Generazione controllabile di immagini mediche con ControlNets
Controllable generation of medical images with ControlNets.
Guida all’uso di ControlNets per controllare il processo di generazione dei modelli di diffusione latente
In questo post, presenteremo una guida sulla formazione di un ControlNet per fornire agli utenti un controllo preciso sul processo di generazione di un Modello di Diffusione Latente (come Stable Diffusion!). Il nostro obiettivo è di mostrare le notevoli capacità di questi modelli nella traduzione di immagini cerebrali attraverso vari contrasti. Per raggiungere questo obiettivo, sfrutteremo il potere dell’estensione open-source recentemente introdotta per MONAI, MONAI Generative Models !

Il codice del nostro progetto è disponibile in questo repository pubblico https://github.com/Warvito/generative_brain_controlnet
Introduzione
Negli ultimi anni, i modelli di diffusione testo-immagine hanno visto notevoli progressi, consentendo la generazione di immagini altamente realistiche basate su descrizioni di testo open-domain. Queste immagini generate hanno dettagli ricchi, contorni ben definiti, strutture coerenti e rappresentazioni contestuali significative. Tuttavia, nonostante i significativi successi dei modelli di diffusione, rimane una sfida nel raggiungere un controllo preciso sul processo generativo. Anche con descrizioni di testo lunghe e intricate, catturare accuratamente le idee desiderate dall’utente può essere difficile.
L’introduzione di ControlNets, come proposto da Lvmin Zhang e Maneesh Agrawala nel loro innovativo articolo “Adding Conditional Control to Text-to-Image Diffusion Models” (2023), ha notevolmente migliorato la controllabilità e la personalizzazione dei modelli di diffusione. Queste reti neurali agiscono come adattatori leggeri, consentendo un controllo e una personalizzazione precisi mentre preservano la capacità di generazione originale dei modelli di diffusione. Affinando questi adattatori mantenendo il modello di diffusione originale congelato, i modelli testo-immagine possono essere efficacemente ampliati per una vasta gamma di applicazioni immagine-immagine.
- NVIDIA RTX sta trasformando i laptop da 14 pollici, oltre alla codifica simultanea dello schermo e il driver May Studio disponibile oggi.
- Una nuova era la serie ‘Age of Empires’ si unisce a GeForce NOW, parte dei 20 giochi in arrivo a giugno.
- Cos’è la fotogrammetria?
Ciò che distingue ControlNet è la soluzione al problema della coerenza spaziale. A differenza dei metodi precedenti, ControlNet consente un controllo esplicito sugli aspetti spaziali, strutturali e geometrici delle strutture generate, mantenendo il controllo semantico derivato dalle didascalie testuali. Lo studio originale ha introdotto vari modelli che consentono la generazione condizionale basata su bordi, posa, maschere semantiche e mappe di profondità, aprendo la strada a entusiasmanti progressi nel campo della computer vision.
Nel campo dell’elaborazione delle immagini mediche, numerose applicazioni immagine-immagine rivestono un’importanza significativa. Tra queste applicazioni, una notevole attività riguarda la traduzione di immagini tra diversi domini, come la conversione di scansioni di tomografia computerizzata (CT) in immagini di risonanza magnetica (MRI) o la trasformazione di immagini tra contrasti distinti, ad esempio, da immagini MRI pesate T1 a quelle pesate T2. In questo post, ci concentreremo su un caso specifico: utilizzando fette 2D di immagini cerebrali ottenute da un’immagine FLAIR per generare l’immagine corrispondente pesata T1. Il nostro obiettivo è dimostrare come la nostra nuova estensione per MONAI (MONAI Generative Models) e ControlNets possano essere utilizzati efficacemente per formare e valutare modelli generativi sui dati medici. Approfondendo questo esempio, miriamo a fornire informazioni sull’applicazione pratica di queste tecnologie nel dominio dell’elaborazione delle immagini mediche.
