Guidare la generazione del testo con la ricerca vincolata a fascio in 🤗 Transformers
Generazione guidata del testo con ricerca vincolata a fascio in 🤗 Transformers.
![]()
Introduzione
Questa pubblicazione assume che il lettore sia familiare con i metodi di generazione di testo utilizzando le diverse varianti della ricerca beam, come spiegato nella pubblicazione: “Come generare testo: utilizzo di diversi metodi di decodifica per la generazione di linguaggio con i Transformer”
A differenza della normale ricerca beam, la ricerca beam vincolata ci consente di esercitare un controllo sull’output della generazione di testo. Questo è utile perché a volte sappiamo esattamente cosa vogliamo all’interno dell’output. Ad esempio, in un compito di traduzione automatica neurale, potremmo sapere quali parole devono essere incluse nella traduzione finale tramite una ricerca nel dizionario. A volte, gli output di generazione che sono quasi altrettanto possibili per un modello di linguaggio potrebbero non essere altrettanto desiderabili per l’utente finale a causa del contesto specifico. Entrambe queste situazioni potrebbero essere risolte consentendo agli utenti di dire al modello quali parole devono essere incluse nell’output finale.
Perché è difficile
Tuttavia, questo è in realtà un problema molto complesso. Questo perché il compito richiede di forzare la generazione di determinate sottosequenze in qualche punto dell’output finale, in qualche momento durante la generazione.
- Un’introduzione al Deep Reinforcement Learning
- Mostra i tuoi progetti negli spazi utilizzando Gradio
- Ospitare i tuoi modelli e dataset su Hugging Face Spaces utilizzando Streamlit
Supponiamo di voler generare una frase S che deve includere la frase p 1 = { t 1 , t 2 } p_1=\{ t_1, t_2 \} p 1 = { t 1 , t 2 } con i token t 1 , t 2 t_1, t_2 t 1 , t 2 nell’ordine. Definiamo la frase attesa S S S come:
S e s p e t t a t a = { s 1 , s 2 , . . . , s k , t 1 , t 2 , s k + 1 , . . . , s n } S_{\text{attesa}} = \{ s_1, s_2, …, s_k, t_1, t_2, s_{k+1}, …, s_n \} S e s p e t t a t a = { s 1 , s 2 , . . . , s k , t 1 , t 2 , s k + 1 , . . . , s n }
Il problema è che la ricerca beam genera la sequenza token per token. Sebbene non sia del tutto accurato, si può pensare alla ricerca beam come alla funzione B ( s 0 : i ) = s i + 1 B(\mathbf{s}_{0:i}) = s_{i+1} B ( s 0 : i ) = s i + 1 , dove guarda alla sequenza di token generata al momento da 0 0 0 a i i i e quindi predice il prossimo token a i + 1 i+1 i + 1 . Ma come può questa funzione sapere, ad un passo arbitrario i < k i < k i < k , che i token devono essere generati in qualche passo futuro k k k ? O quando si trova al passo i = k i=k i = k , come può sapere con certezza che questo è il miglior punto per forzare i token, invece di qualche passo futuro i > k i>k i > k ?
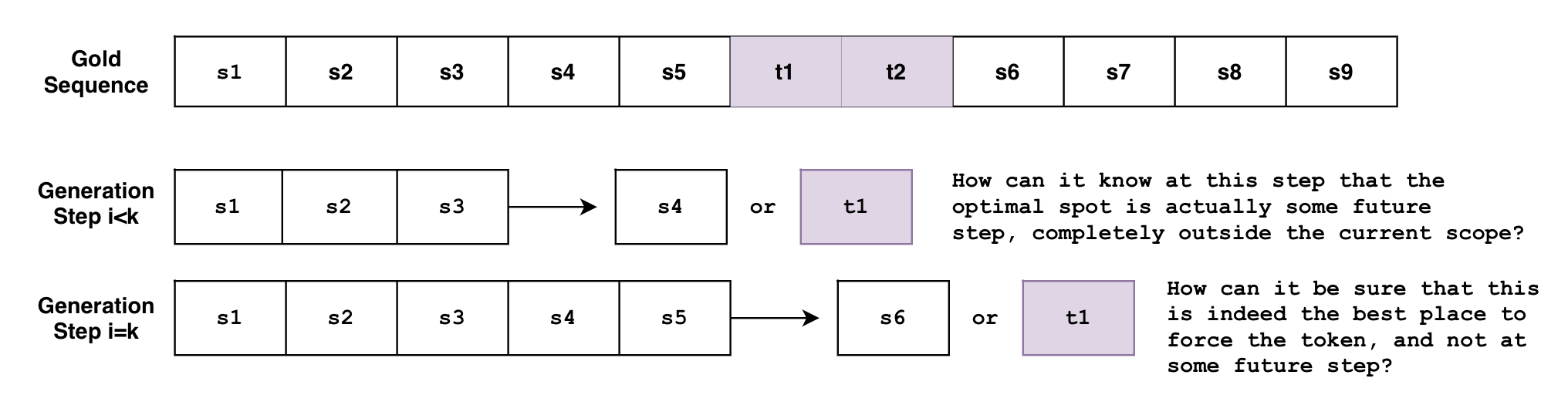
E se si hanno più vincoli con requisiti variabili? Cosa succede se si vuole forzare la frase p 1 = { t 1 , t 2 } p_1=\{t_1, t_2\} p 1 = { t 1 , t 2 } e anche la frase p 2 = { t 3 , t 4 , t 5 , t 6 } p_2=\{ t_3, t_4, t_5, t_6\} p 2 = { t 3 , t 4 , t 5 , t 6 } ? Cosa succede se si vuole che il modello scegli tra le due frasi? Cosa succede se si vuole forzare la frase p 1 p_1 p 1 e forzare solo una frase tra l’elenco di frasi { p 21 , p 22 , p 23 } \{p_{21}, p_{22}, p_{23}\} { p 2 1 , p 2 2 , p 2 3 } ?
