Tutto ciò che devi sapere per costruire la tua prima app di LLM
Guide to building your first LLM app
Un tutorial passo-passo per i caricatori di documenti, gli embeddings, i vector stores e i template di prompt
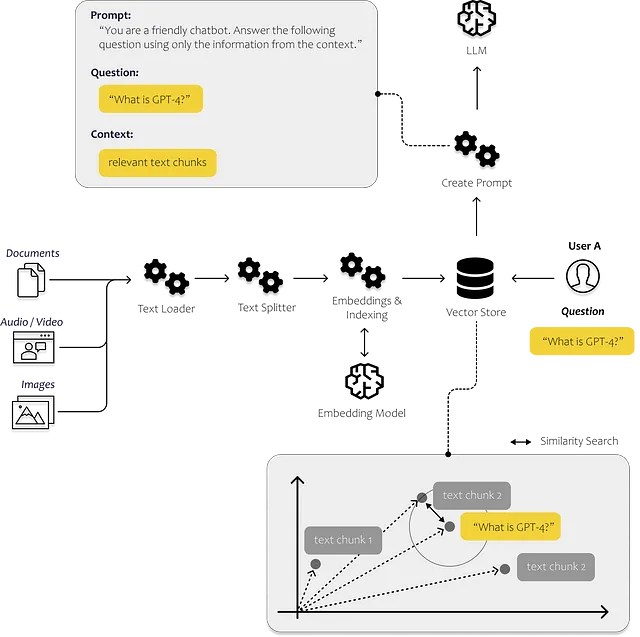
Tabella dei contenuti
Puoi sfogliare l’articolo facendo clic sulle immagini.
Se stai cercando solo un breve tutorial che spiega come costruire un’applicazione LLM semplice, puoi saltare alla sezione “6. Creazione di un Vector store”, lì hai tutti i frammenti di codice di cui hai bisogno per costruire un’applicazione LLM minimalista con vector store, template di prompt e chiamata LLM.


- Reti Neurali Ricorrenti, Spiegate e Visualizzate dalle Basi
- L’IA si mangerà da sola? Questo documento sull’IA introduce un fenomeno chiamato collasso del modello che si riferisce a un processo di apprendimento degenerativo in cui i modelli iniziano a dimenticare gli eventi improbabili nel tempo.
- Sbloccare il Potenziale dell’Intelligenza Artificiale con MINILLM Una Profonda Immersione nella Distillazione della Conoscenza dai Modelli Linguistici Più Grandi ai loro Corrispettivi Più Piccoli.







Perché abbiamo bisogno di LLM
L’evoluzione del linguaggio ci ha portato umani incredibilmente lontano fino ad oggi. Ci consente di condividere conoscenze in modo efficiente e collaborare nella forma che conosciamo oggi. Di conseguenza, la maggior parte delle nostre conoscenze collettive continua ad essere conservata e comunicata attraverso testi scritti non organizzati.
Le iniziative intraprese negli ultimi due decenni per digitalizzare informazioni e processi si sono spesso concentrate sull’accumulo di sempre più dati in database relazionali. Questo approccio consente agli algoritmi di apprendimento automatico analitici tradizionali di elaborare e comprendere i nostri dati.
Tuttavia, nonostante i nostri sforzi estesi per archiviare sempre più dati in modo strutturato, non siamo ancora in grado di catturare e processare l’intera nostra conoscenza.
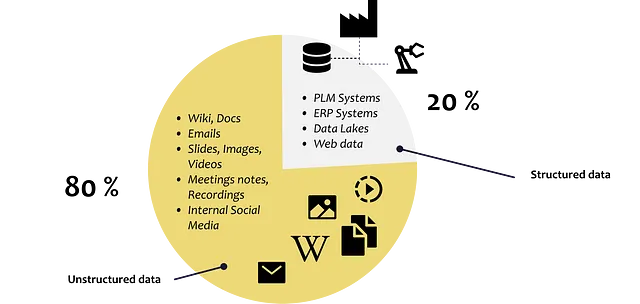
Circa l’80% di tutti i dati nelle aziende è non strutturato, come descrizioni del lavoro, curriculum, e-mail, documenti di testo, diapositive Power Point, registrazioni vocali, video e social media
Lo sviluppo e il progresso che portano a GPT3.5 rappresentano una tappa importante poiché ci consente di interpretare ed analizzare efficacemente diversi set di dati, indipendentemente dalla loro struttura o mancanza di struttura. Oggi abbiamo modelli che possono comprendere e generare vari tipi di contenuti, tra cui testo, immagini e file audio.
Quindi come possiamo sfruttare le loro capacità per le nostre esigenze e dati?
Fine-Tuning vs. Iniezione di Contesto
In generale, abbiamo due approcci fondamentalmente diversi per consentire ai grandi modelli di lingua di rispondere a domande che il LLM non può conoscere: Fine-tuning del modello e Iniezione di contesto
Fine-tuning del modello
Il fine-tuning si riferisce all’allenamento di un modello di lingua esistente con dati aggiuntivi per ottimizzarlo per un compito specifico.
Invece di allenare un modello di lingua da zero, viene utilizzato un modello pre-allenato come BERT o LLama e poi adattato alle esigenze di un compito specifico aggiungendo dati di allenamento specifici per il caso d’uso.
Un team dell’Università di Stanford ha utilizzato il LLM Llama e lo ha sottoposto a fine-tuning utilizzando 50.000 esempi di come potrebbe apparire un’interazione utente/modello. Il risultato è un Chat Bot che interagisce con un utente e risponde a domande. Questo passaggio di fine-tuning ha cambiato il modo in cui il modello interagisce con l’utente finale.
→ Malintesi riguardo al fine-tuning
Il fine-tuning dei PLLM (Pre-trained Language Models) è un modo per adattare il modello per un compito specifico, ma non consente di iniettare la propria conoscenza di dominio nel modello. Ciò perché il modello è già stato allenato su una massiccia quantità di dati di lingua generale e i dati del dominio specifico non sono di solito sufficienti per sovrascrivere ciò che il modello ha già appreso.
Quindi, quando si sottopone il modello a fine-tuning, potrebbe occasionalmente fornire risposte corrette, ma spesso fallirà perché si basa pesantemente sulle informazioni apprese durante il pre-allenamento, che potrebbero non essere precise o rilevanti per il compito specifico. In altre parole, il fine-tuning aiuta il modello ad adattarsi a COME comunica, ma non necessariamente a COSA comunica. (Porsche AG, 2023)
È qui che entra in gioco l’iniezione di contesto.
Iniezione di Contesto / In-context learning
Quando si utilizza l’iniezione di contesto, non si modifica il LLM, ci si concentra invece sulla prompt stessa e si inietta il contesto rilevante nella prompt.
