GPT4All è la ChatGPT locale per i tuoi documenti ed è gratuita!
GPT4All is the local ChatGPT for your documents and it's free!
Come installare GPT4All sul tuo laptop e chiedere all’AI informazioni sulla tua conoscenza di dominio (i tuoi documenti)… e funziona solo sulla CPU!
In questo articolo impareremo come distribuire e utilizzare il modello GPT4All sul tuo computer solo con CPU (sto utilizzando un MacBook Pro senza GPU!)

In questo articolo installeremo su un computer locale GPT4All (un potente LLM) e scopriremo come interagire con i nostri documenti con Python. Una raccolta di PDF o articoli online sarà la base di conoscenza per le nostre domande/risposte.
- Ultima possibilità! I workshop certificati di Intelligenza Artificiale iniziano tra 24 ore! Non perdere l’occasione!
- GraphStorm accelerare l’apprendimento automatico sui grafi con una nuova soluzione per la risoluzione di problemi su grafi di scala aziendale.
- Sunak cerca il sostegno di Biden sull’IA dopo che il Regno Unito è stato escluso da importanti colloqui.
Cos’è GPT4All
Dal sito web ufficiale di GPT4All viene descritto come un chatbot privo di costi, in esecuzione locale e rispettoso della privacy. Nessuna GPU o connessione internet richiesta.
GTP4All è un ecosistema per addestrare e distribuire modelli di linguaggio di grandi dimensioni potenti e personalizzati che vengono eseguiti localmente su CPU di grado consumer.
Il nostro modello GPT4All è un file di 4 GB che è possibile scaricare e collegare al software open source di GPT4All. Nomic AI facilita ecosistemi software sicuri e di alta qualità, guidando l’effort per consentire a individui e organizzazioni di addestrare ed implementare facilmente i propri grandi modelli di linguaggio in locale.
Come funzionerà?
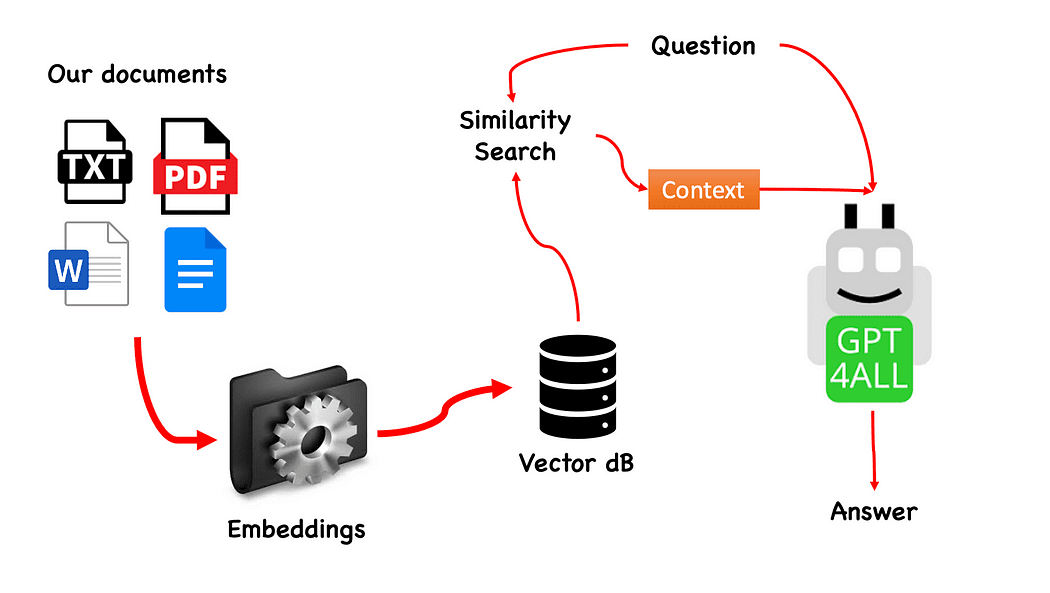
Il processo è davvero semplice (quando lo conosci) e può essere ripetuto anche con altri modelli. I passaggi sono i seguenti:
- caricare il modello GPT4All
- usare Langchain per recuperare i nostri documenti e caricarli
- dividere i documenti in piccoli chunk digeribili da Embeddings
- usare FAISS per creare il nostro database di vettori con gli embeddings
- eseguire una ricerca di similarità (ricerca semantica) sul nostro database di vettori in base alla domanda che vogliamo passare a GPT4All: questo verrà utilizzato come contesto per la nostra domanda
- inviare la domanda e il contesto a GPT4All con Langchain e attendere la risposta.
Quindi ci serve Embeddings. Un embedding è una rappresentazione numerica di una informazione, ad esempio testo, documenti, immagini, audio, ecc. La rappresentazione cattura il significato semantico di ciò che viene incorporato, ed è esattamente ciò di cui abbiamo bisogno. Per questo progetto non possiamo fare affidamento su modelli GPU pesanti: quindi scaricheremo il modello nativo di Alpaca e useremo da Langchain il LlamaCppEmbeddings. Non preoccuparti! Tutto è spiegato passo dopo passo
Iniziamo a codificare
Crea un ambiente virtuale
Crea una nuova cartella per il tuo nuovo progetto Python, ad esempio GPT4ALL_Fabio (metti il tuo nome…):
mkdir GPT4ALL_Fabio
cd GPT4ALL_FabioSuccessivamente, crea un nuovo ambiente virtuale Python. Se hai installato più di una versione di Python, specifica la versione desiderata: in questo caso utilizzerò la mia installazione principale, associata a Python 3.10.
python3 -m venv .venvIl comando python3 -m venv .venv crea un nuovo ambiente virtuale chiamato .venv (il punto creerà una directory nascosta chiamata venv).