I precedenti esempi sono in realtà casi d’uso molto ragionevoli, come verrà mostrato di seguito, e la nuova funzionalità di ricerca a fascio vincolata permette di eseguirli tutti!
In questo post verrà spiegato rapidamente cosa può fare per voi la nuova funzionalità di ricerca a fascio vincolata e poi si approfondiranno i dettagli su come funziona sotto il cofano.
Esempio 1: Forzare una parola
Supponiamo di voler tradurre "Quanti anni hai?" in tedesco.
In un contesto informale si direbbe "Wie alt bist du?", mentre in un contesto formale si direbbe "Wie alt sind Sie?".
E a seconda del contesto, potremmo preferire una forma di formalità rispetto all’altra, ma come lo diciamo al modello?
Ricerca a fascio tradizionale
Ecco come faremmo la traduzione di testo con la ricerca a fascio tradizionale.
!pip install -q git+https://github.com/huggingface/transformers.git
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("t5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")
encoder_input_str = "translate English to German: How old are you?"
input_ids = tokenizer(encoder_input_str, return_tensors="pt").input_ids
outputs = model.generate(
input_ids,
num_beams=10,
num_return_sequences=1,
no_repeat_ngram_size=1,
remove_invalid_values=True,
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Output:
----------------------------------------------------------------------------------------------------
Wie alt bist du?Con la ricerca a fascio vincolata
Ma cosa succede se sappiamo che vogliamo un output formale invece di quello informale? Cosa succede se sappiamo in base alla conoscenza precedente cosa deve includere la generazione e possiamo iniettarlo nella generazione?
Ecco cosa è ora possibile con l’argomento opzionale force_words_ids del metodo model.generate():
tokenizer = AutoTokenizer.from_pretrained("t5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")
encoder_input_str = "translate English to German: How old are you?"
force_words = ["Sie"]
input_ids = tokenizer(encoder_input_str, return_tensors="pt").input_ids
force_words_ids = tokenizer(force_words, add_special_tokens=False).input_ids
outputs = model.generate(
input_ids,
force_words_ids=force_words_ids,
num_beams=5,
num_return_sequences=1,
no_repeat_ngram_size=1,
remove_invalid_values=True,
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Output:
----------------------------------------------------------------------------------------------------
Wie alt sind Sie?Come puoi vedere, siamo stati in grado di guidare la generazione con la conoscenza precedente sul nostro output desiderato. In precedenza avremmo dovuto generare una serie di possibili output, quindi filtrare quelli che soddisfano i nostri requisiti. Ora possiamo farlo durante la generazione stessa.
Esempio 2: Vincoli disgiuntivi
Abbiamo menzionato in precedenza un caso d’uso in cui sappiamo quali parole vogliamo includere nell’output finale. Un esempio potrebbe essere l’uso di un dizionario durante la traduzione automatica neurale.
Ma cosa succede se non sappiamo quali forme di parole usare, dove vorremmo che gli output come ["piove", "pioveva", "pioverà", ...] siano tutti altrettanto possibili? In senso più generale, ci sono sempre casi in cui non vogliamo una corrispondenza esatta parola per parola e potremmo essere aperti ad altre possibilità correlate.
I vincoli che consentono questo comportamento sono i Vincoli disgiuntivi, che consentono all’utente di inserire una lista di parole, il cui scopo è guidare la generazione in modo che l’output finale debba contenere almeno una delle parole della lista.
