facile a costruirsi che a distribuirsi”.
MLOps può essere la soluzione ai problemi che le imprese incontrano nella messa in produzione dei modelli di machine learning. Per quelli di noi scienziati dei dati, la scoperta che circa il 90% dei modelli ML non arriva in produzione, non dovrebbe sorprenderci. MLOps porta la disciplina e il processo ai team di data science e ingegneria per garantire che collaborino strettamente e continuamente. Questa collaborazione è cruciale per garantire una distribuzione di modello di successo.
MLOps in breve
Per quelli familiarizzati con DevOps, MLOps è per le applicazioni di machine learning ciò che DevOps è per le applicazioni software.
MLOps ha molteplici sfumature a seconda di chi si chieda. Tuttavia, ci sono cinque fasi chiave che sono fondamentali per una strategia MLOps di successo. Come nota a margine, un elemento cruciale che deve far parte di ciascuna di queste fasi è la comunicazione con gli stakeholder.
Definizione del problema
Comprendere il problema aziendale a fondo. Questo è uno dei passaggi chiave per una distribuzione e un utilizzo di modello di successo. Coinvolgere tutti gli stakeholder in questa fase per ottenere il loro supporto per il progetto. Potrebbe essere l’ingegneria, il prodotto, la conformità, ecc.
Definizione della soluzione
Solo e solo dopo che la dichiarazione del problema è stata risolta, procedere a pensare al “Come”. È richiesto l’utilizzo del machine learning per affrontare questo problema aziendale? Inizialmente, potrebbe sembrare strano che come scienziato dei dati, suggerisca di evitare il machine learning. Questo perché con “grandi poteri arrivano grandi responsabilità”. La responsabilità in questo caso sarebbe quella di assicurarsi che il modello di machine learning sia costruito, distribuito e monitorato attentamente per garantire che soddisfi e continui a soddisfare il requisito aziendale. I tempi e le risorse dovrebbero essere discussi anche in questa fase con gli stakeholder.
Preparazione dei dati
Una volta deciso di procedere con il machine learning, inizia a pensare ai “Dati”. Questa fase include passaggi come la raccolta di dati, la pulizia dei dati, la trasformazione dei dati, l’ingegneria delle funzionalità e l’etichettatura (per l’apprendimento supervisionato). Qui l’adagio che deve essere ricordato è “spazzatura dentro spazzatura fuori”. Questo passaggio è di solito il più doloroso nel processo ed è fondamentale per garantire il successo del modello. Assicurati di validare i dati e le funzionalità più volte per assicurarti che siano allineati con il problema aziendale. Documenta tutte le tue molte assunzioni che fai durante la creazione di un dataset. Ad esempio: gli outlier per una funzionalità sono effettivamente outlier?
Costruzione e analisi del modello
In questa fase, costruisci e valuta più modelli e seleziona l’architettura del modello che risolve meglio il problema in questione. La metrica scelta per l’ottimizzazione dovrebbe riflettere il requisito aziendale. Oggi, ci sono numerose librerie di machine learning che aiutano ad accelerare questo passaggio. Ricorda di registrare e tenere traccia dei tuoi esperimenti per garantire la riproducibilità della tua pipeline di machine learning.
Distribuzione e monitoraggio del modello
Una volta che abbiamo costruito l’oggetto del modello dalla precedente fase, dobbiamo pensare a come renderlo “utilizzabile” dai nostri utenti finali. Il tempo di risposta deve essere minimizzato mentre si massimizza la throughput. Alcune opzioni popolari per servire il modello sono – endpoint REST API, come un contenitore docker nel cloud o su un dispositivo edge. Non possiamo ancora festeggiare una volta che abbiamo distribuito l’oggetto del modello, poiché sono molto dinamici di natura. Ad esempio, i dati potrebbero derivare in produzione causando il decadimento del modello o potrebbero esserci attacchi avversari sul modello. Abbiamo bisogno di avere un’infrastruttura di monitoraggio robusta in posizione per l’applicazione di machine learning. Qui devono essere monitorate due cose:
- La salute dell’ambiente in cui viene implementato (ad esempio: carico, utilizzo, latenza)
- La salute del modello stesso (ad esempio: metriche di prestazione, distribuzione di output).
La cadenza del processo di monitoraggio deve anche essere determinata in questa fase. Monitorerai la tua applicazione di ML quotidianamente, settimanalmente o mensilmente?
