Quanto è male essere avidi?
Essere avidi è molto male?
Esplorazione di una soluzione golosa al problema di taglio delle scorte
Contenuti
- Motivazione del problema di taglio delle scorte
- Breve panoramica dei problemi NP-Hard
- Codifica del problema di taglio delle scorte in Python
- L’algoritmo goloso
- Confronto con la ricerca esaustiva in uno spazio n ridotto
- Confronto con la ricerca casuale in uno spazio n più ampio
- Conclusioni
Motivazione del problema di taglio delle scorte
Sono un data scientist di professione. Sebbene le mie competenze in data science siano molto importanti sul lavoro (per definizione), trovo che i concetti di data science aiutino a risolvere molti problemi anche al di fuori del lavoro!
Uno dei modi in cui le mie competenze di data science sono utili è nel mio hobby di fai-da-te/creazione. Una sfida comune è sapere come pianificare il taglio del materiale. Ho una lista di tagli che devo effettuare da più pezzi di materiale delle stesse dimensioni acquistati in negozio. Come si pianificano i tagli in modo da sprecare il meno possibile? Questa sfida è conosciuta come “Problema di taglio delle scorte”. Come si scopre, può essere un problema davvero difficile da risolvere, NP-Hard per la precisione!
- Incontra LoraHub un framework AI strategico per la composizione di moduli LoRA (Adattamenti a basso rango) addestrati su diverse attività al fine di ottenere prestazioni adattabili su nuove attività.
- Come ho costruito un linguaggio di programmazione Il (difficile) cammino verso il successo
- Riconoscimento della lingua parlata su Mozilla Common Voice – Parte I.
In questo articolo, esplorerò una “scorciatoia” (gioco di parole inteso) per risolvere questo problema e analizzerò come questo metodo si confronta con il modo più lungo.

Breve panoramica dei problemi NP-Hard
Qui non entrerò molto in profondità sui problemi NP-Hard, ma voglio dare un’idea su di essi. Ciò che rende un problema di ottimizzazione difficile è tipicamente la dimensione del suo spazio delle soluzioni. Quante soluzioni possibili devi esplorare per trovare la migliore? La difficoltà di un problema di solito viene valutata da quanto velocemente cresce lo spazio delle soluzioni all’aumentare della dimensione del problema.
Per il “Problema di taglio delle scorte”, il problema diventa più grande, molto più grande, aggiungendo più tagli. Vedi quanto velocemente cresce lo spazio delle soluzioni qui sotto!
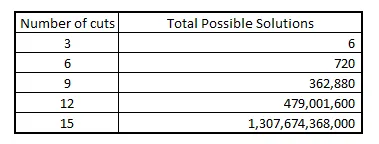
Lo spazio delle soluzioni cresce in modo fattoriale, il che significa che il numero totale di soluzioni che devono essere cercate per essere sicuri della risposta ottimale è n!, il quale, come vedi, diventa molto grande, molto rapidamente.
NP sta per “non deterministico polinomiale”, il che significa che il problema cresce più velocemente di qualsiasi funzione polinomiale. Ci sono un sacco di risorse che approfondiscono i problemi NP/NP-hard. Questo è tutto ciò di cui parlerò qui.
Codifica del problema di taglio delle scorte in Python
Il problema di taglio delle scorte si riduce essenzialmente a un problema di ordinamento. Si effettuano i tagli in un ordine specifico e quando si esaurisce la lunghezza di un pezzo di materiale, si inizia a tagliare (sempre nello stesso ordine) sul pezzo di materiale successivo.
- Una visualizzazione spiega meglio questo concetto. Supponiamo di avere questo ordine di tagli
- [4′, 2′, 1′, 2′, 2′, 1′] e abbiamo pezzi di materiale di dimensione 5′. Il calcolo degli sprechi appare così:
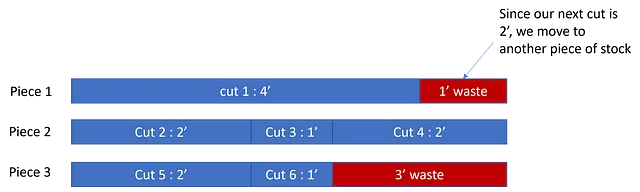
In questo caso abbiamo uno spreco totale di 4′.
Tuttavia, se cambiamo l’ordine (mantenendo tutti i tagli uguali), possiamo ottenere diversi livelli di spreco. Proviamo con [4′, 1′, 2′, 2′, 1′, 2′]:
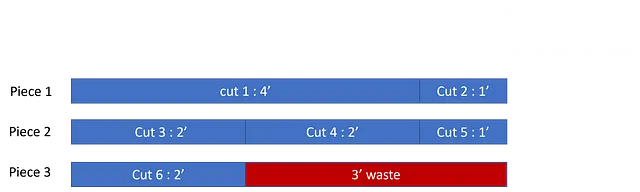
Qui, otteniamo solo 3′ di rifiuti – semplicemente cambiando l’ordine abbiamo ridotto i nostri rifiuti! Questa è l’intera idea di questo problema di ottimizzazione. Vogliamo trovare quale ordine dei tagli è il migliore.
