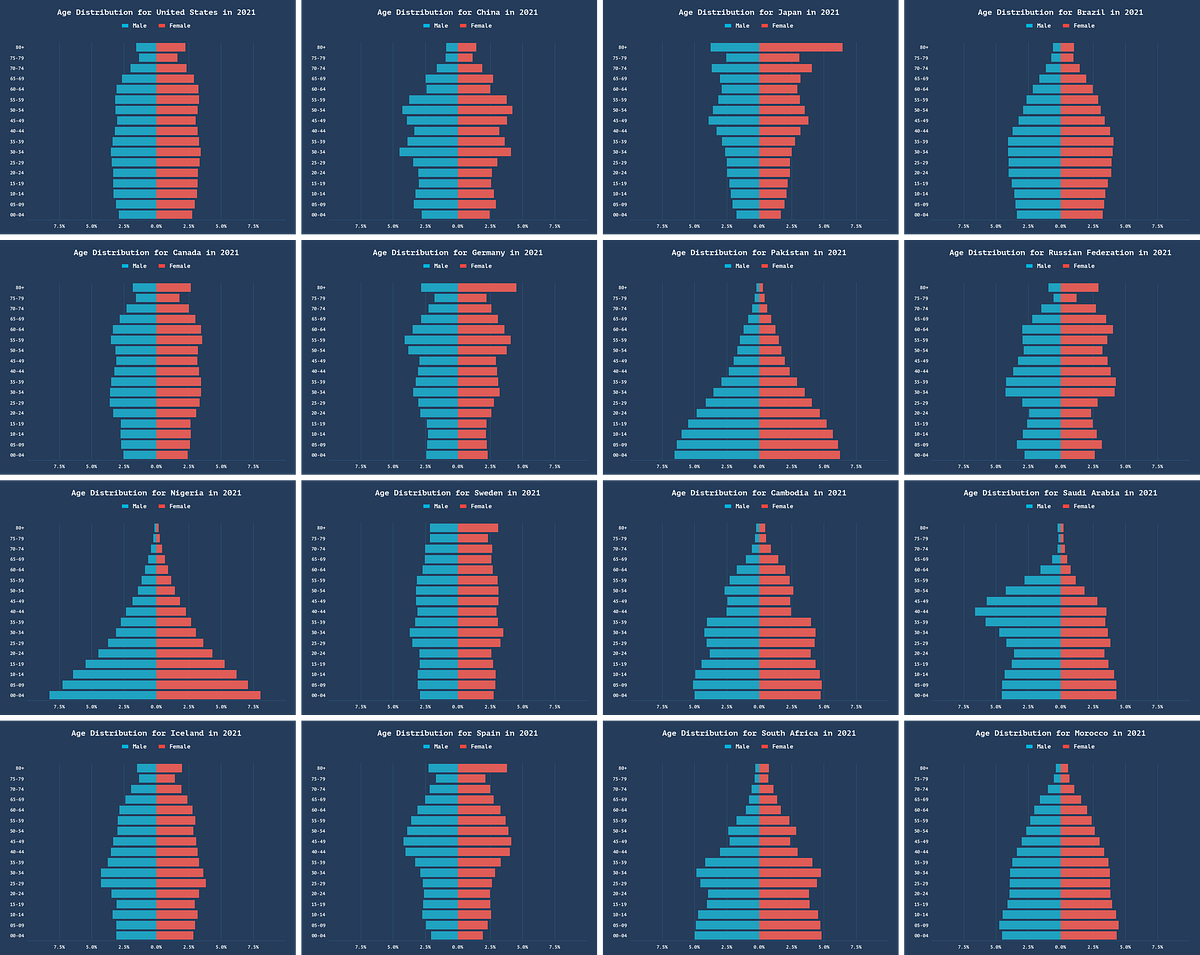
Come l’AI di Meta genera musica basata su una melodia di riferimento.
'How Meta's AI generates music based on a reference melody.'
