Editor di Immagini e EditBench Avanzamento ed valutazione della riparazione delle immagini guidata dal testo.
Editor di Immagini e EditBench guidano la riparazione delle immagini tramite testo.
Pubblicato da Su Wang e Ceslee Montgomery, ingegneri di ricerca di Google Research
Negli ultimi anni, la ricerca sulla generazione di testo-immagine ha visto una serie di progressi (notabilmente, Imagen, Parti, DALL-E 2, ecc.) che si sono naturalmente estesi anche a temi correlati. In particolare, la modifica di immagini guidata dal testo (TGIE) è un compito pratico che comporta la modifica di immagini generate e fotografate anziché rifarle completamente. La modifica rapida, automatizzata e controllabile rappresenta una soluzione comoda quando la ricreazione delle immagini richiederebbe molto tempo o sarebbe impossibile (ad esempio, la modifica degli oggetti nelle foto delle vacanze o il perfezionamento dei dettagli a grana fine di un cucciolo carino generato da zero). Inoltre, TGIE rappresenta una sostanziale opportunità per migliorare la formazione dei modelli di base stessi. I modelli multimodali richiedono dati diversi per essere formati correttamente e la modifica di TGIE può consentire la generazione e la ricombinazione di dati sintetici di alta qualità e scalabili che, forse ancora più importante, possono fornire metodi per ottimizzare la distribuzione dei dati di formazione lungo qualsiasi asse dato.
In “Imagen Editor e EditBench: avanzamento ed valutazione dell’Inpainting di immagini guidato dal testo”, che sarà presentato alla CVPR 2023, presentiamo Imagen Editor, una soluzione di ultima generazione per il compito di inpainting mascherato, ovvero quando un utente fornisce istruzioni di testo insieme a un’overlay o “maschera” (solitamente generata all’interno di un’interfaccia di tipo disegno) che indica l’area dell’immagine che si vuole modificare. Presentiamo anche EditBench, un metodo che valuta la qualità dei modelli di modifica delle immagini. EditBench va oltre i metodi a grana grossa comunemente utilizzati “l’immagine corrisponde al testo”, ed esamina i vari tipi di attributi, oggetti e scene per una comprensione più dettagliata delle prestazioni del modello. In particolare, mette fortemente l’accento sulla fedeltà dell’allineamento immagine-testo senza perdere di vista la qualità dell’immagine.
 |
| Dato un’immagine, una maschera definita dall’utente e un prompt di testo, Imagen Editor apporta modifiche localizzate alle aree designate. Il modello incorpora in modo significativo l’intento dell’utente e esegue modifiche fotorealistiche. |
Imagen Editor
Imagen Editor è un modello basato sulla diffusione, ottimizzato su Imagen per la modifica. Si concentra su rappresentazioni migliorate di input linguistici, controllo a grana fine e output ad alta fedeltà. Imagen Editor riceve tre input dall’utente: 1) l’immagine da modificare, 2) una maschera binaria per specificare la regione di modifica e 3) un prompt di testo: tutti e tre gli input guidano i campioni di output.
Imagen Editor si basa su tre tecniche fondamentali per l’inpainting di immagini guidato dal testo di alta qualità. In primo luogo, a differenza dei modelli di inpainting precedenti (ad esempio, Palette, Context Attention, Gated Convolution) che applicano caselle casuali e maschere di tratti casuali, Imagen Editor utilizza una politica di mascheramento del rilevatore di oggetti con un modulo rilevatore di oggetti che produce maschere di oggetti durante la formazione. Le maschere di oggetti sono basate sugli oggetti rilevati anziché su patch casuali e consentono un allineamento più fondato tra i prompt di testo di modifica e le regioni mascherate. Empiricamente, il metodo aiuta il modello a evitare il diffuso problema del prompt di testo ignorato quando le regioni mascherate sono piccole o coprono solo parzialmente un oggetto (ad esempio, CogView2).
