NT-Xent (Normalized Temperature-Scaled Cross-Entropy) Loss spiegato ed implementato in PyTorch
Explanation and implementation of NT-Xent (Normalized Temperature-Scaled Cross-Entropy) Loss in PyTorch.
Un’intuizione sulla perdita NT-Xent con una spiegazione step-by-step dell’operazione e la nostra implementazione in PyTorch
Co-autore con Naresh Singh.

Introduzione
I recenti progressi nell’apprendimento auto-supervisionato e nell’apprendimento contrastivo hanno entusiasmato i ricercatori e i professionisti del Machine Learning (ML) a esplorare nuovamente questo spazio con rinnovato interesse.
In particolare, il paper SimCLR che presenta un semplice framework per l’apprendimento contrastivo di rappresentazioni visive ha suscitato molta attenzione nell’ambito dell’apprendimento auto-supervisionato e contrastivo.
L’idea centrale del paper è molto semplice: consentire al modello di apprendere se una coppia di immagini è stata derivata dalla stessa immagine iniziale o da immagini diverse.
- Comprendere la Policy Gradient costruendo Cross Entropy da zero
- Ricerca di similarità, Parte 1 kNN e Indice a File Invertito
- Svelare il Pattern di Progettazione delle Reti Neurali Informate dalla Fisica Parte 06
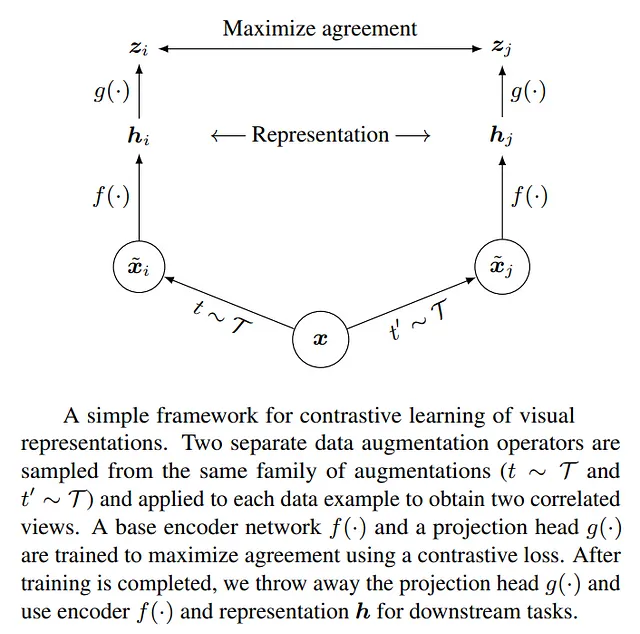
L’approccio SimCLR codifica ogni immagine di input i come un vettore di caratteristiche zi. Ci sono 2 casi da considerare:
- Coppie positive: la stessa immagine viene aumentata utilizzando un diverso set di aumenti e i vettori di caratteristiche risultanti zi e zj vengono confrontati. Questi vettori di caratteristiche sono costretti ad essere simili dalla funzione di perdita.
- Coppie negative: le immagini diverse vengono aumentate utilizzando un diverso set di aumenti e i vettori di caratteristiche risultanti zi e zk vengono confrontati. Questi vettori di caratteristiche sono costretti ad essere dissimili dalla funzione di perdita.
Il resto di questo articolo si concentrerà sulla spiegazione e la comprensione di questa funzione di perdita e sulla sua efficiente implementazione utilizzando PyTorch.
La perdita NT-Xent
A livello elevato, il modello di apprendimento contrastivo viene alimentato con 2N immagini, originanti da N immagini sottostanti. Ciascuna delle N immagini sottostanti viene aumentata utilizzando un set casuale di aumenti all’immagine per produrre 2 immagini aumentate. Ecco come otteniamo 2N immagini in un singolo batch di allenamento alimentato al modello.
Nelle sezioni seguenti, approfondiremo i seguenti aspetti della perdita NT-Xent.
- L’effetto della temperatura su SoftMax e Sigmoid
- Un’interpretazione semplice ed intuitiva della perdita NT-Xent
- Un’implementazione step-by-step di NT-Xent in PyTorch
- Motivazione per la necessità di una funzione di perdita multi-label (NT-BXent)
- Un’implementazione step-by-step di NT-BXent in PyTorch
Tutto il codice per i passaggi 2-5 può essere trovato in questo notebook. Il codice per il passaggio 1 può essere trovato in questo notebook.