MusicGen, analizzato
MusicGen di Meta
Il 13 giugno 2023, Meta (ex Facebook) ha fatto scalpore nelle comunità musicali e di intelligenza artificiale con il rilascio del loro modello di musica generativa, MusicGen. Questo modello non solo supera il MusicLM di Google, lanciato all’inizio di quest’anno, in termini di funzionalità, ma viene anche addestrato su dati musicali con licenza e reso open-source per l’uso non commerciale.
Ciò significa che non solo puoi leggere la ricerca o ascoltare le demo, ma puoi anche copiare il loro codice da GitHub o sperimentare con il modello in un’app web su HuggingFace.
Oltre a generare audio da un prompt di testo, MusicGen può anche generare musica basata su una determinata melodia di riferimento, una funzione nota come condizionamento della melodia. In questo post sul blog, mostrerò come Meta ha implementato questa funzionalità utile e affascinante nel loro modello. Ma prima di approfondire questo argomento, comprendiamo come funziona il condizionamento della melodia nella pratica.
Esempi
Traccia di base
Il seguente è un breve snippet di musica elettronica che ho prodotto per questo articolo. Presenta batterie elettroniche, due bassi 808 dominanti e due synth sincopati. Quando lo ascolti, cerca di identificare la “melodia principale” della traccia.
- Voxel51 rende open-source VoxelGPT un assistente AI che sfrutta la potenza di GPT-3.5 per generare codice Python per l’analisi di dataset di computer vision.
- Analisi delle serie temporali delle azioni Netflix con Pandas
- Cosa fa esattamente un Data Scientist?
Usando MusicGen, posso ora generare musica in altri generi che seguono la stessa melodia principale. Tutto ciò di cui ho bisogno è la mia traccia di base e un prompt di testo che descriva come dovrebbe suonare il nuovo pezzo.
Variante orchestrale
Un grande arrangiamento orchestrale con percussioni tonanti, fanfare di ottoni epici e archi che si innalzano, creando un’atmosfera cinematografica adatta a una battaglia eroica.
Variante reggae
traccia reggae classica con un assolo di chitarra elettronica
Variante jazz
jazz soft, con un assolo di sassofono, accordi di piano e rullante pieno di percussioni
Quanto sono buoni i risultati?
Anche se MusicGen non si attiene strettamente ai miei prompt di testo e crea musica leggermente diversa da quella richiesta, i pezzi generati riflettono comunque accuratamente il genere richiesto e, cosa più importante, ogni pezzo mostra la propria interpretazione della melodia principale della traccia di base.
Sebbene i risultati non siano perfetti, trovo le capacità di questo modello abbastanza impressionanti. Il fatto che MusicGen sia stato uno dei modelli più popolari su HuggingFace fin dal suo rilascio sottolinea ulteriormente la sua importanza. Detto questo, approfondiamo gli aspetti tecnici di come funziona il condizionamento della melodia.
Come vengono addestrati i modelli di testo-musica

Quasi tutti i modelli di musica generativa attuali seguono la stessa procedura durante l’addestramento. Vengono forniti con un ampio database di tracce musicali accompagnate da descrizioni di testo corrispondenti. Il modello impara la relazione tra parole e suoni, nonché come convertire un prompt di testo dato in un pezzo di musica coerente e piacevole. Durante il processo di formazione, il modello ottimizza le proprie composizioni confrontandole con le vere tracce musicali nel dataset. Ciò consente al modello di identificare i propri punti di forza e le aree che richiedono miglioramento.
Il problema sta nel fatto che una volta che un modello di apprendimento automatico viene addestrato per una specifica attività, come la generazione di testo-musica, è limitato a quella particolare attività. Sebbene sia possibile far eseguire a MusicGen determinate attività per cui non è stato esplicitamente addestrato, come continuare una determinata musica, non può essere previsto che affronti tutte le richieste di generazione di musica. Ad esempio, non può semplicemente prendere una melodia e trasformarla in un genere diverso. Sarebbe come gettare patate in un tostapane e aspettarsi che escano delle patatine fritte. Invece, è necessario addestrare un modello separato per implementare questa funzionalità.