 |
| Le maschere casuali ( sinistra ) catturano spesso lo sfondo o intersecano i confini degli oggetti, definendo regioni che possono essere plausibilmente inpaintate solo dal contesto dell’immagine. Le maschere degli oggetti ( destra ) sono più difficili da inpaintare solo dal contesto dell’immagine, incoraggiando i modelli a fare affidamento maggiormente sugli input di testo durante la formazione. |
In seguito, durante l’addestramento e l’elaborazione, Imagen Editor migliora la modifica ad alta risoluzione condizionandosi sulla concatenazione di canali a risoluzione completa (1024×1024 in questo lavoro) dell’immagine di input e della maschera (simile a SR3, Palette e GLIDE). Per il modello di diffusione di base 64×64 e i modelli di super-risoluzione 64×64→256×256, applichiamo una convoluzione di downsampling parametrizzata (ad esempio, convoluzione con una stride), che troviamo empiricamente essere critica per l’alta fedeltà.
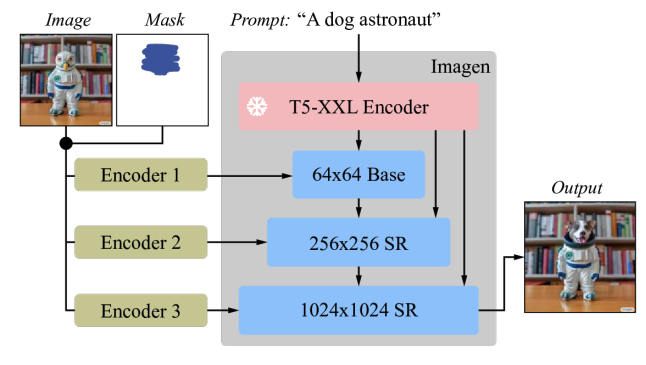 |
| Imagen è ottimizzato per la modifica di immagini. Tutti i modelli di diffusione, ovvero il modello base e i modelli di super-risoluzione (SR), sono condizionati su input di immagini e maschere ad alta risoluzione 1024×1024. Per questo scopo, vengono introdotti nuovi encoder di immagini convoluzionali. |
Infine, durante l’elaborazione, applichiamo una guida senza classificatore (CFG) per orientare i campioni verso una determinata condizionatura, in questo caso, prompt di testo. CFG interpola tra le previsioni del modello condizionate dal testo e non condizionate per garantire una forte allineamento tra l’immagine generata e il prompt di testo di input per il riempimento delle immagini guidate dal testo. Seguiamo Imagen Video e utilizziamo pesi di guida elevati con oscillazione di guida (uno schema di guida che oscilla all’interno di un intervallo di valori di pesi di guida). Nel modello di base (la diffusione di 64x stadio-1), dove garantire un forte allineamento con il testo è più critico, utilizziamo uno schema di peso di guida che oscilla tra 1 e 30. Osserviamo che i pesi di guida elevati combinati con la guida oscillante producono il miglior compromesso tra fedeltà del campione e allineamento testo-immagine.
EditBench
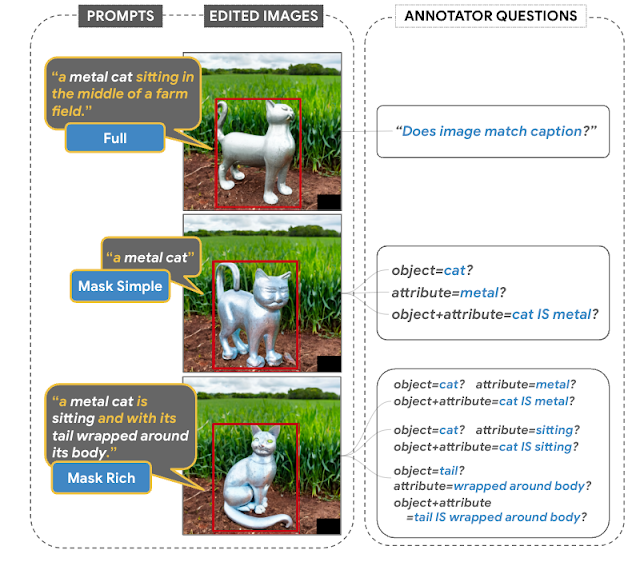