Addestramento del modello di diffusione latente
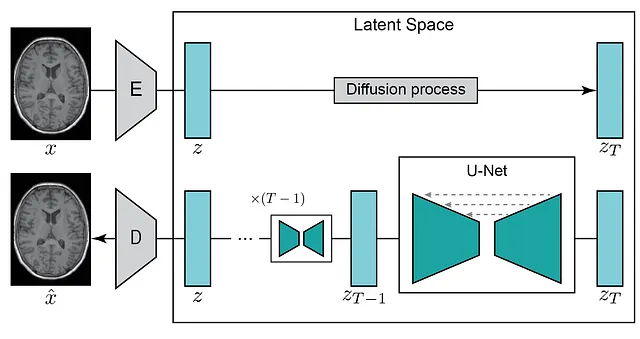
Per generare immagini pesate T1 (T1w) da immagini FLAIR, il primo passo prevede la formazione di un modello di diffusione in grado di generare immagini T1w. Nel nostro esempio, utilizziamo fette 2D estratte da immagini MRI cerebrali provenienti dal dataset UK Biobank (disponibile in base a questo accordo sui dati). Dopo aver registrato i cervelli originali su uno spazio MNI utilizzando il tuo metodo preferito (ad esempio, ANTs o UniRes), estraiamo cinque fette 2D dalla parte centrale del cervello. Abbiamo scelto questa regione poiché presenta vari tessuti, rendendo più facile valutare la traduzione dell’immagine che stiamo eseguendo. Utilizzando questo script, abbiamo ottenuto circa 190.000 fette con una dimensione spaziale di 224 × 160 pixel. Successivamente, dividiamo la nostra immagine nei set di addestramento (~180.000 fette), validazione (~5.000 fette) e test (~5.000 fette) utilizzando questo script. Con il nostro dataset preparato, possiamo iniziare ad addestrare il nostro modello di diffusione latente!
Per ottimizzare le risorse di calcolo, il modello di diffusione latente utilizza un encoder per trasformare l’immagine di input x in uno spazio latente di dimensioni inferiori z, che può poi essere ricostruito da un decoder. Questo approccio consente di addestrare i modelli di diffusione anche con una capacità computazionale limitata, preservando comunque la loro qualità e flessibilità originale. Come abbiamo fatto nel nostro post precedente ( Generazione di immagini mediche con MONAI ), usiamo il modello di autoencoder con regolarizzazione KL di MONAI Generative models per creare il nostro modello di compressione. Utilizzando questa configurazione e la perdita L1 insieme alla regolarizzazione KL, perdita percettiva e perdita avversaria, abbiamo creato un autoencoder in grado di codificare e decodificare immagini del cervello con alta fedeltà (con questo script). La qualità della ricostruzione dell’autoencoder è cruciale per le prestazioni del Modello di Diffusione Latente poiché definisce il limite della qualità delle nostre immagini generate. Se il decoder dell’autoencoder produce immagini sfocate o di bassa qualità, il nostro modello generativo non sarà in grado di generare immagini di qualità superiore.
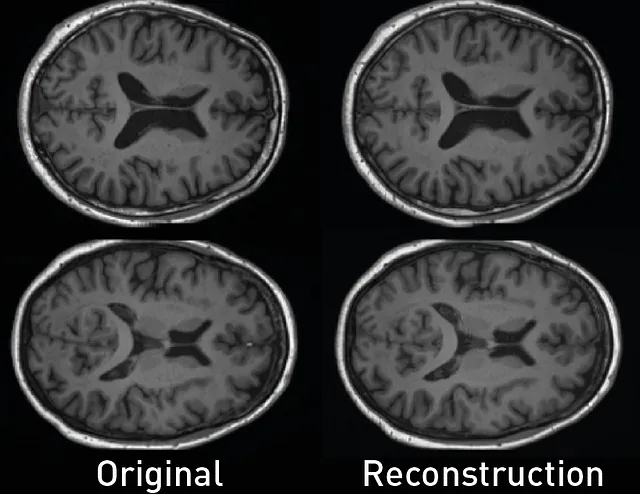
Utilizzando questo script, possiamo quantificare la fedeltà dell’autoencoder utilizzando la Misura dell’Indice di Similarità Strutturale Multi-scala (MS-SSIM) tra le immagini originali e le loro ricostruzioni. In questo esempio, otteniamo un’alta performance con una metrica MS-SSIM pari a 0,9876.
