Word2Vec, GloVe e FastText, spiegati
Explain Word2Vec, GloVe, and FastText.
Come i computer comprendono le parole
I computer non comprendono le parole come noi. Preferiscono lavorare con i numeri. Quindi, per aiutare i computer a comprendere le parole e i loro significati, utilizziamo qualcosa chiamato embedding. Questi embedding rappresentano numericamente le parole come vettori matematici.
La cosa interessante di questi embedding è che se li apprendiamo correttamente, le parole che hanno significati simili avranno valori numerici simili. In altre parole, i loro numeri saranno più vicini tra loro. Ciò consente ai computer di comprendere le connessioni e le similitudini tra diverse parole in base alle loro rappresentazioni numeriche.
Uno dei metodi più noti per apprendere gli embedding delle parole è Word2Vec. In questo articolo, approfondiremo le complessità di Word2Vec ed esploreremo le sue diverse architetture e varianti.
Word2Vec
Nei primi tempi, le frasi erano rappresentate con vettori n-gram. Questi vettori avevano lo scopo di catturare l’essenza di una frase considerando sequenze di parole. Tuttavia, avevano alcune limitazioni. I vettori n-gram erano spesso grandi e sparsi, il che li rendeva computazionalmente difficili da creare. Ciò ha creato un problema noto come la maledizione della dimensionalità. Essenzialmente, questo significava che in spazi ad alta dimensionalità, i vettori che rappresentavano le parole erano così lontani l’uno dall’altro che diventava difficile determinare quali parole erano veramente simili.
- Lo zaino che risolve il bias di ChatGPT i modelli di linguaggio Backpack sono metodi AI alternativi per i transformer.
- Impara una lingua velocemente con ChatGPT (Tutor di lingua gratuito)
- WAYVE presenta GAIA-1 un nuovo modello di intelligenza artificiale generativa per l’autonomia che crea video di guida realistici sfruttando input video, testo e azione.
Poi, nel 2003, si è verificato un notevole progresso con l’introduzione di un modello di linguaggio probabilistico neurale. Questo modello ha completamente cambiato il modo in cui rappresentiamo le parole utilizzando qualcosa chiamato vettori densi continui. A differenza dei vettori n-gram, che erano discreti e sparsi, questi vettori densi offrivano una rappresentazione continua. Anche piccoli cambiamenti in questi vettori hanno portato a rappresentazioni significative, sebbene potrebbero non corrispondere direttamente a parole inglesi specifiche.
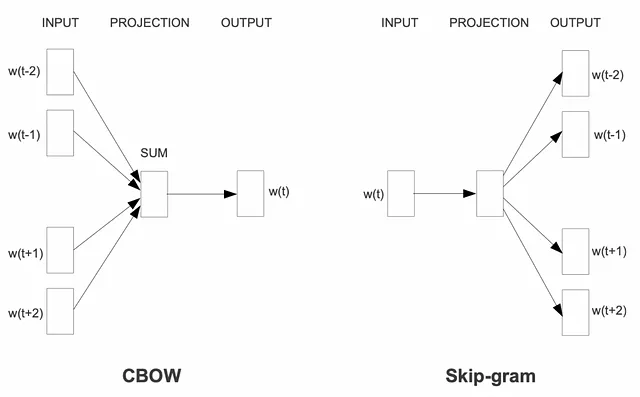
Basandosi su questi entusiasmanti progressi, è emerso nel 2013 il framework Word2Vec. Ha presentato un potente metodo per codificare i significati delle parole in vettori densi continui. All’interno di Word2Vec, sono state introdotte due architetture principali: Continuous Bag of Words (CBoW) e Skip-gram.
Queste architetture hanno aperto le porte a modelli di formazione efficienti capaci di generare embedding di parole di alta qualità. Sfruttando vaste quantità di dati di testo, Word2Vec ha portato le parole alla vita nel mondo numerico. Ciò ha permesso ai computer di comprendere i significati contestuali e le relazioni tra le parole, offrendo un approccio trasformativo all’elaborazione del linguaggio naturale.