L’effetto della temperatura su SoftMax e Sigmoid
Per comprendere tutte le parti in movimento della funzione di perdita contrastiva che studieremo in questo articolo, dobbiamo prima capire l’effetto della temperatura sulle funzioni di attivazione SoftMax e Sigmoid.
Di solito, la scala di temperatura viene applicata all’input di SoftMax o Sigmoid per levigare o accentuare l’output di quelle funzioni di attivazione. I logit di input vengono divisi per la temperatura prima di passare alle funzioni di attivazione. Puoi trovare tutto il codice per questa sezione in questo notebook.
SoftMax: Per SoftMax, una temperatura elevata riduce la varianza nella distribuzione di output che si traduce in una morbidezza delle etichette. Una temperatura bassa aumenta la varianza nella distribuzione di output e fa risaltare il valore massimo rispetto agli altri valori. Vedi i grafici qui sotto per l’effetto della temperatura su SoftMax quando viene alimentato con il tensore di input [0.1081, 0.4376, 0.7697, 0.1929, 0.3626, 2.8451].

Sigmoid: Per Sigmoid, una temperatura elevata produce una distribuzione di output che viene attratta verso 0.0, mentre una temperatura bassa allunga gli input a valori più alti, allungando gli output per avvicinarsi a 0.0 o 1.0 a seconda della magnitudo non firmata dell’input.
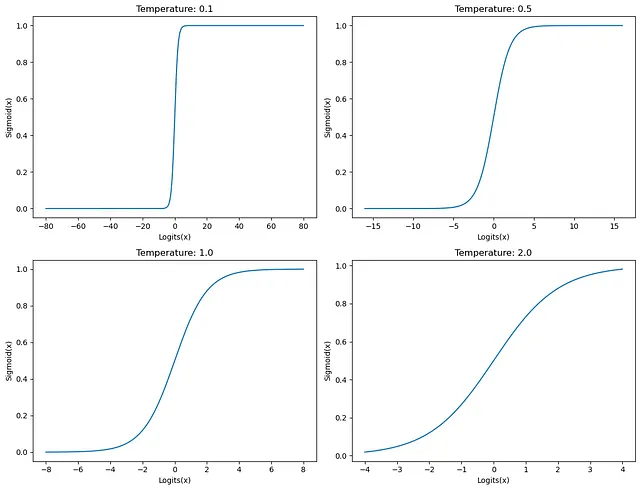
Ora che abbiamo capito l’effetto dei vari valori di temperatura sulle funzioni SoftMax e Sigmoid, vediamo come questo si applica alla nostra comprensione della perdita NT-Xent.
Interpretazione della perdita NT-Xent
La perdita NT-Xent è compresa comprendendo i singoli termini nel nome di questa perdita.
- Normalizzato: la similarità coseno produce un punteggio normalizzato nell’intervallo [-1.0 a +1.0]
- Scala di temperatura: la similarità coseno di tutte le coppie è scalata da una temperatura prima del calcolo della perdita di entropia incrociata
- Perdita di entropia incrociata: la perdita sottostante è una perdita di entropia incrociata multi-classe (singola-etichetta)
Come accennato sopra, assumiamo che per un batch di dimensioni 2N, i vettori di caratteristiche ai seguenti indici rappresentino le coppie positive (0, 1), (2, 3), (4, 5), (6, 7), … e il resto delle combinazioni rappresenti le coppie negative. Questo è un fattore importante da tenere a mente durante l’interpretazione della perdita NT-Xent poiché è correlata a SimCLR.
Ora che abbiamo capito cosa significano i termini nel contesto della perdita NT-Xent, diamo un’occhiata ai passaggi meccanici necessari per calcolare la perdita NT-Xent su un batch di vettori di caratteristiche.
- Il punteggio di similarità coseno di tutte le coppie viene calcolato per ciascuno dei 2N vettori prodotti dal modello SimCLR. Ciò produce (2N)² punteggi di similarità rappresentati come matrice 2N x 2N.
- I risultati di confronto tra lo stesso valore (i, i) vengono scartati (poiché una distribuzione è perfettamente simile a se stessa e non può permettere al modello di imparare nulla di utile).
- Ogni valore (similarità coseno) è scalato da un parametro di temperatura 𝜏 (che è un iper-parametro).
