Come elaborare 15 miliardi di log al giorno e mantenere le grandi interrogazioni entro 1 secondo
Elaborate 15 billion logs per day and maintain large queries within 1 second.
Questo caso d’uso di data warehousing riguarda la scalabilità. L’utente è China Unicom, uno dei più grandi fornitori di servizi di telecomunicazioni al mondo. Utilizzando Apache Doris, implementano più cluster su scala di petabyte su dozzine di macchine per supportare i loro 15 miliardi di aggiunte di log giornalieri provenienti dalle loro oltre 30 linee di business. Un tale sistema di analisi di log gigantesco fa parte della loro gestione della sicurezza informatica. Per la necessità di monitoraggio in tempo reale, tracciamento delle minacce e allerta, richiedono un sistema di analisi dei log in grado di raccogliere, archiviare, analizzare e visualizzare automaticamente log e record degli eventi.
Dal punto di vista architettonico, il sistema dovrebbe essere in grado di effettuare analisi in tempo reale di vari formati di log e, naturalmente, essere scalabile per supportare dimensioni di dati enormi e in costante aumento. Il resto di questo post riguarda l’architettura di elaborazione dei log e come realizzano l’ingestione stabile dei dati, l’archiviazione a basso costo e le query rapide con essa.
Architettura del sistema
- Intervista del 30º anniversario di VoAGI con il fondatore Gregory Piatetsky-Shapiro
- Felice 30° Anniversario VoAGI!
- Sbloccare la scatola nera Una legge quantitativa per comprendere il processo di elaborazione dei dati nelle reti neurali profonde
Questa è una panoramica del loro flusso di dati. I log vengono raccolti nel data warehouse e passano attraverso diversi livelli di elaborazione.
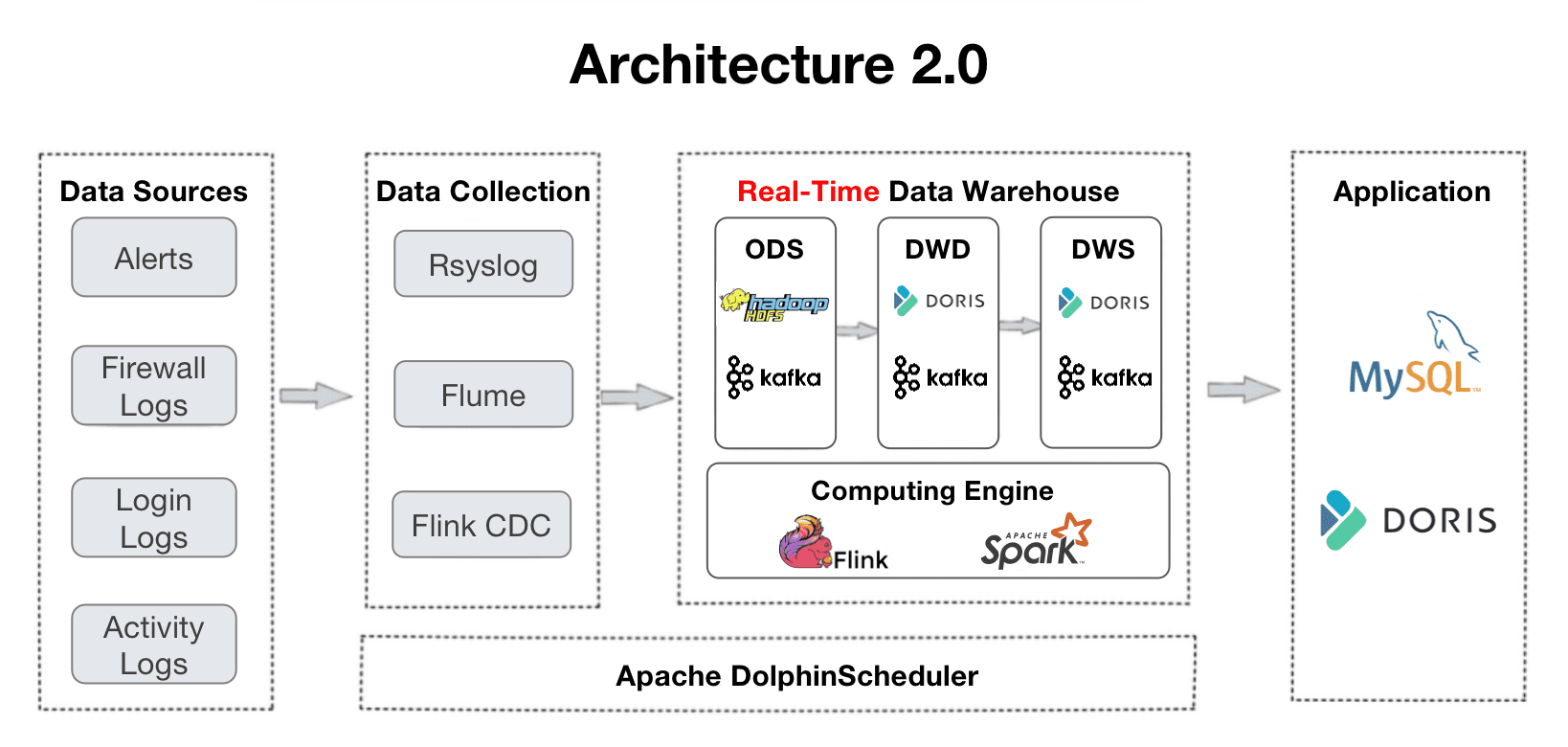
- ODS: I log originali e gli avvisi da tutte le fonti vengono raccolti in Apache Kafka. Nel frattempo, una copia di essi verrà archiviata in HDFS per la verifica o il ripristino dei dati.