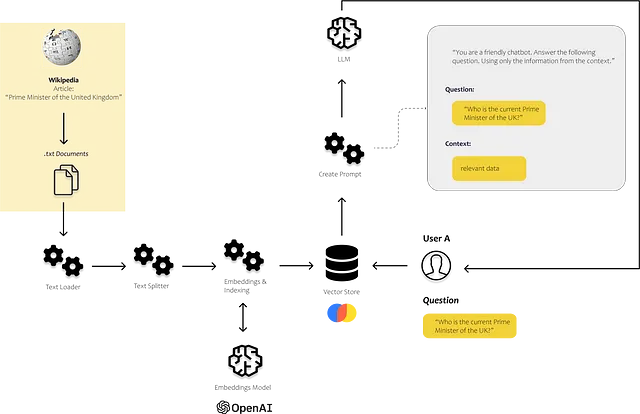
Quindi, dobbiamo pensare a come fornire alla prompt le informazioni corrette. Nella figura sottostante, puoi vedere schematicamente come funziona l’intero processo. Abbiamo bisogno di un processo che sia in grado di identificare i dati più rilevanti. Per fare ciò, dobbiamo consentire al nostro computer di confrontare le varie parti di testo tra di loro.
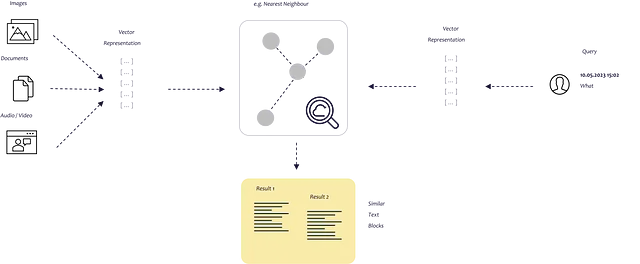
Ciò può essere fatto con le embedding. Con le embedding, traduciamo il testo in vettori, consentendoci di rappresentare il testo in uno spazio di embedding multidimensionale. I punti che sono più vicini tra loro nello spazio sono spesso utilizzati nello stesso contesto. Per evitare che questa ricerca di similarità richieda troppo tempo, immagazziniamo i nostri vettori in un database di vettori e li indicizziamo.
Microsoft ci sta mostrando come potrebbe funzionare con Bing Chat. Bing combina la capacità dei LLM di comprendere il linguaggio e il contesto con l’efficienza della ricerca web tradizionale.
Lo scopo dell’articolo è quello di dimostrare il processo di creazione di una soluzione semplice che ci consente di analizzare i nostri stessi testi e documenti, e quindi incorporare le conoscenze acquisite in esse nelle risposte che la nostra soluzione restituisce all’utente. Descriverò tutti i passaggi e i componenti necessari per implementare una soluzione end-to-end.
Quindi, come possiamo utilizzare le capacità dei LLM per soddisfare le nostre esigenze? Andiamo passo dopo passo.
Tutorial passo-passo – La tua prima app LLM
Nel seguito, vogliamo utilizzare i LLM per rispondere alle richieste relative ai nostri dati personali. Per fare ciò, iniziamo trasferendo il contenuto dei nostri dati personali in un database vettoriale. Questo passaggio è cruciale perché ci consente di cercare efficientemente le sezioni rilevanti all’interno del testo. Utilizzeremo queste informazioni dai nostri dati e le capacità dei LLM per interpretare il testo e rispondere alla domanda dell’utente.
Possiamo anche guidare il chatbot per rispondere esclusivamente alle domande basate sui dati che forniamo. In questo modo, possiamo garantire che il chatbot rimanga concentrato sui dati a disposizione e fornisca risposte accurate e pertinenti.
Per implementare il nostro caso d’uso, faremo affidamento pesantemente su LangChain.
Cos’è LangChain?
“LangChain è un framework per lo sviluppo di applicazioni alimentate da modelli di linguaggio.” (Langchain, 2023)
Quindi, LangChain è un framework Python progettato per supportare la creazione di varie applicazioni LLM come chatbot, strumenti di sintesi e praticamente qualsiasi strumento si desideri creare per sfruttare la potenza degli LLM. La libreria combina vari componenti di cui avremo bisogno. Possiamo collegare questi componenti in catene chiamate catene.
I moduli più importanti di Langchain sono (Langchain, 2023):
- Modelli: Interfacce per vari tipi di modelli
- Prompt: Gestione del prompt, ottimizzazione del prompt e serializzazione del prompt
- Indici: Caricatori di documenti, divisori di testo, archivi di vettori – consentono un accesso più rapido ed efficiente ai dati
- Catene: Le catene vanno oltre una singola chiamata LLM, ci consentono di configurare sequenze di chiamate
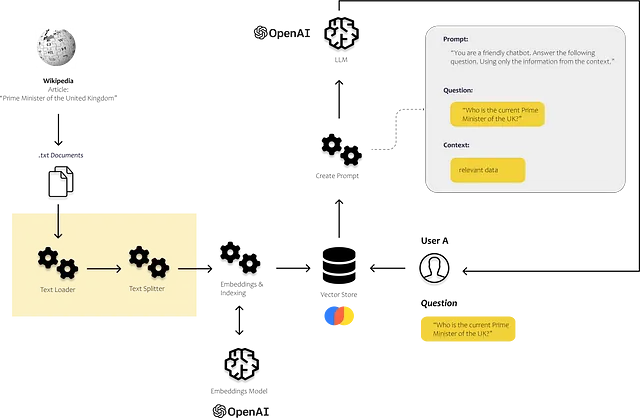
Nell’immagine sottostante, si può vedere dove entrano in gioco questi componenti. Carichiamo e processiamo i nostri dati non strutturati utilizzando i caricatori di documenti e i divisori di testo dal modulo degli indici. Il modulo prompt ci consente di iniettare il contenuto trovato nel nostro template di prompt, e infine, inviamo il prompt al nostro modello utilizzando il modulo del modello.
