Costruisci modelli di ML ad alte prestazioni utilizzando PyTorch 2.0 su AWS – Parte 1.
Build high-performance ML models using PyTorch 2.0 on AWS - Part 1.
PyTorch è un framework di machine learning (ML) ampiamente utilizzato dai clienti AWS per una varietà di applicazioni, come la visione artificiale, l’elaborazione del linguaggio naturale, la creazione di contenuti e altro ancora. Con il recente rilascio di PyTorch 2.0, i clienti AWS possono fare le stesse cose che potevano fare con PyTorch 1.x ma più velocemente e su scala con migliori velocità di formazione, uso ridotto della memoria e capacità distribuite migliorate. Diversi nuovi tecnologie, tra cui torch.compile, TorchDynamo, AOTAutograd, PrimTorch e TorchInductor, sono state incluse nel rilascio di PyTorch 2.0. Fare riferimento a PyTorch 2.0: il nostro rilascio di prossima generazione che è più veloce, più Pythonico e dinamico che mai per i dettagli.
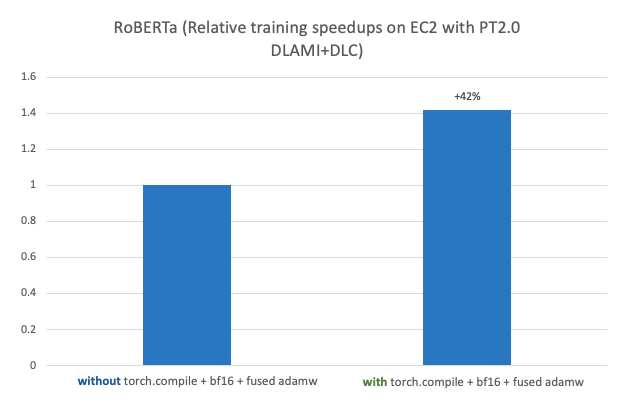
Questo post dimostra le prestazioni e la facilità di esecuzione dell’addestramento di modelli ML distribuiti su larga scala ad alte prestazioni e della distribuzione utilizzando PyTorch 2.0 su AWS. Questo post mostra inoltre un’implementazione passo passo del fine-tuning di un modello RoBERTa (Robustly Optimized BERT Pretraining Approach) per l’analisi dei sentimenti utilizzando AWS Deep Learning AMI (AWS DLAMI) e AWS Deep Learning Containers (DLC) su Amazon Elastic Compute Cloud (Amazon EC2 p4d.24xlarge) con un aumento delle prestazioni del 42% quando utilizzato con PyTorch 2.0 torch.compile + bf16 + fused AdamW. Il modello fine-tuned viene quindi distribuito su un’istanza C7g EC2 basata su AWS Graviton su Amazon SageMaker con un aumento delle prestazioni del 10% rispetto a PyTorch 1.13.
La seguente figura mostra un benchmark delle prestazioni del fine-tuning di un modello RoBERTa su Amazon EC2 p4d.24xlarge con AWS PyTorch 2.0 DLAMI + DLC.
- Annuncio estrazioni di tabelle migliorate con Amazon Textract
- Presentiamo la messa a punto della popolarità per elementi simili in Amazon Personalize.
- Barkour Misurare le capacità di agilità a livello animale con robot quadrupedi
Fare riferimento a PyTorch 2.0 di ottimizzazione dell’infrazione con i processori AWS Graviton per i dettagli sulle prestazioni dei benchmark dell’infrazione basati su istanze AWS Graviton per PyTorch 2.0.
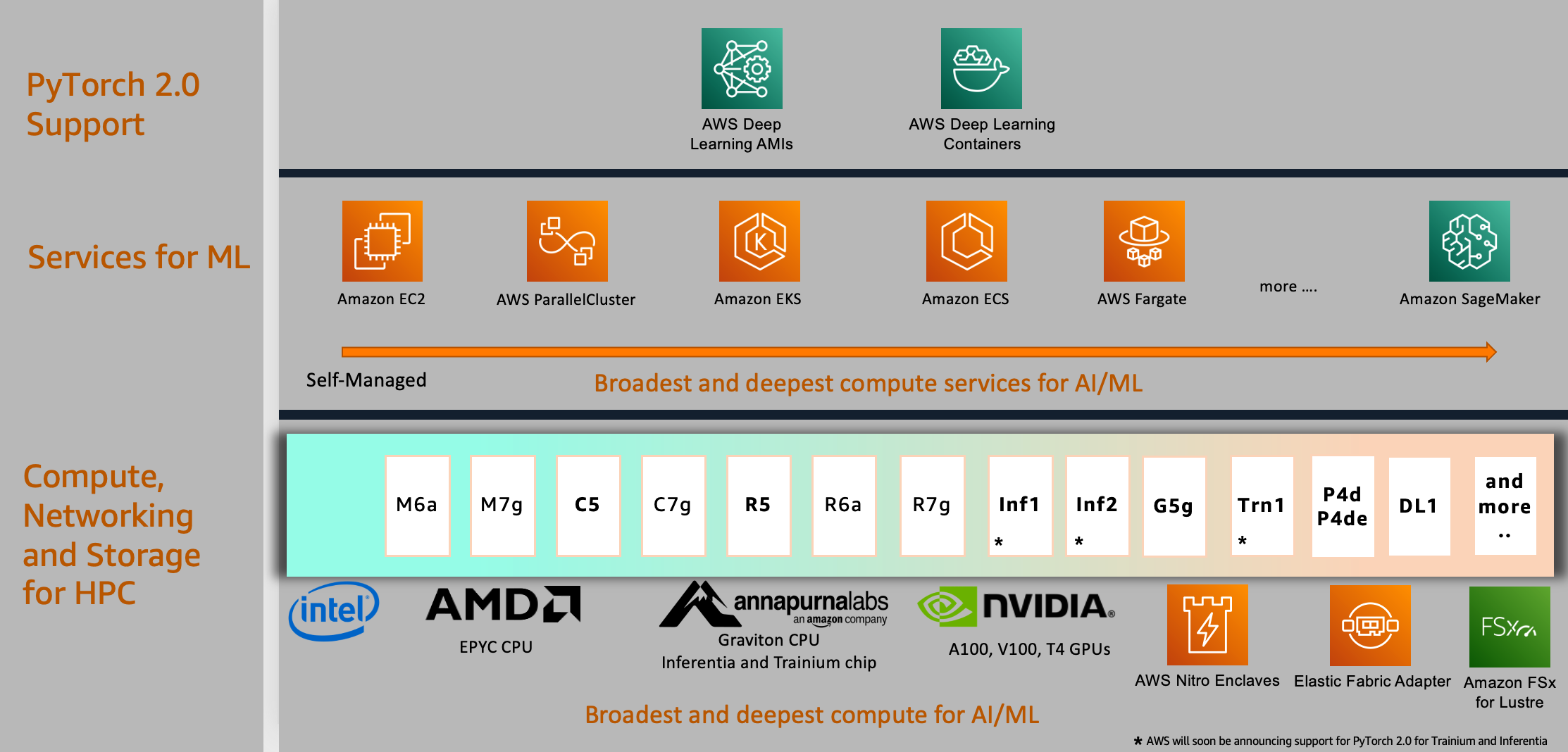
Supporto per PyTorch 2.0 su AWS
Il supporto di PyTorch2.0 non è limitato ai servizi e ai calcoli mostrati nell’esempio di caso d’uso in questo post; si estende a molti altri su AWS, di cui discutiamo in questa sezione.
Requisito di business