Un ambiente virtuale fornisce un’installazione Python isolata, che consente di installare pacchetti e dipendenze solo per un progetto specifico senza influire sull’installazione di Python a livello di sistema o su altri progetti. Questo isolamento aiuta a mantenere la coerenza e a prevenire potenziali conflitti tra diversi requisiti del progetto.
Una volta creato l’ambiente virtuale, puoi attivarlo usando il seguente comando:
source .venv/bin/activate
Le librerie da installare
Per il progetto che stiamo costruendo non abbiamo bisogno di troppe librerie. Abbiamo solo bisogno di:
- bindings Python per GPT4All
- Langchain per interagire con i nostri documenti
LangChain è un framework per lo sviluppo di applicazioni basate su modelli linguistici. Consente non solo di chiamare un modello linguistico tramite un’API, ma anche di connettere un modello linguistico ad altre fonti di dati e consentire a un modello linguistico di interagire con il suo ambiente.
pip install pygpt4all==1.0.1
pip install pyllamacpp==1.0.6
pip install langchain==0.0.149
pip install unstructured==0.6.5
pip install pdf2image==1.16.3
pip install pytesseract==0.3.10
pip install pypdf==3.8.1
pip install faiss-cpu==1.7.4Per LangChain si vede che abbiamo specificato anche la versione. Questa libreria sta ricevendo molti aggiornamenti di recente, quindi per essere sicuri che il nostro setup funzioni anche domani, è meglio specificare una versione che sappiamo funzionare bene. Unstructured è una dipendenza obbligatoria per il caricatore pdf e anche per pytesseract e pdf2image.
NOTA: nel repository GitHub c’è un file requirements.txt (suggerito da jl adcr) con tutte le versioni associate a questo progetto. Puoi fare l’installazione in un colpo solo, dopo averlo scaricato nella directory principale del progetto con il seguente comando:
pip install -r requirements.txtAlla fine dell’articolo ho creato una sezione per la risoluzione dei problemi. Il repo GitHub ha anche un README aggiornato con tutte queste informazioni.
Tieni presente che alcune librerie hanno versioni disponibili a seconda della versione di Python che stai eseguendo nel tuo ambiente virtuale.
Scarica i modelli sul tuo PC
Questo è un passaggio davvero importante.
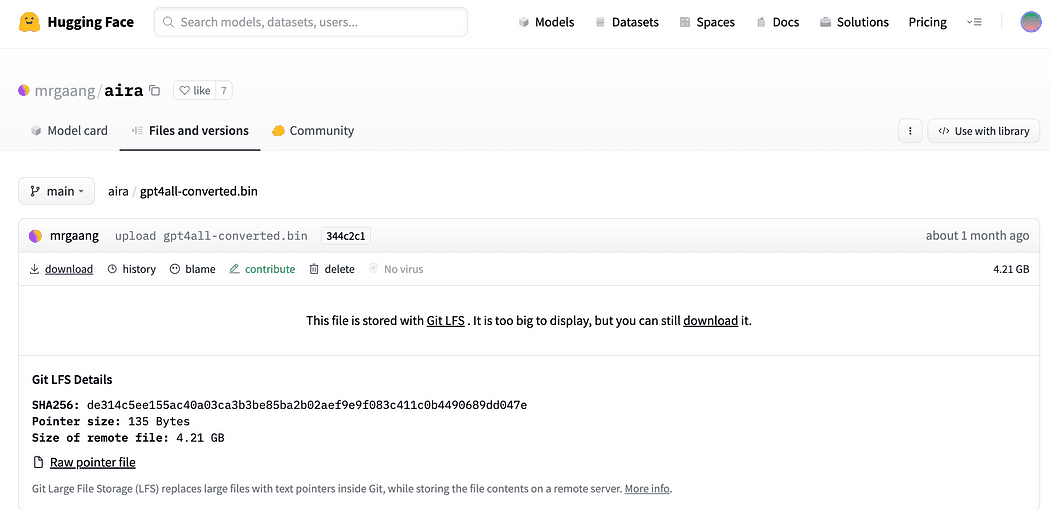
Per il progetto abbiamo sicuramente bisogno di GPT4All. Il processo descritto su Nomic AI è davvero complicato e richiede hardware che non tutti abbiamo (come me). Quindi ecco il link al modello già convertito e pronto per essere usato. Fai semplicemente clic su download.
Come descritto brevemente nell’introduzione, abbiamo bisogno anche del modello per gli embedding, un modello che possiamo eseguire sulla nostra CPU senza schiacciarla. Clicca sul link qui per scaricare l’alpaca-native-7B-ggml già convertito a 4 bit e pronto per essere usato come nostro modello per gli embedding.
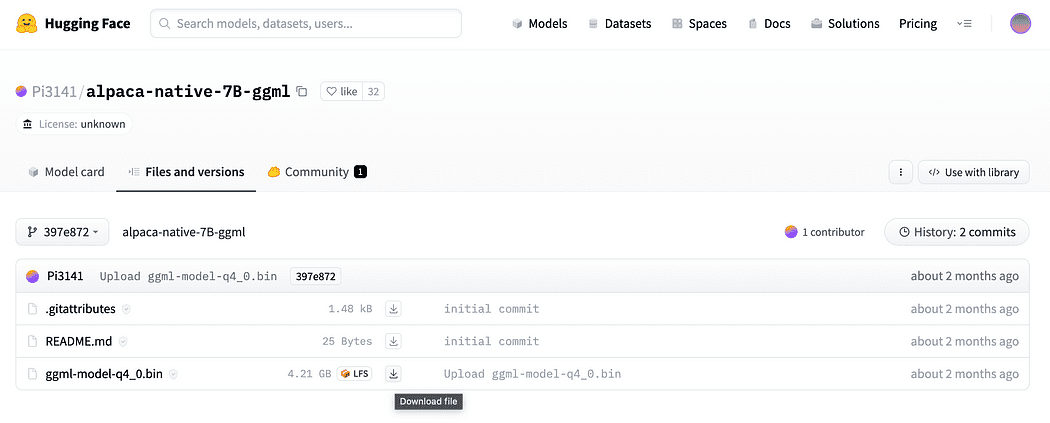
Perché abbiamo bisogno degli embedding? Se ti ricordi dal diagramma di flusso, il primo passo richiesto, dopo che abbiamo raccolto i documenti per la nostra base di conoscenza, è quello di incorporarli. Gli embedding LLamaCPP di questo modello Alpaca sono perfetti per il lavoro e questo modello è abbastanza piccolo (4 Gb). Comunque puoi anche usare il modello Alpaca per le tue domande e risposte!