Dopo aver addestrato l’autoencoder, addestreremo il modello di diffusione nello spazio latente z. Il modello di diffusione è un modello in grado di generare immagini da un’immagine di puro rumore denoisandola iterativamente nel corso di una serie di timestep. Solitamente utilizza un’architettura U-Net (che ha un formato encoder-decoder), dove abbiamo strati dell’encoder collegati tramite skip connection con strati nella parte del decoder (tramite lunghe connessioni skip), consentendo la riutilizzabilità delle caratteristiche e stabilizzando l’addestramento e la convergenza.
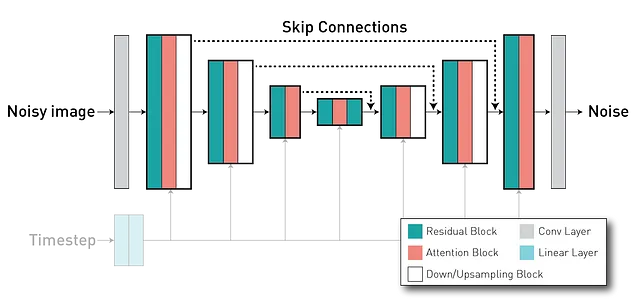
Durante l’addestramento, il Modello di Diffusione Latente apprende una previsione del rumore condizionata a questi prompt. Di nuovo, stiamo utilizzando MONAI per creare e addestrare questa rete. In questo script, istanziamo il modello con questa configurazione, dove l’addestramento e la valutazione vengono eseguiti in questa parte del codice. Poiché non siamo troppo interessati ai prompt testuali in questo tutorial, stiamo utilizzando lo stesso per tutte le immagini (una frase che dice “Immagine pesata in T1 di un cervello”).
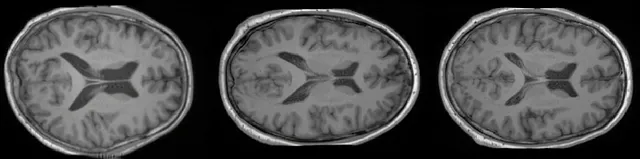
Di nuovo, possiamo quantificare le prestazioni del nostro modello generativo addestrato, questa volta valutiamo la qualità dei campioni (utilizzando la Distanza Fréchet Inception (FID)) e la diversità del modello (calcolando la MS-SSIM tra tutti i campioni di un gruppo di 1.000 campioni). Utilizzando questi due script (1 e 2), abbiamo ottenuto un FID = 2.1986 e una MS-SSIM Diversity = 0.5368.
Come si può vedere dalle immagini e dai risultati precedenti, abbiamo ora un modello in grado di generare immagini ad alta risoluzione con grande qualità. Tuttavia, non abbiamo alcun controllo spaziale su come dovrebbero apparire le immagini. Per questo, useremo un ControlNet per guidare la generazione del nostro Modello di Diffusione Latente.