Molti clienti AWS, in un insieme diversificato di settori, stanno trasformando le loro attività mediante l’utilizzo di intelligenza artificiale (AI), in particolare nell’area di AI generativa e modelli di linguaggio di grandi dimensioni (LLM) progettati per generare testo simile a quello umano. Questi sono fondamentalmente modelli basati su tecniche di deep learning che vengono addestrati con centinaia di miliardi di parametri. La crescita delle dimensioni dei modelli sta aumentando il tempo di formazione da giorni a settimane e persino mesi in alcuni casi. Ciò sta guidando un aumento esponenziale dei costi di addestramento e infrazione, che richiede, più che mai, un framework come PyTorch 2.0 con supporto integrato per l’addestramento accelerato di modelli e l’infrastruttura ottimizzata di AWS adattata alle specifiche esigenze di carico di lavoro e prestazioni.
Scelta del calcolo
AWS fornisce il supporto per PyTorch 2.0 sulla più ampia scelta di potenti calcoli, reti ad alta velocità e opzioni di archiviazione ad alte prestazioni scalabili che è possibile utilizzare per qualsiasi progetto o applicazione di ML e personalizzare per soddisfare le tue esigenze di prestazioni e budget. Ciò è manifestato nel diagramma nella sezione successiva; nel livello inferiore, forniamo una vasta selezione di istanze di calcolo alimentate da processori AWS Graviton, Nvidia, AMD e Intel.
Per la distribuzione di modelli, è possibile utilizzare processori basati su ARM come l’istanza basata su AWS Graviton recentemente annunciata che fornisce prestazioni di infrazione per PyTorch 2.0 con una velocità fino a 3,5 volte superiore per Resnet50 rispetto al rilascio precedente di PyTorch e fino a 1,4 volte la velocità per BERT, rendendo le istanze basate su AWS Graviton le istanze a calcolo ottimizzato più veloci su AWS per le soluzioni di infrazione basate su CPU.
Scelta dei servizi di ML
Per utilizzare il calcolo di AWS, è possibile selezionare un’ampia gamma di servizi cloud globali per lo sviluppo, il calcolo e l’orchestrazione del flusso di lavoro di ML. Questa scelta consente di allinearsi con le strategie aziendali e cloud e di eseguire lavori PyTorch 2.0 sulla piattaforma di tua scelta. Ad esempio, se hai restrizioni in locale o investimenti esistenti in prodotti open source, puoi utilizzare Amazon EC2, AWS ParallelCluster o AWS UltraCluster per eseguire carichi di lavoro di addestramento distribuito basati su un approccio autogestito. Puoi anche utilizzare un servizio completamente gestito come SageMaker per un’infrastruttura di formazione su larga scala, completamente gestita e ottimizzata per i costi. SageMaker si integra anche con vari strumenti MLOps, che ti consentono di scalare la distribuzione del tuo modello, ridurre i costi di infrazione, gestire i modelli in modo più efficace in produzione e ridurre il carico operativo.
In modo simile, se si hanno investimenti esistenti in Kubernetes, è possibile utilizzare anche Amazon Elastic Kubernetes Service (Amazon EKS) e Kubeflow su AWS per implementare un pipeline di ML per l’addestramento distribuito o utilizzare un servizio di orchestrazione dei container nativo di AWS come Amazon Elastic Container Service (Amazon ECS) per l’addestramento e il rilascio dei modelli. Le opzioni per costruire la propria piattaforma di ML non sono limitate a questi servizi; è possibile scegliere a seconda delle esigenze organizzative per i propri lavori PyTorch 2.0.
