Come chattare con qualsiasi file PDF e immagine utilizzando modelli di lingua estesi – Con codice
Chatta con PDF e immagini usando modelli di lingua estesi - Con codice
Guida completa alla creazione di un assistente AI che può rispondere a domande su qualsiasi file
Introduzione
Tante informazioni preziose sono intrappolate nei file PDF e nelle immagini. Fortunatamente, abbiamo queste potenti menti capaci di elaborare quei file per trovare informazioni specifiche, il che è fantastico.
Ma quanti di noi, nel profondo, non vorrebbero avere uno strumento che può rispondere a qualsiasi domanda su un determinato documento?
Questo è l’intero scopo di questo articolo. Spiegherò passo dopo passo come costruire un sistema in grado di interagire con qualsiasi file PDF e immagine.
Se preferisci guardare un video, controlla il link qui sotto:
Workflow generale del progetto
È sempre utile avere una chiara comprensione dei principali componenti del sistema in fase di costruzione. Quindi cominciamo.
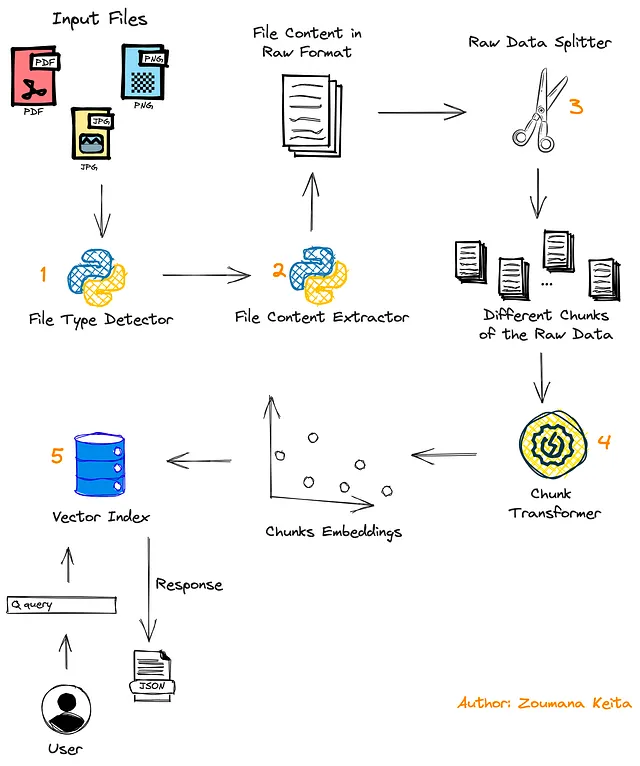
- Prima, l’utente invia il documento da elaborare, che può essere in formato PDF o immagine.
- Viene utilizzato un secondo modulo per rilevare il formato del file in modo che possa essere applicata la funzione di estrazione del contenuto pertinente.
- Il contenuto del documento viene quindi suddiviso in più parti utilizzando il modulo
Data Splitter. - Queste parti vengono infine trasformate in embedding utilizzando il modulo
Chunk Transformerprima di essere memorizzate nel vettore di archiviazione. - Alla fine del processo, la query dell’utente viene utilizzata per trovare parti pertinenti che contengono la risposta a quella query, e il risultato viene restituito all’utente come JSON.
1. Rileva il tipo di documento
Per ogni documento di input, viene applicata una specifica elaborazione a seconda del suo tipo, che sia un PDF o un immagine.