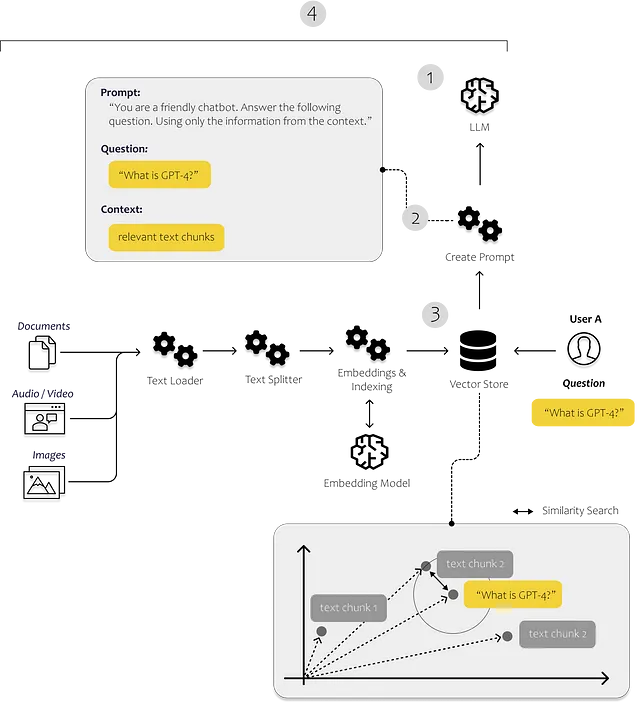
5. Agenti: Gli agenti sono entità che utilizzano gli LLM per prendere decisioni su quale azione intraprendere. Dopo aver preso un’azione, osservano l’esito di quella azione e ripetono il processo fino a quando il loro compito non è completato.
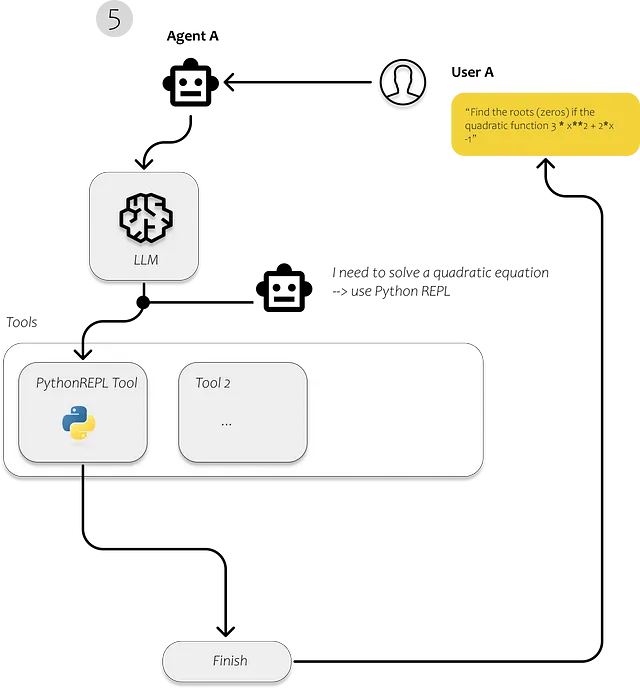
Usiamo Langchain nel primo passo per caricare i documenti, analizzarli e renderli efficientemente ricercabili. Dopo aver indicizzato il testo, dovrebbe diventare molto più efficiente riconoscere i frammenti di testo rilevanti per rispondere alle domande dell’utente.
Ciò di cui abbiamo bisogno per la nostra semplice applicazione è ovviamente un LLM. Useremo GPT3.5 tramite l’API OpenAI. Quindi abbiamo bisogno di un archivio di vettori che ci consenta di alimentare l’LLM con i nostri dati. E se vogliamo eseguire diverse azioni per diverse query, abbiamo bisogno di un agente che decida cosa dovrebbe accadere per ogni query.
Cominciamo dall’inizio. Prima di tutto dobbiamo importare i nostri documenti.
La sezione seguente descrive quali moduli sono inclusi nel modulo di caricamento di LangChain per caricare diversi tipi di documenti da diverse fonti.
1. Caricamento dei documenti utilizzando Langchain
LangChain è in grado di caricare una serie di documenti da una vasta gamma di fonti. È possibile trovare un elenco di possibili caricatori di documenti nella documentazione di LangChain. Tra questi ci sono caricatori per pagine HTML, bucket S3, PDF, Notion, Google Drive e molti altri.
Per il nostro semplice esempio, utilizziamo dati che probabilmente non erano inclusi nei dati di addestramento di GPT3.5. Utilizzo l’articolo di Wikipedia su GPT4 perché presumo che GPT3.5 abbia conoscenze limitate su GPT4.
Per questo esempio minimo, non utilizzo nessuno dei caricatori di LangChain, sto solo estraendo direttamente il testo da Wikipedia [Licenza: CC BY-SA 3.0] utilizzando BeautifulSoup.
Si noti che lo scraping dei siti Web dovrebbe essere effettuato solo in conformità con i termini d’uso del sito Web e lo stato di copyright/licenza del testo e dei dati che si desidera utilizzare.
import requestsfrom bs4 import BeautifulSoupurl = "https://en.wikipedia.org/wiki/GPT-4"response = requests.get(url)soup = BeautifulSoup(response.content, 'html.parser')# find the content divcontent_div = soup.find('div', {'class': 'mw-parser-output'})# remove unwanted elements from divunwanted_tags = ['sup', 'span', 'table', 'ul', 'ol']for tag in unwanted_tags: for match in content_div.findAll(tag): match.extract()print(content_div.get_text())
2. Dividiamo il nostro documento in frammenti di testo
Successivamente, dobbiamo dividere il testo in sezioni più piccole chiamate pezzi di testo. Ogni pezzo di testo rappresenta un punto dati nello spazio di embedding, consentendo al computer di determinare la somiglianza tra questi pezzi.
Il seguente frammento di testo utilizza il modulo text splitter di langchain. In questo caso particolare, specifichiamo una dimensione di chunk di 100 e un sovrapposizione di chunk di 20. È comune utilizzare chunk di testo più grandi, ma è possibile sperimentare un po’ per trovare la dimensione ottimale per il caso d’uso. È solo necessario ricordare che ogni LLM ha un limite di token (4000 tokes per GPT 3.5). Poiché stiamo inserendo i blocchi di testo nel nostro prompt, dobbiamo assicurarci che l’intero prompt non sia più grande di 4000 token.
da langchain.text_splitter import RecursiveCharacterTextSplitterarticle_text = content_div.get_text()text_splitter = RecursiveCharacterTextSplitter( # Imposta una dimensione di chunk davvero piccola, solo per mostrare. chunk_size = 100, chunk_overlap = 20, length_function = len,)texts = text_splitter.create_documents([article_text])print(texts[0])print(texts[1])
Ciò suddivide l’intero testo come segue:
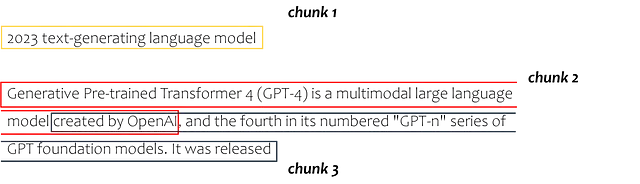
3. Da Text Chunks a Embeddings
Ora dobbiamo rendere i componenti testuali comprensibili e confrontabili con i nostri algoritmi. Dobbiamo trovare un modo per convertire il linguaggio umano in forma digitale, rappresentata da bit e byte.
