Da Grezzo a Raffinato Un Viaggio Attraverso la Preelaborazione dei Dati – Parte 3 Dati Duplicati
From Raw to Refined A Journey Through Data Preprocessing - Part 3 Duplicate Data
Questo articolo spiegherà come identificare i record duplicati nei dati e le diverse modalità per affrontare il problema dei record duplicati.
Perché la presenza di record duplicati nei dati è un problema?
La presenza di valori duplicati nei dati spesso viene ignorata da molti programmatori. Ma, gestire i record duplicati nei dati è piuttosto importante.
Avere record duplicati può portare a un’analisi errata dei dati e alla presa di decisioni.
Ad esempio, cosa succede quando si sostituiscono i valori mancanti (imputazione) con la media in dati con record duplicati?
- Dati Fittizi sulle Lamentele Bancarie
- Incontra LegalBench un benchmark AI open-source costruito collaborativamente per valutare il ragionamento legale nei grandi modelli di linguaggio in inglese.
- Scopri come addestrare modelli di rilevamento degli oggetti con MMDetection
In questo scenario, potrebbe essere utilizzato un valore medio errato per l’imputazione. Prendiamo ad esempio.
Considera i seguenti dati. I dati contengono due colonne, ovvero Nome e Peso. Nota che il valore del peso per ‘John’ è ripetuto. Inoltre, il valore del peso per ‘Steve’ è mancante.
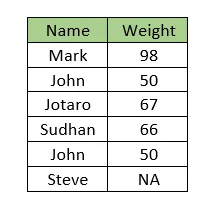
Se si desidera imputare il valore mancante del peso per Steve con la media di tutti i valori del peso, allora l’imputazione verrebbe effettuata utilizzando la media errata, cioè
(98 + 50 + 67 + 66 + 50)/5 = 66.2
Ma la media effettiva dei dati ignorando il valore duplicato è
(98 + 50 + 67 + 66)/4 = 70.25
Pertanto, il valore mancante verrà imputato in modo errato se non facciamo qualcosa riguardo ai record duplicati.
Inoltre, i valori duplicati possono influenzare anche le decisioni aziendali che vengono prese utilizzando tali dati errati.
In sintesi, i record duplicati dei dati devono essere gestiti per mantenere i dati privi di problemi.
Ora, vediamo diversi metodi per affrontare i record duplicati nei dati.
Identificare i valori duplicati nei dati
Possiamo utilizzare il metodo duplicato di pandas per identificare le righe duplicate nei dati.
Adesso, comprendiamo i valori duplicati utilizzando un esempio.
## Importazione delle librerie richiesteimport numpy as npimport pandas as pdimport warningswarnings.filterwarnings('ignore')## Creazione di un dataframeName = ['Mark', 'John', 'Jotaro', 'Mark', 'John', 'Steve']Weight = [98, 50, 67, 66, 50, np.nan]Height = [170, 175, 172, 170, 175, 166]df = pd.DataFrame()df['Name'] = Namedf['Weight'] = Weightdf['Height'] = Heightdf
Identificare i valori duplicati:
## Identificazione dei valori duplicati (comportamento predefinito)df.duplicated()
Otteniamo il valore True, dove è presente il record duplicato, e False dove sono presenti i record unici.
Nota che per impostazione predefinita, il metodo duplicated() utilizza tutte le colonne per trovare i record duplicati. Ma, possiamo utilizzare un sottoinsieme di colonne per trovare i duplicati. Per fare ciò, il metodo duplicated() ha un parametro chiamato subset. Il parametro subset prende la lista dei nomi delle colonne che vogliamo utilizzare per trovare i duplicati.
## parametro subset del metodo duplicated()df.duplicated(subset=['Name','Height'])
Inoltre, il metodo duplicated() ha un altro parametro importante chiamato keep. Il valore del parametro keep decide se considerare il primo record o l’ultimo record come unico tra tutti i record duplicati. Abbiamo anche l’opzione di considerare tutti i record duplicati come non unici.
keep = ‘first’: Il primo record tra tutti i record duplicati è considerato unico.
keep = ‘last’: L’ultimo record tra tutti i record duplicati è considerato unico.
keep = False: Tutti i record duplicati sono considerati non unici.
## parametro keep del metodo duplicated()df.duplicated(keep='first')
Notare che il primo valore duplicato (all’indice 1) è considerato unico e tutti gli altri (all’indice 4) sono considerati duplicati.
## parametro keep del metodo duplicated()df.duplicated(keep='last')
Notare che l’ultimo valore duplicato (all’indice 4) è considerato unico e tutti gli altri (all’indice 1) sono considerati duplicati.
## parametro keep del metodo duplicated()df.duplicated(keep=False)
Notare che tutti i record duplicati (all’indice 1 e all’indice 4) vengono mostrati.