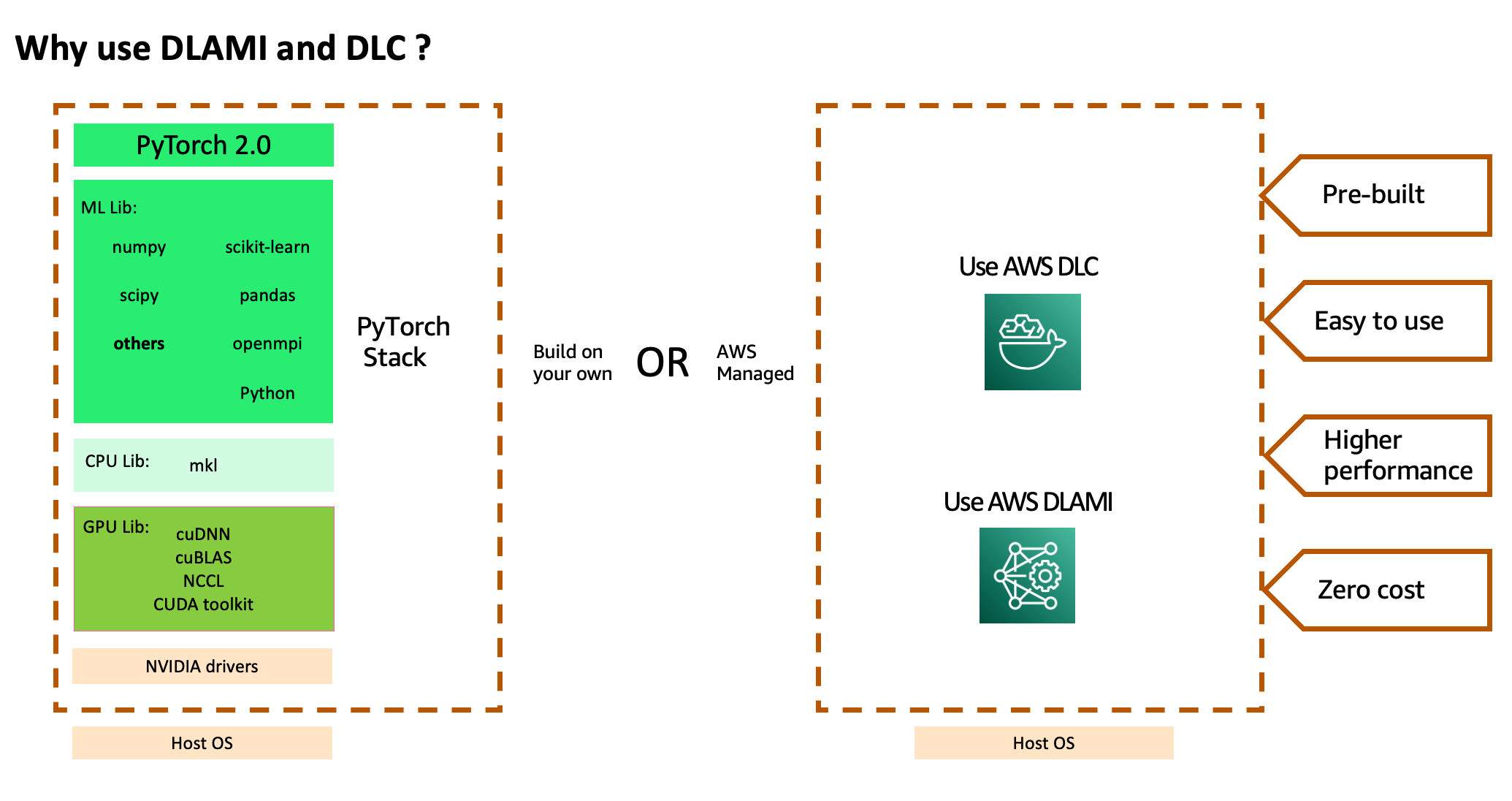
Abilitazione di PyTorch 2.0 con AWS DLAMI e AWS DLC
Per utilizzare lo stack di servizi AWS e la potente elaborazione, è necessario installare una versione compilata ottimizzata del framework PyTorch2.0 e le sue dipendenze richieste, molte delle quali sono progetti indipendenti, e testarle dall’inizio alla fine. Potrebbero essere necessarie anche librerie specifiche per la CPU per le routine matematiche accelerate, librerie specifiche per la GPU per le routine di calcolo matematico e di comunicazione inter-GPU e driver GPU che devono essere allineati con il compilatore GPU utilizzato per compilare le librerie GPU. Se i propri lavori richiedono l’addestramento multi-nodo su larga scala, è necessaria una rete ottimizzata che possa fornire la latenza più bassa e la massima larghezza di banda. Dopo aver costruito lo stack, è necessario eseguire regolarmente la scansione e la correzione per le vulnerabilità di sicurezza e ricostruire e testare lo stack dopo ogni aggiornamento della versione del framework.
AWS aiuta a ridurre questo lavoro pesante offrendo un insieme curato e sicuro di framework, dipendenze e strumenti per accelerare l’apprendimento profondo nel cloud attraverso AWS DLAMIs e AWS DLCs . Queste immagini di macchine e container pre-costruiti e testati sono ottimizzati per l’apprendimento profondo su EC2 Accelerated Computing Instance types, consentendo di scalare su più nodi per carichi di lavoro distribuiti in modo più efficiente e facile. Comprende un adattatore tessile elastico pre-costruito (EFA), uno stack GPU Nvidia e molti framework di apprendimento profondo (TensorFlow, MXNet e PyTorch con l’ultima versione di 2.0) per l’addestramento distribuito ad alte prestazioni di apprendimento profondo. Non è necessario spendere tempo nell’installazione e nella risoluzione dei problemi del software e dei driver di apprendimento profondo o nella costruzione dell’infrastruttura di ML, né è necessario sostenere il costo ricorrente della correzione di queste immagini per le vulnerabilità di sicurezza o della ricreazione delle immagini dopo ogni nuovo aggiornamento della versione del framework. Invece, è possibile concentrarsi sul valore aggiunto più elevato degli incarichi di formazione su larga scala in un periodo di tempo più breve e sulla modellizzazione di ML più veloce.