Il dataset EditBench per l’elaborazione di immagini guidata dal testo contiene 240 immagini, di cui 120 generate e 120 immagini naturali. Le immagini generate sono sintetizzate da Parti e le immagini naturali sono tratte dai dataset Visual Genome e Open Images. EditBench cattura una vasta gamma di lingue, tipi di immagini e livelli di specificità del prompt di testo (ad es. didascalie semplici, ricche e complete). Ogni esempio consiste in (1) un’immagine di input mascherata, (2) un prompt di testo di input e (3) un’immagine di output di alta qualità utilizzata come riferimento per le metriche automatiche. Per fornire una visione delle relative forze e debolezze dei diversi modelli, i prompt di EditBench sono progettati per testare dettagli fini lungo tre categorie: (1) attributi (ad es. materiale, colore, forma, dimensione, conteggio); (2) tipi di oggetti (ad es. comuni, rari, rendering di testo); e (3) scene (ad es. interni, esterni, realistici o dipinti). Per comprendere come diverse specifiche di prompt influiscano sulle prestazioni del modello, forniamo tre tipi di prompt di testo: una descrizione singolo attributo (Mask Simple) o una descrizione multi-attributo dell’oggetto mascherato (Mask Rich) – o una descrizione dell’intera immagine (Full Image). Mask Rich, in particolare, sonda la capacità dei modelli di gestire il legame e l’inclusione di attributi complessi.
 |
| L’immagine completa è utilizzata come riferimento per un riempimento riuscito. La maschera copre l’oggetto di destinazione con una forma libera e non suggerente. Valutiamo i prompt Mask Simple, Mask Rich e Full Image, coerentemente con i modelli di testo-immagine convenzionali. |
A causa delle debolezze intrinseche delle metriche di valutazione automatica esistenti (CLIPScore e CLIP-R-Precision) per TGIE, consideriamo la valutazione umana come il punto di riferimento per EditBench. Nella sezione sottostante, dimostriamo come EditBench viene applicato alla valutazione del modello.
Valutazione
Valutiamo il modello Imagen Editor – con mascheramento degli oggetti (IM) e con mascheramento casuale (IM-RM) – rispetto a modelli comparabili, Stable Diffusion (SD) e DALL-E 2 (DL2). Imagen Editor supera questi modelli con ampi margini in tutte le categorie di valutazione di EditBench.
Per le richieste Full Image, la valutazione umana su singola immagine fornisce risposte binarie per confermare se l’immagine corrisponde alla didascalia. Per le richieste Mask Simple, la valutazione umana su singola immagine conferma se l’oggetto e l’attributo sono correttamente rappresentati e vincolati correttamente (ad esempio, per un gatto rosso, un gatto bianco su un tavolo rosso sarebbe un vincolo non corretto). La valutazione umana a confronto su due immagini utilizza solo richieste Mask Rich per confronti a confronto tra IM e ciascuno degli altri tre modelli (IM-RM, DL2 e SD) e indica quale immagine si abbina meglio alla didascalia per l’allineamento testo-immagine e quale immagine è più realistica.