Ora, per codificare questo in uno script Python, abbiamo bisogno di (1) funzioni per calcolare i rifiuti di ogni ordine e (2) un algoritmo per ordinare le liste in ordini ottimali.
La funzione per calcolare i rifiuti riproduce semplicemente la logica descritta sopra. Ecco il codice Python:
def total_waste(stock_size, solution): ''' Calcola i rifiuti di taglio dato una soluzione specifica input stock_size (float) : la dimensione del materiale disponibile per l'acquisto solution (list) : lista di float che rappresentano l'ordine dei tagli da effettuare output cut_off_waste (float) : il totale dei rifiuti di taglio della soluzione data ''' # impostare una variabile per tener traccia delle lunghezze totali dei tagli sul pezzo corrente di materiale temp_cut_length = 0 # iniziare senza rifiuti cut_off_waste = 0 for cut in solution: # se il prossimo taglio non si adatta al materiale corrente, # calcolare nuovi rifiuti e reimpostare per un altro pezzo di materiale if temp_cut_length + cut > stock_size: # calcolare i rifiuti di taglio cut_off_waste += stock_size - temp_cut_length # reimpostare la lunghezza del taglio temp_cut_length = cut else: # aggiungere alla lunghezza cumulativa dei tagli sul materiale temp_cut_length += cut # aggiungere i rifiuti dell'ultimo taglio - non sono catturati nel ciclo cut_off_waste += stock_size - temp_cut_length return cut_off_wasteCopriremo l’algoritmo di cui abbiamo bisogno nella prossima sezione.
L’algoritmo greedy
L’algoritmo greedy è estremamente semplice, basta trovare il pezzo più grande che si adatta a quello che rimane del materiale corrente su cui stai lavorando.
Usando l’esempio precedente, diremo che vogliamo fare questi tagli [4′, 2′, 1′, 2′, 2′, 1′] e abbiamo bisogno di un algoritmo greedy per ottimizzare l’ordine.
Iniziamo con il taglio più lungo che si adatta al nostro pezzo corrente di materiale. Poiché non abbiamo effettuato nessun taglio, il nostro pezzo corrente di materiale è di 5′. 4′ è il taglio più lungo che abbiamo e si adatta ai 5′ di materiale rimanente. Il taglio successivo più lungo è di 2′, poiché abbiamo solo 1′ di materiale rimasto, è troppo lungo. Passiamo al taglio successivo più lungo, che è di 1′. Questo si adatta al materiale rimanente, quindi il nostro prossimo taglio è di 1′. L’algoritmo segue questo schema fino a quando non ci sono più tagli rimasti.
Ecco come appare quell’algoritmo in Python:
def greedy_search(cuts, stock_size): ''' Calcola una soluzione ottimale greedy input: cuts (list) : tagli da effettuare stock_size (float) : dimensione del materiale disponibile per l'acquisto output: cut_plan (list) : sequenza di tagli per ottenere risultati ottimali greedy waste (float) : quantità di materiale sprecato dalla soluzione ''' # piano di taglio vuoto, da popolare cut_plan = [] # inizia con taglio pari alla dimensione del materiale cut_off = stock_size # copia la lista dei tagli per evitare di modificare la lista originale cuts_copy = copy(cuts) # ordina i tagli in ordine discendente cuts = list(np.sort(cuts)[::-1]) # continua ad ordinare i tagli finché # tutti i tagli sono stati ordinati while len(cuts_copy) > 0: for cut_size in cuts_copy: # se la dimensione del taglio è inferiore al materiale rimanente, # assegna il taglio adesso if cut_size < cut_off: # aggiungi il taglio al piano cut_plan.append(cut_size) # aggiorna la quantità rimanente cut_off -= cut_size # rimuovi il taglio dalla lista dei tagli che devono ancora # essere ordinati cuts_copy.remove(cut_size) # reimposta il taglio su tutta la dimensione del materiale cut_off = stock_size # calcola i rifiuti usando la funzione total_waste waste = total_waste(stock_size, cut_plan) return cut_plan, wasteConfronto con la ricerca esaustiva in spazio di bassa n
Stiamo risparmiando molto tempo usando un’approssimazione della soluzione ottimale tramite l’algoritmo greedy, ma quanto è buona questa approssimazione? Una ricerca esaustiva dello spazio delle soluzioni fornisce la soluzione ottimale globale – che è il nostro punto di riferimento. Confrontiamo la soluzione dell’algoritmo greedy con le soluzioni ottimali globali per scenari con solo alcuni tagli (ricordiamo che trovare l’ottimale globale con molti tagli è davvero difficile).