Aggiornamento 2023.05.25: Molti utenti Windows stanno riscontrando problemi nell’utilizzare gli embedding llamaCPP. Questo accade principalmente perché durante l’installazione del pacchetto Python llama-cpp-python con:
pip install llama-cpp-pythonil pacchetto pip compila dalla sorgente la libreria. Di solito Windows non ha CMake o il compilatore C installati di default sulla macchina. Ma non preoccuparti, c’è una soluzione
L’installazione di llama-cpp-python, richiesta da LangChain con gli embedding llama, su Windows CMake C complier non è installato di default, quindi non puoi compilare dalla sorgente.
Sui Mac con Xtools e su Linux, di solito il compilatore C è già disponibile nel sistema operativo.
Per evitare il problema DEVI utilizzare la wheel precompilata.
Vai qui https://github.com/abetlen/llama-cpp-python/releases
e cerca la wheel compilata per la tua architettura e versione di Python — DEVI prendere la versione Weels 0.1.49 perché le versioni superiori non sono compatibili.
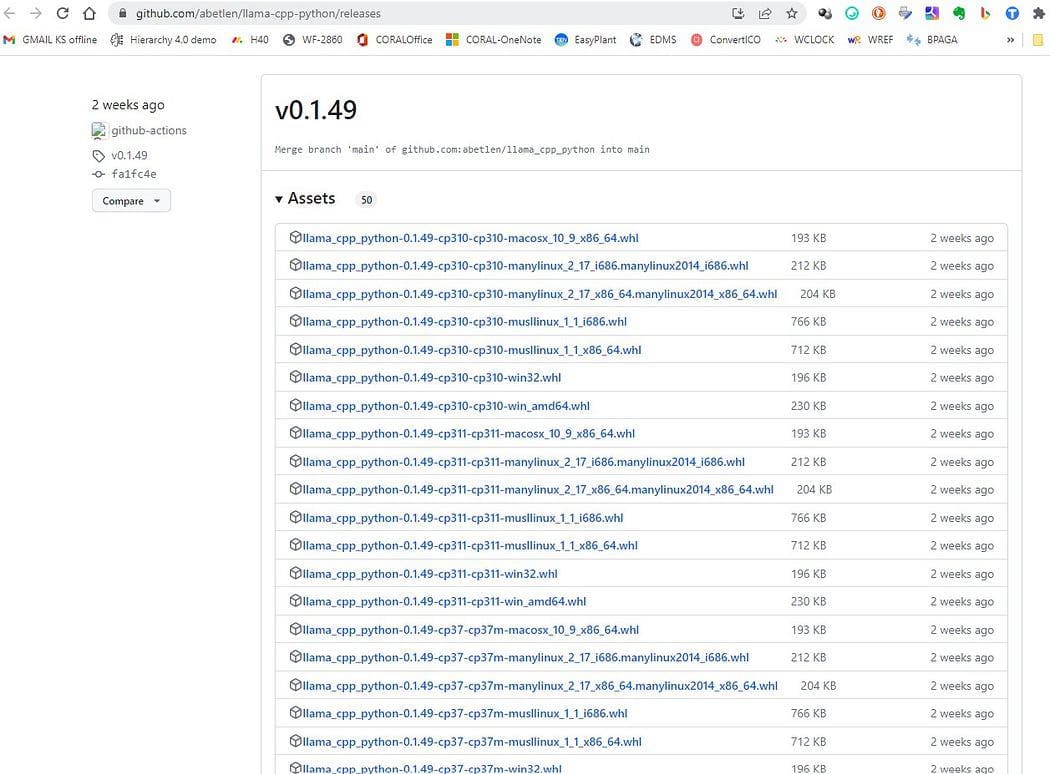
Nel mio caso ho Windows 10, 64 bit, python 3.10
quindi il mio file è llama_cpp_python-0.1.49-cp310-cp310-win_amd64.whl
Questo problema è monitorato nel repository GitHub
Dopo il download, è necessario mettere i due modelli nella directory dei modelli, come mostrato di seguito.

Interazione di base con GPT4All
Poiché vogliamo avere il controllo della nostra interazione con il modello GPT, dobbiamo creare un file python (chiamiamolo pygpt4all_test.py), importare le dipendenze e dare le istruzioni al modello. Vedrai che è abbastanza facile.
from pygpt4all.models.gpt4all import GPT4AllQuesto è il binding python per il nostro modello. Ora possiamo chiamarlo e iniziare a fare domande. Proviamone una creativa.
Creiamo una funzione che legge il callback dal modello e chiediamo a GPT4All di completare la nostra frase.
def new_text_callback(testo):
print(testo, end="")
modello = GPT4All('./models/gpt4all-converted.bin')
modello.generate("C'era una volta, ", n_predict=55, new_text_callback=new_text_callback)La prima istruzione sta dicendo al nostro programma dove trovare il modello (ricorda quello che abbiamo fatto nella sezione precedente)
La seconda istruzione chiede al modello di generare una risposta e completare il nostro prompt “C’era una volta,”.
