Grandi modelli linguistici Una nuova legge di Moore?
Grandi modelli linguistici Una nuova legge di Moore?
Qualche giorno fa, Microsoft e NVIDIA hanno presentato Megatron-Turing NLG 530B, un modello basato su Transformer acclamato come “il più grande e potente modello generativo di linguaggio al mondo”.
Questo è sicuramente un impressionante esempio di ingegneria di Machine Learning. Tuttavia, dovremmo essere entusiasti di questa tendenza ai mega-modelli? Personalmente, non lo sono. Ecco perché.

Questo è il tuo cervello con il Deep Learning
I ricercatori stimano che il cervello umano contenga in media 86 miliardi di neuroni e 100 trilioni di sinapsi. È lecito supporre che non tutti siano dedicati al linguaggio. Curiosamente, si prevede che GPT-4 abbia circa 100 trilioni di parametri… Per quanto questa analogia sia grossolana, non dovremmo chiederci se costruire modelli di linguaggio delle dimensioni del cervello umano sia il miglior approccio a lungo termine?
- Evento di lancio del corso
- Ottimizza XLSR-Wav2Vec2 per l’ASR a bassa risorsa con i Transformers di 🤗
- Accelerazione del raffinamento distribuito di PyTorch con tecnologie Intel
Certo, il nostro cervello è un dispositivo meraviglioso, prodotto da milioni di anni di evoluzione, mentre i modelli di Deep Learning hanno solo poche decadi di vita. Tuttavia, la nostra intuizione dovrebbe dirci che qualcosa non torna (gioco di parole inteso).
Deep Learning, spese esorbitanti?
Come ci si può aspettare, addestrare un modello con 530 miliardi di parametri su immensi dataset di testo richiede una buona infrastruttura. Infatti, Microsoft e NVIDIA hanno utilizzato centinaia di server DGX A100 multi-GPU. A $199.000 ciascuno, tenendo conto anche dell’attrezzatura di rete, dei costi di hosting, ecc., chiunque volesse replicare questo esperimento dovrebbe spendere quasi $100 milioni di dollari. Desidera le patatine con quello?
Seriamente, quali organizzazioni hanno casi d’uso aziendali che giustificherebbero una spesa di $100 milioni per un’infrastruttura di Deep Learning? O anche $10 milioni? Molto poche. Allora, per chi sono veramente questi modelli?
Quella sensazione di calore è il tuo cluster di GPU
Pur essendo un risultato di ingegneria brillante, addestrare modelli di Deep Learning su GPU è una tecnica di forza bruta. Secondo le specifiche, ogni server DGX può consumare fino a 6,5 kilowatt. Ovviamente, avrai bisogno di almeno tanta potenza di raffreddamento nel tuo datacenter (o nel tuo armadio server). A meno che tu non sia uno Stark e debba mantenere Winterfell calda in inverno, questo è un altro problema con cui dovrai confrontarti.
Inoltre, con l’aumentare della consapevolezza pubblica sui temi del clima e della responsabilità sociale, le organizzazioni devono tener conto della propria impronta di carbonio. Secondo questo studio del 2019 dell’Università del Massachusetts, “addestrare BERT su una GPU è approssimativamente equivalente a un volo transamericano”.
BERT-Large ha 340 milioni di parametri. Possiamo solo immaginare quale potrebbe essere l’impronta di carbonio di Megatron-Turing… Le persone che mi conoscono non mi definirebbero un ambientalista troppo sensibile. Tuttavia, alcuni numeri sono difficili da ignorare.
E allora?
Sono entusiasta di Megatron-Turing NLG 530B e di qualunque altra bestia arriverà? No. Penso che il miglioramento (relativamente piccolo) delle prestazioni sia giustificato dai costi aggiunti, dalla complessità e dall’impronta di carbonio? No. Penso che costruire e promuovere questi enormi modelli stia aiutando le organizzazioni a comprendere e adottare il Machine Learning? No.
Resto perplesso sul significato di tutto ciò. Scienza per la scienza stessa? Buon vecchio marketing? Supremazia tecnologica? Probabilmente un po’ di tutto. Li lascio fare, allora.
Invece, voglio concentrarmi su tecniche pragmatiche e concrete che tutti possono utilizzare per costruire soluzioni di Machine Learning di alta qualità.
Utilizza modelli preaddestrati
Nella stragrande maggioranza dei casi, non avrai bisogno di un’architettura di modello personalizzato. Forse ne vorrai uno personalizzato (che è una cosa diversa), ma ci sono molti rischi. Solo per esperti!
