GraphStorm accelerare l’apprendimento automatico sui grafi con una nuova soluzione per la risoluzione di problemi su grafi di scala aziendale.
GraphStorm accelera l'apprendimento automatico su grandi grafi con una nuova soluzione per problemi aziendali di scala grafica.
Siamo entusiasti di annunciare il rilascio open-source di GraphStorm 0.1, un framework di machine learning (ML) per grafi aziendali a basso codice per costruire, addestrare e distribuire soluzioni di graph ML su grafi complessi su scala aziendale in pochi giorni invece di mesi. Con GraphStorm, è possibile costruire soluzioni che tengono direttamente in considerazione la struttura delle relazioni o interazioni tra miliardi di entità, che sono intrinsecamente incorporate nella maggior parte dei dati del mondo reale, tra cui scenari di rilevamento frodi, raccomandazioni, rilevamento comunità e problemi di ricerca/recupero.
Fino ad ora, è stato notoriamente difficile costruire, addestrare e distribuire soluzioni di graph ML per grafi aziendali complessi che facilmente hanno miliardi di nodi, centinaia di miliardi di archi e dozzine di attributi, pensiamo solo ad un grafo che cattura i prodotti di Amazon.com, gli attributi del prodotto, i clienti e altro ancora. Con GraphStorm, rilasciamo gli strumenti che Amazon usa internamente per portare soluzioni di graph ML su larga scala in produzione. GraphStorm non richiede di essere un esperto di graph ML ed è disponibile sotto licenza Apache v2.0 su GitHub. Per saperne di più su GraphStorm, visita il repository GitHub.
In questo post, forniamo un’introduzione a GraphStorm, la sua architettura e un esempio di caso d’uso su come usarlo.
Presentazione di GraphStorm
Gli algoritmi di graph e il graph ML stanno emergendo come soluzioni all’avanguardia per molti importanti problemi aziendali come la previsione dei rischi di transazione, l’anticipazione delle preferenze dei clienti, il rilevamento di intrusioni, l’ottimizzazione delle catene di approvvigionamento, l’analisi delle reti sociali e la previsione del traffico. Ad esempio, Amazon GuardDuty, il servizio di rilevamento delle minacce nativo di AWS, utilizza un grafo con miliardi di archi per migliorare la copertura e l’accuratezza della sua intelligence sulle minacce. Ciò consente a GuardDuty di categorizzare i domini precedentemente non visti come altamente probabili di essere maligni o benigni in base alla loro associazione con domini maligni noti. Utilizzando le reti neurali di graph (GNN), GuardDuty è in grado di migliorare la sua capacità di avvisare i clienti.
- Sunak cerca il sostegno di Biden sull’IA dopo che il Regno Unito è stato escluso da importanti colloqui.
- 5 Idee di Business No Code con Bubble.io
- Crea QR Code Sorprendenti Utilizzando ControlNet AI
Tuttavia, lo sviluppo, il lancio e il funzionamento delle soluzioni di graph ML richiedono mesi e richiedono competenze di graph ML. Come primo passo, uno scienziato di graph ML deve costruire un modello di graph ML per un dato caso d’uso utilizzando un framework come Deep Graph Library (DGL). L’addestramento di tali modelli è sfidante a causa delle dimensioni e della complessità dei grafi nelle applicazioni aziendali, che raggiungono regolarmente miliardi di nodi, centinaia di miliardi di archi, diversi tipi di nodi e archi e centinaia di attributi di nodi e archi. I grafi aziendali possono richiedere terabyte di archiviazione in memoria, richiedendo agli scienziati di graph ML di costruire pipeline di addestramento complesse. Infine, dopo che un modello è stato addestrato, devono essere distribuiti per l’elaborazione, il che richiede pipeline di elaborazione che sono altrettanto difficili da costruire come le pipeline di addestramento.