Per eseguirlo, assicurati che l’ambiente virtuale sia ancora attivato e semplicemente esegui:
python3 pygpt4all_test.pyDovresti vedere un testo di caricamento del modello e il completamento della frase. A seconda delle risorse hardware potrebbe richiedere un po’ di tempo.
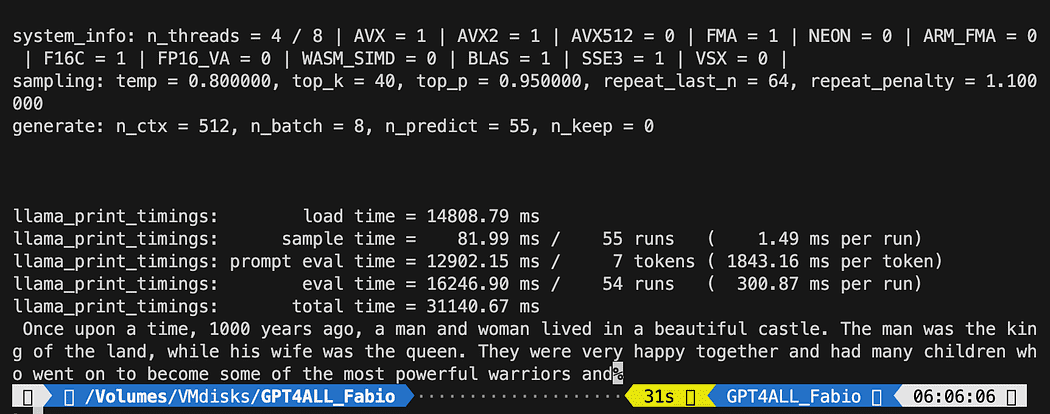
Il risultato potrebbe essere diverso dal tuo… Ma per noi l’importante è che funzioni e possiamo procedere con LangChain per creare cose avanzate.
NOTA (aggiornata il 23 maggio 2023): se si verifica un errore relativo a pygpt4all, controllare la sezione risoluzione dei problemi su questo argomento con la soluzione fornita da Rajneesh Aggarwal o da Oscar Jeong.
Modello LangChain su GPT4All
Il framework LangChain è una libreria davvero sorprendente. Fornisce componenti per lavorare con modelli di linguaggio in modo facile da usare, e fornisce anche catene. Le catene possono essere pensate come l’assemblaggio di questi componenti in modi particolari per ottenere al meglio un determinato caso d’uso. Questi sono destinati ad essere un’interfaccia di livello superiore attraverso la quale le persone possono facilmente iniziare con un caso d’uso specifico. Queste catene sono anche progettate per essere personalizzabili.
Nel nostro prossimo test python useremo un Prompt Template. I modelli di linguaggio prendono il testo in input – quel testo è comunemente indicato come prompt. Tipicamente questo non è semplicemente una stringa codificata ma piuttosto una combinazione di un modello, alcuni esempi e l’input dell’utente. LangChain fornisce diverse classi e funzioni per rendere facile la costruzione e il lavoro con i prompt. Vediamo come possiamo farlo anche noi.
Crea un nuovo file python e chiamalo my_langchain.py
# Import di langchain Prompt Template and Chain
from langchain import PromptTemplate, LLMChain
# Import llm to be able to interact with GPT4All directly from langchain
from langchain.llms import GPT4All
# Callbacks manager is required for the response handling
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
percorso_locale = './models/gpt4all-converted.bin'
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])Abbiamo importato dal modulo LangChain il Prompt Template e Chain e la classe llm GPT4All per interagire direttamente con il nostro modello GPT.
Poi, dopo aver impostato il percorso llm (come abbiamo fatto prima), istanziamo il gestore di callback in modo da poter catturare le risposte alla nostra query.
Creare un template è davvero facile: seguendo il tutorial sulla documentazione possiamo usare qualcosa del genere…
template = """Domanda: {question}
Risposta: Pensiamo passo dopo passo.
"""
prompt = PromptTemplate(template=template, input_variables=["question"])La variabile template è una stringa multilinea che contiene la struttura della nostra interazione con il modello: tra parentesi graffe inseriamo le variabili esterne al template, nel nostro scenario è la nostra domanda.
Poiché si tratta di una variabile, è possibile decidere se è una domanda codificata duramente o una domanda di input dell’utente: ecco i due esempi.
# Domanda codificata duramente
question = "Qual è il pilota di Formula 1 che ha vinto il campionato nell'anno in cui è nato Leonardo di Caprio?"
# Domanda di input dell'utente...
question = input("Inserisci la tua domanda: ")Per la nostra prova commenteremo quella di input dell’utente. Ora dobbiamo solo collegare insieme il nostro modello, la domanda e il modello linguistico.
template = """Domanda: {question}
Risposta: Pensiamo passo dopo passo.
"""
prompt = PromptTemplate(template=template, input_variables=["question"])
# inizializza l'istanza di GPT4All
llm = GPT4All(model=local_path, callback_manager=callback_manager, verbose=True)
# collega il modello linguistico al nostro modello di prompt
llm_chain = LLMChain(prompt=prompt, llm=llm)
# Domanda codificata duramente
question = "Qual è il pilota di Formula 1 che ha vinto il campionato nell'anno in cui è nato Leonardo di Caprio?"
# Domanda di input dell'utente...
# question = input("Inserisci la tua domanda: ")
#Esegui la query e ottieni i risultati
llm_chain.run(question)Ricorda di verificare che il tuo ambiente virtuale sia ancora attivato ed esegui il comando:
python3 my_langchain.pyPotresti ottenere risultati diversi dai miei. Ciò che è sorprendente è che puoi vedere l’intero ragionamento seguito da GPT4All nel tentativo di ottenere una risposta per te. Regolando la domanda potresti ottenere risultati migliori.
