Una guida rapida sulla normalizzazione per il tuo modello NLP
Guida rapida normalizzazione modello NLP
Accelerare la convergenza del tuo modello e stabilizzare il processo di addestramento con la normalizzazione
Introduzione
Addestrare efficientemente modelli di deep learning è una sfida. Il problema diventa più difficile con la recente crescita delle dimensioni e della complessità dell’architettura dei modelli NLP. Per gestire miliardi di parametri, sono state proposte più ottimizzazioni per una convergenza più rapida e un addestramento stabile. Una delle tecniche più notevoli è la normalizzazione.
In questo articolo, impareremo alcune tecniche di normalizzazione, come funzionano e come possono essere utilizzate per modelli deep NLP.
Perché non BatchNorm?
BatchNorm [2] è una tecnica di normalizzazione precoce proposta per risolvere gli spostamenti covarianti interni.
Per spiegare in termini semplici, uno spostamento covariante interno si verifica quando c’è un cambiamento nella distribuzione dei dati di input del layer. Quando le reti neurali sono costrette a adattarsi a diverse distribuzioni di dati, l’aggiornamento del gradiente cambia drasticamente tra i batch. Pertanto, i modelli impiegano più tempo per adattarsi, imparare i pesi corretti e convergere. Il problema peggiora con l’aumentare delle dimensioni del modello.
- Come costruire grafici a cascata con Plotly Graph Objects
- Test di ipotesi e test A/B
- Richiedi i tuoi documenti con Langchain e Deep Lake!
Le soluzioni iniziali includono l’utilizzo di un piccolo learning rate (in modo che l’impatto dello spostamento delle distribuzioni dei dati sia minore) e una inizializzazione attenta dei pesi. BatchNorm ha risolto il problema in modo efficace normalizzando l’input sulla dimensione della caratteristica.
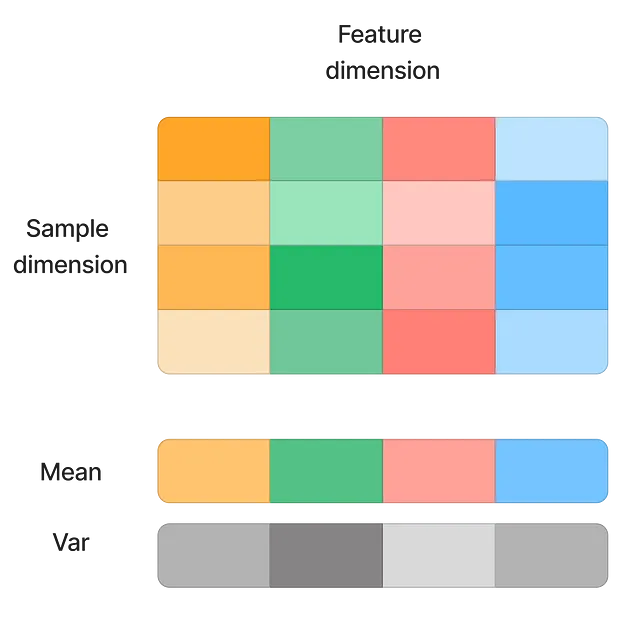
La tecnica aiuta a velocizzare significativamente la convergenza e consente un learning rate più elevato poiché il modello diventa meno sensibile agli outlier. Tuttavia, presenta ancora alcuni svantaggi:
- Dimensione del batch piccola: BatchNorm si basa sui dati del batch per calcolare la media e la deviazione standard della caratteristica. Quando la dimensione del batch è piccola, media e varianza non possono più rappresentare la popolazione. Pertanto, con BatchNorm non è possibile il learning online.
- Input sequenziale: In BatchNorm, la normalizzazione di ogni campione di input dipende da altri campioni dello stesso batch. Questo non funziona così bene con dati sequenziali. Ad esempio…