Ecco un esempio che utilizza una combinazione dei due tipi di vincoli sopra menzionati:
from transformers import GPT2LMHeadModel, GPT2Tokenizer
model = GPT2LMHeadModel.from_pretrained("gpt2")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
force_word = "spaventato"
force_flexible = ["grido", "grida", "gridando", "gridato"]
force_words_ids = [
tokenizer([force_word], add_prefix_space=True, add_special_tokens=False).input_ids,
tokenizer(force_flexible, add_prefix_space=True, add_special_tokens=False).input_ids,
]
starting_text = ["I soldati", "Il bambino"]
input_ids = tokenizer(starting_text, return_tensors="pt").input_ids
outputs = model.generate(
input_ids,
force_words_ids=force_words_ids,
num_beams=10,
num_return_sequences=1,
no_repeat_ngram_size=1,
remove_invalid_values=True,
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
print(tokenizer.decode(outputs[1], skip_special_tokens=True))
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Output:
----------------------------------------------------------------------------------------------------
I soldati, che erano tutti spaventati e gridavano l'uno contro l'altro mentre cercavano di uscire
Il bambino è stato portato in un ospedale locale dove gridava e spaventato per la sua vita, hanno detto le autorità.Come puoi vedere, il primo output ha utilizzato "screaming", il secondo output ha utilizzato "screamed", e entrambi hanno utilizzato "scared" letteralmente. L’elenco da cui scegliere ["screaming", "screamed", ...] non deve essere solo forme verbali, può soddisfare qualsiasi caso in cui abbiamo bisogno di sceglierne solo una da un elenco di parole.
Ricerca Beam tradizionale
Di seguito è riportato un esempio di ricerca Beam tradizionale, tratto da un precedente post sul blog:
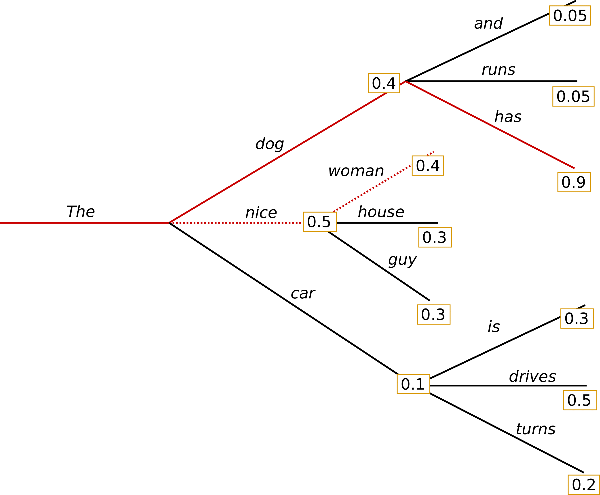
A differenza della ricerca greedy, la ricerca Beam funziona mantenendo un elenco più lungo di ipotesi. Nell’immagine sopra, abbiamo visualizzato tre possibili token successivi ad ogni possibile passo nella generazione.
Ecco un altro modo per visualizzare il primo passo della ricerca Beam per l’esempio precedente, nel caso di num_beams=3:
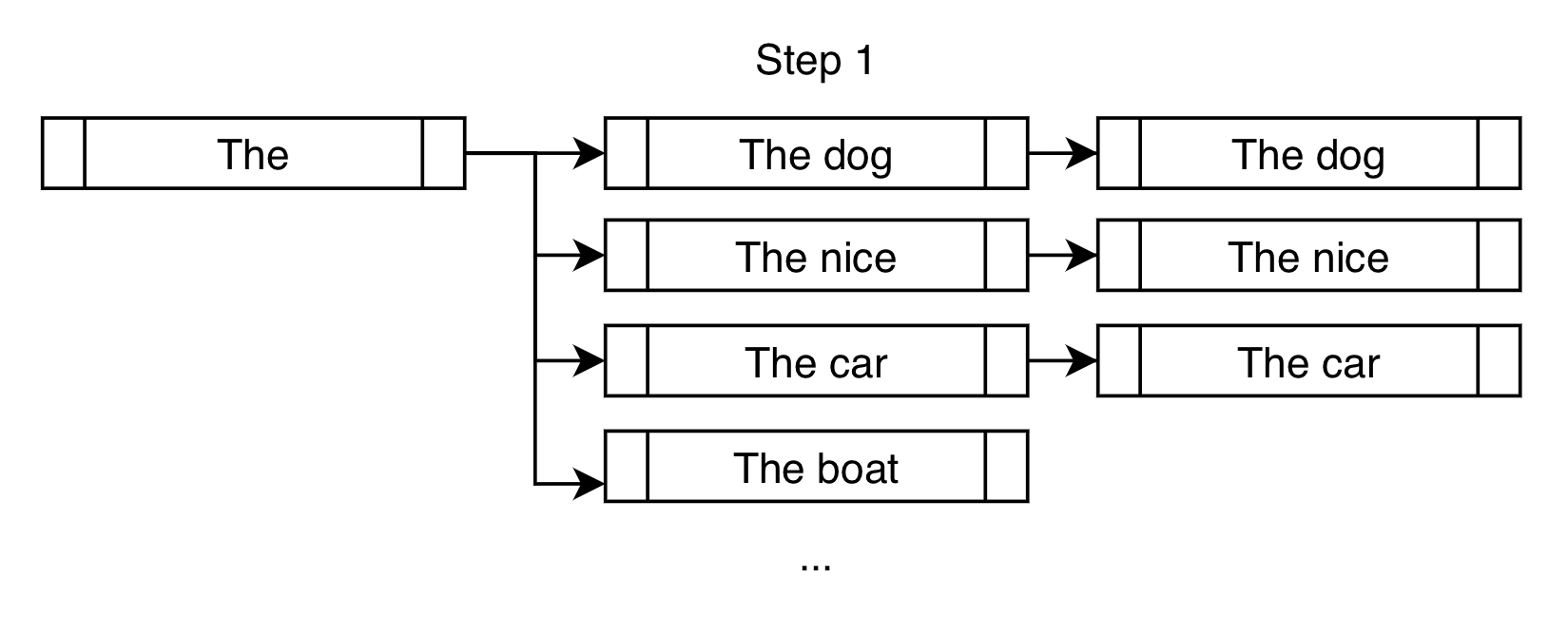
Al contrario di ciò che farebbe una ricerca greedy, che sceglierebbe solo "The dog", una ricerca Beam consentirebbe di considerare anche "The nice" e "The car".