- DWD: Qui si trovano le tabelle dei fatti. Apache Flink pulisce, standardizza, reintegra e de-identifica i dati e li scrive nuovamente in Kafka. Queste tabelle dei fatti verranno anche inserite in Apache Doris, in modo che Doris possa tracciare un determinato elemento o utilizzarle per la creazione di dashboard e report. Poiché i log non sono avversi alla duplicazione, le tabelle dei fatti verranno organizzate nel modello di chiave duplicata di Apache Doris.
- DWS: Questo livello aggrega i dati da DWD e crea le basi per le query e l’analisi.
- ADS: In questo livello, Apache Doris aggrega automaticamente i dati con il suo modello di chiave aggregata e aggiorna automaticamente i dati con il suo modello di chiave unica.
L’architettura 2.0 si evolve dall’architettura 1.0, che è supportata da ClickHouse e Apache Hive. La transizione è stata determinata dalle esigenze dell’utente per l’elaborazione dei dati in tempo reale e le query di join multi-tabella. Dalla loro esperienza con la vecchia architettura, hanno riscontrato un supporto inadeguato per la concorrenza e i join multi-tabella, manifestati da frequenti timeout nella creazione di dashboard e errori OOM nei join distribuiti.
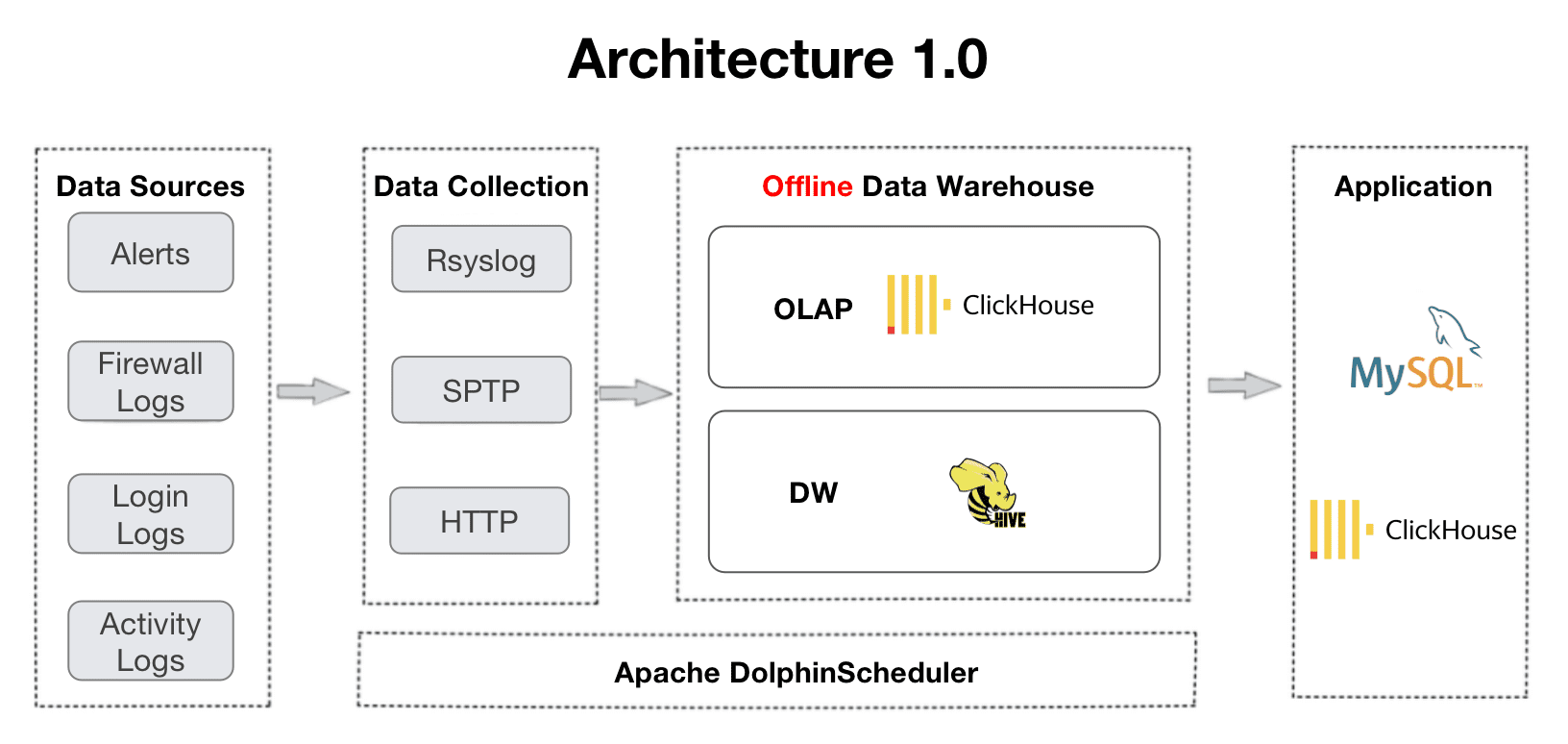
Ora diamo un’occhiata alla loro pratica di ingestione dei dati, archiviazione e query con l’architettura 2.0.
Pratica di casi reali
Ingestione stabile di 15 miliardi di log al giorno
Nel caso dell’utente, la loro attività genera 15 miliardi di log ogni giorno. Ingerire un tale volume di dati in modo rapido e stabile è un vero problema. Con Apache Doris, il modo consigliato è utilizzare il Flink-Doris-Connector. È sviluppato dalla comunità di Apache Doris per la scrittura di dati su larga scala. Il componente richiede una configurazione semplice. Implementa il caricamento in streaming e può raggiungere una velocità di scrittura di 200.000-300.000 log al secondo, senza interrompere i carichi di lavoro di analisi dei dati.