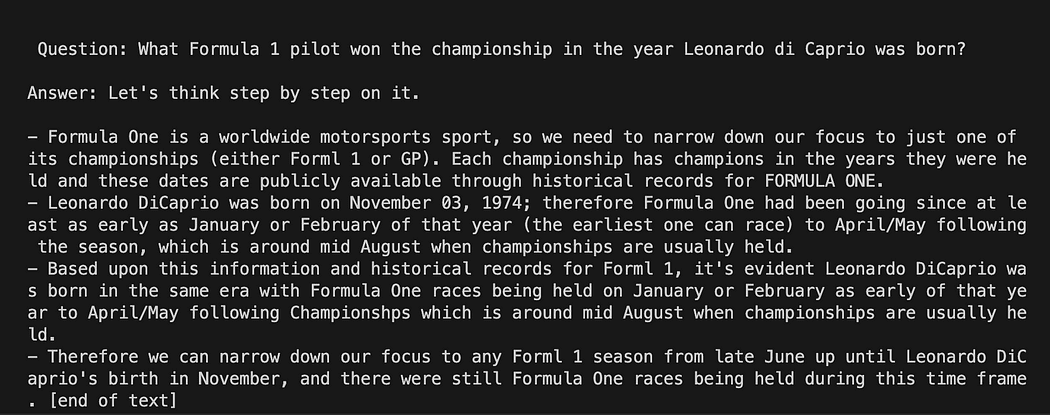
Langchain con Prompt Template su GPT4All
Rispondere alle domande sui tuoi documenti utilizzando LangChain e GPT4All
Qui inizia la parte incredibile, perché stiamo per parlare con i nostri documenti utilizzando GPT4All come chatbot che risponde alle nostre domande.
La sequenza di passaggi, riferendosi al Workflow della QnA con GPT4All, consiste nel caricare i nostri file pdf, suddividerli in frammenti. Dopo di che avremo bisogno di un Vector Store per i nostri embedding. Dobbiamo alimentare i nostri documenti suddivisi in un vector store per il recupero delle informazioni e quindi li incorporeremo insieme alla ricerca di similarità su questo database come contesto per la nostra query LLM.
A tale scopo useremo FAISS direttamente dalla libreria Langchain. FAISS è una libreria open-source di Facebook AI Research, progettata per trovare rapidamente elementi simili in grandi collezioni di dati ad alta dimensionalità. Offre metodi di indicizzazione e ricerca per rendere più facile e veloce individuare gli elementi più simili all’interno di un dataset. È particolarmente conveniente per noi perché semplifica il recupero delle informazioni e ci consente di salvare localmente il database creato: ciò significa che dopo la prima creazione verrà caricato molto rapidamente per qualsiasi utilizzo successivo.
Creazione del database di indice vettoriale
Crea un nuovo file e chiamalo my_knowledge_qna.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# funzione per caricare solo file TXT
from langchain.document_loaders import TextLoader
# splitter di testo per creare frammenti
from langchain.text_splitter import RecursiveCharacterTextSplitter
# per poter caricare i file pdf
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader
# Vector Store Index per creare il nostro database sulla conoscenza
from langchain.indexes import VectorstoreIndexCreator
# Embeddings LLamaCpp dal modello Alpaca
from langchain.embeddings import LlamaCppEmbeddings
# libreria FAISS per la ricerca di similarità
from langchain.vectorstores.faiss import FAISS
import os # per l'interazione con i file
import datetimeLe prime librerie sono le stesse utilizzate in precedenza: inoltre stiamo utilizzando Langchain per la creazione dell’indice di vector store, LlamaCppEmbeddings per interagire con il nostro modello Alpaca (quantizzato a 4 bit e compilato con la libreria cpp) e il caricatore PDF.
Carichiamo anche i nostri LLM con i loro rispettivi percorsi: uno per gli embedding e uno per la generazione di testo.
# assegna il percorso per i 2 modelli GPT4All e Alpaca per gli embeddings
gpt4all_path = './models/gpt4all-converted.bin'
llama_path = './models/ggml-model-q4_0.bin'
# Manager per la gestione delle chiamate con il modello
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])
# crea l'oggetto di embedding
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# crea l'oggetto llm di GPT4All
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True)Per il test vediamo se siamo riusciti a leggere tutti i file pdf: il primo passo è dichiarare 3 funzioni da utilizzare su ogni singolo documento. La prima funzione è quella di dividere il testo estratto in chunk, la seconda è quella di creare l’indice vettoriale con i metadati (come i numeri di pagina, ecc…) e l’ultima è per testare la ricerca di similarità (lo spiegherò meglio più avanti).
# Dividi il testo
def split_chunks(sources):
chunks = []
splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32)
for chunk in splitter.split_documents(sources):
chunks.append(chunk)
return chunks
def create_index(chunks):
texts = [doc.page_content for doc in chunks]
metadatas = [doc.metadata for doc in chunks]
search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas)
return search_index
def similarity_search(query, index):
# k è il numero di similarità cercate che corrispondono alla query
# il valore predefinito è 4
matched_docs = index.similarity_search(query, k=3)
sources = []
for doc in matched_docs:
sources.append(
{
"page_content": doc.page_content,
"metadata": doc.metadata,
}
)
return matched_docs, sourcesOra possiamo testare la generazione dell’indice per i documenti nella cartella docs: dobbiamo mettere lì tutti i nostri pdf. Langchain ha anche un metodo per caricare l’intera cartella, indipendentemente dal tipo di file: poiché è complicato il post process, lo coprirò nell’articolo successivo sui modelli LaMini.