Continuous Bag-of-Words (CBoW)
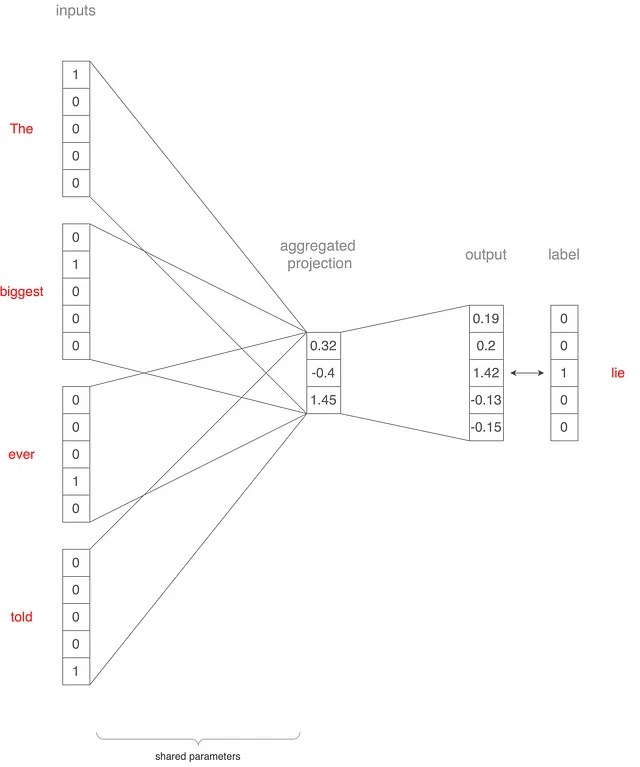
In questa sezione e nella successiva, capiamo come i modelli CBoW e skip-gram vengono addestrati utilizzando un vocabolario ridotto di cinque parole: più grande, mai, bugia, raccontata e la. E abbiamo una frase di esempio “La più grande bugia mai raccontata”. Come passeremmo questa frase all’architettura CBoW? Questo è mostrato nella Figura 2 sopra, ma descriveremo anche il processo.
Supponiamo di impostare la dimensione della finestra di contesto su 2. Prendiamo le parole “La,” “più grande,” “mai” e “raccontata” e le convertiamo in vettori one-hot 5×1.
Questi vettori vengono quindi passati come input al modello e mappati in uno strato di proiezione. Diciamo che questo strato di proiezione ha una dimensione di 3. Il vettore di ogni parola viene moltiplicato per una matrice di peso 5×3 (condivisa tra gli input), risultando in quattro vettori 3×1. La media di questi vettori ci dà un singolo vettore 3×1. Questo vettore viene quindi proiettato nuovamente su un vettore 5×1 utilizzando un’altra matrice di peso 3×5.
Questo vettore finale rappresenta la parola centrale “bugia”. Calcolando il vero vettore one hot e il vettore di output effettivo, otteniamo una perdita che viene utilizzata per aggiornare i pesi della rete tramite la retropropagazione.
Ripetiamo questo processo facendo scorrere la finestra di contesto e applicandola successivamente a migliaia di frasi. Dopo che l’addestramento è completo, il primo livello del modello, con dimensioni 5×3 (dimensione del vocabolario x dimensione della proiezione), contiene i parametri appresi. Questi parametri vengono utilizzati come tabella di ricerca per mappare ogni parola alla sua corrispondente rappresentazione vettoriale.
Skip-gram
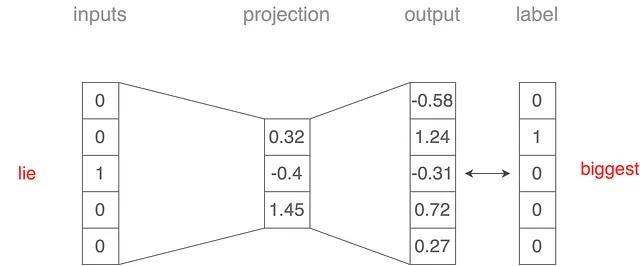
Nel modello skip-gram, utilizziamo un’architettura simile a quella del caso continuous bag-of-words (CBoW). Tuttavia, invece di prevedere la parola target basandosi sulle parole circostanti, invertiamo lo scenario come mostrato nella Figura 3. Ora, la parola “lie” diventa l’input e miriamo a prevedere le sue parole di contesto. Il nome “skip-gram” riflette questo approccio, poiché prevediamo le parole di contesto che possono “saltare” alcune parole.