Addestramento di ControlNet
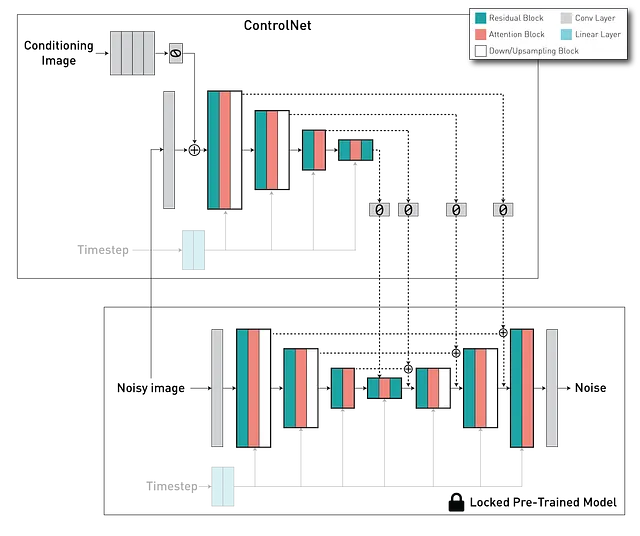
L’architettura ControlNet comprende due componenti principali: una versione addestrabile dell’encoder del modello U-Net, compresi i blocchi centrali, e una versione “bloccata” pre-addestrata del modello di diffusione. Qui, la copia bloccata preserva la capacità generativa, mentre la copia addestrabile viene addestrata su specifici set di dati di immagini per apprendere il controllo condizionale. Queste due componenti sono interconnesse tramite uno strato di “convoluzione zero” – uno strato di convoluzione 1×1 con pesi e bias inizializzati a zero. I pesi di convoluzione passano gradualmente da zero a parametri ottimizzati, garantendo che durante i primi passi di addestramento, le uscite delle copie addestrabili e bloccate rimangano consistenti con ciò che sarebbero se il ControlNet fosse assente. In altre parole, quando un ControlNet viene applicato a determinati blocchi di reti neurali prima di qualsiasi ottimizzazione, non introduce alcuna influenza o rumore alle caratteristiche neurali profonde.
Integrando queste due componenti, il ControlNet ci consente di governare il comportamento di ogni livello nell’U-Net del modello di diffusione.
Nel nostro esempio, istanziamo il ControlNet in questo script, usando il seguente frammento equivalente.
import torchfrom generative.networks.nets import ControlNet, DiffusionModelUNet# Carica il modello di diffusione pre-addestratodiffusion_model = DiffusionModelUNet( spatial_dims=2, in_channels=3, out_channels=3, num_res_blocks=2, num_channels=[256, 512, 768], attention_levels=[False, True, True], with_conditioning=True, cross_attention_dim=1024, num_head_channels=[0, 512, 768],)diffusion_model.load_state_dict(torch.load("diffusion_model.pt"))# Crea il ControlNetcontrolnet = ControlNet( spatial_dims=2, in_channels=3, num_res_blocks=2, num_channels=[256, 512, 768], attention_levels=[False, True, True], with_conditioning=True, cross_attention_dim=1024, num_head_channels=[0, 512, 768], conditioning_embedding_in_channels=1, conditioning_embedding_num_channels=[64, 128, 128, 256],)# Crea una copia addestrabile del modello di diffusionecontrolnet.load_state_dict(diffusion_model.state_dict(), strict=False)# Blocca il peso del modello di diffusionefor p in diffusion_model.parameters(): p.requires_grad = FalseDato che stiamo utilizzando un modello di diffusione latente, questo richiede ControlNets per convertire le condizioni basate sull’immagine nello stesso spazio latente per abbinare la dimensione di convoluzione. A tal fine, utilizziamo una rete convoluzionale addestrata congiuntamente con il modello completo. Nel nostro caso, abbiamo tre livelli di downsampling (simili al KL dell’autoencoder) definiti in “conditioning_embedding_num_channels = [64, 128, 128, 256]”. Poiché la nostra immagine condizionale è un’immagine FLAIR con un solo canale, dobbiamo anche specificare il suo numero di canali di input in “conditioning_embedding_in_channels = 1”.
Dopo aver inizializzato la nostra rete, la addestriamo in modo simile a un modello di diffusione. Nello snippet seguente (e in questa parte del codice), possiamo vedere che prima passiamo la nostra immagine FLAIR condizionale alla rete addestrabile e otteniamo le uscite dalle sue connessioni di salto. Poi, questi valori sono inseriti nel modello di diffusione quando si calcola il rumore previsto. Internamente, il modello di diffusione somma la connessione di salto dai ControlNets con le proprie prima di alimentare la parte del decoder (codice).