Nel passo successivo, consideriamo i possibili token successivi per ognuno dei tre rami creati nel passo precedente.
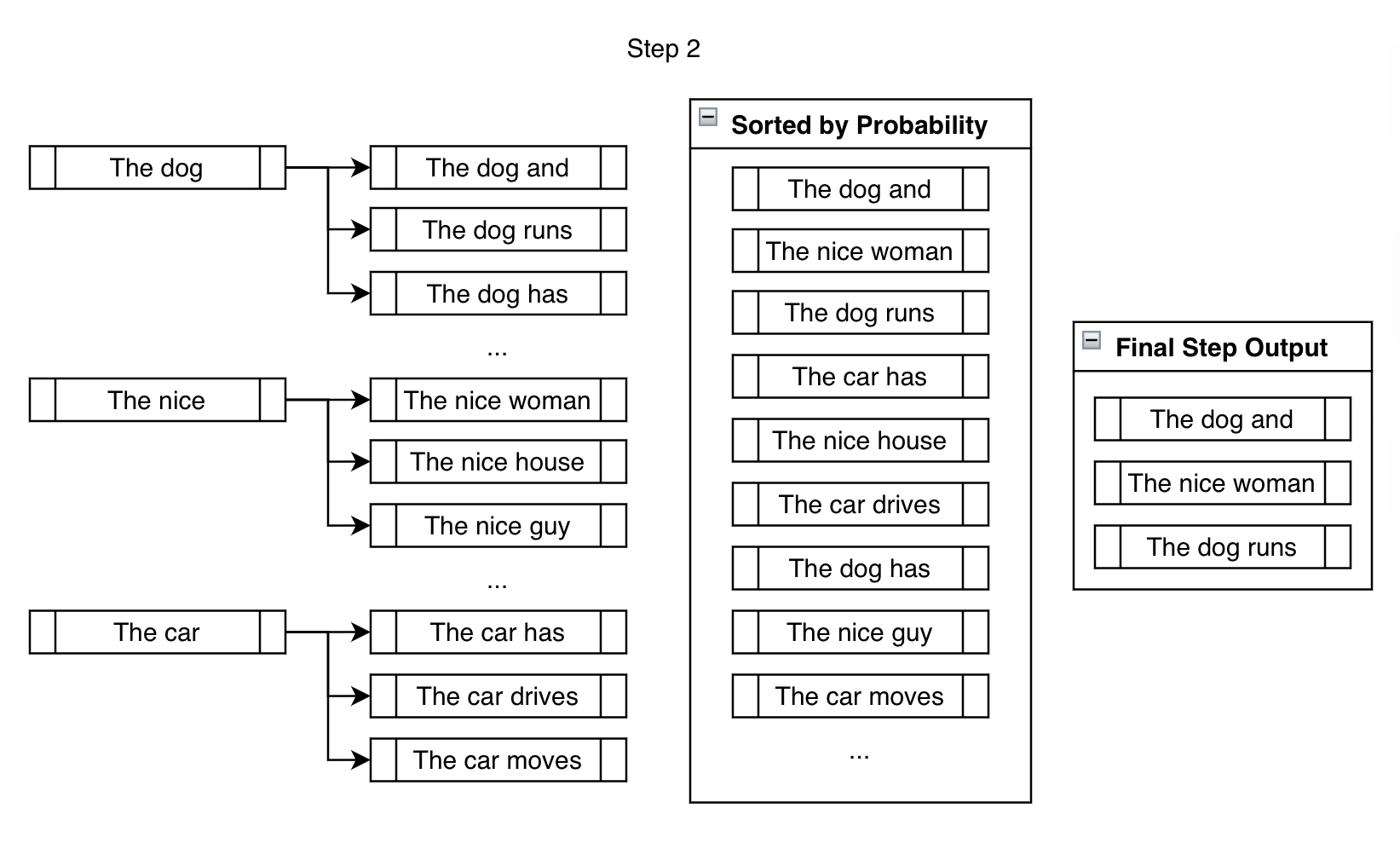
Anche se finiamo per considerare un numero significativamente maggiore di output rispetto a num_beams, li riduciamo a num_beams alla fine del passo. Non possiamo semplicemente continuare a creare nuovi rami, altrimenti il numero di beams che dovremmo tenere traccia sarebbe beams n \text{beams}^{n} beams n per n n n passi, che diventa molto grande molto rapidamente (10 10 1 0 beams dopo 10 10 1 0 passi sono 10 , 000 , 000 , 000 10,000,000,000 1 0 , 0 0 0 , 0 0 0 , 0 0 0 beams!).