Un buon punto di partenza è cercare modelli che siano stati preaddestrati per il compito che stai cercando di risolvere (ad esempio, riassumere testo in inglese).
Successivamente, dovresti provare rapidamente alcuni modelli per fare previsioni sui tuoi dati. Se le metriche ti dicono che uno funziona abbastanza bene, sei a posto! Se hai bisogno di una maggiore precisione, dovresti considerare la messa a punto del modello (ne parleremo tra un attimo).
Utilizza modelli più piccoli
Nell’valutare i modelli, dovresti scegliere il più piccolo che possa garantire la precisione di cui hai bisogno. Sarà più veloce nelle previsioni e richiederà meno risorse hardware per addestramento e inferenza. La parsimonia paga sempre.
Non è neanche qualcosa di nuovo. Gli esperti di Computer Vision ricorderanno quando è uscito SqueezeNet nel 2017, ottenendo una riduzione del 50 volte delle dimensioni del modello rispetto ad AlexNet, mantenendo o superando la sua accuratezza. Quanto era intelligente!
Anche nella comunità del Natural Language Processing sono in corso sforzi di ridimensionamento, utilizzando tecniche di apprendimento di trasferimento come la distillazione della conoscenza. DistilBERT è forse il suo risultato più conosciuto. Rispetto al modello originale di BERT, mantiene il 97% della comprensione del linguaggio pur essendo più piccolo del 40% e più veloce del 60%. Puoi provarlo qui. Lo stesso approccio è stato applicato ad altri modelli, come il BART di Facebook, e puoi provare DistilBART qui.
I modelli recenti del progetto Big Science sono anche molto impressionanti. Come visibile in questo grafico incluso nel paper di ricerca, il loro modello T0 supera GPT-3 in molti compiti pur essendo 16 volte più piccolo.

Puoi provare T0 qui. Questo è il tipo di ricerca di cui abbiamo bisogno di più!
Modelli di Fine-Tuning
Se hai bisogno di specializzare un modello, ci dovrebbero essere pochissime ragioni per addestrarlo da zero. Invece, dovresti fare il fine-tuning, ovvero addestrarlo solo per qualche epoca sui tuoi dati. Se hai pochi dati, forse uno di questi dataset può aiutarti a iniziare.
Avete indovinato, è un altro modo per fare transfer learning, e ti aiuterà a risparmiare su tutto!
- Meno dati da raccogliere, archiviare, pulire e annotare,
- Esperimenti e iterazioni più veloci,
- Meno risorse richieste in produzione.
In altre parole: risparmia tempo, risparmia denaro, risparmia risorse hardware, salva il mondo!
Se hai bisogno di un tutorial, il corso di Hugging Face ti farà partire in poco tempo.
Utilizza un’infrastruttura basata sul cloud
Ti piaccia o meno, le aziende di cloud sanno come costruire infrastrutture efficienti. Gli studi sulla sostenibilità mostrano che l’infrastruttura basata sul cloud è più efficiente dal punto di vista energetico e delle emissioni di carbonio rispetto all’alternativa: vedi AWS, Azure e Google. Earth.org afferma che sebbene l’infrastruttura cloud non sia perfetta, “[è] più efficiente dal punto di vista energetico rispetto all’alternativa e facilita servizi benefici per l’ambiente e la crescita economica”.