Come gestire i record duplicati nei dati
Il passo successivo dopo aver identificato i record duplicati è gestirli.
Ci sono due modi per gestire i record duplicati nei dati.
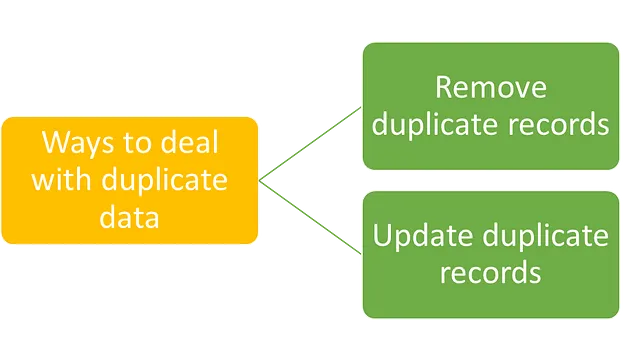
Rimuovere i record duplicati
Iniziamo con l’approccio in cui rimuoviamo i record duplicati.
Possiamo utilizzare il metodo drop_duplicates() di pandas per fare ciò.
Per impostazione predefinita, il metodo drop_duplicates() mantiene il primo record dall’insieme di tutti i record duplicati e quindi elimina il resto dai dati. Inoltre, per impostazione predefinita, il metodo drop_duplicates() utilizza tutte le colonne per identificare i record duplicati.
Ma questo comportamento predefinito può essere modificato utilizzando i due parametri del metodo drop_duplicates(). Sono
- keep
- subset
Lavorano esattamente come i parametri keep e subset del metodo duplicated().
"""rimozione dei valori duplicati utilizzando il metodo drop_duplicates() di pandas (comportamento predefinito)"""df1 = df.drop_duplicates()df1
"""rimozione dei valori duplicati utilizzando il metodo drop_duplicates() di pandas con i parametri subset e keep (comportamento personalizzato)"""df2 = df.drop_duplicates(subset=['Weight'], keep='last')df2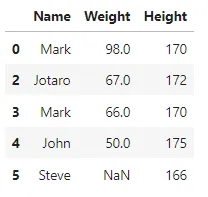
Aggiornamento dei record duplicati
A volte vogliamo sostituire i record duplicati con un certo valore. Diciamo che abbiamo trovato due record duplicati, poi abbiamo scoperto che la persona che ha acquisito i dati ha inserito accidentalmente il nome sbagliato in uno dei record duplicati. Quindi in questo caso, vorremmo mettere il nome della persona corretta. In questo modo si risolverebbe il problema dei valori duplicati.
df.duplicated(keep=False)
Qui, abbiamo record duplicati agli indici 1 e 4. Ora, se cambiamo il valore della colonna ‘Nome’ all’indice 1, non avremo più valori duplicati.
## cambiando il valore di 'Nome' per il primo record duplicatodf.iloc[1, 0] = 'Dio' df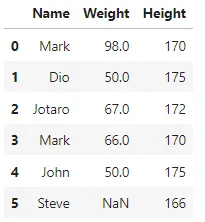
Abbiamo cambiato il valore di ‘Nome’ per il primo record duplicato. Ora, verifichiamo nuovamente se ci sono record duplicati presenti nei dati o meno.
df.duplicated()
Ora, non abbiamo più record duplicati.
Grazie per la lettura! Se hai qualche pensiero sull’articolo, fammelo sapere.
Stai avendo difficoltà a scegliere cosa leggere dopo? Non preoccuparti, conosco un articolo che penso troverai interessante.
Da Raw a Refined: Un viaggio attraverso la Preelaborazione dei Dati – Parte 2: Valori Mancanti
Perché occuparsi di valori mancanti?
pub.towardsai.net
e un altro…
Da Raw a Refined: Un viaggio attraverso la Preelaborazione dei Dati – Parte 1: Feature Scaling
A volte, i dati che riceviamo per i nostri compiti di apprendimento automatico non sono in un formato adatto per la codifica con Scikit-Learn…
pub.towardsai.net
Shivam Shinde
- Connettiti con me su LinkedIn
- Allo stesso modo, puoi seguirmi su VoAGI
Buona giornata!
Riferimenti:
Gestione dei valori duplicati in un DataFrame di Pandas
Come analista dei dati, è nostra responsabilità garantire l’integrità dei dati per ottenere informazioni accurate e affidabili. Dati…
stackabuse.com
Trova righe duplicate in un Dataframe basate su tutte o alcune colonne – GeeksforGeeks
Un portale di informatica per appassionati. Contiene informazioni ben scritte, ben pensate e ben spiegate sull’informatica…
www.geeksforgeeks.or
Metodo Pandas DataFrame duplicated()
W3Schools offre tutorial gratuiti online, riferimenti ed esercizi in tutti i principali linguaggi web. Copre…
www.w3schools.com