la mia cartella docs contiene 4 file pdf
Applicheremo le nostre funzioni al primo documento nella lista
# ottieni la lista dei file pdf dalla cartella docs in formato list
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# crea un loader per i PDF dal percorso
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
# carica i documenti con Langchain
docs = loader.load()
# Dividi in chunk
chunks = split_chunks(docs)
# crea l'indice vettoriale del db
db0 = create_index(chunks)Nelle prime righe usiamo la libreria os per ottenere la lista dei file pdf all’interno della cartella docs. Quindi carichiamo il primo documento ( doc_list[0] ) dalla cartella docs con Langchain, lo dividiamo in chunk e quindi creiamo il database vettoriale con gli embeddings LLama.
Come avete visto stiamo usando il metodo pyPDF . Questo è un po’ più lungo da usare, poiché è necessario caricare i file uno per uno, ma caricando i PDF utilizzando pypdf in un array di documenti ci consente di avere un array in cui ogni documento contiene il contenuto della pagina e i metadati con il numero di pagina. Questo è molto comodo quando si vuole conoscere le fonti del contesto che daremo a GPT4All con la nostra query. Qui l’esempio dalla readthedocs:
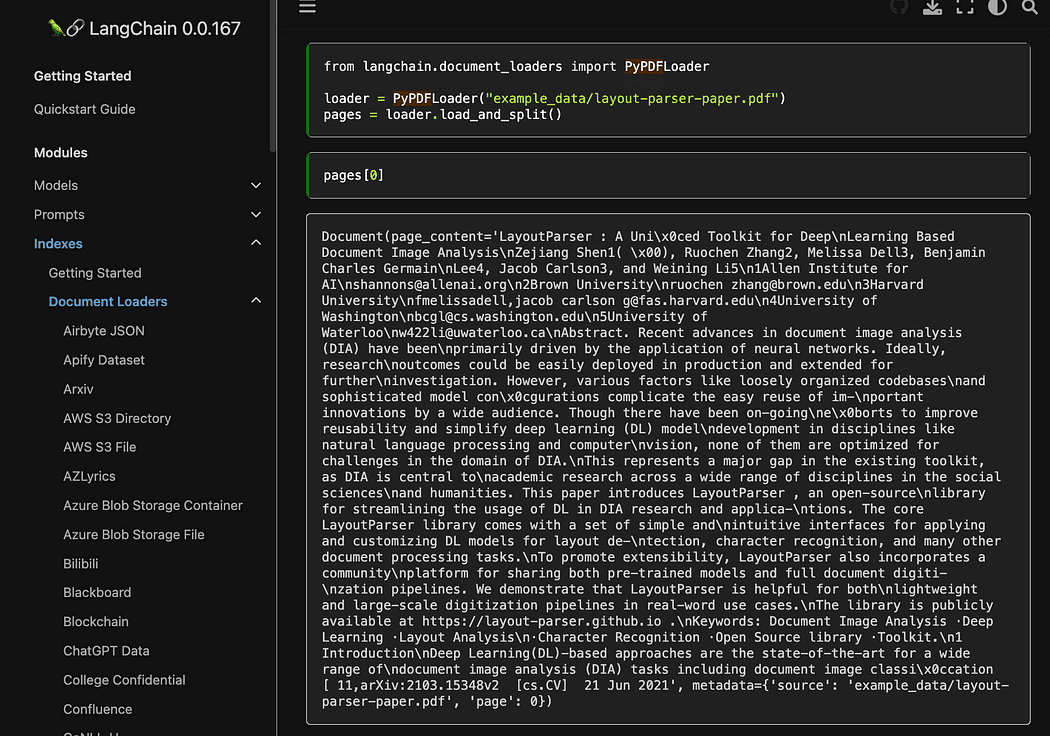 Screenshot dalla documentazione di Langchain
Screenshot dalla documentazione di Langchain
Possiamo eseguire il file python con il comando dal terminale:
python3 my_knowledge_qna.pyDopo il caricamento del modello per gli embeddings vedrete i token al lavoro per l’indicizzazione: non preoccupatevi poiché ci vorrà del tempo, specialmente se lo eseguite solo sulla CPU, come me (ci sono voluti 8 minuti).
 Completamento del primo database vettoriale
Completamento del primo database vettoriale
Come ho spiegato, il metodo pyPDF è più lento ma ci fornisce dati aggiuntivi per la ricerca di similarità. Per iterare attraverso tutti i nostri file useremo un metodo conveniente di FAISS che ci consente di UNIRE diversi database insieme. Quello che facciamo ora è utilizzare il codice sopra per generare il primo db (lo chiameremo db0 ) e con un ciclo for creiamo l’indice del file successivo nell’elenco e lo uniamo immediatamente con db0 .
Ecco il codice: nota che ho aggiunto alcuni registri per darti lo stato del progresso utilizzando datetime.datetime.now() e stampando la differenza tra l’ora di fine e l’ora di inizio per calcolare quanto tempo ha impiegato l’operazione (puoi rimuoverlo se non ti piace).
Le istruzioni per la fusione sono così
# unisci dbi con il db0 esistente
db0.merge_from(dbi)Una delle ultime istruzioni serve per salvare il nostro database localmente: l’intera generazione può richiedere anche ore (dipende da quanti documenti hai) quindi è davvero buono che dobbiamo farlo solo una volta!
# Salva il database localmente
db0.save_local("my_faiss_index")Ecco l’intero codice. Commenteremo molte parti di esso quando interagiremo con GPT4All caricando l’indice direttamente dalla nostra cartella.