Per il resto della generazione, ripetiamo il passo sopra finché non vengono soddisfatti i criteri di fine, come generare il token <eos> o raggiungere max_length, ad esempio. Creare rami, ordinare, ridurre e ripetere.
Ricerca Beam vincolata
La ricerca Beam vincolata cerca di soddisfare i vincoli inserendo i token desiderati ad ogni passo della generazione.
Supponiamo di voler forzare la frase "is fast" nell’output generato.
Nell’impostazione tradizionale della ricerca Beam, troviamo i k token successivi più probabili per ogni ramo e li aggiungiamo per la considerazione. Nell’impostazione vincolata, facciamo lo stesso ma aggiungiamo anche i token che ci avvicineranno a soddisfare i nostri vincoli. Ecco una dimostrazione:
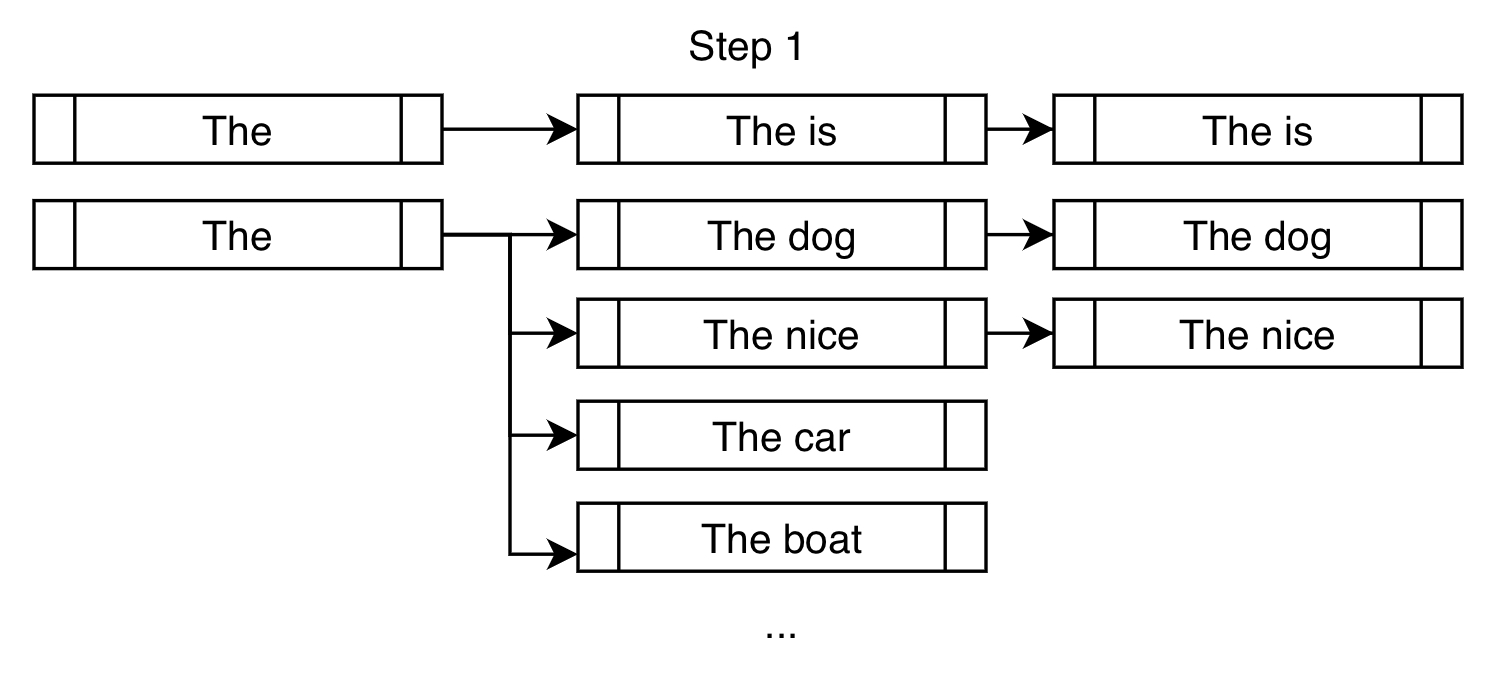
Oltre ai soliti token successivi ad alta probabilità come "dog" e "nice", forziamo il token "is" per avvicinarci al soddisfacimento del nostro vincolo di "is fast".