Ho creato casualmente 250 elenchi di tagli per taglie di taglio comprese tra 2 e 10. Ogni taglio era compreso tra 0 e 1 e la dimensione del materiale era fissata a 1,1. Di seguito le prestazioni:
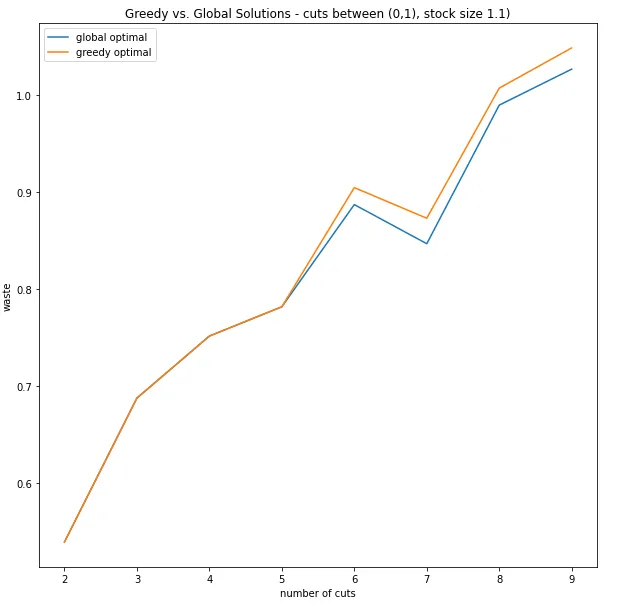
Come puoi vedere, all’aumentare di ‘n’, le prestazioni dell’algoritmo greedy peggiorano rispetto all’ottimo globale, ma rimangono relativamente vicine e altamente correlate.
Confronto con la ricerca casuale nello spazio n-dimensionale
Purtroppo, abbiamo un grave punto cieco… Cioè, non conosciamo l’ottimo globale nello spazio n-dimensionale. Ora, ci occupiamo di confrontare diversi tipi di euristiche (algoritmi progettati per approssimare ottimi globali). Come si comporta l’algoritmo greedy rispetto alla ricerca casuale dello spazio delle soluzioni?
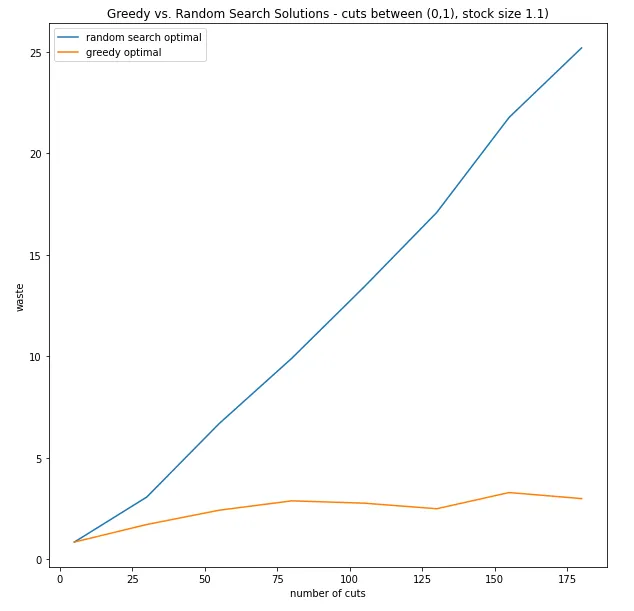
Possiamo vedere che, all’aumentare del numero di tagli, la ricerca casuale peggiora molto. Ha senso perché la ricerca casuale seleziona casualmente 500 soluzioni e ne sceglie la migliore: man mano che lo spazio delle soluzioni si espande, la percentuale di spazio soluzioni che esploriamo casualmente diventa sempre più piccola. Ora possiamo vedere che la soluzione greedy è molto migliore rispetto a guardare casualmente le soluzioni potenziali.
Conclusioni
Sembra che la soluzione greedy per il problema del taglio del materiale sia un modo ragionevole e molto veloce per trovare una soluzione abbastanza buona. Per i miei scopi, questo è sufficiente. Faccio solo alcuni progetti all’anno e di solito sono di piccole dimensioni. Tuttavia, per applicazioni come stabilimenti di produzione, approcci più complicati e intensivi avranno probabilmente un impatto significativo sul budget dell’azienda. Puoi esaminare la ‘programmazione lineare intera mista’ (MILP), che è un altro modo per cercare soluzioni ottimali migliori.
Se dovessi approfondire questo problema, confronterei l’approccio greedy con algoritmi metaeuristici migliori (la ricerca casuale è probabilmente il peggiore), come varie versioni di hill-climb, tabu search o simulated annealing. Per ora mi fermo qui, ho un’altra tabella da fare!
Per tutto il codice utilizzato in questo articolo, consulta questo repository.