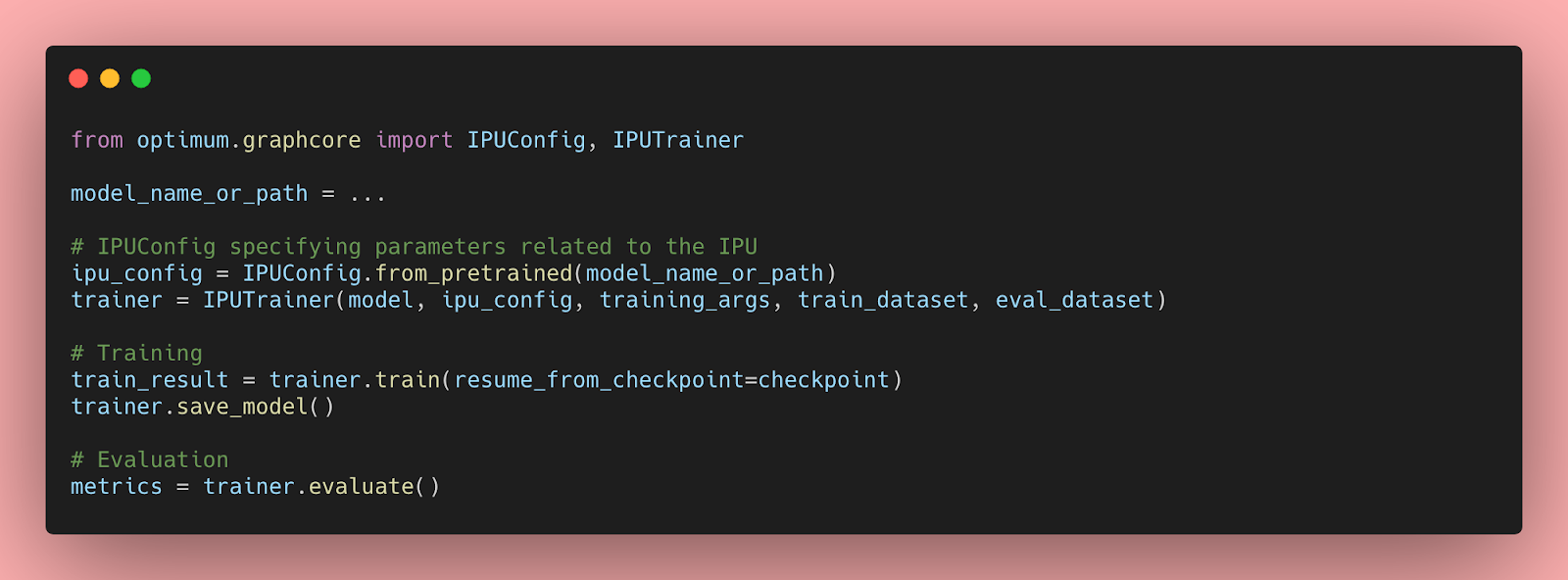
Il cloud ha sicuramente molti vantaggi in termini di facilità d’uso, flessibilità e pagamento in base all’utilizzo. È anche un po’ più ecosostenibile di quanto probabilmente pensassi. Se ti mancano le GPU, perché non provare a fare il fine-tuning dei tuoi modelli di Hugging Face su Amazon SageMaker, il servizio gestito da AWS per il Machine Learning? Abbiamo molti esempi per te.
Ottimizza i tuoi modelli
Dai compilatori alle macchine virtuali, gli ingegneri del software da tempo utilizzano strumenti che ottimizzano automaticamente il loro codice per l’hardware su cui viene eseguito.
Tuttavia, la comunità di Machine Learning sta ancora lottando con questo argomento, e con buona ragione. Ottimizzare i modelli per dimensione e velocità è un compito estremamente complesso, che coinvolge tecniche come:
- Hardware specializzato che accelera l’addestramento (Graphcore, Habana) e l’inferenza (Google TPU, AWS Inferentia).
- Pruning: rimuovere i parametri del modello che hanno poco o nessun impatto sull’output previsto.
- Fusion: unire gli strati del modello (ad esempio, convoluzione e attivazione).
- Quantizzazione: memorizzare i parametri del modello in valori più piccoli (ad esempio, 8 bit invece di 32 bit).
Fortunatamente, stanno iniziando ad apparire strumenti automatizzati, come la libreria open source Optimum e Infinity, una soluzione containerizzata che offre accuratezza di Transformers con una latenza di 1 millisecondo.
Conclusioni
Le dimensioni dei modelli di linguaggio sono aumentate di 10 volte ogni anno negli ultimi anni. Questo sta iniziando a somigliare a un’altra legge di Moore.
Ci siamo già stati, e dovremmo sapere che questa strada porta a rendimenti decrescenti, costi più elevati, maggiore complessità e nuovi rischi. Le grandezze esponenziali tendono a non finire bene. Ricordate Meltdown e Spectre? Vogliamo scoprire come si presenta la situazione per l’AI?
Invece di inseguire modelli con un trilione di parametri (fate le vostre scommesse), non sarebbe meglio se costruissimo soluzioni pratiche ed efficienti che tutti gli sviluppatori possono utilizzare per risolvere problemi reali?
Se sei interessato a come Hugging Face può aiutare la tua organizzazione a costruire e implementare soluzioni di Machine Learning di produzione, contattaci all’indirizzo [email protected] (niente reclutatori, niente vendite, per favore).