L’immagine fornisce un esempio semplice che può sembrare ovvio alla maggior parte degli esseri umani. Tuttavia, dobbiamo trovare un modo per far capire al computer che il nome “Charles” è associato agli uomini piuttosto che alle donne e che, se Charles è un uomo, è il re e non la regina.

Negli ultimi anni sono emersi nuovi metodi e modelli che fanno proprio questo. Quello che vogliamo è un modo per tradurre il significato delle parole in uno spazio n-dimensionale, in modo da poter confrontare i pezzi di testo tra loro e persino calcolare una misura per la loro somiglianza.
I modelli di embedding cercano di imparare proprio questo analizzando il contesto in cui le parole vengono tipicamente utilizzate. Poiché tè, caffè e colazione sono spesso utilizzati nello stesso contesto, sono più vicini tra loro nello spazio n-dimensionale rispetto, ad esempio, a tè e piselli. Tè e piselli suonano simili ma sono raramente usati insieme. (AssemblyAI, 2022)

I modelli di embedding ci forniscono un vettore per ogni parola nello spazio di embedding. Infine, rappresentandoli utilizzando vettori, siamo in grado di eseguire calcoli matematici, come il calcolo delle somiglianze tra le parole come la distanza tra i punti dati.

Per convertire il testo in embedding, ci sono diversi modi, ad esempio Word2Vec, GloVe, fastText o ELMo.
Modelli di embedding
Per catturare le somiglianze tra le parole negli embedding, Word2Vec utilizza una semplice rete neurale. Alleniamo questo modello con grandi quantità di dati di testo e vogliamo creare un modello in grado di assegnare un punto nello spazio di embedding n-dimensionale ad ogni parola e descrivere quindi il suo significato sotto forma di vettore.
Per l’allenamento, assegniamo un neurone nel layer di input a ciascuna parola unica nel nostro set di dati. Nell’immagine sottostante, potete vedere un esempio semplice. In questo caso, il layer nascosto contiene solo due neuroni. Due, perché vogliamo mappare le parole in uno spazio di embedding bidimensionale. (I modelli esistenti sono in realtà molto più grandi e quindi rappresentano le parole in spazi dimensionali superiori – il modello di embedding Ada di OpenAI, ad esempio, utilizza 1536 dimensioni) Dopo il processo di allenamento, i pesi individuali descrivono la posizione nello spazio di embedding.
In questo esempio, il nostro dataset consiste di una singola frase: “Google è un’azienda tecnologica”. Ogni parola nella frase serve come input per la rete neurale (NN). Di conseguenza, la nostra rete ha cinque neuroni di input, uno per ogni parola.
Durante il processo di allenamento, ci concentriamo sulla previsione della parola successiva per ogni parola di input. Quando iniziamo dall’inizio della frase, il neurone di input corrispondente alla parola “Google” riceve un valore di 1, mentre i neuroni restanti ricevono un valore di 0. Il nostro obiettivo è allenare la rete a prevedere la parola “è” in questo particolare scenario.
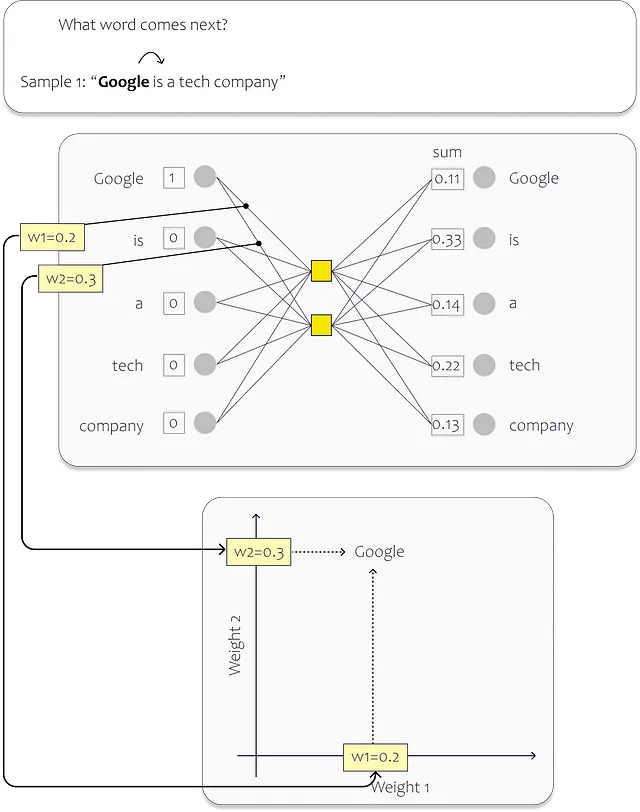
In realtà, ci sono molteplici approcci per apprendere i modelli di embedding, ognuno con il proprio modo unico di prevedere le uscite durante il processo di allenamento. Due metodi comunemente utilizzati sono CBOW (Borsa continua di parole) e Skip-gram.
In CBOW, prendiamo le parole circostanti come input e cerchiamo di prevedere la parola centrale. Al contrario, in Skip-gram, prendiamo la parola centrale come input e cerchiamo di prevedere le parole che si verificano sui suoi lati sinistro e destro. Tuttavia, non entrerò nei dettagli di questi metodi. Diciamo solo che questi approcci ci forniscono degli embedding, che sono rappresentazioni che catturano le relazioni tra le parole analizzando il contesto di grandi quantità di dati di testo.
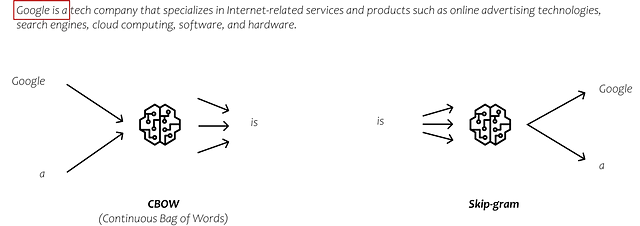
Se vuoi saperne di più sugli embedding, ci sono moltissime informazioni disponibili su internet. Tuttavia, se preferisci una guida visiva e passo-passo, potresti trovare utile guardare la StatQuest di Josh Starmer su Word Embedding e Word2Vec.