Panoramica della soluzione
Considerando che l’addestramento sulla GPU e l’inferenza sulla CPU è un caso d’uso popolare per i clienti AWS, abbiamo incluso come parte di questo post un’implementazione step-by-step di un’architettura ibrida (come mostrato nel seguente diagramma). Esploreremo l’arte del possibile e utilizzeremo un’istanza P4 EC2 con supporto BF16 inizializzata con Base GPU DLAMI che include i driver NVIDIA, CUDA, NCCL, EFA stack e PyTorch2.0 DLC per il fine-tuning di un modello di analisi del sentiment RoBERTa che offre controllo e flessibilità nell’uso di qualsiasi libreria open-source o proprietaria. Quindi utilizziamo SageMaker per un’infrastruttura di hosting modello completamente gestita per ospitare il nostro modello su istanze C7g basate su AWS Graviton3 . Abbiamo scelto C7g su SageMaker perché è stato dimostrato di ridurre i costi di inferenza fino al 50% rispetto alle istanze EC2 comparabili per l’inferenza in tempo reale su SageMaker. Il seguente diagramma illustra questa architettura.
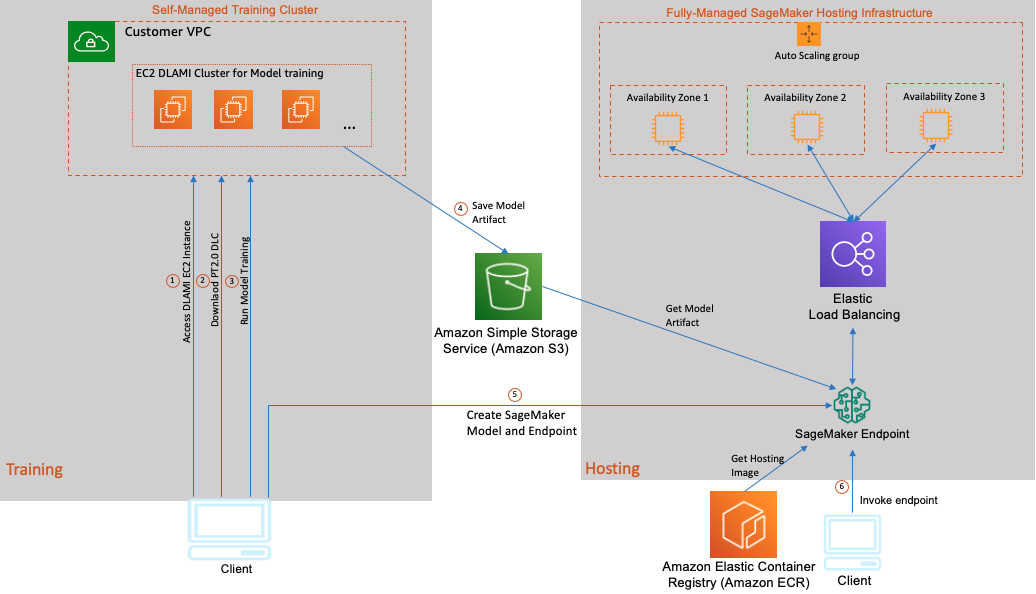
L’addestramento e l’hosting del modello in questo caso d’uso consistono nei seguenti passaggi:
- Avviare un’istanza EC2 Ubuntu basata su GPU DLAMI nella propria VPC e connettersi all’istanza utilizzando SSH.
- Dopo aver effettuato l’accesso all’istanza EC2, scaricare il DLC PyTorch 2.0 di AWS.
- Eseguire il proprio container DLC con uno script di addestramento del modello per il fine-tuning del modello RoBERTa.
- Dopo il completamento dell’addestramento del modello, imballare il modello salvato, gli script di inferenza e alcuni file di metadati in un file tar che l’inferenza di SageMaker può utilizzare e caricare il pacchetto del modello su un bucket di Amazon Simple Storage Service (Amazon S3).
- Implementare il modello utilizzando SageMaker e creare un endpoint di inferenza HTTPS. L’endpoint di inferenza di SageMaker contiene un bilanciatore di carico e una o più istanze del proprio container di inferenza in diverse Zone di disponibilità. È possibile implementare più versioni dello stesso modello o modelli completamente diversi dietro questo singolo endpoint. In questo esempio, ospitiamo un singolo modello.
- Richiamare il proprio endpoint del modello inviando dati di test e verificare l’output di inferenza.
Nelle sezioni seguenti, mostriamo come sintonizzare un modello RoBERTa per l’analisi del sentiment. RoBERTa è sviluppato da Facebook AI, migliorando il popolare modello BERT modificando i parametri chiave e pre-addestrandolo su un corpus più grande. Ciò porta a prestazioni migliori rispetto a vanilla BERT.
Usiamo la libreria transformers di Hugging Face per ottenere il modello RoBERTa pre-addestrato su circa 124 milioni di tweet e lo sintonizziamo sul dataset di Twitter per l’analisi del sentiment.
Prerequisiti
Assicurati di soddisfare i seguenti prerequisiti:
- Hai un account AWS.