# ottieni l'elenco dei file pdf dalla directory docs in formato elenco
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# crea un caricatore per i PDF dal percorso
general_start = datetime.datetime.now() #non usato ora ma utile
print("inizio del ciclo...")
loop_start = datetime.datetime.now() #non usato ora ma utile
print("generazione del primo database di vettori e poi iterazione con .merge_from")
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
docs = loader.load()
chunks = split_chunks(docs)
db0 = create_index(chunks)
print("Principale database di vettori creato. Inizio iterazione e unione...")
for i in range(1,num_of_docs):
print(doc_list[i])
print(f"posizione ciclo {i}")
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[i]))
start = datetime.datetime.now() #non usato ora ma utile
docs = loader.load()
chunks = split_chunks(docs)
dbi = create_index(chunks)
print("inizio unione con db0...")
db0.merge_from(dbi)
end = datetime.datetime.now() #non usato ora ma utile
elapsed = end - start #non usato ora ma utile
#tempo totale
print(f"completato in {elapsed}")
print("-----------------------------------")
loop_end = datetime.datetime.now() #non usato ora ma utile
loop_elapsed = loop_end - loop_start #non usato ora ma utile
print(f"Tutti i documenti elaborati in {loop_elapsed}")
print(f"il database è stato creato con {num_of_docs} sottoinsiemi di indice db")
print("-----------------------------------")
print(f"Fusione completata")
print("-----------------------------------")
print("Salvataggio del database unito localmente")
# Salva il database localmente
db0.save_local("my_faiss_index")
print("-----------------------------------")
print("database unito salvato come my_faiss_index")
general_end = datetime.datetime.now() #non usato ora ma utile
general_elapsed = general_end - general_start #non usato ora ma utile
print(f"Tutte le indicizzazioni completate in {general_elapsed}")
print("-----------------------------------")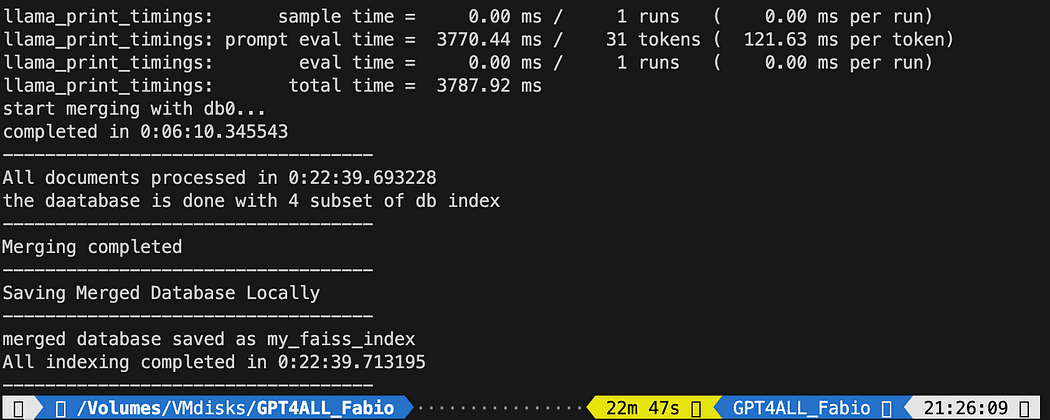 L’esecuzione del file python ha richiesto 22 minuti
L’esecuzione del file python ha richiesto 22 minuti
Fai domande a GPT4All sui tuoi documenti
Ora siamo qui. Abbiamo il nostro indice, possiamo caricarlo e con un Prompt Template possiamo chiedere a GPT4All di rispondere alle nostre domande. Iniziamo con una domanda codificata duramente e poi cicleremo attraverso le nostre domande di input.
Inserisci il seguente codice all’interno di un file python db_loading.py e eseguilo con il comando da terminale python3 db_loading.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# funzione per il caricamento solo dei file TXT
from langchain.document_loaders import TextLoader
# diviso il testo per creare i chunk
from langchain.text_splitter import RecursiveCharacterTextSplitter
# per poter caricare i file pdf
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader
# Indice del Vector Store per creare il nostro database sulla nostra conoscenza
from langchain.indexes import VectorstoreIndexCreator
# Embedding LLamaCpp dal modello Alpaca
from langchain.embeddings import LlamaCppEmbeddings
# libreria FAISS per la ricerca di similarità
from langchain.vectorstores.faiss import FAISS
import os #per l'interazione con i file
import datetime
# TEST PER LA RICERCA DI SIMILARITÀ
# assegna il percorso per i 2 modelli GPT4All e Alpaca per gli embeddings
gpt4all_path = './models/gpt4all-converted.bin'
llama_path = './models/ggml-model-q4_0.bin'
# Calback manager per la gestione delle chiamate con il modello
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])
# crea l'oggetto embedding
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# crea l'oggetto GPT4All llm
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True)
# Dividi il testo
def split_chunks(sources):
chunks = []
splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32)
for chunk in splitter.split_documents(sources):
chunks.append(chunk)
return chunks
def create_index(chunks):
texts = [doc.page_content for doc in chunks]
metadatas = [doc.metadata for doc in chunks]
search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas)
return search_index
def similarity_search(query, index):
# k è il numero di similarità cercato che corrisponde alla query
# di default è 4
matched_docs = index.similarity_search(query, k=3)
sources = []
for doc in matched_docs:
sources.append(
{
"page_content": doc.page_content,
"metadata": doc.metadata,
}
)
return matched_docs, sources
# Carica il nostro indice vettoriale locale db
index = FAISS.load_local("my_faiss_index", embeddings)
# Domanda codificata duramente
query = "Cos'è un PLC e qual è la differenza con un PC"
docs = index.similarity_search(query)
# Ottieni i migliori 3 risultati corrispondenti - definiti nella funzione k=3
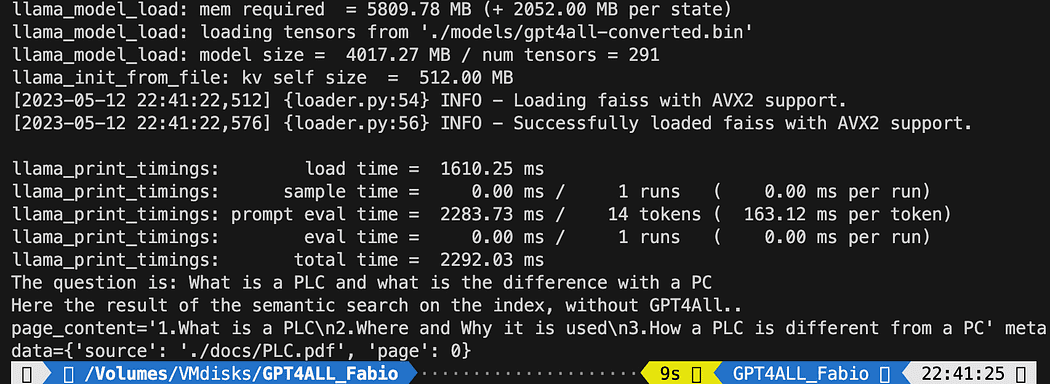
print(f"La domanda è: {query}")
print("Ecco il risultato della ricerca semantica sull'indice, senza GPT4All..")