Torniamo ai modelli di embedding
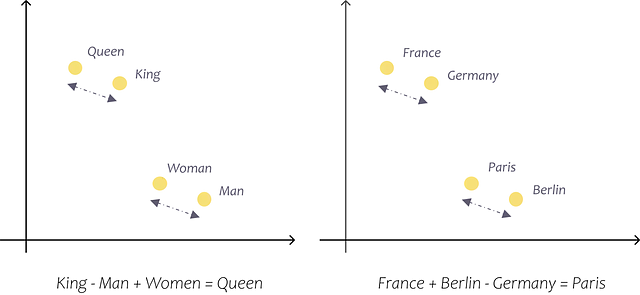
Ciò che ho appena cercato di spiegare utilizzando un esempio semplice in uno spazio di embedding bidimensionale si applica anche a modelli più grandi. Ad esempio, i vettori Word2Vec standard hanno 300 dimensioni, mentre il modello Ada di OpenAI ha 1536 dimensioni. Questi vettori preallenati ci consentono di catturare le relazioni tra le parole e i loro significati con tale precisione che possiamo effettuare calcoli con essi. Ad esempio, utilizzando questi vettori, possiamo scoprire che Francia + Berlino – Germania = Parigi, e anche più veloce + caldo – veloce = più caldo. (Tazzyman, s.d.)
In seguito vogliamo utilizzare l’API di OpenAI non solo per utilizzare i loro LLMs, ma anche per sfruttare i loro modelli di embedding.
Nota: la differenza tra i modelli di embedding e i LLMs è che i modelli di embedding si concentrano sulla creazione di rappresentazioni vettoriali di parole o frasi per catturare i loro significati e le relazioni, mentre i LLMs sono modelli versatili addestrati a generare testo coerente e pertinente in base a prompt o query forniti.
Modelli di embedding di OpenAI
Similmente ai vari LLM di OpenAI, è possibile scegliere tra una varietà di modelli di embedding, come Ada, Davinci, Curie e Babbage. Tra questi, Ada-002 è attualmente il modello più veloce ed economico, mentre Davinci fornisce generalmente la massima accuratezza e performance. Tuttavia, è necessario provarli personalmente e trovare il modello ottimale per il proprio caso d’uso. Se sei interessato a una comprensione dettagliata degli embedding di OpenAI, puoi fare riferimento alla documentazione di OpenAI.
Il nostro obiettivo con i modelli di embedding è di convertire i nostri frammenti di testo in vettori. Nel caso della seconda generazione di Ada, questi vettori hanno 1536 dimensioni di output, il che significa che rappresentano una posizione o orientamento specifico all’interno di uno spazio a 1536 dimensioni.
OpenAI descrive questi vettori di embedding nella loro documentazione come segue:
“Gli embedding che sono numericamente simili sono anche semanticamente simili. Ad esempio, il vettore di embedding di”canine companions say” sarà più simile al vettore di embedding di “woof” che a quello di “meow” (OpenAI, 2022).
Parole o frasi semanticamente simili sono più vicine tra loro nello spazio di embedding — Immagine di OpenAI
Proviamoci. Utilizziamo l’API di OpenAI per tradurre i nostri frammenti di testo in embedding come segue:
import openaiprint(texts[0])embedding = openai.Embedding.create( input=texts[0].page_content, model="text-embedding-ada-002")["data"][0]["embedding"]len(embedding)
Convertiamo il nostro testo, come il primo frammento di testo contenente “2023 text-generating language model”, in un vettore con 1536 dimensioni. In questo modo, per ogni frammento di testo, possiamo osservare nello spazio a 1536 dimensioni quali frammenti di testo sono più vicini e simili tra loro.
Proviamoci. Il nostro obiettivo è di confrontare le domande degli utenti con i frammenti di testo generando embedding per la domanda e poi confrontandola con altri punti dati nello spazio.

Quando rappresentiamo i frammenti di testo e la domanda dell’utente come vettori, acquisiamo la capacità di esplorare varie possibilità matematiche. Per determinare la similarità tra due punti dati, è necessario calcolare la loro prossimità nello spazio multidimensionale, che viene ottenuta utilizzando metriche di distanza. Ci sono diversi metodi disponibili per calcolare la distanza tra i punti. Maarten Grootendorst ha riassunto nove di essi in uno dei suoi post su Nisoo.
Una metrica di distanza comunemente utilizzata è la similarità coseno. Quindi proviamo a calcolare la similarità coseno tra la nostra domanda e i frammenti di testo:
import numpy as npfrom numpy.linalg import norm# calcola gli embedding per la domanda dell'utenteusers_question = "Che cos'è GPT-4?"question_embedding = get_embedding(text=users_question, model="text-embedding-ada-002")# crea una lista per memorizzare la similarità coseno calcolatacos_sim = []for index, row in df.iterrows(): A = row.ada_embedding B = question_embedding # calcola la similarità coseno cosine = np.dot(A,B)/(norm(A)*norm(B)) cos_sim.append(cosine)df["cos_sim"] = cos_simdf.sort_values(by=["cos_sim"], ascending=False)
Ora abbiamo l’opzione di scegliere il numero di frammenti di testo che vogliamo fornire al nostro LLM per rispondere alla domanda.
Il passo successivo è determinare quale LLM vogliamo utilizzare.
4. Definisci il modello che vuoi utilizzare
Langchain fornisce una varietà di modelli e integrazioni, tra cui GPT di OpenAI e Huggingface, tra gli altri. Se decidiamo di utilizzare GPT di OpenAI come nostro Large Language Model, il primo passo è definire la nostra API Key. Attualmente, OpenAI offre una certa capacità di utilizzo gratuito, ma una volta superato un certo numero di token al mese, dovremo passare a un account a pagamento.
Se usiamo GPT per rispondere a domande brevi simili a come faremmo con Google, i costi rimangono relativamente bassi. Tuttavia, se usiamo GPT per rispondere a domande che richiedono la fornitura di contesto esteso, come i dati personali, la query può accumulare rapidamente migliaia di token. Ciò aumenta significativamente il costo. Ma non preoccuparti, puoi impostare un limite di costo.
Cosa sono i token?
In termini più semplici, un token è essenzialmente una parola o un gruppo di parole. Tuttavia, in inglese, le parole possono avere forme diverse, come tempi verbali, plurali o parole composte. Per gestirle, possiamo usare la sottotokenizzazione, che suddivide una parola in parti più piccole come la radice, il prefisso, il suffisso e altri elementi linguistici. Ad esempio, la parola “tiresome” può essere divisa in “tire” e “some”, mentre “tired” può essere divisa in “tire” e “d”. In questo modo, possiamo riconoscere che “tiresome” e “tired” hanno la stessa radice e una derivazione simile. (Wang, 2023)
OpenAI offre un tokenizer sul suo sito web per avere un’idea di cosa sia un token. Secondo OpenAI, un token corrisponde generalmente a ~4 caratteri di testo per il testo inglese comune. Ciò corrisponde a circa ¾ di una parola (quindi 100 token ~= 75 parole). Puoi trovare un’app Tokenizer sul sito web di OpenAI che ti dà un’idea di cosa conta effettivamente come token.
Imposta un limite di utilizzo
Se sei preoccupato per il costo, puoi trovare un’opzione nel tuo portale utente OpenAI per limitare i costi mensili.