GraphStorm 0.1 è un framework di graph ML aziendale a basso codice che consente ai professionisti di ML di scegliere facilmente i modelli di graph ML predefiniti che sono stati dimostrati essere efficaci, di eseguire l’addestramento distribuito su grafi con miliardi di nodi e di distribuire i modelli in produzione. GraphStorm offre una raccolta di modelli di graph ML integrati, come Relational Graph Convolutional Networks (RGCN), Relational Graph Attention Networks (RGAT) e Heterogeneous Graph Transformer (HGT) per applicazioni aziendali con grafi eterogenei, che consentono agli ingegneri di ML con poca esperienza di graph ML di provare diverse soluzioni di modelli per il loro compito e selezionare rapidamente quella giusta. Le pipeline di addestramento e di elaborazione distribuite end-to-end, che scalano su grafi aziendali su scala di miliardi, rendono facile addestrare, distribuire ed eseguire l’elaborazione. Se sei nuovo in GraphStorm o in graph ML in generale, beneficerai dei modelli e delle pipeline predefiniti. Se sei un esperto, hai tutte le opzioni per ottimizzare la pipeline di addestramento e l’architettura del modello per ottenere le migliori prestazioni. GraphStorm è costruito su DGL, un framework ampiamente popolare per lo sviluppo di modelli GNN, ed è disponibile come codice open-source sotto licenza Apache v2.0.
“GraphStorm è progettato per aiutare i clienti a sperimentare e operazionalizzare i metodi di graph ML per le applicazioni industriali per accelerare l’adozione di graph ML”, afferma George Karypis, Senior Principal Scientist di Amazon AI/ML research. “Dopo il suo rilascio all’interno di Amazon, GraphStorm ha ridotto fino a cinque volte lo sforzo per costruire soluzioni basate su graph ML”.
“GraphStorm consente al nostro team di addestrare l’embedding GNN in modo auto-supervisionato su un grafo con 288 milioni di nodi e 2 miliardi di archi”, afferma Haining Yu, Applied Scientist principale presso Amazon Measurement, Ad Tech e Data Science. “Gli embedding GNN pre-addestrati mostrano un miglioramento del 24% su un compito di previsione dell’attività degli acquirenti rispetto ad una baseline basata su BERT all’avanguardia; supera anche le prestazioni dei benchmark in altre applicazioni pubblicitarie”.
“Prima di GraphStorm, i clienti potevano solo scalare verticalmente per gestire grafi di 500 milioni di archi”, afferma Brad Bebee, GM per Amazon Neptune e Amazon Timestream. “GraphStorm consente ai clienti di scalare l’addestramento del modello GNN su grafi massicci di Amazon Neptune con decine di miliardi di archi”.
Architettura tecnica di GraphStorm
La figura seguente mostra l’architettura tecnica di GraphStorm.

GraphStorm è costruito su PyTorch e può funzionare su una singola GPU, più GPU e macchine con più GPU. È composto da tre livelli (contrassegnati con le caselle gialle nella figura precedente):
- Livello inferiore (Dist GraphEngine) – Il livello inferiore fornisce i componenti di base per consentire il machine learning di grafi distribuiti, inclusi grafi distribuiti, tensori distribuiti, embedding distribuiti e sampler distribuiti. GraphStorm fornisce implementazioni efficienti di questi componenti per scalare l’addestramento del machine learning di grafi a grafi di miliardi di nodi.
- Livello medio (GS training/inference pipeline) – Il livello medio fornisce trainer, evaluatori e predictor per semplificare l’addestramento e l’infertza del modello sia per i modelli incorporati che per i modelli personalizzati. Fondamentalmente, utilizzando l’API di questo livello, puoi concentrarti sullo sviluppo del modello senza preoccuparti di come scalare l’addestramento del modello.
- Livello superiore (GS general model zoo) – Il livello superiore è uno zoo di modelli con GNN e modelli non-GNN popolari per diversi tipi di grafi. Al momento della scrittura, fornisce RGCN, RGAT e HGT per grafi eterogenei e BERTGNN per grafi testuali. In futuro, aggiungeremo il supporto per modelli di grafi temporali come TGAT per grafi temporali e TransE e DistMult per grafi di conoscenza.