print(docs[0])Il testo stampato è l’elenco delle 3 fonti che meglio corrispondono alla query, dando anche il nome del documento e il numero di pagina.
Ora possiamo utilizzare la ricerca di similarità come contesto per la nostra query utilizzando il modello di prompt. Dopo le 3 funzioni, sostituisci tutto il codice con il seguente:
# Carica il nostro database di vettori di indice locale
index = FAISS.load_local("my_faiss_index", embeddings)
# Crea il modello di prompt
template = """
Usa il contesto seguente per rispondere alle domande.
Contesto: {context}
---
Domanda: {question}
Risposta: Pensiamo passo dopo passo."""
# Domanda predefinita
question = "Cos'è un PLC e qual è la differenza con un PC"
matched_docs, sources = similarity_search(question, index)
# Creazione del contesto
context = "\n".join([doc.page_content for doc in matched_docs])
# Istanziare il modello di prompt e la catena GPT4All
prompt = PromptTemplate(template=template, input_variables=["context", "question"]).partial(context=context)
llm_chain = LLMChain(prompt=prompt, llm=llm)
# Stampa il risultato
print(llm_chain.run(question))Dopo l’esecuzione, otterrai un risultato simile a questo (ma può variare). Stupefacente, vero?!?
Usa il contesto seguente per rispondere alle domande.
Contesto: 1. Cos'è un PLC
2. Dove e perché viene utilizzato
3. In che cosa differisce un PLC da un PC
Il PLC è particolarmente importante in settori in cui la sicurezza e l'affidabilità sono
critici, come impianti di produzione, impianti chimici e centrali elettriche.
In che cosa differisce un PLC da un PC
Poiché un PLC è un computer specializzato utilizzato in applicazioni industriali e
manifatturiere per controllare macchinari e processi, i
componenti hardware di un tipico PLC devono essere in grado di interagire con
dispositivo industriale. Quindi un tipico hardware PLC include:
---
Domanda: Cos'è un PLC e qual è la differenza con un PC
Risposta: Pensiamo passo dopo passo. 1) Un controllore logico programmabile (PLC),
anche chiamato sistema di controllo industriale o ICS, si riferisce a un computer industriale
che controlla vari processi automatizzati come macchine di produzione / linee di assemblaggio eccetera attraverso sensori e attuatori collegati ad esso tramite input e output.
È una forma di computer digitale che ha
la capacità di esecuzione di istruzioni multiple (MIE), registri di memoria integrati
usati da routine software, schede di interfaccia di input / output (IOC)
per comunicare con altri dispositivi elettronicamente / digitalmente su
o bus eccetera
2). Un controllore logico programmabile è ampiamente utilizzato nell'automazione industriale poiché ha la capacità di eseguire più di una istruzione.
Può svolgere compiti automaticamente e istruzioni programmate, il che consente
per svolgere operazioni complesse che sono al di là di una
Capacità del Personal Computer (PC). Quindi un ICS / PLC contiene memoria integrata
registri utilizzati da routine software o codici firmware eccetera ma
Il PC non li contiene, quindi hanno bisogno di interfacce esterne come
dischi fissi (HDD), porte USB, protocolli di comunicazione seriale e parallela
per archiviare i dati per ulteriori analisi o generazione di report.Se vuoi che una domanda inserita dall’utente sostituisca la riga
question = "Cos'è un PLC e qual è la differenza con un PC"con qualcosa del genere:
question = input("La tua domanda: ")Conclusioni
È ora di sperimentare. Fai domande diverse su tutti gli argomenti correlati ai tuoi documenti e vedi i risultati. C’è molto spazio per il miglioramento, certamente sul prompt e sul modello: puoi dare un’occhiata qui per qualche ispirazione. Ma la documentazione di Langchain è davvero fantastica (sono riuscito a seguirla!!).
Puoi seguire il codice dall’articolo o controllarlo nel mio repository github .
Fabio Matricardi, educatore, insegnante, ingegnere e appassionato di apprendimento. Ha insegnato per 15 anni a giovani studenti e ora forma nuovi dipendenti presso Key Solution Srl. Ha iniziato la sua carriera come ingegnere di automazione industriale nel 2010. Appassionato di programmazione fin da adolescente, ha scoperto la bellezza della creazione di software e interfacce uomo-macchina per dare vita a qualcosa. Insegnare e fare coaching fa parte della sua routine quotidiana, così come studiare e imparare come essere un leader appassionato con competenze di gestione aggiornate. Unisciti a lui nel percorso verso un design migliore, un’integrazione di sistema predittivo utilizzando Machine Learning e Artificial Intelligence durante l’intero ciclo di vita dell’ingegneria.
Originale. Ripubblicato con il permesso.