- Assicurati di essere nella regione
us-west-2per eseguire questo esempio. (Questo esempio è testato inus-west-2; tuttavia, puoi eseguirlo in qualsiasi altra regione.) - Crea un ruolo con il nome
sagemakerrole. Aggiungi le politiche gestiteAmazonSageMakerFullAccesseAmazonS3FullAccessper dare a SageMaker l’accesso ai bucket S3. - Crea un ruolo EC2 con il nome
ec2_role. Usa la seguente policy di autorizzazione:
#Refer - Assicurati che il ruolo EC2 abbia le seguenti politiche
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"ecr:BatchGetImage",
"ecr:BatchCheckLayerAvailability",
"ecr:CompleteLayerUpload",
"ecr:GetDownloadUrlForLayer",
"ecr:InitiateLayerUpload",
"ecr:PutImage",
"ecr:UploadLayerPart",
"ecr:GetAuthorizationToken",
"s3:*",
"s3-object-lambda:*",
"iam:Get*",
"iam:PassRole",
"sagemaker:*"
],
"Resource": "*"
}
]
}1. Avvia la tua istanza di sviluppo
Crea un’istanza p4d.24xlarge che offre 8 GPU NVIDIA A100 Tensor Core in us-west-2:
#STEP 1.1
Per una breve guida sul lancio della tua istanza, leggi la documentazione Introduzione ad Amazon EC2.Nella selezione dell’AMI, segui le note sulla versione per eseguire questo comando utilizzando l’interfaccia della riga di comando di AWS (AWS CLI) per trovare l’ID AMI da utilizzare in us-west-2:
#STEP 1.2 - Ciò richiede le credenziali AWS CLI per chiamare l'API ec2 describe-images (ec2:DescribeImages).
aws ec2 describe-images --region us-west-2 --owners amazon --filters 'Name=name,Values=Deep Learning Base GPU AMI (Ubuntu 20.04) ????????' 'Name=state,Values=available' --query 'reverse(sort_by(Images, &CreationDate))[:1].ImageId' --output text Assicurati che la dimensione del volume radice gp3 sia di 200 GiB.
La crittografia del volume EBS non è abilitata per impostazione predefinita. Considera di modificare questo aspetto quando si sposta questa soluzione in produzione.
2. Scarica un contenitore di deep learning
I DLC AWS sono disponibili come immagini Docker in Amazon Elastic Container Registry Public, un servizio di registro di immagini di contenitori AWS gestito, sicuro, scalabile e affidabile. Ogni immagine Docker è costruita per l’addestramento o l’elaborazione su una specifica versione di framework di deep learning, versione di Python, con supporto CPU o GPU. Seleziona il framework PyTorch 2.0 dall’elenco delle immagini di contenitori di deep learning disponibili.
Completa i seguenti passaggi per scaricare il tuo DLC:
a. Accedi tramite SSH all’istanza. Per impostazione predefinita, il gruppo di sicurezza utilizzato con EC2 apre la porta SSH a tutti. Consideralo se stai spostando questa soluzione in produzione:
#STEP 2.1 - Usa l'IP pubblico
ssh -i ~/.ssh/<pub_key> ubuntu@<IP_ADDR>
#Refer - Output: Nota il pacchetto python3.9 che useremo per eseguire e installare gli script di inferenza
__| __|_ )
_| ( / Deep Learning Base GPU AMI (Ubuntu 20.04)
___|\___|___|
Benvenuto in Ubuntu 20.04.6 LTS (GNU/Linux 5.15.0-1035-aws x86_64v)
* Si prega di notare che l'istanza Amazon EC2 P2 non è supportata nell'attuale DLAMI.
* Istanze EC2 supportate: G3, P3, P3dn, P4d, P4de, G5, G4dn.
Versione del driver NVIDIA: 525.85.12
Versione CUDA predefinita: 11.2
Le librerie di utilità sono installate in /usr/bin/python3.9.
Per accedervi, utilizza /usr/bin/python3.9.Per impostazione predefinita, il gruppo di sicurezza utilizzato con Amazon EC2 apre la porta SSH a tutti. Considera di cambiarlo se stai spostando questa soluzione in produzione.
b. Imposta le variabili d’ambiente necessarie per eseguire i passaggi rimanenti di questa implementazione:
#PASSAGGIO 2.2
Allega il ruolo "ec2_role" alla tua istanza EC2 dalla console AWS.
#PASSAGGIO 2.3
Seguire i passaggi qui per creare un bucket S3 nella regione us-west-2
#PASSAGGIO 2.4 - Imposta le variabili d'ambiente
#Bucket creato nel passaggio 2.3
esporta S3_BUCKET=<tuo-s3-bucket>
esporta PYTHON_V=python3.9
esporta SAGEMAKER_ROLE=$(aws iam get-role --role-name sagemakerrole --output text --query 'Role.Arn')
aws configure set default.region 'us-west-2'Amazon ECR supporta i repository di immagini pubbliche con autorizzazioni basate sulle risorse utilizzando AWS Identity and Access Management (IAM) in modo che determinati utenti o servizi possano accedere alle immagini.
c. Accedi al registro DLC:
#PASSAGGIO 2.5 - accesso
aws ecr get-login-password --region us-west-2 | docker login --username AWS --password-stdin 763104351884.dkr.ecr.us-west-2.amazonaws.com
#Riferimento - Output
Accesso riuscitod. Scarica l’ultima immagine PyTorch 2.0 con supporto per GPU in us-west-2
#PASSAGGIO 2.6 - scarica l'ultima immagine DLC PyTorch
docker pull 763104351884.dkr.ecr.us-west-2.amazonaws.com/pytorch-training:2.0.0-gpu-py310-cu118-ubuntu20.04-ec2
#Riferimento - Output
7608715873ec: Scaricato
a0bad51e1731: Scaricato
f7778ea3b9cc: Scaricato
....