Una semplice modifica alla ricetta di addestramento
Esploriamo come Meta ha adattato la procedura di addestramento del modello per consentire a MusicGen di generare variazioni di una melodia data in base a un prompt di testo. Tuttavia, ci sono diverse sfide associate a questo approccio. Uno degli ostacoli principali è l’ambiguità nell’identificare “la melodia” di una canzone e rappresentarla in modo significativo dal punto di vista computazionale. Tuttavia, per comprendere la nuova procedura di addestramento a un livello più ampio, supponiamo un accordo su ciò che costituisce “la melodia” e su come può essere facilmente estratta e fornita al modello. In questo scenario, il metodo di addestramento aggiustato può essere delineato come segue:

Per ogni traccia nel database, il primo passo è estrarne la melodia. Successivamente, il modello è alimentato sia con la descrizione testuale della traccia che con la sua corrispondente melodia, inducendo il modello a ricreare la traccia originale. Fondamentalmente, questo approccio semplifica l’obiettivo di addestramento originale, in cui il modello era unicamente incaricato di ricreare la traccia in base al testo.
Per capire perché facciamo questo, chiediamoci cosa impara il modello di intelligenza artificiale in questa procedura di addestramento. In sostanza, impara come una melodia può essere trasformata in un pezzo completo di musica in base a una descrizione testuale. Ciò significa che dopo l’addestramento, possiamo fornire al modello una melodia e chiedergli di comporre un pezzo di musica con qualsiasi genere, umore o strumentazione. Per il modello, questa è la stessa attività di generazione “semi-alla cieca” che ha eseguito con successo innumerevoli volte durante l’addestramento.
Dopo aver compreso la tecnica utilizzata da Meta per insegnare la generazione di musica condizionata alla melodia al modello, dobbiamo comunque affrontare la sfida di definire precisamente ciò che costituisce “la melodia”.
Cos’è “la melodia”?
La verità è che non esiste un metodo oggettivo per determinare o estrarre “la melodia” di un brano musicale polifonico, a meno che tutti gli strumenti suonino all’unisono. Anche se spesso c’è uno strumento predominante come una voce, una chitarra o un violino, ciò non implica necessariamente che gli altri strumenti non facciano parte di “la melodia”. Prendiamo come esempio “Bohemian Rhapsody” dei Queen. Quando pensi alla canzone, potresti prima ricordare le melodie vocali principali di Freddie Mercury. Tuttavia, ciò significa che il pianoforte nell’intro, i cori nella sezione centrale e la chitarra elettrica prima di “So you think you can stone me…” non fanno parte della melodia?
Un metodo per estrarre “la melodia” di una canzone consiste nel considerare la melodia più prominente come quella più dominante, identificata tipicamente come la melodia più rumorosa del mix. Il cromagramma è una rappresentazione ampiamente utilizzata che visualizza visivamente le note musicali più dominanti in un brano. Di seguito, puoi trovare il cromagramma della traccia di riferimento, inizialmente con la strumentazione completa e poi escludendo batteria e basso. Sul lato sinistro, le note più rilevanti per la melodia (B, F#, G) sono evidenziate in blu.
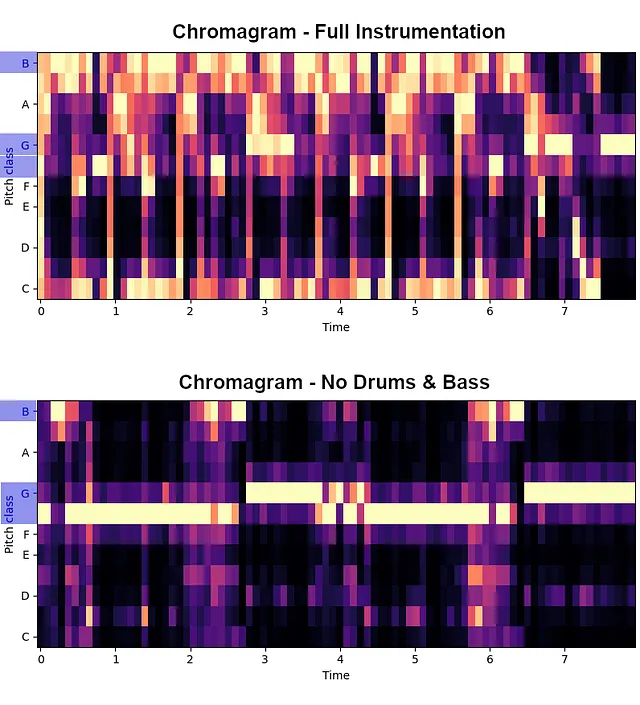
Entrambi i cromagrammi rappresentano accuratamente le note melodiche principali, con la versione della traccia senza batteria e basso che fornisce una visualizzazione più chiara della melodia. Lo studio di Meta ha anche rivelato la stessa osservazione, che li ha portati a utilizzare il loro strumento di separazione delle sorgenti (DEMUCS) per rimuovere eventuali elementi ritmici disturbanti dalla traccia. Questo processo porta a una rappresentazione sufficientemente rappresentativa di “la melodia”, che può quindi essere fornita al modello.