Una lezione appresa è che quando si utilizza Flink per la scrittura ad alta frequenza, è necessario trovare la configurazione dei parametri corretta per il proprio caso per evitare l’accumulo di versioni dei dati. In questo caso, l’utente ha apportato le seguenti ottimizzazioni:
- Checkpoint di Flink: Hanno aumentato l’intervallo di checkpoint da 15s a 60s per ridurre la frequenza di scrittura e il numero di transazioni elaborate da Doris per unità di tempo. Ciò può alleviare la pressione della scrittura dei dati e evitare la generazione di troppe versioni dei dati.
- Pre-Aggregazione dei dati: Per i dati dello stesso ID provenienti da diverse tabelle, Flink li pre-aggrega in base all’ID della chiave primaria e crea una tabella piatta, al fine di evitare un consumo eccessivo di risorse causato dalla scrittura di dati da più origini.
- Compattazione di Doris: Il trucco qui consiste nel trovare i parametri giusti del backend (BE) di Doris per allocare la giusta quantità di risorse CPU per la compattazione dei dati, impostare il numero appropriato di partizioni dei dati, bucket e repliche (troppi tablet di dati comporteranno enormi costi aggiuntivi) e aumentare il valore di max_tablet_version_num per evitare l’accumulo di versioni.
Queste misure insieme garantiscono la stabilità dell’ingestione quotidiana. L’utente ha riscontrato una performance stabile e un punteggio di compattazione basso nel backend di Doris. Inoltre, la combinazione di pre-elaborazione dei dati in Flink e il modello di chiave unica in Doris possono garantire aggiornamenti più rapidi dei dati.
Strategie di archiviazione per ridurre i costi del 50%
La dimensione e la velocità di generazione dei log impongono anche una pressione sull’archiviazione. Tra l’immensa quantità di dati di log, solo una parte ha un alto valore informativo, quindi l’archiviazione dovrebbe essere differenziata. L’utente ha tre strategie di archiviazione per ridurre i costi.
- Algoritmo di compressione ZSTD (ZStandard): Per tabelle di dimensioni superiori a 1TB, specificare il metodo di compressione come “ZSTD” durante la creazione della tabella, si otterrà un rapporto di compressione di 10:1.