Digest: sha256:1ab0d477345a11970d811cc252bc461dd70859f15caa19a65198e7941953e6b8
Stato: Scaricata l'immagine più recente per 763104351884.dkr.ecr.us-west-2.amazonaws.com/pytorch-training:2.0.0-gpu-py310-cu118-ubuntu20.04-ec2
763104351884.dkr.ecr.us-west-2.amazonaws.com/pytorch-training:2.0.0-gpu-py310-cu118-ubuntu20.04-ec2Se si riceve l’errore “no space left on device”, assicurarsi di aumentare il volume EBS di EC2 a 200 GiB e quindi estendere il sistema di file Linux.
3. Clona gli ultimi script adattati a PyTorch 2.0
Clona gli script con il seguente codice:
#PASSAGGIO 3.1
cd $HOME
git clone https://github.com/aws-samples/aws-deeplearning-labs.git
cd aws-deeplearning-labs/workshop/twitter_lm/scripts/
esporta ml_working_dir=$PWDPoiché stiamo usando l’API delle trasformazioni Hugging Face con l’ultima versione 4.28.1, ha già abilitato il supporto PyTorch 2.0. Abbiamo aggiunto il seguente argomento all’API del formatore in train_sentiment.py per abilitare le nuove funzionalità PyTorch 2.0:
- Torch compile – Sperimenta un miglioramento medio del 43% sulle GPU Nvidia A100 con una sola riga di modifica.
- Tipo di dati BF16 – Nuovo supporto per il tipo di dati (Brain Floating Point) per GPU Ampere o più recenti.
- Optimizer AdamW fuso – Implementazione AdamW fusa per accelerare ulteriormente la formazione. Questo metodo di ottimizzazione stocastica modifica l’implementazione tipica della decadimento del peso in Adam separando il decadimento del peso dall’aggiornamento del gradiente.
#Riferimento - configurazione di formazione aggiornata
training_args = TrainingArguments(
do_eval=True,
evaluation_strategy='epoch',
output_dir='test_trainer',
logging_dir='test_trainer',
logging_strategy='epoch',
save_strategy='epoch',
num_train_epochs=10,
learning_rate=1e-05,
# argomenti specifici di pytorch 2.0.0
torch_compile=True,
bf16=True,
optim='adamw_torch_fused',
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
load_best_model_at_end=True,
metric_for_best_model='recall',
)4. Costruire una nuova immagine Docker con le dipendenze
Estendiamo l’immagine pre-costruita di PyTorch 2.0 DLC per installare il transformer di Hugging Face e altre librerie di cui abbiamo bisogno per ottimizzare il nostro modello. Ciò ti consente di utilizzare le librerie di deep learning incluse, testate e ottimizzate senza dover creare un’immagine da zero. Vedi il codice seguente:
#STEP 4.1 - Crea Dockerfile con il seguente contenuto
printf 'FROM 763104351884.dkr.ecr.us-west-2.amazonaws.com/pytorch-training:2.0.0-gpu-py310-cu118-ubuntu20.04-ec2
RUN pip install scikit-learn evaluate transformers xformers
' > Dockerfile
#STEP 4.2 - Costruisci il nuovo file Docker
docker build -f Dockerfile -t pytorch2.0:roberta-sentiment-analysis .5. Inizia l’addestramento usando il container
Esegui il seguente comando Docker per iniziare l’ottimizzazione del modello sul dataset di sentiment tweet_eval. Stiamo usando gli argomenti del container Docker (dimensione della memoria condivisa, memoria massima bloccata e dimensione dello stack) raccomandati da Nvidia per i carichi di lavoro di deep learning.
#STEP 5.1 - Esegui il container Docker per l'addestramento del modello
docker run --net=host --uts=host --ipc=host --shm-size=1g --ulimit stack=67108864 --ulimit memlock=-1 --gpus all -v "/home/ubuntu:/workspace" pytorch2.0:roberta-sentiment-analysis python /workspace/aws-deeplearning-labs/workshop/twitter_lm/scripts/train_sentiment.pyDovresti aspettarti l’output seguente. Lo script scarica prima il dataset TweetEval, che consiste in sette task eterogenei in Twitter, tutti inquadrati come classificazione di tweet multiclasse. I task includono ironia, odio, offensivo, posizione, emoji, emozione e sentiment.
Lo script quindi scarica il modello di base e avvia il processo di ottimizzazione. Le metriche di addestramento ed valutazione sono riportate alla fine di ogni epoch.