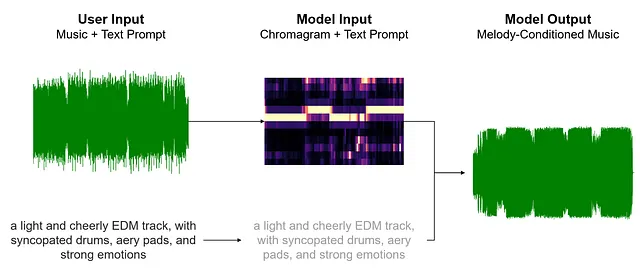
In sintesi, ora possiamo collegare i pezzi per comprendere il processo sottostante quando si richiede a MusicGen di eseguire la generazione condizionata alla melodia. Ecco una rappresentazione visiva del flusso di lavoro:
Limitazioni

Mentre MusicGen mostra promettenti sviluppi nella condizionamento melodico, è importante riconoscere che la tecnologia è ancora un lavoro in corso. I Cromagrammi, anche quando batteria e basso vengono rimossi, offrono una rappresentazione imperfetta della melodia di una traccia. Una limitazione è che i cromagrammi categorizzano tutte le note in 12 classi di toni occidentali, il che significa che catturano la transizione tra due classi di toni ma non la direzione (verso l’alto o verso il basso) della melodia.
Per esempio, l’intervallo melodico tra il passaggio da C4 a G4 (una quinta perfetta) differisce significativamente rispetto al passaggio da C4 a G3 (una quarta perfetta). Tuttavia, in un cromagramma, entrambi gli intervalli sembrerebbero uguali. Il problema si aggrava con i salti di ottava, poiché il cromagramma indicherebbe che la melodia è rimasta sulla stessa nota. Consideriamo come un cromagramma interpretarebbe erroneamente il salto emotivo di ottava eseguito da Céline Dion in “My Heart Will Go On” durante la frase “wher-e-ver you are” come un movimento melodico stabile. Per dimostrarlo, guarda il cromagramma per il ritornello di “Take on Me” degli A-ha, qui sotto. Riflette l’idea della melodia della canzone?

Un’altra sfida è il pregiudizio intrinseco del cromagramma. Funziona bene nel catturare la melodia di alcune canzoni, ma completamente sbaglia in altre. Questo pregiudizio è sistematico piuttosto che casuale. Le canzoni con melodie dominanti, salti minimi di intervallo e suonate all’unisono sono meglio rappresentate dal cromagramma rispetto alle canzoni con melodie complesse distribuite su più strumenti e con grandi salti di intervallo.
Inoltre, sono da notare le limitazioni del modello AI generativo stesso. L’audio di output presenta ancora differenze notevoli rispetto alla musica fatta dall’uomo e mantenere uno stile coerente su un intervallo di sei secondi rimane una lotta. Inoltre, MusicGen non riesce a catturare fedelmente gli aspetti più intricati del prompt di testo, come dimostrato dagli esempi forniti in precedenza. Saranno necessari ulteriori sviluppi tecnologici per il generatore di melodie per raggiungere un livello in cui possa essere utilizzato non solo per divertimento e ispirazione, ma anche per generare musica amichevole per l’utente finale.