Puoi trovare la chiave API nel tuo account utente su OpenAI. Il modo più semplice è cercare su Google “chiave API OpenAI”. Questo ti porta direttamente alla pagina delle impostazioni, per creare una nuova chiave.
Per usarlo in Python, devi salvare la chiave come nuova variabile di ambiente con il nome “OPENAI_API_KEY”:
import osos.environment["OPENAI_API_KEY"] = "testapikey213412"Quando definisci i tuoi modelli, puoi impostare alcune preferenze. Il Playground di OpenAI ti dà la possibilità di sperimentare un po’ con i diversi parametri prima di decidere quali impostazioni vuoi usare:
Nella WebUI del Playground sulla destra, troverai diversi parametri forniti da OpenAI che ci permettono di influenzare l’output della LLM. Due parametri che vale la pena esplorare sono la selezione del modello e la temperatura.
Hai la possibilità di scegliere tra una varietà di modelli diversi. Il modello Text-davinci-003 è attualmente il più grande e potente. D’altra parte, modelli come Text-ada-001 sono più piccoli, più veloci e più economici.
Sotto, puoi vedere un sommario dell’elenco prezzi di OpenAI. Ada è meno costoso rispetto al modello più potente, Davinci. Quindi, se le prestazioni di Ada soddisfano le nostre esigenze, possiamo non solo risparmiare denaro, ma anche ottenere tempi di risposta più brevi.
Potresti iniziare usando Davinci e poi valutare se possiamo ottenere risultati sufficientemente buoni anche con Ada.
Quindi proviamolo in Jupyter Notebook. Stiamo usando langchain per connetterci a GPT.
from langchain.llms import OpenAIllm = OpenAI(temperature=0.7)Se vuoi vedere una lista con tutti gli attributi, usa __dict__:
llm.__dict__
Se non specifichiamo un modello particolare, il connettore langchain usa per impostazione predefinita “text-davinci-003”.
Adesso, possiamo invocare direttamente il modello in Python. Basta chiamare la funzione llm e fornire il tuo prompt come input.

Ora puoi chiedere a GPT qualsiasi cosa riguardo alla conoscenza umana comune.

GPT può fornire solo informazioni limitate su argomenti che non sono inclusi nei suoi dati di training. Ciò include dettagli specifici che non sono disponibili pubblicamente o eventi che sono avvenuti dopo l’ultimo aggiornamento dei dati di training.

Allora, come possiamo essere sicuri che i modelli siano in grado di rispondere alle domande sugli eventi attuali?
Come già menzionato, c’è un modo per farlo. Dobbiamo fornire al modello le informazioni necessarie all’interno della richiesta.
Per rispondere alla domanda sul primo ministro attuale del Regno Unito, ho alimentato la richiesta con informazioni tratte dall’articolo di Wikipedia “Primi ministri del Regno Unito”. Per riassumere il processo, stiamo:
- Caricando l’articolo
- Dividere il testo in frammenti di testo
- Calcolare gli embedding per i frammenti di testo
- Calcolare la similarità tra tutti i frammenti di testo e la domanda dell’utente
import requestsfrom bs4 import BeautifulSoupfrom langchain.text_splitter import RecursiveCharacterTextSplitterimport numpy as npfrom numpy.linalg import norm##################################################################### caricare i documenti##################################################################### URL della pagina di Wikipedia da analizzareurl = 'https://en.wikipedia.org/wiki/Prime_Minister_of_the_United_Kingdom'# Invia una richiesta GET all'URLresponse = requests.get(url)# Analizza il contenuto HTML utilizzando BeautifulSoupsoup = BeautifulSoup(response.content, 'html.parser')# Trova tutto il testo sulla paginatext = soup.get_text()##################################################################### Dividere il testo####################################################################text_splitter = RecursiveCharacterTextSplitter( # Imposta una dimensione di frammento molto piccola, solo per mostrare. chunk_size = 100, chunk_overlap = 20, length_function = len,)texts = text_splitter.create_documents([text])for text in texts: text_chunks.append(text.page_content)##################################################################### Calcolare gli embedding####################################################################df = pd.DataFrame({'text_chunks': text_chunks})# crea una nuova lista con tutti i frammenti di testotext_chunks=[]for text in texts: text_chunks.append(text.page_content)# ottenere gli embedding dal modello di embedding di testodef get_embedding(text, model="text-embedding-ada-002"): text = text.replace("\n", " ") return openai.Embedding.create(input = [text], model=model)['data'][0]['embedding']df['ada_embedding'] = df.text_chunks.apply(lambda x: get_embedding(x, model='text-embedding-ada-002'))##################################################################### Calcolare le similarità con la domanda dell'utente##################################################################### calcola gli embedding per la domanda dell'utenteusers_question = "Chi è l'attuale primo ministro del Regno Unito?"question_embedding = get_embedding(text=users_question, model="text-embedding-ada-002")Adesso cerchiamo di trovare i frammenti di testo con la massima similarità alla domanda dell’utente:
from langchain import PromptTemplatefrom langchain.llms import OpenAI# calcola gli embedding per la domanda dell'utenteusers_question = "Chi è l'attuale primo ministro del Regno Unito?"question_embedding = get_embedding(text=users_question, model="text-embedding-ada-002")# crea una lista per memorizzare la similarità cosinusacosc_sim = []for index, row in df.iterrows(): A = row.ada_embedding B = question_embedding # calcola la similarità cosinusale cosine = np.dot(A,B)/(norm(A)*norm(B)) cos_sim.append(cosine)df["cos_sim"] = cos_simdf.sort_values(by=["cos_sim"], ascending=False)
I frammenti di testo sembrano piuttosto disordinati, ma proviamoci e vediamo se GPT è abbastanza intelligente da gestirli.
Ora che abbiamo identificato i segmenti di testo che potenzialmente contengono le informazioni rilevanti, possiamo testare se il nostro modello è in grado di rispondere alla domanda. Per raggiungere questo obiettivo, dobbiamo costruire la nostra richiesta in modo da trasmettere chiaramente il nostro compito desiderato al modello.
5. Definiamo il nostro Modello di Richiesta
Ora abbiamo i frammenti di testo che contengono le informazioni che stiamo cercando, dobbiamo costruire una richiesta. All’interno della richiesta specifichiamo anche la modalità desiderata per il modello per rispondere alle domande. Quando definiamo la modalità stiamo specificando lo stile di comportamento desiderato in cui vogliamo che l’LLM generi risposte.
L’LLM può essere utilizzato per varie attività, ed ecco alcuni esempi della vasta gamma di possibilità:
- Sommario: “Sommario del seguente testo in 3 paragrafi per gli esecutivi: [TESTO]
- Estrazione di conoscenze: “In base a questo articolo: [TESTO], cosa dovrebbero considerare le persone prima di acquistare una casa?”