#Riferimento - Output
{'loss': 0.6927, 'learning_rate': 9e-06, 'epoch': 1.0}
{'eval_loss': 0.6144512295722961, 'eval_recall': 0.7129473901625799, 'eval_runtime': 3.2694, 'eval_samples_per_second': 611.74, 'eval_steps_per_second': 4.894, 'epoch': 1.0}
{'loss': 0.5554, 'learning_rate': 8.000000000000001e-06, 'epoch': 2.0}
{'eval_loss': 0.5860999822616577, 'eval_recall': 0.7312511094156663, 'eval_runtime': 3.3918, 'eval_samples_per_second': 589.655, 'eval_steps_per_second': 4.717, 'epoch': 2.0}
{'loss': 0.5084, 'learning_rate': 7e-06, 'epoch': 3.0}
{'eval_loss': 0.6119785308837891, 'eval_recall': 0.730757638985487, 'eval_runtime': 3.592, 'eval_samples_per_second': 556.791, 'eval_steps_per_second': 4.454, 'epoch': 3.0}Statistiche di performance
Con PyTorch 2.0 e l’ultima libreria di Hugging Face transformers 4.28.1, abbiamo osservato un miglioramento del 42% su una singola istanza p4d.24xlarge con 8 GPU A100 da 40 GB. I miglioramenti delle performance derivano dalla combinazione di torch.compile, il tipo di dato BF16 e l’ottimizzatore AdamW fuso. Il codice seguente è il risultato finale di due esecuzioni di addestramento con e senza le nuove funzionalità:
#Riferimento statistiche di performance
senza torch.compile + bf16 + fused adamw:
{'eval_loss': 0.7532123327255249, 'eval_recall': 0.7315191840508296, 'eval_runtime': 3.7641, 'eval_samples_per_second': 531.341, 'eval_steps_per_second': 4.251, 'epoch': 10.0}
{'train_runtime': 1891.5635, 'train_samples_per_second': 241.15, 'train_steps_per_second': 1.887, 'train_loss': 0.4372138784713104, 'epoch': 10.0}
con torch.compile + bf16 + fused adamw
{'eval_loss': 0.7548801898956299, 'eval_recall': 0.7251081080195005, 'eval_runtime': 3.5685, 'eval_samples_per_second': 560.453, 'eval_steps_per_second': 4.484, 'epoch': 10.0}
{'train_runtime': 1095.388, 'train_samples_per_second': 416.428, 'train_steps_per_second': 3.259, 'train_loss': 0.44210514314368327, 'epoch': 10.0}6. Testare il modello addestrato in locale prima di prepararsi per l’ inferenza SageMaker
Puoi trovare i seguenti file sotto $ml_working_dir/saved_model/ dopo l’addestramento:
#Refer - artefatti di addestramento del modello
config.json
merges.txt
pytorch_model.bin
special_tokens_map.json
tokenizer.json
tokenizer_config.json
vocab.jsonAssicuriamoci di poter eseguire l’ inferenza in locale prima di prepararci per l’ inferenza SageMaker. Possiamo caricare il modello salvato ed eseguire l’ inferenza in locale utilizzando lo script test_trained_model.py:
#STEP 6.1 - esegui il container docker per l' inferenza del modello di prova
docker run --net=host --uts=host --ipc=host --ulimit stack=67108864 --ulimit memlock=-1 --gpus all -v "/home/ubuntu:/workspace" pytorch2.0:roberta-sentiment-analysis python /workspace/aws-deeplearning-labs/workshop/twitter_lm/scripts/test_trained_model.pyDovresti aspettarti il seguente output con l’input “I casi di Covid stanno aumentando velocemente!”:
#Refer - Output
[{'label': 'negative', 'score': 0.854185163974762}]7. Prepara il pacchetto del modello per l’ inferenza SageMaker
Nella directory in cui si trova il modello, crea una nuova directory chiamata code:
#STEP 7.1 - imposta i permessi
cd $ml_working_dir
sudo chown ubuntu:ubuntu saved_model
cd saved_model
mkdir codeNella nuova directory, crea il file inference.py e aggiungi il seguente:
#STEP 7.2 - scrivi inference.py
printf 'import json
from transformers import pipeline
REQUEST_CONTENT_TYPE = "application/x-text"
STR_DECODE_CODE = "utf-8"
RESULT_CLASS = "sentiment"
RESULT_SCORE = "score"
def model_fn(model_dir):
sentiment_analysis = pipeline(
"sentiment-analysis",
model=model_dir,
tokenizer=model_dir,
return_all_scores=True
)
return sentiment_analysis
def input_fn(request_body, request_content_type):
if request_content_type == REQUEST_CONTENT_TYPE:
input_data = request_body.decode(STR_DECODE_CODE)
return input_data
def predict_fn(input_data, model):
return model(input_data)
def output_fn(prediction, accept):
class_label = None
score = -1
for _pred in prediction[0]:
if _pred["score"] > score:
score = _pred["score"]
class_label = _pred["label"]
return json.dumps({RESULT_CLASS: class_label, RESULT_SCORE: score})' > code/inference.pyCrea un altro file nella stessa directory chiamato requirements.txt e inserisci transformers al suo interno. SageMaker installa le dipendenze in requirements.txt nel contenitore di inferenza per te.
#STEP 7.3 - scrivi requirements.txt
printf 'transformers' > code/requirements.txtAlla fine, dovresti avere la seguente struttura della cartella:
#Refer - struttura della cartella del pacchetto di inferenza
code/
code/inference.py
code/requirements.txt
config.json
merges.txt
pytorch_model.bin
special_tokens_map.json
tokenizer.json
tokenizer_config.json
vocab.jsonIl modello è pronto per essere confezionato e caricato su Amazon S3 per l’utilizzo con l’ inferenza SageMaker:
#STEP 7.4 - crea il file tar del pacchetto di inferenza e caricarlo su S3
sudo tar -cvpzf ./personal-roberta-base-sentiment.tar.gz -C ./ .
aws s3 cp ./personal-roberta-base-sentiment.tar.gz s3://$S3_BUCKET8. Distribuisci il modello su un’istanza SageMaker AWS Graviton
Le nuove generazioni di CPU offrono un significativo miglioramento delle prestazioni nell’ inferenza di ML grazie alle istruzioni incorporate specializzate. In questo caso d’uso, utilizziamo l’infrastruttura di hosting completamente gestita di SageMaker con le istanze C7g basate su AWS Graviton3. AWS ha anche misurato un risparmio dei costi fino al 50% per l’ inferenza PyTorch con le istanze EC2 C7g basate su AWS Graviton3 rispetto a istanze EC2 comparabili con Torch Hub ResNet50 e molti modelli di Hugging Face.