Per illustrare questo, consideriamo alcuni esempi:
- La parola di input “lie” è accoppiata con la parola di output “the”.
- La parola di input “lie” è accoppiata con la parola di output “biggest”.
- La parola di input “lie” è accoppiata con la parola di output “ever”.
- La parola di input “lie” è accoppiata con la parola di output “told”.
Ripetiamo questo processo per tutte le parole nei dati di addestramento. Una volta completato l’addestramento, i parametri del primo livello, con dimensioni della dimensione del vocabolario x della dimensione della proiezione, catturano le relazioni tra le parole di input e le loro corrispondenti rappresentazioni vettoriali. Questi parametri appresi ci consentono di mappare una parola di input alla sua rispettiva rappresentazione vettoriale nel modello skip-gram.
Vantaggi
- Supera la maledizione della dimensionalità con semplicità: Word2Vec fornisce una soluzione semplice ed efficiente alla maledizione della dimensionalità. Rappresentando le parole come vettori densi, riduce la sparsità e la complessità computazionale associate ai metodi tradizionali come i vettori n-gram.
- Genera vettori in modo che le parole più vicine nel significato abbiano valori vettoriali più vicini: le embedding di Word2Vec presentano una proprietà preziosa in cui le parole con significati simili sono rappresentate da vettori che sono più vicini in valore numerico. Ciò consente di catturare relazioni semantiche e di svolgere attività come la similarità delle parole e la rilevazione delle analogie.
- Embedding preaddestrate per varie applicazioni di NLP: le embedding preaddestrate di Word2Vec sono ampiamente disponibili e possono essere utilizzate in una serie di applicazioni di elaborazione del linguaggio naturale (NLP). Queste embedding, addestrate su grandi corpora, rappresentano una risorsa preziosa per attività come l’analisi dei sentimenti, il riconoscimento delle entità nominate, la traduzione automatica e altro ancora.
- Cornice auto-supervisionata per l’incremento dei dati e l’addestramento: Word2Vec opera in modo auto-supervisionato, sfruttando i dati esistenti per apprendere le rappresentazioni delle parole. Ciò rende facile raccogliere più dati e addestrare il modello, poiché non richiede insiemi di dati etichettati estesi. La struttura può essere applicata a grandi quantità di testo non etichettato, migliorando il processo di addestramento.
Svantaggi
- Limitata preservazione delle informazioni globali: le embedding di Word2Vec si concentrano principalmente sulla cattura delle informazioni di contesto locale e potrebbero non preservare le relazioni globali tra le parole. Questa limitazione può influire sulle attività che richiedono una comprensione più ampia del testo, come la classificazione dei documenti o l’analisi dei sentimenti a livello di documento.
- Meno adatto per le lingue morfologicamente ricche: le lingue morfologicamente ricche, caratterizzate da forme di parole e inflessioni complesse, possono rappresentare una sfida per Word2Vec. Poiché Word2Vec tratta ogni parola come un’unità atomica, potrebbe avere difficoltà a catturare la morfologia ricca e le sfumature semantiche presenti in tali lingue.
- Mancanza di consapevolezza del contesto ampio: i modelli di Word2Vec considerano solo una finestra di contesto locale di parole circostanti la parola target durante l’addestramento. Questa consapevolezza di contesto limitata potrebbe comportare una comprensione incompleta dei significati delle parole in determinati contesti. Potrebbe avere difficoltà a catturare dipendenze a lungo raggio e intricate relazioni semantiche presenti in alcuni fenomeni linguistici.
Nelle sezioni seguenti, vedremo alcune architetture di embedding di parole che aiutano a affrontare questi svantaggi.
GloVe: Vettori globali
I metodi di Word2Vec sono stati efficaci nella cattura del contesto locale in una certa misura, ma non sfruttano appieno il contesto globale disponibile nel corpus. Il contesto globale si riferisce all’utilizzo di più frasi in tutto il corpus per raccogliere informazioni. Qui entra in gioco GloVe, poiché sfrutta la co-occorrenza parola-parola per apprendere le embedding delle parole.