 |
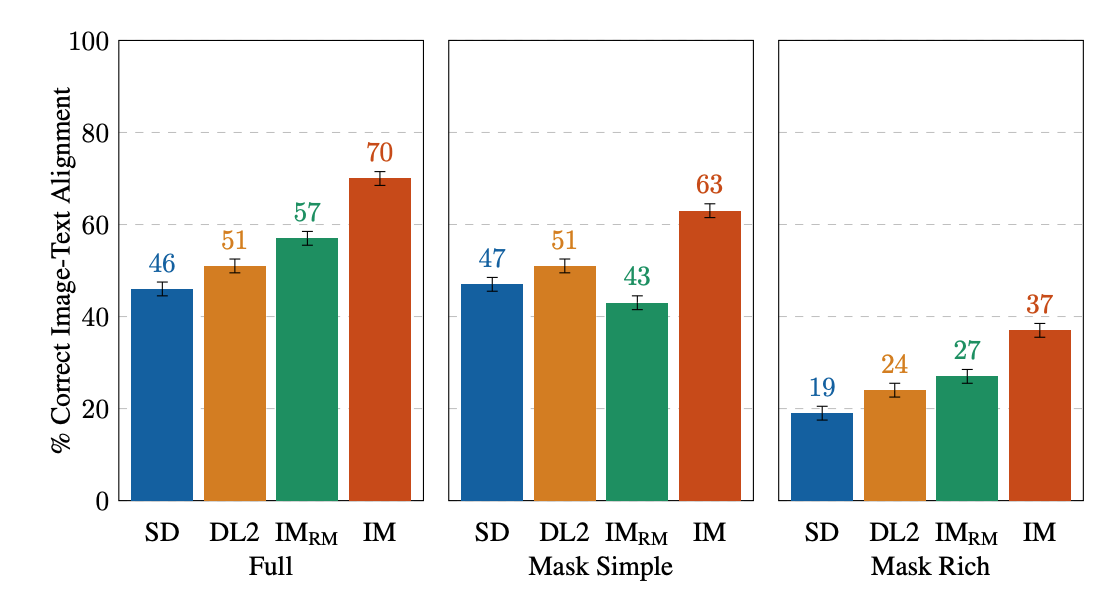
| Valutazione umana. Le richieste Full Image suscitano l’impressione complessiva degli annotatori sull’allineamento testo-immagine; Mask Simple e Mask Rich verificano l’inclusione corretta di particolari attributi, oggetti e vincoli di attributi. |
Per la valutazione umana su singola immagine, IM riceve i punteggi più alti in tutto (10-13% più alto del modello che si comporta secondo). Per il resto, l’ordine di prestazione è IM-RM > DL2 > SD (con una differenza del 3-6%) tranne per Mask Simple, dove IM-RM rimane indietro del 4-8%. Poiché relativamente più contenuto semantico è coinvolto in Full e Mask Rich, congettiamo che IM-RM e IM benefici siano il codificatore di testo T5 XXL a performance più elevate.
 |
| Valutazioni umane su singola immagine di text-guided image inpainting su EditBench per tipo di richiesta. Per le richieste Mask Simple e Mask Rich, l’allineamento testo-immagine è corretto se l’immagine modificata include accuratamente ogni attributo e oggetto specificato nella richiesta, compreso il vincolo di attributo corretto. Si noti che a causa di progettazioni di valutazione diverse, le richieste Full rispetto alle sole maschere, i risultati sono meno direttamente confrontabili. |
EditBench si concentra sull’annotazione dettagliata, quindi valutiamo i modelli per tipi di oggetti e attributi. Per i tipi di oggetti, IM è il leader in tutte le categorie, con una performance del 10-11% migliore del modello che si comporta secondo nella rappresentazione comune, rara e testuale.
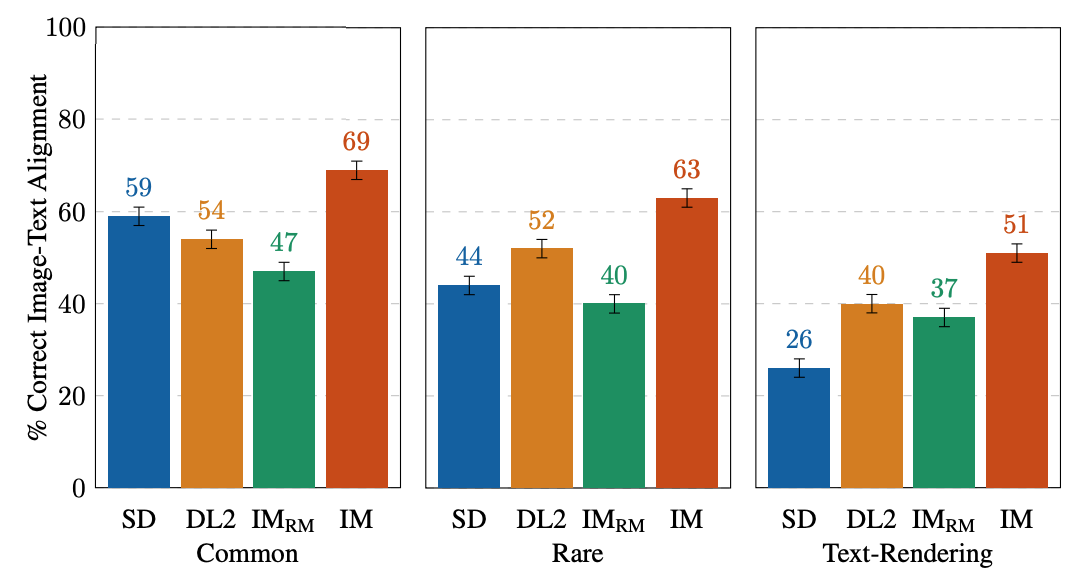 |
| Valutazioni umane su singola immagine su EditBench Mask Simple per tipo di oggetto. Come coorte, i modelli sono migliori nella rappresentazione degli oggetti rispetto alla rappresentazione del testo. |
Per i tipi di attributi, IM è valutato molto più alto (13-16%) rispetto al modello che si posiziona al secondo posto, tranne che per il conteggio, dove DL2 è solo 1% dietro.