# Loop di addestramento...images = batch["t1w"].to(device)cond = batch["flair"].to(device)...noise = torch.randn_like(latent_representation).to(device)noisy_z = scheduler.add_noise( original_samples=latent_representation, noise=noise, timesteps=timesteps)# Calcola la parte addestrabiledown_block_res_samples, mid_block_res_sample = controlnet( x=noisy_z, timesteps=timesteps, context=prompt_embeds, controlnet_cond=cond)# Usando le uscite Controlnet per controllare il comportamento del modello di diffusione noise_pred = diffusion_model( x=noisy_z, timesteps=timesteps, context=prompt_embeds, down_block_additional_residuals=down_block_res_samples, mid_block_additional_residual=mid_block_res_sample,)# Quindi calcola la perdita del modello di diffusione come al solito...Campionamento e valutazione di ControlNet
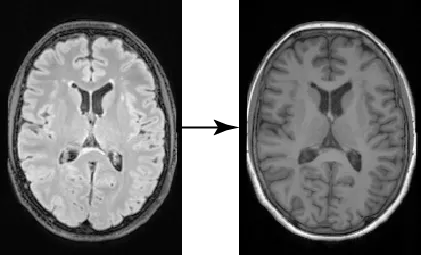
Dopo aver addestrato i nostri modelli, possiamo campionarli e valutarli. Qui, stiamo usando le immagini FLAIR dal set di test per generare immagini T1w condizionate. Similmente alla nostra formazione, il processo di campionamento è molto simile a quello utilizzato con il modello di diffusione, l’unica differenza è che passiamo l’immagine di condizione al ControlNet addestrato e usiamo la sua uscita per alimentare il modello di diffusione in ciascun timestep di campionamento. Come possiamo osservare dalla figura sottostante, le nostre immagini generate seguono con alta fedeltà spaziale la condizionazione originale, con i giri del cortice che seguono forme simili e le immagini che conservano il confine tra i diversi tessuti.
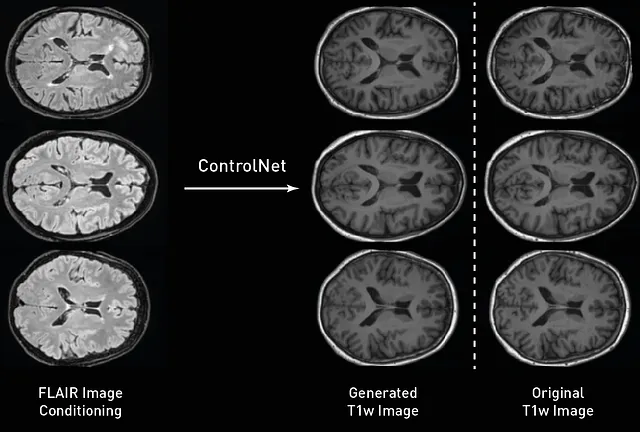
Dopo aver campionato le immagini dei nostri modelli, possiamo quantificare le prestazioni del nostro ControlNet quando traduciamo le immagini tra diversi contrasti. Poiché abbiamo le immagini T1w attese dal set di test, possiamo anche controllarne le differenze e calcolare la distanza tra le immagini reali e sintetiche utilizzando l’errore assoluto medio (MAE), il rapporto segnale-rumore di picco (PSNR) e il MS-SSIM. Nel nostro set di test, abbiamo ottenuto un PSNR = 26,2458+-1,0092, MAE = 0,02632+-0,0036 e MSSIM = 0,9526+-0,0111 quando abbiamo eseguito questo script.
E questo è tutto! ControlNet offre un incredibile controllo sui nostri modelli di diffusione e gli approcci recenti hanno esteso il suo metodo per combinare diversi ControlNet addestrati (Multi-ControlNet), lavorare con diversi tipi di condizionamento nello stesso modello (adattatori T2I) e persino condizionare il modello su stili (utilizzando metodi come ControlNet 1.1 – solo riferimento). Se questi metodi ti sembrano interessanti, non dimenticare di seguirmi per ulteriori guide come questa! 😁
Per ulteriori tutorial sui modelli generativi MONAI e per saperne di più sulle nostre funzionalità, consulta la nostra pagina Tutorial!
Nota: tutte le immagini, salvo diversa indicazione, sono dell’autore.