Il concetto di matrice di co-occorrenza parola-parola è fondamentale per Glove. Si tratta di una matrice che cattura le occorrenze di ogni parola nel contesto di ogni altra parola nel corpus. Ogni cella nella matrice rappresenta il conteggio delle occorrenze di una parola nel contesto di un’altra parola.
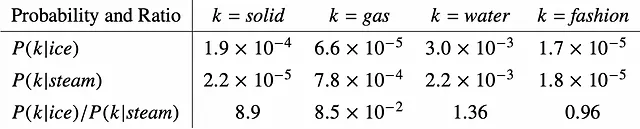
Invece di lavorare direttamente con le probabilità di co-occorrenza come in Word2Vec, Glove parte dai rapporti delle probabilità di co-occorrenza. Nel contesto della Figura 4, P( k | ice ) rappresenta la probabilità che la parola k occorra nel contesto della parola “ice”, mentre P( k | steam ) rappresenta la probabilità che la parola k occorra nel contesto della parola “steam”. Confrontando il rapporto P( k | ice ) / P( k | steam ), possiamo determinare l’associazione della parola k con ice o steam. Se il rapporto è molto maggiore di 1, indica una forte associazione con ice. Al contrario, se il rapporto è più vicino a 0, suggerisce una forte associazione con steam. Un rapporto più vicino a 1 implica che non ci sia un’associazione chiara né con ice né con steam.
Ad esempio, quando k = “solid”, il rapporto di probabilità è molto maggiore di 1, indicando una forte associazione con ice. D’altra parte, quando k = “gas”, il rapporto di probabilità è molto più vicino a 0, suggerendo una forte associazione con steam. Per quanto riguarda le parole “water” e “fashion”, non mostrano un’associazione chiara né con ice né con steam.
L’associazione di parole basata sui rapporti di probabilità è esattamente ciò che miriamo a ottenere. E questo è ottimizzato durante l’apprendimento delle embedding con GloVe.
FastText
Le architetture tradizionali di word2vec, oltre a non utilizzare le informazioni globali, non gestiscono efficacemente le lingue che sono morfologicamente ricche.
Cosa significa che una lingua è morfologicamente ricca? In tali lingue, una parola può cambiare forma in base al contesto in cui viene utilizzata. Prendiamo ad esempio una lingua del Sud dell’India chiamata “Kannada”.
In Kannada, la parola per “casa” è scritta come ಮನೆ (mane). Tuttavia, quando diciamo “nella casa”, diventa ಮನೆಯಲ್ಲಿ (maneyalli), e quando diciamo “dalla casa”, cambia in ಮನೆಯಿಂದ (maneyinda). Come si può vedere, cambia solo la preposizione, ma le parole tradotte hanno forme diverse. In inglese, sono tutte semplicemente “casa”. Di conseguenza, le architetture tradizionali di word2vec mapperebbero tutte queste varianti allo stesso vettore. Tuttavia, se dovessimo creare un modello word2vec per Kannada, che è morfologicamente ricca, ogni di questi tre casi verrebbe assegnato a vettori diversi. Inoltre, la parola “casa” in Kannada può assumere molte più forme rispetto a questi tre esempi. Poiché il nostro corpus potrebbe non contenere tutte queste variazioni, l’addestramento tradizionale di word2vec potrebbe non catturare tutte le diverse rappresentazioni delle parole.
Per affrontare questo problema, FastText introduce una soluzione considerando le informazioni di sotto-parola durante la generazione di vettori di parole. Invece di trattare ogni parola come un’entità unica, FastText suddivide le parole in n-grammi di caratteri, che vanno da tri-grammi a 6-grammi. Questi n-grammi vengono quindi mappati in vettori, che vengono successivamente aggregati per rappresentare l’intera parola. Questi vettori aggregati vengono quindi alimentati in un’architettura skip-gram.
Questo approccio consente il riconoscimento di caratteristiche condivise tra diverse forme di parole all’interno di una lingua. Anche se potremmo non aver visto ogni singola forma di una parola nel corpus, i vettori appresi catturano le somiglianze e le caratteristiche comuni tra queste forme. Le lingue morfologicamente ricche, come l’arabo, il turco, il finlandese e varie lingue indiane, possono beneficiare della capacità di FastText di generare vettori di parole che tengono conto di diverse forme e variazioni.