- Scrittura di contenuti (ad esempio mail, messaggi, codice): Scrivi una email a Jane chiedendo un aggiornamento sul documento per il nostro progetto. Usa un tono informale e amichevole.”
- Miglioramenti grammaticali e di stile: “Correggi questo testo in inglese standard e cambia il tono in uno più amichevole: [TESTO]
- Classificazione: “Classifica ogni messaggio come tipo di ticket di supporto: [TESTO]”
Per il nostro esempio, vogliamo implementare una soluzione che estrae dati da Wikipedia e interagisce con l’utente come un chatbot. Vogliamo che risponda alle domande come un esperto motivato e disponibile del servizio di assistenza.
Per guidare il LLM nella giusta direzione, sto aggiungendo le seguenti istruzioni al prompt:
“Sei un chatbot che ama aiutare le persone! Rispondi alla seguente domanda utilizzando solo il contesto fornito. Se non sei sicuro e la risposta non è esplicitamente nel contesto, di’ “Spiacente, non so come aiutarti”.
In questo modo, imposto una limitazione che consente solo a GPT di utilizzare le informazioni memorizzate nel nostro database. Questa restrizione ci consente di fornire le fonti su cui si basa il nostro chatbot per generare la risposta, il che è fondamentale per la tracciabilità e l’instaurazione di fiducia. Inoltre, ci aiuta ad affrontare il problema della generazione di informazioni non affidabili e ci consente di fornire risposte utilizzabili in un contesto aziendale per scopi decisionali.
Come contesto, sto usando semplicemente i primi 50 frammenti di testo con la maggiore somiglianza alla domanda. Una dimensione maggiore dei frammenti di testo sarebbe probabilmente stata migliore poiché di solito possiamo rispondere alla maggior parte delle domande con uno o due passaggi di testo. Ma lascio a voi la scelta della migliore dimensione per il vostro caso d’uso.
from langchain import PromptTemplatefrom langchain.llms import OpenAI# define the LLM you want to usellm = OpenAI(temperature=1)# calcuate the embeddings for the user's questionusers_question = "Chi è il Primo Ministro attuale del Regno Unito?"question_embedding = get_embedding(text=users_question, model="text-embedding-ada-002")# create a list to store the calculated cosine similaritycos_sim = []for index, row in df.iterrows(): A = row.ada_embedding B = question_embedding # calculate the cosine similiarity cosine = np.dot(A,B)/(norm(A)*norm(B)) cos_sim.append(cosine)df["cos_sim"] = cos_simdf.sort_values(by=["cos_sim"], ascending=False)# define the context for the prompt by joining the most relevant text chunkscontext = ""for index, row in df[0:50].iterrows(): context = context + " " + row.text_chunks# define the prompt templatetemplate = """Sei un chat bot che ama aiutare le persone! Dato il seguente contesto, rispondi alla domandautilizzando solo il contesto fornito. Se non sei sicuro e la risposta non èesplicitamente scritta nella documentazione, di' "Spiacente, non so come aiutarti".Sezioni del contesto:{context}Domanda:{users_question}Risposta:"""prompt = PromptTemplate(template=template, input_variables=["context", "users_question"])# fill the prompt templateprompt_text = prompt.format(context = context, question=users_question)llm(prompt_text)Utilizzando quel template specifico, sto incorporando sia il contesto che la domanda dell’utente nel nostro prompt. La risposta risultante è la seguente:

Sorprendentemente, anche questa semplice implementazione sembra aver prodotto alcuni risultati soddisfacenti. Procediamo chiedendo al sistema alcune altre domande riguardanti i primi ministri britannici. Lascerò tutto inalterato sostituendo solo la domanda dell’utente:
users_question = "Chi è stato il primo Primo Ministro del Regno Unito?"
Sembra funzionare in qualche modo. Tuttavia, il nostro obiettivo ora è trasformare questo processo lento in uno robusto ed efficiente. Per fare ciò, introduciamo una fase di indicizzazione in cui memorizziamo le nostre embedding e gli indici in un vector store. Ciò migliorerà le prestazioni complessive e diminuirà il tempo di risposta.
6. Creazione di un vector store (database di vettori)
Un vector store è un tipo di data store ottimizzato per archiviare e recuperare grandi quantità di dati che possono essere rappresentati come vettori. Questi tipi di database consentono di interrogare ed estrarre sottoinsiemi di dati in base a vari criteri, come le misure di somiglianza o altre operazioni matematiche.
La conversione dei nostri dati di testo in vettori è il primo passo, ma non è sufficiente per le nostre esigenze. Se dovessimo memorizzare i vettori in un data frame e cercare passo dopo passo le somiglianze tra le parole ogni volta che otteniamo una query, l’intero processo sarebbe incredibilmente lento.
Per cercare in modo efficiente i nostri embeddings, è necessario indicizzarli. L’indicizzazione è il secondo componente importante di un database vettoriale. L’indice fornisce un modo per mappare le query ai documenti o elementi più rilevanti nel vector store senza dover calcolare le somiglianze tra ogni query e ogni documento.
Negli ultimi anni sono stati rilasciati numerosi vector store. In particolare nel campo delle LLMs, l’attenzione intorno ai vector store è esplosa:

Adesso scegliamone uno e proviamolo per il nostro caso d’uso. Come abbiamo fatto nelle sezioni precedenti, stiamo nuovamente calcolando gli embeddings e memorizzandoli in un vector store. Per farlo, stiamo utilizzando moduli adatti di LangChain e Chroma come vector store.