Per il passo successivo, i candidati ramificati qui sotto sono per lo più gli stessi della ricerca Beam tradizionale. Ma come nell’esempio precedente, la ricerca Beam vincolata aggiunge ai candidati esistenti forzando i vincoli ad ogni nuovo ramo:
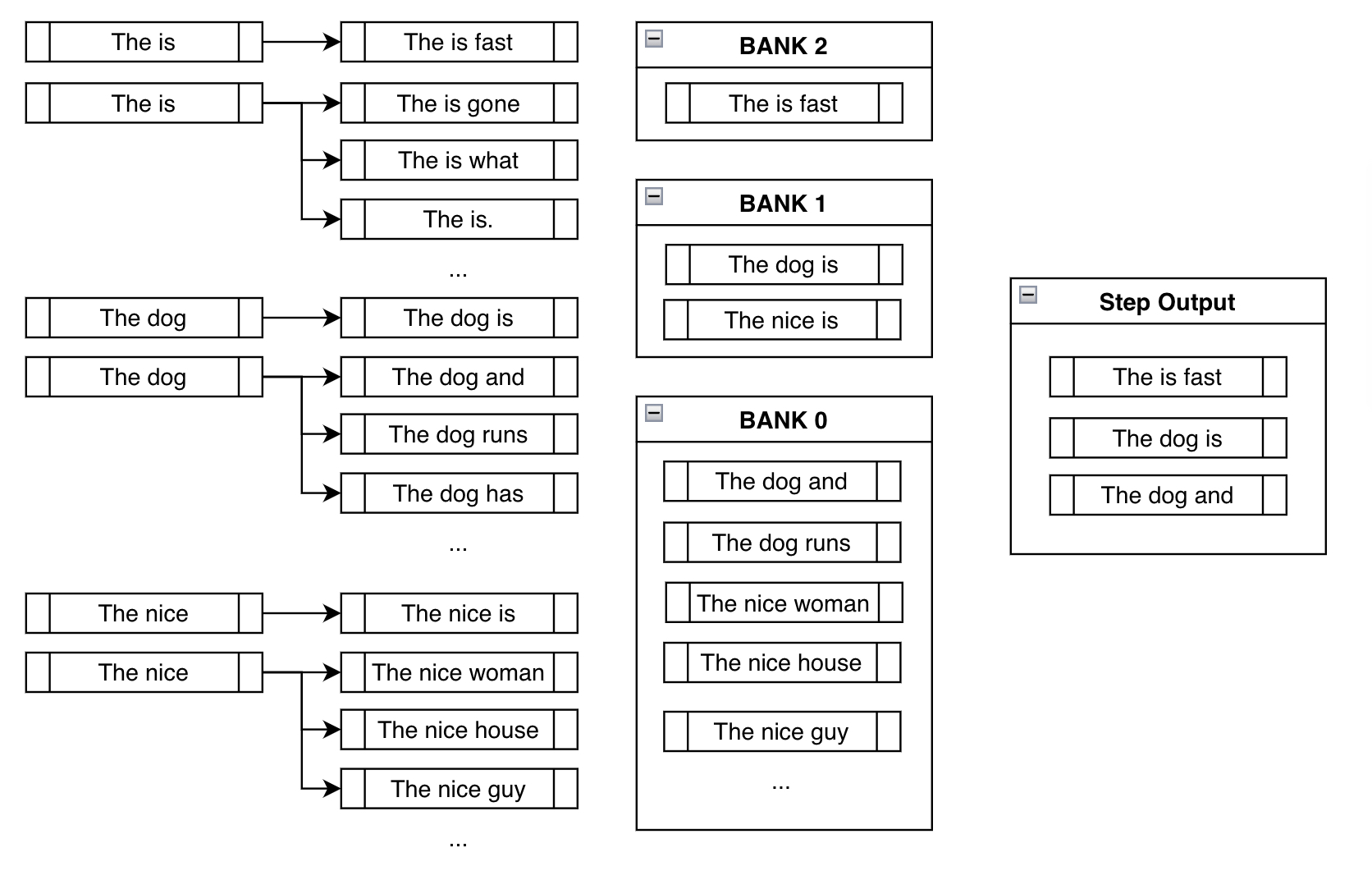
Banche
Prima di parlare del passo successivo, dobbiamo pensare al comportamento indesiderabile risultante che possiamo vedere nel passo sopra.
Il problema con il forzare semplicemente la frase desiderata "is fast" nell’output è che, nella maggior parte dei casi, si otterrebbero output senza senso come "The is fast" sopra. Questo è ciò che rende questo un problema non banale da risolvere. Una discussione più approfondita sulle complessità di risolvere questo problema può essere trovata nella richiesta di funzionalità originale che è stata sollevata in huggingface/transformers.
Le banche risolvono questo problema creando un equilibrio tra il soddisfacimento dei vincoli e la creazione di output sensati.
Bank n n n si riferisce all’elenco di travi che hanno compiuto n n n passi nel soddisfacimento dei vincoli. Dopo aver ordinato tutte le possibili travi nelle rispettive banche, facciamo una selezione round-robin. Con l’esempio sopra, selezioneremmo l’output più probabile da Bank 2, quindi il più probabile da Bank 1, uno da Bank 0, il secondo più probabile da Bank 2, il secondo più probabile da Bank 1 e così via. Poiché stiamo usando num_beams=3, facciamo semplicemente il processo sopra tre volte per ottenere ["The is fast", "The dog is", "The dog and"].