- La perdita di entropia incrociata viene applicata a ogni riga della matrice risultante sopra. Il paragrafo seguente spiega in modo più dettagliato.
- Tipicamente, la media di queste perdite (una perdita per elemento in un batch) viene utilizzata per la retropropagazione.
Il modo in cui viene utilizzata la perdita di entropia incrociata qui è semanticamente leggermente diverso da come viene utilizzata nelle normali attività di classificazione. Nelle attività di classificazione, viene addestrato un “classification head” finale per produrre un vettore di probabilità uno-hot per ogni input e calcoliamo la perdita di entropia incrociata su quel vettore di probabilità uno-hot poiché stiamo effettivamente calcolando la differenza tra 2 distribuzioni. Questo video spiega bellissimamente il concetto di perdita di entropia incrociata. Nella perdita NT-Xent, non c’è una corrispondenza 1:1 tra uno strato addestrabile e la distribuzione di output. Invece, viene calcolato un vettore di caratteristiche per ogni input e quindi viene calcolata la similarità coseno tra ogni coppia di vettori di caratteristiche. Il trucco qui è che poiché ogni immagine è simile esattamente a 1 altra immagine nel batch di input (coppia positiva) (se ignoriamo la similarità di un vettore di caratteristiche con se stesso), possiamo considerare questo come un ambiente simile alla classificazione in cui la distribuzione di probabilità di similarità tra immagini rappresenta un’attività di classificazione in cui una di esse sarà vicina a 1.0 e il resto sarà vicino a 0.0.
Ora che abbiamo una solida comprensione generale della perdita NT-Xent, dovremmo essere in ottima forma per implementare queste idee in PyTorch. Cominciamo!
Implementazione della perdita NT-Xent in PyTorch
Tutto il codice in questa sezione può essere trovato in questo notebook .
Riuso del codice : Molte implementazioni della perdita NT-Xent viste online implementano tutte le operazioni da zero. Inoltre, alcune di esse implementano la funzione di perdita in modo inefficiente, preferendo utilizzare cicli for anziché il parallelismo GPU . Invece, useremo un approccio diverso. Implementeremo questa perdita in termini della standard cross-entropy loss che PyTorch fornisce già. Per fare ciò, dobbiamo manipolare le previsioni e le etichette di verità terre in un formato che cross_entropy possa accettare. Vediamo come fare questo di seguito.
Tensore di previsione : Prima di tutto, dobbiamo creare un tensore PyTorch che rappresenterà l’output dal nostro modello di apprendimento contrastivo. Supponiamo che la nostra dimensione batch sia 8 (2N=8), e i nostri vettori di caratteristiche hanno 2 dimensioni (2 valori). Chiameremo la nostra variabile di input “x”.
x = torch.randn(8, 2)Similarità coseno : Successivamente, calcoleremo la similarità coseno a coppie tra ogni vettore di caratteristiche in questo batch e memorizzeremo il risultato nella variabile chiamata “xcs”. Se la riga sotto sembra confusa, si prega di leggere i dettagli su questa pagina . Questo è il passaggio “normalize”.
xcs = F.cosine_similarity(x[None,:,:], x[:,None,:], dim=-1)Come già detto, dobbiamo ignorare il punteggio di autosimilarità di ogni vettore di caratteristiche poiché non contribuisce all’apprendimento del modello e sarà un fastidio superfluo in seguito quando vogliamo calcolare la perdita di cross-entropia. A tal fine, definiremo una variabile “eye” che è una matrice con gli elementi sulla diagonale principale che hanno un valore di 1.0 e il resto è 0.0. Possiamo creare una tale matrice usando il seguente comando.
eye = torch.eye(8)Ora convertiamo questa in una matrice booleana in modo da poter indicizzare la variabile “xcs” utilizzando questa matrice di maschera.
eye = eye.bool()Cloniamo il tensore “xcs” in un tensore chiamato “y” in modo da poter fare riferimento al tensore “xcs” in seguito.
y = xcs.clone()Ora, impostiamo i valori lungo la diagonale principale della matrice di similarità coseno a coppie su -inf in modo che quando calcoliamo il softmax su ogni riga, questo valore non contribuirà a nulla.
y[eye] = float("-inf")Il tensore “y” scalato da un parametro di temperatura sarà uno degli input (previsioni) all’API di perdita di cross-entropia in PyTorch. Successivamente, dobbiamo calcolare le etichette di verità terra (target) che dobbiamo alimentare all’API di perdita di cross-entropia.