Consapevolezza del contesto
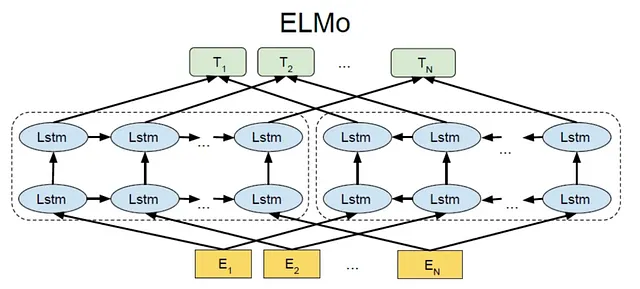
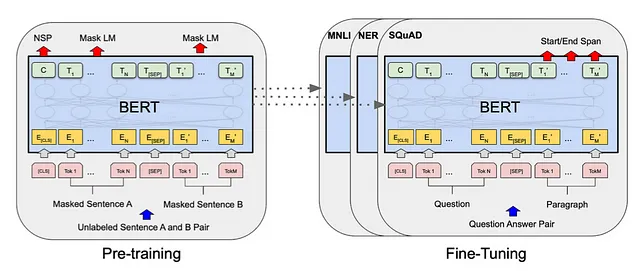
Nonostante i suoi vantaggi, le architetture word2vec menzionate hanno una limitazione: generano la stessa rappresentazione vettoriale per una determinata parola, indipendentemente dal suo contesto.
Per illustrare questo punto, consideriamo le seguenti due frasi:
- “That drag queen slays.”
- “She has an ace and queen for a perfect hand.”
In queste frasi, la parola “queen” ha significati diversi. Tuttavia, nelle architetture word2vec, i vettori per “queen” in entrambi i casi sarebbero gli stessi. Questo non è ideale perché vogliamo che i vettori delle parole catturino e rappresentino significati diversi basati sui loro contesti.
Per risolvere questo problema, sono state introdotte architetture più avanzate come le celle LSTM. Queste architetture sono state progettate per incorporare informazioni contestuali nelle rappresentazioni delle parole. Nel tempo, sono emersi modelli basati sui trasformatori come BERT e GPT, portando allo sviluppo dei modelli linguistici su larga scala che vediamo oggi. Questi modelli eccellono nel considerare il contesto e generare rappresentazioni delle parole sensibili alle parole e alle frasi circostanti.
Considerando il contesto, queste architetture avanzate consentono la creazione di vettori di parole più sfumati e significativi, garantendo che la stessa parola possa avere diverse rappresentazioni vettoriali a seconda del suo contesto specifico.
Conclusione
In conclusione, questo post del blog fornisce approfondimenti sull’architettura word2vec e sulla sua capacità di rappresentare le parole utilizzando vettori densi continui. Implementazioni successive come GloVe hanno capitalizzato il contesto globale, mentre FastText ha consentito l’apprendimento efficiente di vettori per lingue morfologicamente ricche come l’arabo, il finlandese e varie lingue indiane. Tuttavia, un inconveniente comune tra questi approcci è che assegnano lo stesso vettore a una parola indipendentemente dal suo contesto durante l’infrazione, il che può ostacolare la rappresentazione accurata delle parole con significati multipli.
Per risolvere questa limitazione, gli sviluppi successivi in NLP hanno introdotto le celle LSTM e le architetture dei trasformatori, che eccellono nel catturare il contesto specifico e sono diventate la base per i moderni modelli linguistici su larga scala. Questi modelli hanno la capacità di comprendere e generare rappresentazioni delle parole che variano in base al loro contesto circostante, accogliendo i significati sfumati delle parole in diverse situazioni.
Tuttavia, è importante riconoscere che il framework word2vec rimane significativo, poiché continua a alimentare numerose applicazioni nel campo del processing del linguaggio naturale. La sua semplicità e la capacità di generare rappresentazioni vettoriali delle parole significative hanno dimostrato di essere preziose, nonostante le sfide poste dalle variazioni contestuali nei significati delle parole.
Per ulteriori informazioni sui modelli linguistici, controlla questa playlist di YouTube.
Buon apprendimento!