Per distribuire i modelli su istanze AWS Graviton, utilizziamo i DLC AWS che forniscono supporto per PyTorch 2.0 e TorchServe 0.8.0, oppure è possibile utilizzare i propri contenitori compatibili con l’architettura ARMv8.2.
Utilizziamo il modello che abbiamo addestrato in precedenza: s3://<your-s3-bucket>/twitter-roberta-base-sentiment-latest.tar.gz. Se non hai mai usato SageMaker prima, leggi la guida: Iniziare con Amazon SageMaker.
Per iniziare, assicurati che il pacchetto SageMaker sia aggiornato:
#STEP 8.1 - Installa la libreria SageMaker
cd $ml_working_dir
$PYTHON_V -m pip install -U sagemakerPerché si tratta di un esempio, crea un file chiamato start_endpoint.py e aggiungi il seguente codice. Questo sarà lo script Python per avviare un endpoint di inferenza SageMaker con la modalità:
#STEP 8.2 - scrivi start_endpoint.py
printf '# Importa alcuni moduli necessari
from sagemaker import get_execution_role, Session, image_uris
from sagemaker.model import Model
import boto3
import os
model_name = "pytorch-roberta-model"
# Imposta la sessione SageMaker
region = boto3.Session().region_name
role = os.environ.get("SAGEMAKER_ROLE")
sm_client = boto3.client("sagemaker", region_name=region)
sagemaker_session = Session()
bucket = os.environ.get("S3_BUCKET")
# Seleziona il contenitore. Nel nostro caso, è graviton
container_uri = image_uris.retrieve(
region="us-west-2",
framework="pytorch",
version="2.0.0",
image_scope="inference_graviton")
# Imposta i parametri del modello
model = Model(
image_uri=container_uri,
model_data=f"s3://{bucket}/personal-roberta-base-sentiment.tar.gz",
role=role,
name=model_name,
sagemaker_session=sagemaker_session
)
# Distribuisci il modello
endpoint = model.deploy(
initial_instance_count=1,
instance_type="ml.c7g.4xlarge",
endpoint_name="sm-endpoint-" + model_name
)' > start_endpoint.pyStiamo utilizzando ml.c7g.4xlarge per l’istanza e stiamo recuperando PT 2.0 con uno scope di immagine inference_graviton. Questa è la nostra istanza AWS Graviton3.
Successivamente, creiamo il file che esegue la previsione. Li facciamo come script separati in modo da poter eseguire le previsioni quante volte vogliamo. Crea predict.py con il seguente codice:
#STEP 8.3 - scrivi predict.py
printf 'import boto3
from boto3 import Session, client
model_name = "pytorch-roberta-model"
data = "Scrivere dati per analizzare i sentimenti e vedere come vengono visualizzati i dati"
sagemaker_runtime = boto3.client("sagemaker-runtime", region_name="us-west-2")
endpoint_name="sm-endpoint-" + model_name
print("Chiamata al modello:" + endpoint_name)
response = sagemaker_runtime.invoke_endpoint(
EndpointName=endpoint_name,
Body=bytes(data, "utf-8"),
ContentType="application/x-text",
)
print(response["Body"].read().decode("utf-8"))' > predict.pyCon gli script generati, possiamo ora avviare un endpoint, fare previsioni contro l’endpoint e pulire quando abbiamo finito:
#Step 8.4 - Avvia l'endpoint di inferenza SageMaker
$PYTHON_V start_endpoint.py
#Step 8.5 Effettua una previsione, questa può essere eseguita quante volte vogliamo
$PYTHON_V predict.py
#Refer - Output della previsione
Chiamata al modello:sm-endpoint-pytorch-roberta-model
{"sentiment": "neutro", "score": 0.9342969059944153}9. Pulizia
Infine, vogliamo ripulirci da questo esempio. Crea cleanup.py e aggiungi il seguente codice:
#STEP 9.1 Script di pulizia
printf 'from boto3 import client
model_name = "pytorch-roberta-model"
endpoint_name="sm-endpoint-" + model_name
sagemaker_client = client("sagemaker", region_name="us-west-2")
sagemaker_client.delete_endpoint(EndpointName=endpoint_name)
sagemaker_client.delete_endpoint_config(EndpointConfigName=endpoint_name)
sagemaker_client.delete_model(ModelName=model_name)' > cleanup.py
#Step 9.2 Pulizia
$PYTHON_V cleanup.pyConclusion
Le AWS DLAMI e i DLC sono diventati lo standard di riferimento per l’esecuzione di workload di deep learning su una vasta selezione di servizi di calcolo e di ML su AWS. Oltre all’utilizzo di DLC specifici per i framework sui servizi di ML di AWS, è possibile utilizzare anche un singolo framework su Amazon EC2, il che rimuove la maggior parte delle difficoltà necessarie per gli sviluppatori per costruire e mantenere applicazioni di deep learning. Consultare le note sulla versione per DLAMI e le immagini dei contenitori di deep learning disponibili per iniziare.
Questo post ha mostrato una delle molte possibilità per addestrare e servire il proprio prossimo modello su AWS e ha discusso diversi formati che è possibile adottare per soddisfare gli obiettivi aziendali. Prova questo esempio o utilizza i nostri altri servizi di ML su AWS per espandere la produttività dei dati per la tua attività. Abbiamo incluso un semplice problema di analisi del sentiment per permettere ai nuovi clienti di ML di capire quanto sia semplice iniziare con PyTorch 2.0 su AWS. Nel futuro, copriremo casi d’uso, modelli e tecnologie AWS più avanzati in prossimi post del blog.