- Raccogliere i dati che vogliamo utilizzare per rispondere alle domande degli utenti:
import requestsfrom bs4 import BeautifulSoupfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.text_splitter import CharacterTextSplitterfrom langchain.vectorstores import Chromafrom langchain.document_loaders import TextLoader# URL della pagina Wikipedia da cui effettuare lo scrapingurl = 'https://en.wikipedia.org/wiki/Prime_Minister_of_the_United_Kingdom'# Invio di una richiesta GET all'URLresponse = requests.get(url)# Parsing del contenuto HTML utilizzando BeautifulSoupsoup = BeautifulSoup(response.content, 'html.parser')# Troviamo tutto il testo sulla paginatext = soup.get_text()text = text.replace('\n', '')# Apriamo un nuovo file chiamato 'output.txt' in modalità scrittura e memorizziamo l'oggetto file in una variabilewith open('output.txt', 'w', encoding='utf-8') as file: # Scriviamo la stringa nel file file.write(text)2. Caricare i dati e definire come si vuole suddividere i dati in frammenti di testo
from langchain.text_splitter import RecursiveCharacterTextSplitter# carica il documentocon open('./output.txt', encoding='utf-8') as f: text = f.read()# definire lo splitter di testotext_splitter = RecursiveCharacterTextSplitter( chunk_size = 500, chunk_overlap = 100, length_function = len,)texts = text_splitter.create_documents([text])3. Definire il modello di embeddings che si vuole utilizzare per calcolare gli embeddings per i frammenti di testo e memorizzarli in un vector store (qui: Chroma)
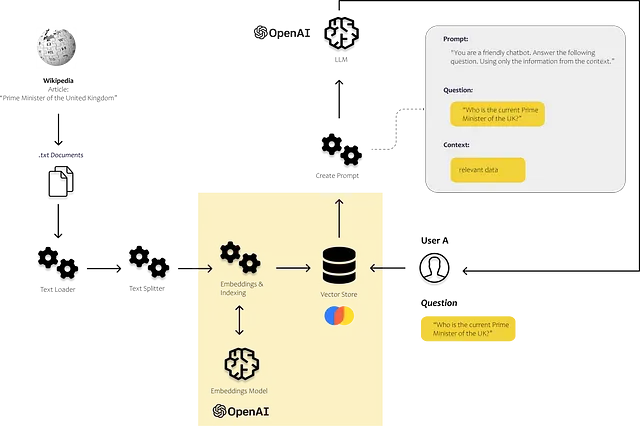
from langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Chroma# definiamo il modello di embeddingsembeddings = OpenAIEmbeddings()# utilizziamo i frammenti di testo e il modello di embeddings per riempire il nostro vector storedb = Chroma.from_documents(texts, embeddings)4. Calcolare gli embeddings per la domanda dell’utente, trovare frammenti di testo simili nel nostro vector store e usarli per costruire la nostra richiesta
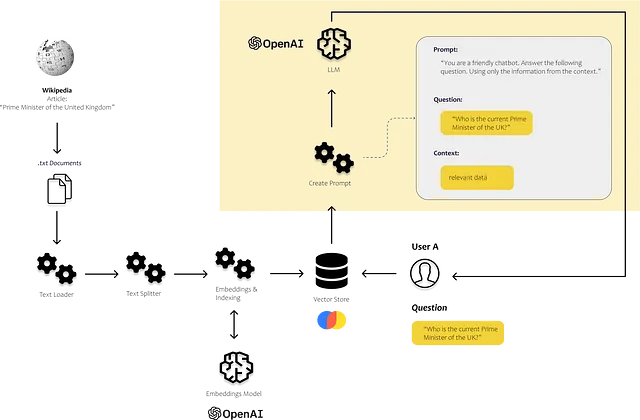
from langchain.llms import OpenAIfrom langchain import PromptTemplateusers_question = "Chi è il Primo Ministro del Regno Unito attualmente?"# utilizziamo il nostro vector store per trovare frammenti di testo similiresults = db.similarity_search( query=user_question, n_results=5)# definiamo il template della richiestatemplate = """Sei un chat bot che ama aiutare le persone! Dato il seguente contesto, rispondi alla domanda usando solo il contesto fornito. Se non sei sicuro e la risposta non è esplicitamente scritta nella documentazione, dì "Mi dispiace, non so come aiutare con questo."Contesto:{context}Domanda:{users_question}Risposta:"""prompt = PromptTemplate(template=template, input_variables=["context", "users_question"])# riempiamo il template della richiestaprompt_text = prompt.format(context = results, users_question = users_question)# chiediamo alla LLM definita precedentementellm(prompt_text)
Sommario
Per consentire al nostro LLM di analizzare e rispondere alle domande sui nostri dati, di solito non perfezioniamo il modello. Invece, durante il processo di perfezionamento, l’obiettivo è migliorare la capacità del modello di rispondere efficacemente a un compito specifico, piuttosto che insegnargli nuove informazioni.
Nel caso di Alpaca 7B, l’LLM (LLaMA) è stato perfezionato per comportarsi e interagire come un chatbot. L’attenzione era rivolta al perfezionamento delle risposte del modello, piuttosto che all’insegnamento di informazioni completamente nuove.
Quindi, per poter rispondere alle domande sui nostri dati, utilizziamo l’approccio di Iniezione di Contesto. La creazione di un’app LLM con Iniezione di Contesto è un processo relativamente semplice. La principale sfida consiste nell’organizzare e formattare i dati da memorizzare in un database vettoriale. Questo passaggio è cruciale per il recupero efficiente di informazioni contestualmente simili e per garantire risultati affidabili.
L’obiettivo dell’articolo era quello di dimostrare un approccio minimalista all’utilizzo di modelli di embedding, store vettoriali e LLM per elaborare le richieste degli utenti. Mostra come queste tecnologie possano lavorare insieme per fornire risposte pertinenti e accurate, anche a fatti in costante cambiamento.
Ti è piaciuta la storia?
- Iscriviti gratuitamente per ricevere una notifica quando pubblico una nuova storia.
- Vuoi leggere più di 3 storie gratuite al mese? – Diventa un membro Nisoo per 5$/mese. Puoi supportarmi utilizzando il mio link di riferimento quando ti registri. Riceverò una commissione senza costi aggiuntivi per te.
Non esitare a contattarmi su LinkedIn!
Riferimenti
AssemblyAI (Direttore). (2022, 5 gennaio). Una panoramica completa degli embedding di parole. https://www.youtube.com/watch?v=5MaWmXwxFNQ
Grootendorst, M. (2021, 7 dicembre). 9 misure di distanza in Data Science. Nisoo. https://towardsdatascience.com/9-distance-measures-in-data-science-918109d069fa
Langchain. (2023). Benvenuti in LangChain – 🦜🔗 LangChain 0.0.189. https://python.langchain.com/en/latest/index.html
Nelson, P. (2023). Tendenze di ricerca e analisi dei dati non strutturati | Accenture. Blog di ricerca e analisi dei contenuti di ricerca. https://www.accenture.com/us-en/blogs/search-and-content-analytics-blog/search-unstructured-data-analytics-trends
OpenAI. (2022). Introduzione agli embedding di testo e codice. https://openai.com/blog/introducing-text-and-code-embeddings
OpenAI (Direttore). (2023, 14 marzo). Cosa puoi fare con GPT-4? https://www.youtube.com/watch?v=oc6RV5c1yd0
Porsche AG. (2023, 17 maggio). ChatGPT & knowledge enterprise: “Come posso creare un chatbot per la mia unità aziendale?” #NextLevelGermanEngineering. https://medium.com/next-level-german-engineering/chatgpt-enterprise-knowledge-how-can-i-create-a-chatbot-for-my-business-unit-4380f7b3d4c0
Tazzyman, S. (2023). Modelli di reti neurali. NLP-Guidance. https://moj-analytical-services.github.io/NLP-guidance/NNmodels.html
Wang, W. (2023, 12 aprile). Un’analisi approfondita dei modelli basati su Transformer. Nisoo.