Prospettive future

Come possiamo migliorare l’AI?
Dal mio punto di vista, una delle principali preoccupazioni che la ricerca futura dovrebbe affrontare riguardo alla generazione di musica condizionata dalla melodia è l’estrazione e la rappresentazione della “melodia” da una traccia. Mentre il cromagramma è un metodo di elaborazione del segnale ben consolidato e semplice, ci sono numerose approcci più nuovi ed sperimentali che utilizzano il deep learning a tale scopo. Sarebbe interessante vedere aziende come Meta che traggono ispirazione da questi sviluppi, molti dei quali sono coperti in una completa recensione di 72 pagine di Reddy et al. (2022).
Riguardo alla qualità del modello stesso, sia la qualità audio che la comprensione degli input di testo possono essere migliorati aumentando la dimensione del modello e dei dati di addestramento, così come lo sviluppo di algoritmi più efficienti per questa specifica attività. A mio parere, il rilascio di MusicLM nel gennaio 2023 assomiglia a un “momento GPT-2”. Stiamo cominciando a testimoniare le capacità di questi modelli, ma sono ancora necessari notevoli miglioramenti su vari aspetti. Se questa analogia si dimostrerà vera, possiamo anticipare il rilascio di un modello di generazione musicale simile a GPT-3 prima di quanto ci aspettiamo.
Qual è l’impatto sugli artisti musicali?
Come spesso accade con l’AI musicale generativa, sorgono preoccupazioni riguardo al potenziale impatto negativo sul lavoro e sulla sussistenza dei creatori musicali. Mi aspetto che in futuro diventerà sempre più difficile guadagnarsi da vivere creando variazioni di melodie esistenti. Questo è particolarmente evidente in scenari come la produzione di jingle, dove le aziende possono generare senza sforzo numerose variazioni di una caratteristica melodia di jingle a costi minimi per nuove campagne pubblicitarie o annunci personalizzati. Senza dubbio, ciò costituisce una minaccia per gli artisti musicali che dipendono da tali attività come fonte significativa di reddito. Ribadisco il mio appello ai creativi coinvolti nella produzione di musica valutata per le sue qualità musicali oggettive piuttosto che soggettive e umane (come la musica in stock o i jingle) di esplorare alternative fonti di reddito per prepararsi al futuro.
Da un lato positivo, la generazione di musica condizionata dalla melodia rappresenta un incredibile strumento per migliorare la creatività umana. Se qualcuno sviluppa una melodia accattivante e memorabile, può generare rapidamente esempi di come potrebbe suonare in vari generi. Questo processo può aiutare a identificare il genere e lo stile ideale per portare la musica alla vita. Inoltre, offre l’opportunità di rivedere progetti passati nel proprio catalogo musicale, esplorando il loro potenziale quando tradotti in diversi generi o stili. Infine, questa tecnologia abbassa la barriera di ingresso per individui creativi senza formazione musicale formale per entrare nel campo. Ora chiunque può inventare una melodia, canticchiarla in un microfono dello smartphone e condividere arrangiamenti notevoli delle loro idee con amici, familiari o addirittura cercare di raggiungere un pubblico più vasto.
La questione se la generazione di musica AI sia vantaggiosa per le nostre società resta aperta al dibattito. Tuttavia, credo fermamente che la generazione di musica condizionata dalla melodia sia uno dei casi d’uso di questa tecnologia che genuinamente migliora il lavoro dei creativi professionisti e aspiranti. Aggiunge valore offrendo nuove vie di esplorazione. Non vedo l’ora di assistere a ulteriori sviluppi in questo campo nel prossimo futuro.
Se sei affascinato dall’intersezione tra musica e AI, ti piaceranno anche alcuni dei miei altri articoli su questo argomento:
- Come Google ha usato dataset falsi per addestrare la generazione di musica AI
- I chatbot stanno per sconvolgere la ricerca musicale
- MusicLM – Ha risolto Google la generazione di musica AI?