Tensore di etichette di verità terre (Target) : Per l’esempio che stiamo usando (2N=8), questo è ciò che dovrebbe apparire il tensore di verità terra.
tensor([1, 0, 3, 2, 5, 4, 7, 6])
Questo perché le seguenti coppie di indice nel tensore “y” contengono coppie positive.
(0, 1), (1, 0)
(2, 3), (3, 2)
(4, 5), (5, 4)
(6, 7), (7, 6)
Per interpretare le coppie di indice sopra, guardiamo a un singolo esempio. La coppia (4, 5) significa che la colonna 5 alla riga 4 dovrebbe essere impostata su 1.0 (coppia positiva), che è ciò che il tensore sopra sta dicendo anche. Fantastico!
Per creare il tensore sopra, possiamo usare il seguente codice PyTorch, che memorizza le etichette di verità terre nella variabile “target”.
target = torch.arange(8)target[0::2] += 1target[1::2] -= 1Loss cross-entropy: abbiamo tutti gli ingredienti di cui abbiamo bisogno per calcolare la nostra perdita! L’unica cosa che rimane da fare è chiamare l’API cross_entropy in PyTorch.
loss = F.cross_entropy(y / temperatura, target, reduction="mean")La variabile “loss” contiene ora la perdita NT-Xent calcolata. Riassumiamo tutto il codice in una singola funzione Python qui sotto.
def nt_xent_loss(x, temperature): assert len(x.size()) == 2 # Similarità coseno xcs = F.cosine_similarity(x[None,:,:], x[:,None,:], dim=-1) xcs[torch.eye(x.size(0)).bool()] = float("-inf") # Etichette verità fondamentali target = torch.arange(8) target[0::2] += 1 target[1::2] -= 1 # Perdita standard di cross-entropia return F.cross_entropy(xcs / temperature, target, reduction="mean")Il codice sopra funziona fintanto che ogni vettore di funzionalità ha esattamente una coppia positiva nel batch quando si addestra il nostro modello di apprendimento contrastivo. Vediamo come gestire più coppie positive in un compito di apprendimento contrastivo.
Una perdita multi-etichetta per l’apprendimento contrastivo: NT-BXent
Nel paper SimCLR, ogni immagine i ha esattamente 1 coppia simile all’indice j. Ciò rende la perdita di entropia incrociata una scelta perfetta per il compito poiché assomiglia a un problema multi-classe. Tuttavia, se abbiamo M > 2 aumenti della stessa immagine alimentati nel singolo batch di addestramento del modello di apprendimento contrastivo, ogni batch avrà M-1 coppie simili di immagine per l’immagine i. Questo compito assomiglierebbe a un problema multi-etichetta.
La scelta ovvia sarebbe sostituire la perdita di entropia incrociata con la perdita di entropia incrociata binaria. Quindi il nome perdita di NT-BXent, che sta per perdita normalizzata di entropia incrociata binaria scalata dalla temperatura.
La formulazione qui sotto mostra la perdita Li per l’elemento i. La σ nella formula qui sotto sta per la funzione Sigmoid.
Per evitare il problema dell’equilibrio delle classi, pesiamo le coppie positive e negative dall’inverso del numero di coppie positive e negative nel nostro mini-batch. La perdita finale nel mini-batch utilizzato per la retropropagazione sarà la media delle perdite di ogni campione nel nostro mini-batch.
Successivamente, concentriamo la nostra attenzione sulla nostra implementazione della perdita NT-BXent in PyTorch.
Implementazione della perdita NT-BXent in PyTorch
Tutto il codice in questa sezione può essere trovato in questo notebook.
Riutilizzo del codice: Come per la nostra implementazione della perdita NT-Xent, riutilizzeremo il metodo di perdita di entropia incrociata binaria (BCE) fornito da PyTorch. L’impostazione delle nostre etichette di verità fondamentali sarà simile a quella di un problema di classificazione multi-etichetta in cui viene utilizzata la perdita BCE.