In questo modo, anche se stiamo forzando il modello a considerare il ramo in cui abbiamo aggiunto manualmente il token desiderato, teniamo comunque traccia di altre sequenze ad alta probabilità che probabilmente hanno più senso. Anche se "The is fast" soddisfa completamente il nostro vincolo, non è una frase molto sensata. Fortunatamente, abbiamo "The dog is" e "The dog and" con cui lavorare nei passaggi successivi, che speriamo porteranno a output più sensati in seguito.
Questo comportamento è dimostrato nel terzo passaggio dell’esempio sopra:
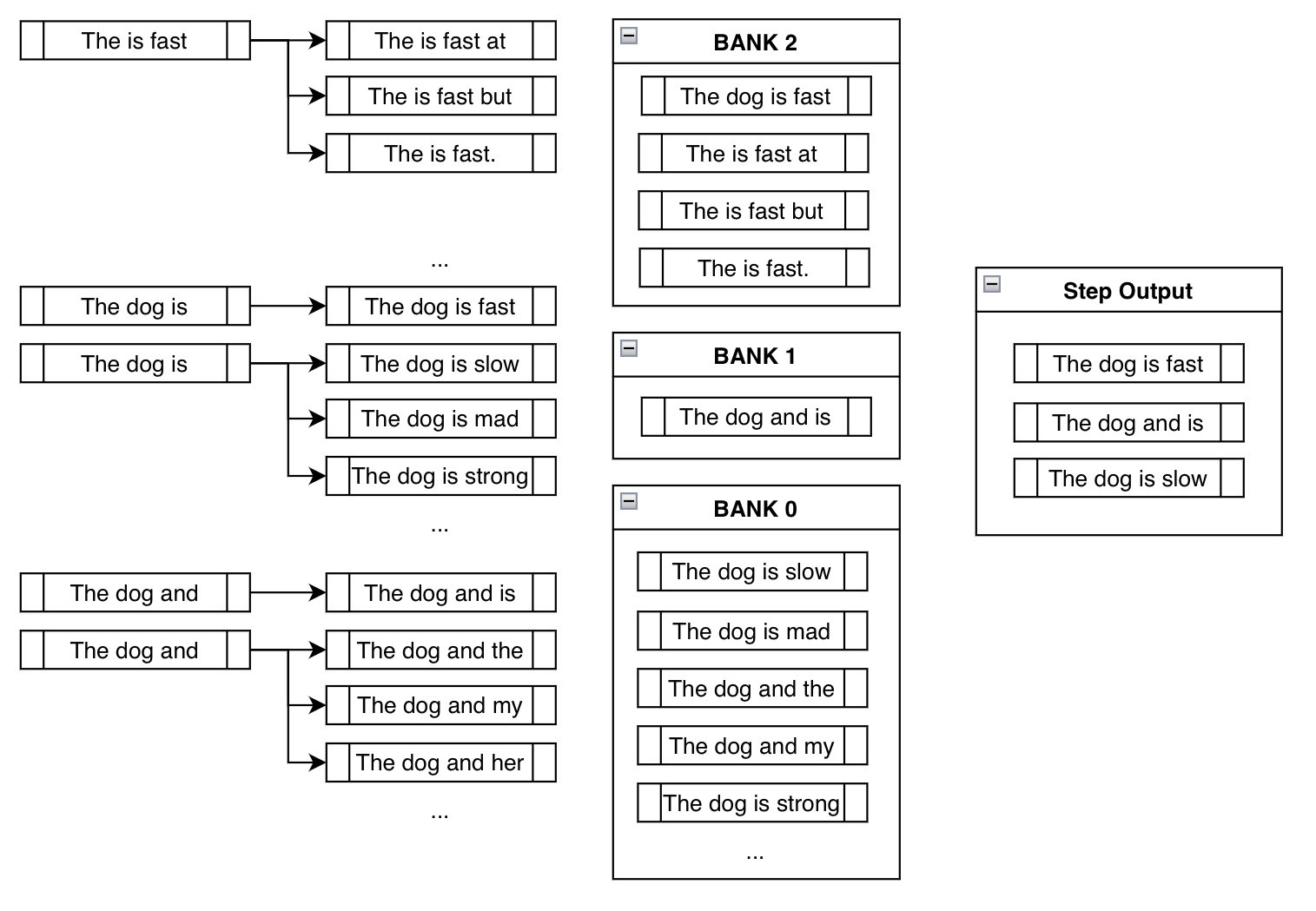
Notare come "The is fast" non richieda l’aggiunta manuale di token di vincolo poiché è già soddisfatto (cioè contiene già la frase "is fast"). Notare anche come le travi come "The dog is slow" o "The dog is mad" siano effettivamente in Bank 0, poiché, anche se include il token "is", deve ricominciare da capo per generare "is fast". Aggiungendo qualcosa come "slow" dopo "is", ha effettivamente azzerato il suo progresso.