Come usare GraphStorm
Dopo aver installato GraphStorm, ti servono solo tre passaggi per costruire e addestrare i modelli GML per la tua applicazione.
In primo luogo, preprocessi i tuoi dati (potenzialmente includendo la tua personalizzazione delle caratteristiche) e li trasformi in un formato tabellare richiesto da GraphStorm. Per ogni tipo di nodo, definisci una tabella che elenca tutti i nodi di quel tipo e le loro caratteristiche, fornendo un ID univoco per ogni nodo. Per ogni tipo di arco, definisci allo stesso modo una tabella in cui ogni riga contiene gli ID del nodo sorgente e di destinazione per un arco di quel tipo (per ulteriori informazioni, consulta il tutorial Use Your Own Data). Inoltre, fornisci un file JSON che descrive la struttura del grafo complessivo.
In secondo luogo, tramite l’interfaccia della riga di comando (CLI), utilizzi il componente construct_graph incorporato di GraphStorm per l’elaborazione dei dati specifica di GraphStorm, che consente un efficiente addestramento e inferenza distribuiti.
In terzo luogo, configurare il modello e l’addestramento in un file YAML (esempio) e, nuovamente utilizzando la CLI, invocare uno dei cinque componenti incorporati (gs_node_classification, gs_node_regression, gs_edge_classification, gs_edge_regression, gs_link_prediction) come pipeline di addestramento per addestrare il modello. Questo passaggio porta all’addestramento degli artefatti del modello. Per fare inferenza, devi ripetere i primi due passaggi per trasformare i dati di inferenza in un grafo utilizzando lo stesso componente GraphStorm (construct_graph) come prima.
Infine, puoi invocare uno dei cinque componenti incorporati, lo stesso utilizzato per l’addestramento del modello, come pipeline di inferenza per generare embedding o risultati di previsione.
Il flusso complessivo è anche rappresentato nella figura seguente.
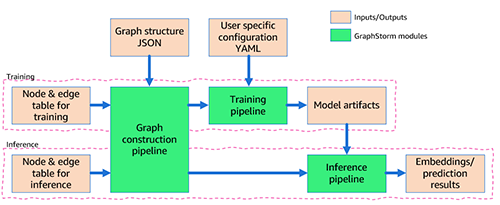
Nella sezione seguente, forniamo un caso d’uso di esempio.
Effettuare previsioni sui dati OAG grezzi
In questo post, dimostriamo quanto sia facile per GraphStorm abilitare l’addestramento e l’inferenza del machine learning sui grafi di un grande dataset grezzo. L’Open Academic Graph (OAG) contiene cinque entità (papers, autori, venues, affiliations e field of study). Il dataset grezzo è archiviato in file JSON con oltre 500 GB.
Il nostro compito è costruire un modello per prevedere il field of study di un paper. Per prevedere il field of study, puoi formularlo come un compito di classificazione multi-label, ma è difficile usare la codifica one-hot per archiviare le etichette perché ci sono centinaia di migliaia di campi. Pertanto, dovresti creare i nodi field of study e formulare questo problema come un compito di previsione del collegamento, prevedendo a quali nodi field of study un nodo paper dovrebbe connettersi.
Per modellare questo dataset con un metodo a grafo, il primo passo è elaborare il dataset ed estrarre entità e archi. È possibile estrarre cinque tipi di archi dai file JSON per definire un grafo, come mostrato nella figura seguente. È possibile utilizzare il notebook Jupyter nel codice di esempio di GraphStorm per elaborare il dataset e generare cinque tabelle di entità per ogni tipo di entità e cinque tabelle di archi per ogni tipo di arco. Il notebook Jupyter genera anche embedding BERT sulle entità con dati testuali, come gli articoli.