Ora hai costruito, implementato e monitorizzato una robusta applicazione di machine learning. Ma purtroppo la ruota non si ferma, poiché i passaggi sopra menzionati devono essere iterati continuamente. 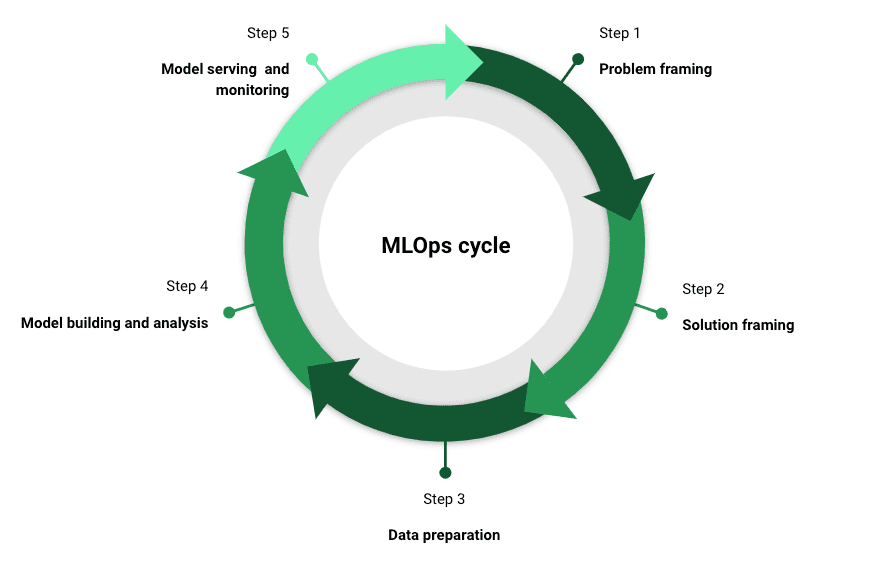
Caso di studio FinTech
Per mettere in pratica i cinque passaggi sopra menzionati, supponiamo in questa sezione che tu sia un scienziato dati presso un’azienda FinTech incaricata di implementare un modello di frode per rilevare transazioni fraudolente.
In questo caso, inizia con un’analisi approfondita del tipo di frode (prima parte o terza parte?) che stai cercando di rilevare. Come vengono identificate le transazioni come frodi o meno? Sono segnalate dall’utente finale o devi usare euristici per identificare una frode? Chi consumerà il modello? Sarà utilizzato in tempo reale o in modalità batch? Le risposte alle domande sopra sono cruciali per risolvere questo problema aziendale.
Successivamente, pensa alla soluzione migliore per affrontare questo problema. Hai bisogno di machine learning per affrontarlo o puoi iniziare con un semplice euristico per affrontare la frode? Tutte le frodi provengono da un piccolo insieme di indirizzi IP?
Se decidi di costruire un modello di machine learning (supponiamo apprendimento supervisionato per questo caso), avrai bisogno di etichette e caratteristiche. Come affronterai le variabili mancanti? E gli outlier? Qual è la finestra di osservazione per le etichette di frode? Cioè, quanto tempo impiega un utente per segnalare una transazione fraudolenta? C’è un data warehouse che puoi usare per costruire le caratteristiche? Assicurati di convalidare i dati e le caratteristiche prima di procedere. Questo è anche un buon momento per impegnarti con i portatori di interesse sulla direzione del progetto.
Una volta ottenuti i dati necessari, costruisci il modello e svolgi l’analisi necessaria. Assicurati che la metrica del modello sia allineata all’uso aziendale (ad esempio: potrebbe essere il recall al primo decile per questo caso d’uso). L’algoritmo del modello scelto soddisfa i requisiti di latenza?
Infine, coordina con l’ingegneria per implementare e servire il modello. Poiché la rilevazione delle frodi è un ambiente molto dinamico, in cui i truffatori cercano di stare sempre un passo avanti al sistema, il monitoraggio è molto cruciale. Avere un piano di monitoraggio sia per i dati che per il modello. Misure come il PSI (indice di stabilità della popolazione) sono comuni per tenere traccia della deriva dei dati. Con quale frequenza rialleni il modello?
Ora puoi creare con successo valore aziendale riducendo le transazioni fraudolente utilizzando il machine learning (se necessario!).
Conclusioni
Spero che dopo aver letto questo articolo, tu veda i vantaggi dell’implementazione di MLOps nella tua azienda. Per riassumere, MLOps garantisce che il team di scienze dei dati:
- affronti il giusto problema aziendale
- utilizzi il giusto strumento per risolvere il problema
- sfrutti il dataset che rappresenta il problema
- costruisca il modello di machine learning ottimale
- e infine implementi e monitori il modello per garantire il continuo successo
Tuttavia, sii consapevole dei comuni errori per garantire che il tuo progetto di scienze dei dati non diventi una lapide nel cimitero delle scienze dei dati! Bisogna ricordare che un’applicazione di scienze dei dati è una cosa viva e respirante. I dati e il modello devono essere continuamente monitorati. La governance dell’IA dovrebbe essere considerata fin dall’inizio e non come un’aggiunta successiva.
Con questi principi in mente, sono sicuro che potrai veramente creare valore aziendale sfruttando il machine learning (se necessario!).
Riferimenti MLOps
- Machine Learning Engineering for Production (MLOps)
- Un’introduzione gentile a MLOps
- Pratiche MLOps per scienziati dei dati
- MLOps: la prossima stella lucente
Natesh Babu Arunachalam è un leader delle scienze dei dati presso Mastercard, attualmente concentrato sulla costruzione di applicazioni AI innovative utilizzando i dati bancari aperti.