E infine notare come siamo arrivati a un output sensato che contiene la nostra frase di vincolo: "The dog is fast"!
Eramo preoccupati inizialmente perché l’aggiunta cieca dei token desiderati portava a frasi prive di senso come "The is fast". Tuttavia, utilizzando la selezione round-robin dalle banche, implicitamente ci siamo liberati degli output privi di senso a favore degli output più sensati.
Maggiori informazioni su classi di vincoli e vincoli personalizzati
Il punto principale dell’illustrazione può essere riassunto come segue. Ad ogni passaggio, continuiamo a sollecitare il modello a considerare i token che soddisfano i nostri vincoli, tenendo traccia delle travi che non li soddisfano, fino a quando otteniamo sequenze con probabilità ragionevolmente alte che contengono le nostre frasi desiderate.
Quindi un modo corretto per progettare questa implementazione è rappresentare ogni vincolo come un oggetto Constraint, il cui scopo è tenere traccia del suo progresso e dire alla ricerca della trave quali token generare successivamente. Sebbene abbiamo fornito l’argomento chiave force_words_ids per model.generate(), effettivamente accade quanto segue nel backend:
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, PhrasalConstraint
tokenizer = AutoTokenizer.from_pretrained("t5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")
encoder_input_str = "translate English to German: How old are you?"
constraints = [
PhrasalConstraint(
tokenizer("Sie", add_special_tokens=False).input_ids
)
]
input_ids = tokenizer(encoder_input_str, return_tensors="pt").input_ids
outputs = model.generate(
input_ids,
constraints=constraints,
num_beams=10,
num_return_sequences=1,
no_repeat_ngram_size=1,
remove_invalid_values=True,
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Output:
----------------------------------------------------------------------------------------------------
Wie alt sind Sie?Puoi definirne uno tu stesso e inserirlo nell’argomento chiave constraints per progettare i tuoi vincoli unici. Devi solo creare una sottoclasse dell’interfaccia astratta Constraint e seguire i suoi requisiti. Puoi trovare ulteriori informazioni nella definizione di Constraint trovata qui .
Alcune idee uniche (non ancora implementate; forse puoi provarci!) includono vincoli come OrderedConstraints, TemplateConstraints che potrebbero essere aggiunti in seguito. Attualmente, la generazione viene soddisfatta includendo le sequenze, ovunque nell’output. Ad esempio, un esempio precedente aveva una sequenza con scared -> screaming e l’altra con screamed -> scared. OrderedConstraints potrebbe consentire all’utente di specificare l’ordine in cui questi vincoli vengono soddisfatti.
TemplateConstraints potrebbe consentire un uso più specifico della funzionalità, dove l’obiettivo può essere qualcosa del tipo:
starting_text = "La donna"
template = ["la", "", "Scuola di", "", "in"]
possible_outputs == [
"La donna ha frequentato la Ross School of Business nel Michigan.",
"La donna era l'amministratore della Harvard School of Business nel MA."
]o:
starting_text = "La donna"
template = ["la", "", "", "Università", "", "in"]
possible_outputs == [
"La donna ha frequentato la Carnegie Mellon University a Pittsburgh.",
]
impossible_outputs == [
"La donna ha frequentato la Harvard University nel MA."
]oppure se all’utente non interessa il numero di token che possono essere inseriti tra due parole, allora si può semplicemente usare OrderedConstraint.
Conclusioni
La ricerca guidata con beam search ci offre un modo flessibile per inserire conoscenze esterne e requisiti nella generazione di testo. In precedenza, non c’era un modo facile per dire al modello di 1. includere un elenco di sequenze in cui 2. alcune delle quali sono opzionali e alcune no, in modo tale che 3. vengano generate da qualche parte nella sequenza in posizioni ragionevoli. Ora, possiamo avere il pieno controllo sulla nostra generazione con una combinazione di diverse sottoclassi di oggetti Constraint!
Questa nuova funzionalità si basa principalmente sui seguenti articoli:
- Guided Open Vocabulary Image Captioning with Constrained Beam Search
- Fast Lexically Constrained Decoding with Dynamic Beam Allocation for Neural Machine Translation
- Improved Lexically Constrained Decoding for Translation and Monolingual Rewriting
- Guided Generation of Cause and Effect
Come quelli sopra, molti nuovi articoli di ricerca stanno esplorando modi per utilizzare conoscenze esterne (ad esempio, KG, KB) per guidare gli output di modelli di deep learning di grandi dimensioni. Speriamo che questa funzionalità di ricerca guidata con beam search diventi un altro modo efficace per raggiungere questo scopo.
Grazie a tutti coloro che hanno fornito indicazioni per il contributo di questa funzionalità: Patrick von Platen per essere stato coinvolto dalla segnalazione iniziale all’RP finale, e Narsil Patry, per aver fornito un feedback dettagliato sul codice.
L’immagine in miniatura di questo post utilizza un’icona con l’attribuzione: Shorthand icons created by Freepik – Flaticon