Tensore di previsione: useremo lo stesso tensore di previsione (8, 2) che abbiamo usato per l’implementazione della perdita NT-Xent.
x = torch.randn(8, 2)Similarità coseno: poiché il tensore di input x è lo stesso, il tensore di similarità coseno tra tutte le coppie xcs sarà anche lo stesso. Si prega di consultare questa pagina per una spiegazione dettagliata di ciò che fa la riga qui sotto.
xcs = F.cosine_similarity(x[None,:,:], x[:,None,:], dim=-1)Per assicurarsi che la perdita dall’elemento in posizione (i, i) sia 0, dovremo eseguire alcune acrobazie per far sì che il tensore xcs contenga un valore 1 in ogni indice (i, i) dopo che Sigmoid gli è stato applicato. Poiché useremo la perdita BCE, segneremo il punteggio di auto-similarità di ogni vettore di funzionalità con il valore infinito nel tensore xcs. Questo perché l’applicazione della funzione sigmoid sul tensore xcs, convertirà l’infinito nel valore 1, e configureremo le nostre etichette di verità fondamentali in modo che ogni posizione (i, i) nelle etichette di verità fondamentali abbia il valore 1.
Creiamo un tensore di mascheramento che ha il valore Vero lungo la diagonale principale (xcs ha punteggi di auto-similarità lungo la diagonale principale) e Falso ovunque altro.
eye = torch.eye(8).bool()Cloniamo il tensore “xcs” in un tensore chiamato “y” in modo da poter fare riferimento al tensore “xcs” in seguito.
y = xcs.clone()Ora, impostiamo i valori lungo la diagonale principale della matrice di similarità coseno a tutte le coppie su infinito in modo che quando calcoliamo la sigmoide su ogni riga, otteniamo 1 in queste posizioni.
y[eye] = float("inf")Il tensore “y” scalato da un parametro di temperatura sarà uno dei dati di input (previsioni) per l’API di perdita BCE in PyTorch. Successivamente, dobbiamo calcolare le etichette di verità fondamentale (target) che dobbiamo fornire all’API di perdita BCE.
Etichette di verità fondamentale (tensore target): ci aspettiamo che l’utente ci passi la coppia di tutte le coppie di indici (x, y) che contengono esempi positivi. Questo è un cambiamento rispetto a quello che abbiamo fatto per la perdita NT-Xent, poiché le coppie positive erano implicite, mentre qui le coppie positive sono esplicite.
Oltre alle posizioni fornite dall’utente, impostiamo tutti gli elementi diagonali come coppie positive come spiegato sopra. Utilizzeremo l’API di indicizzazione dei tensori di PyTorch per prendere tutti gli elementi in quelle posizioni e impostarli a 1, mentre il resto viene inizializzato a 0.
target = torch.zeros(8, 8)pos_indices = torch.tensor([ (0, 0), (0, 2), (0, 4), (1, 4), (1, 6), (1, 1), (2, 3), (3, 7), (4, 3), (7, 6),])# Aggiungere gli indici della diagonale principale come indici positivi.# Questo sarà utile poiché useremo BCELoss in PyTorch,# che si aspetterà un valore per gli elementi sulla diagonale principale.pos_indices = torch.cat([pos_indices, torch.arange(8).reshape(8, 1).expand(-1, 2)], dim=0)# Impostare i valori nel vettore target a 1.target[pos_indices[:,0], pos_indices[:,1]] = 1Perdita di entropia incrociata binaria (BCE): a differenza della perdita NT-Xent, non possiamo semplicemente chiamare la funzione torch.nn.functional.binary_cross_entropy_function, poiché vogliamo pesare la perdita positiva e negativa in base a quante coppie positive e negative ha l’elemento all’indice i nel mini-batch corrente.
Il primo passo consiste comunque nel calcolare la perdita BCE elemento per elemento.
temperature = 0.1loss = F.binary_cross_entropy((y / temperature).sigmoid(), target, reduction="none")Crea un maschera binaria di coppie positive e negative e quindi crea 2 tensori, loss_pos e loss_neg, che contengono solo quegli elementi dalla perdita calcolata che corrispondono alle coppie positive e negative.
target_pos = target.bool()target_neg = ~target_pos# loss_pos e loss_neg di seguito contengono valori diversi da zero solo per quegli elementi# che sono coppie positive e coppie negative rispettivamente.loss_pos = torch.zeros(x.size(0), x.size(0)).masked_scatter(target_pos, loss[target_pos])loss_neg = torch.zeros(x.size(0), x.size(0)).masked_scatter(target_neg, loss[target_neg])Successivamente, sommiamo la perdita della coppia positiva e negativa (separatamente) corrispondente a ciascun elemento i nel nostro mini-batch.