Dopo aver definito le entità e gli archi tra le entità, è possibile creare mag_bert.json, che definisce lo schema del grafo, e invocare la pipeline di costruzione del grafo integrata construct_graph in GraphStorm per costruire il grafo (vedi il codice seguente). Anche se la pipeline di costruzione del grafo di GraphStorm viene eseguita su una singola macchina, supporta il multi-processing per elaborare i nodi e le caratteristiche degli archi in parallelo (--num_processes) e può archiviare le caratteristiche dell’entità e dell’arco in memoria esterna (--ext-mem-workspace) per scalare a dataset di grandi dimensioni.
python3 -m graphstorm.gconstruct.construct_graph \
--num-processes 16 \
--output-dir /data/oagv2.1/mag_bert_constructed \
--graph-name mag --num-partitions 4 \
--skip-nonexist-edges \
--ext-mem-workspace /mnt/raid0/tmp_oag \
--ext-mem-feat-size 16 --conf-file mag_bert.jsonPer elaborare un grafo così grande, è necessaria un’istanza CPU di grande memoria per costruire il grafo. È possibile utilizzare un’istanza Amazon Elastic Compute Cloud (Amazon EC2) r6id.32xlarge (128 vCPU e 1 TB di RAM) o istanze r6a.48xlarge (192 vCPU e 1,5 TB di RAM) per costruire il grafo OAG.
Dopo aver costruito un grafo, è possibile utilizzare gs_link_prediction per addestrare un modello di previsione del link su quattro istanze g5.48xlarge. Quando si utilizzano i modelli integrati, è sufficiente invocare una sola riga di comando per avviare il lavoro di addestramento distribuito. Vedere il codice seguente:
python3 -m graphstorm.run.gs_link_prediction \
--num-trainers 8 \
--part-config /data/oagv2.1/mag_bert_constructed/mag.json \
--ip-config ip_list.txt \
--cf ml_lp.yaml \
--num-epochs 1 \
--save-model-path /data/mag_lp_modelDopo l’addestramento del modello, l’artefatto del modello viene salvato nella cartella /data/mag_lp_model.
Ora è possibile eseguire l’infrazione della previsione del link per generare gli embedding GNN e valutare le prestazioni del modello. GraphStorm fornisce molteplici metriche di valutazione integrate per valutare le prestazioni del modello. Per i problemi di previsione del link, ad esempio, GraphStorm produce automaticamente la metrica mean reciprocal rank (MRR). MRR è una metrica preziosa per valutare i modelli di previsione dei collegamenti del grafo perché valuta quanto alto sono classificati i collegamenti reali tra i collegamenti previsti. Ciò cattura la qualità delle previsioni, assicurando che il modello dia la giusta priorità alle connessioni vere, che è il nostro obiettivo qui.
È possibile eseguire l’infrazione con una sola riga di comando, come mostrato nel codice seguente. In questo caso, il modello raggiunge un MRR di 0,31 sul set di test del grafo costruito.
python3 -m graphstorm.run.gs_link_prediction \
--inference --num_trainers 8 \
--part-config /data/oagv2.1/mag_bert_constructed/mag.json \
--ip-config ip_list.txt \
--cf ml_lp.yaml \
--num-epochs 3 \
--save-embed-path /data/mag_lp_model/emb \
--restore-model-path /data/mag_lp_model/epoch-0/Si noti che la pipeline di infrazione genera gli embedding dal modello di previsione del link. Per risolvere il problema di trovare il campo di studio per qualsiasi articolo dato, basta eseguire una ricerca k-nearest neighbor sugli embedding.
Conclusioni
GraphStorm è un nuovo framework di ML a grafo che rende facile costruire, addestrare e distribuire modelli di ML a grafo su grafi industriali. Affronta alcune delle sfide chiave del ML a grafo, tra cui la scalabilità e la facilità d’uso. Fornisce componenti integrate per elaborare grafi di miliardi di elementi, dall’input dati grezzi all’addestramento del modello e all’infrazione del modello, e ha consentito a diverse squadre Amazon di addestrare modelli di ML a grafo all’avanguardia in varie applicazioni. Controlla il nostro repository GitHub per ulteriori informazioni.





