Come ho costruito una pipeline dati a cascata basata su AWS
Building a cascading data pipeline with AWS
Automatico, scalabile e potente
Oggi condividerò un po’ di esperienza nella costruzione di un progetto di ingegneria dei dati di cui sono sempre orgoglioso. Imparerai le ragioni per cui ho utilizzato gli strumenti e i componenti AWS e come ho progettato l’architettura.
Avviso legale: Il contenuto di questo testo è ispirato alla mia esperienza con un’entità non nominata. Tuttavia, determinati interessi commerciali critici e dettagli sono stati intenzionalmente sostituiti con dati/codici immaginari o omessi, al fine di mantenere la riservatezza e la privacy. Pertanto, l’estensione completa e accurata degli effettivi interessi commerciali coinvolti è riservata.
Prerequisiti
- Conoscenza di Python
- Comprensione dei componenti AWS, come DynamoDB, Lambda serverless, SQS e CloudWatch
- Esperienza di programmazione con YAML & SAM CLI
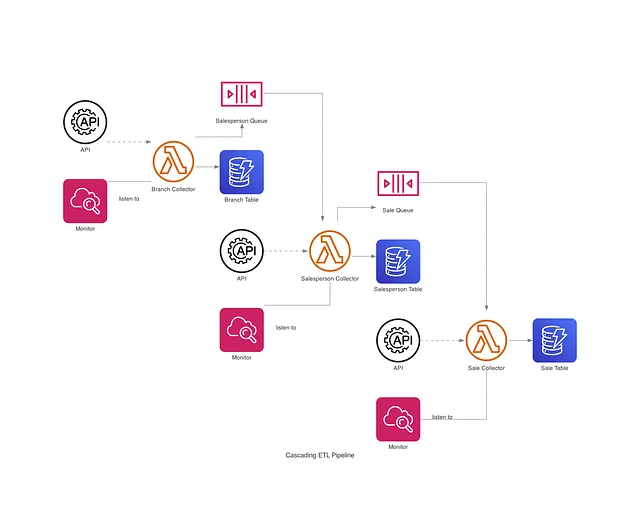
Background
Diciamo che sei un ingegnere dei dati e hai bisogno di aggiornare costantemente i dati nel data warehouse. Ad esempio, sei responsabile di sincronizzarti regolarmente con i record delle vendite di Dunder Mifflin Paper Co. (Capisco che questo non è uno scenario realistico, ma divertiamoci :)!) I dati ti vengono inviati tramite un’API di un fornitore e sei responsabile di assicurarti che le informazioni sulle filiali, sugli dipendenti (in realtà solo i venditori sono considerati) e sulle vendite siano aggiornate. L’API fornita ha i seguenti 3 percorsi:
/branches, accetta il nome della filiale come parametro di query per recuperare i metadati di una filiale specifica;/employees, accetta l’ID della filiale come parametro di query per recuperare le informazioni di tutti i suoi dipendenti di una determinata filiale, la risposta include una coppia chiave-valore che indica le occupazioni dei dipendenti;/sales, accetta l’ID del dipendente come parametro di query per recuperare tutti i record di vendite di un venditore, la risposta include una coppia chiave-valore che indica quando è stata completata la transazione.
Quindi, in generale, i risultati dell’API hanno questo aspetto:
- Quantizzazione a 4 bit con GPTQ
- Guida del Data Scientist alla tipizzazione in Python migliorare la chiarezza del codice
- Predizione di serie temporali multivariate con BQML
Percorso /branches:
{ "result": [ { "id": 1, "branch_name": "Scranton"…