# loss_pos e loss_neg contengono ora la somma delle perdite della coppia positiva e negativa# come calcolato rispetto all'input i.loss_pos = loss_pos.sum(dim=1)loss_neg = loss_neg.sum(dim=1)Per eseguire la ponderazione, dobbiamo tenere traccia del numero di coppie positive e negative corrispondenti a ciascun elemento i nel nostro mini-batch. I tensori “num_pos” e “num_neg” memorizzeranno questi valori.
# num_pos e num_neg di seguito contengono il numero di coppie positive e negative# calcolato rispetto all'input i. In un contesto reale, questo numero dovrebbe# essere lo stesso per ogni elemento di input, ma lo lasciamo variare qui per massima# flessibilità.num_pos = target.sum(dim=1)num_neg = target.size(0) - num_posAbbiamo tutti gli ingredienti necessari per calcolare la nostra perdita! L’unica cosa che dobbiamo fare è pesare la perdita positiva e negativa in base al numero di coppie positive e negative, e quindi calcolare la media della perdita in tutto il mini-batch.
def nt_bxent_loss(x, pos_indices, temperature): assert len(x.size()) == 2 # Aggiungi gli indici degli elementi della diagonale principale a pos_indices pos_indices = torch.cat([ pos_indices, torch.arange(x.size(0)).reshape(x.size(0), 1).expand(-1, 2), ], dim=0) # Etichette di verità fondamentale target = torch.zeros(x.size(0), x.size(0)) target[pos_indices[:,0], pos_indices[:,1]] = 1.0 # Similarità cosinale xcs = F.cosine_similarity(x[None,:,:], x[:,None,:], dim=-1) # Imposta il logit dell'elemento diagonale su "inf" che indica una completa # correlazione. sigmoid(inf) = 1.0, quindi funzionerà perfettamente # quando si calcola la Binary cross-entropy Loss. xcs[torch.eye(x.size(0)).bool()] = float("inf") # Standard binary cross-entropy loss. Usiamo binary_cross_entropy() qui e non # binary_cross_entropy_with_logits() a causa di # https://github.com/pytorch/pytorch/issues/102894 # Il metodo *_with_logits() utilizza il trucco del log-sum-exp, che causa inf e -inf # a risultare in un risultato NaN. loss = F.binary_cross_entropy((xcs / temperature).sigmoid(), target, reduction="none") target_pos = target.bool() target_neg = ~target_pos loss_pos = torch.zeros(x.size(0), x.size(0)).masked_scatter(target_pos, loss[target_pos]) loss_neg = torch.zeros(x.size(0), x.size(0)).masked_scatter(target_neg, loss[target_neg]) loss_pos = loss_pos.sum(dim=1) loss_neg = loss_neg.sum(dim=1) num_pos = target.sum(dim=1) num_neg = x.size(0) - num_pos return ((loss_pos / num_pos) + (loss_neg / num_neg)).mean()pos_indices = torch.tensor([ (0, 0), (0, 2), (0, 4), (1, 4), (1, 6), (1, 1), (2, 3), (3, 7), (4, 3), (7, 6),])for t in (0.01, 0.1, 1.0, 10.0, 20.0): print(f"Temperatura: {t:5.2f}, Perdita: {nt_bxent_loss(x, pos_indices, temperature=t)}")Stampa.
Temperatura: 0.01, Perdita: 62.898780822753906
Temperatura: 0.10, Perdita: 4.851151943206787
Temperatura: 1.00, Perdita: 1.0727109909057617
Temperatura: 10.00, Perdita: 0.9827173948287964
Temperatura: 20.00, Perdita: 0.982099175453186
Conclusione
L’apprendimento auto-supervisionato è un campo emergente nel deep learning e consente di addestrare modelli su dati non etichettati. Questa tecnica ci consente di lavorare senza la necessità di dati etichettati su larga scala.
In questo articolo, abbiamo appreso le funzioni di perdita per l’apprendimento contrastivo. La prima, chiamata perdita NT-Xent, viene utilizzata per l’apprendimento su una singola coppia positiva per input in un mini-batch. Abbiamo introdotto la perdita NT-BXent che viene utilizzata per l’apprendimento su più (> 1) coppie positive per input in un mini-batch. Abbiamo imparato a interpretarle in modo intuitivo, basandoci sulla nostra conoscenza della perdita di cross-entropia e della perdita di binary cross-entropy. Infine, le abbiamo implementate entrambe in modo efficiente in PyTorch.