 |
| Valutazioni umane su singole immagini su EditBench Mask Simple per tipo di attributo. La mascheratura degli oggetti migliora la conformità agli attributi della richiesta (IM vs. IM-RM). |
A confronto con gli altri modelli uno-contro-uno, IM guida l’allineamento del testo con un margine significativo, essendo preferito dagli annotatori rispetto a SD, DL2 e IM-RM.
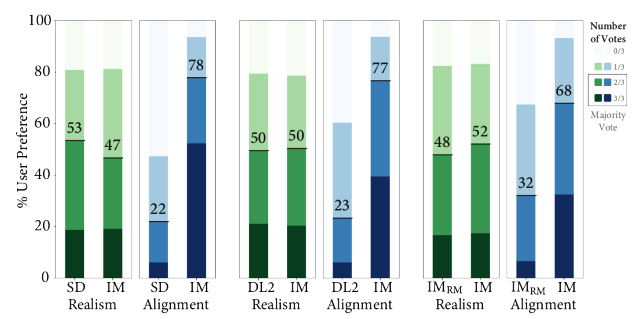 |
| Valutazione umana a confronto della realtà delle immagini e dell’allineamento testo-immagine su EditBench Mask Rich. Per l’allineamento testo-immagine, Imagen Editor è preferito in tutti i confronti. |
Infine, illustriamo un confronto rappresentativo uno a fianco all’altro per tutti i modelli. Consultare l’articolo per ulteriori esempi.
 |
| Esempi di output del modello per le richieste Mask Simple vs. Mask Rich. La mascheratura degli oggetti migliora la conformità dettagliata di Imagen Editor alla richiesta rispetto allo stesso modello addestrato con maschere casuali. |
Conclusione
Abbiamo presentato Imagen Editor e EditBench, ottenendo significativi progressi nell’inpainting di immagini guidato dal testo e nella valutazione dello stesso. Imagen Editor è un inpainting di immagini guidato dal testo affinato da Imagen. EditBench è un benchmark sistematico esaustivo per l’inpainting di immagini guidato dal testo, valutando le prestazioni su più dimensioni: attributi, oggetti e scene. Si noti che a causa di preoccupazioni relative all’IA responsabile, non rilasciamo Imagen Editor al pubblico. EditBench, d’altra parte, è rilasciato in pieno per il beneficio della comunità di ricerca.
Ringraziamenti
Grazie a Gunjan Baid, Nicole Brichtova, Sara Mahdavi, Kathy Meier-Hellstern, Zarana Parekh, Anusha Ramesh, Tris Warkentin, Austin Waters e Vijay Vasudevan per il loro generoso supporto. Ringraziamo Igor Karpov, Isabel Kraus-Liang, Raghava Ram Pamidigantam, Mahesh Maddinala e tutti gli anonimi annotatori umani per la loro coordinazione al completamento dei compiti di valutazione umana. Siamo grati a Huiwen Chang, Austin Tarango e Douglas Eck per il feedback sulla pubblicazione. Grazie a Erica Moreira e Victor Gomes per l’aiuto nella coordinazione delle risorse. Infine, grazie agli autori di DALL-E 2 per averci dato il permesso di utilizzare i loro output del modello per scopi di ricerca.