- Archiviazione tiered dei dati caldi e freddi: Questo è supportato dalla nuova funzionalità di Doris. L’utente imposta un periodo di “raffreddamento” dei dati di 7 giorni. Ciò significa che i dati degli ultimi 7 giorni (ovvero i dati caldi) verranno archiviati su SSD. Man mano che il tempo passa, i dati caldi “si raffreddano” (diventando più vecchi di 7 giorni), verranno automaticamente spostati su HDD, che è meno costoso. Man mano che i dati diventano ancora più “freddi”, verranno spostati nell’archiviazione degli oggetti per costi di archiviazione molto più bassi. Inoltre, nell’archiviazione degli oggetti, i dati verranno archiviati con una sola copia anziché tre. Ciò riduce ulteriormente i costi e gli oneri derivanti dall’archiviazione ridondante.
- Numero differenziato di repliche per diverse partizioni dei dati: L’utente ha partizionato i propri dati per intervallo di tempo. Il principio è quello di avere più repliche per le partizioni di dati più recenti e meno per quelle più vecchie. Nel loro caso, i dati degli ultimi 3 mesi vengono accessi frequentemente, quindi hanno 2 repliche per questa partizione. I dati che hanno da 3 a 6 mesi hanno due repliche, mentre i dati da 6 mesi fa hanno una sola copia.
Con queste tre strategie, l’utente ha ridotto i propri costi di archiviazione del 50%.
Strategie di interrogazione differenziate in base alla dimensione dei dati
Alcuni log devono essere tracciati e localizzati immediatamente, come quelli relativi a eventi anomali o a guasti. Per garantire una risposta in tempo reale a queste interrogazioni, l’utente ha diverse strategie di interrogazione per diverse dimensioni dei dati:
- Meno di 100G: L’utente utilizza la funzionalità di partizionamento dinamico di Doris. Le tabelle di piccole dimensioni verranno partizionate per data e le tabelle di grandi dimensioni verranno partizionate per ora. Ciò può evitare il disequilibrio dei dati. Per garantire ulteriormente un equilibrio all’interno di una partizione di dati, utilizzano l’ID a forma di fiocco di neve come campo di bucketing. Hanno anche impostato un offset di inizio. Verranno conservati i dati degli ultimi 20 giorni. Questo è il punto di equilibrio tra il backlog dei dati e le esigenze analitiche.
- 100G~1T: Queste tabelle hanno le loro viste materializzate, che sono i set di risultati pre-calcolati conservati in Doris. Di conseguenza, le interrogazioni su queste tabelle saranno molto più veloci e consumeranno meno risorse. La sintassi DDL delle viste materializzate in Doris è la stessa di quella di PostgreSQL e Oracle.
- Oltre 100T: Queste tabelle vengono inserite nel modello di chiave aggregata di Apache Doris e vengono pre-aggregate. In questo modo, consentiamo di eseguire interrogazioni su 2 miliardi di record di log in 1-2 secondi.
Queste strategie hanno ridotto i tempi di risposta delle interrogazioni. Ad esempio, un’interrogazione di un elemento dati specifico richiedeva qualche minuto, ma ora può essere completata in millisecondi. Inoltre, per le grandi tabelle che contengono 10 miliardi di record di dati, le interrogazioni su diverse dimensioni possono essere eseguite in pochi secondi.
Piani in corso
L’utente sta attualmente effettuando test con l’indice invertito appena aggiunto in Apache Doris. È progettato per velocizzare la ricerca full-text delle stringhe e le interrogazioni di equivalenza e intervallo dei numeri e delle date. Hanno anche fornito un prezioso feedback sulla logica di bucketing automatico in Doris: Attualmente, Doris decide il numero di bucket per una partizione in base alla dimensione dei dati della partizione precedente. Il problema per l’utente è che la maggior parte dei loro nuovi dati arriva durante il giorno, ma poco di notte. Quindi nel loro caso, Doris crea troppi bucket per i dati notturni ma troppo pochi durante il giorno, che è l’opposto di ciò di cui hanno bisogno. Sperano di aggiungere una nuova logica di bucketing automatico, in cui il riferimento per Doris per decidere il numero di bucket sia la dimensione dei dati e la distribuzione del giorno precedente. Sono venuti nella comunità di Apache Doris e stiamo lavorando su questa ottimizzazione. Zaki Lu è un ex product manager di Baidu e ora DevRel per la comunità open source di Apache Doris.






