Costruisci applicazioni di chatbot personalizzate utilizzando i modelli di OpenChatkit su Amazon SageMaker.
Build custom chatbot applications using OpenChatkit models on Amazon SageMaker.
I modelli di lingua open-source (LLM) sono diventati popolari, consentendo a ricercatori, sviluppatori e organizzazioni di accedere a questi modelli per favorire l’innovazione e la sperimentazione. Ciò incoraggia la collaborazione della comunità open-source per contribuire allo sviluppo e al miglioramento dei LLM. I LLM open-source forniscono trasparenza all’architettura del modello, al processo di formazione e ai dati di formazione, il che consente ai ricercatori di capire come funziona il modello e identificare eventuali pregiudizi e affrontare le preoccupazioni etiche. Questi LLM open-source stanno democratizzando l’IA generativa rendendo disponibile la tecnologia avanzata di elaborazione del linguaggio naturale (NLP) a un’ampia gamma di utenti per costruire applicazioni aziendali mission-critical. GPT-NeoX, LLaMA, Alpaca, GPT4All, Vicuna, Dolly e OpenAssistant sono alcuni dei popolari LLM open-source.
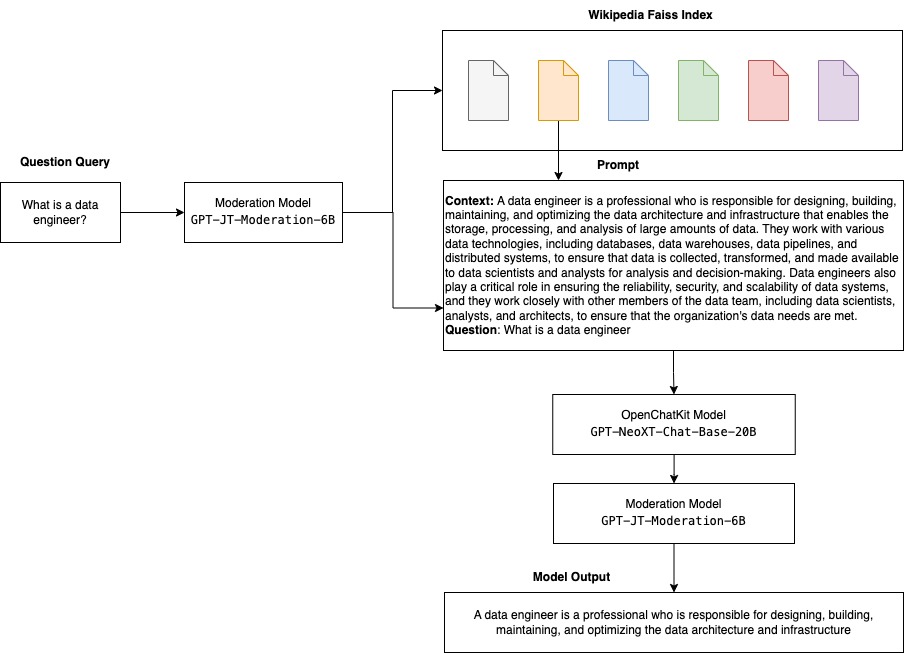
OpenChatKit è un LLM open-source utilizzato per costruire applicazioni di chatbot generiche e specializzate, rilasciato da Together Computer nel marzo 2023 sotto licenza Apache-2.0. Questo modello consente agli sviluppatori di avere maggior controllo sul comportamento del chatbot e di personalizzarlo per le loro specifiche applicazioni. OpenChatKit fornisce un set di strumenti, base bot e blocchi di costruzione per creare chatbot completamente personalizzati e potenti. I componenti chiave sono i seguenti:
- Un LLM sintonizzato sull’istruzione, sintonizzato per la chat da GPT-NeoX-20B di EleutherAI con oltre 43 milioni di istruzioni su un calcolo al 100% a carbonio negativo. Il modello
GPT-NeoXT-Chat-Base-20Bè basato sul modello GPT-NeoX di EleutherAI ed è sintonizzato con dati che si concentrano su interazioni in stile dialogo. - Ricette di personalizzazione per sintonizzare il modello per ottenere un’alta precisione sulle vostre attività.
- Un sistema di recupero estensibile che consente di aumentare le risposte del bot con informazioni da un repository di documenti, API o altre fonti di informazioni in tempo reale al momento dell’infusione.
- Un modello di moderazione, sintonizzato da GPT-JT-6B, progettato per filtrare a quali domande il bot risponde.
La crescente scala e dimensione dei modelli di apprendimento profondo presentano ostacoli per distribuire con successo questi modelli in applicazioni di IA generativa. Per soddisfare le esigenze di latenza ridotta e alta velocità di trasmissione, diventa essenziale utilizzare metodi sofisticati come il parallelismo del modello e la quantizzazione. Mancando di competenze nell’applicazione di questi metodi, numerosi utenti incontrano difficoltà nell’avviare l’hosting di modelli di dimensioni considerevoli per casi d’uso di IA generativa.
In questo post, mostriamo come distribuire i modelli OpenChatKit (modelli GPT-NeoXT-Chat-Base-20B e GPT-JT-Moderation-6B) su Amazon SageMaker utilizzando DJL Serving e librerie open-source di parallellismo del modello come DeepSpeed e Hugging Face Accelerate. Utilizziamo DJL Serving, che è una soluzione di servizio di modelli universale ad alta performance alimentata dalla Deep Java Library (DJL) che è agnostica del linguaggio di programmazione. Dimostriamo come la libreria Hugging Face Accelerate semplifichi la distribuzione di grandi modelli in più GPU, riducendo così il carico di esecuzione dei LLM in modo distribuito. Iniziamo!
- 16 casi d’uso di ChatGPT
- Dopo Amazon, l’ambizione di accelerare la produzione americana
- Q&A Gabriela Sá Pessoa sulla politica brasiliana, i diritti umani nell’Amazzonia e l’IA.
Sistema di recupero estensibile
Un sistema di recupero estensibile è uno dei componenti chiave di OpenChatKit. Consente di personalizzare la risposta del bot in base a una base di conoscenze a dominio chiuso. Sebbene i LLM siano in grado di conservare le conoscenze fattuali nei loro parametri di modello e possono raggiungere prestazioni notevoli nelle attività di NLP downstream quando sono sintonizzati, la loro capacità di accedere e prevedere conoscenze a dominio chiuso con precisione rimane limitata. Pertanto, quando vengono presentati con compiti ad alta intensità di conoscenza, le loro prestazioni sono inferiori a quelle delle architetture specifiche per il compito. È possibile utilizzare il sistema di recupero OpenChatKit per aumentare le conoscenze nelle loro risposte da fonti di conoscenza esterne come Wikipedia, repository di documenti, API e altre fonti di informazioni.
Il sistema di recupero consente al chatbot di accedere alle informazioni attuali ottenendo dettagli pertinenti in risposta a una query specifica, fornendo così il contesto necessario per il modello per generare risposte. Per illustrare la funzionalità di questo sistema di recupero, forniamo supporto per un indice di articoli di Wikipedia e offriamo codice di esempio che mostra come invocare un’API di ricerca web per il recupero delle informazioni. Seguendo la documentazione fornita, è possibile integrare il sistema di recupero con qualsiasi dataset o API durante il processo di infusione, consentendo al chatbot di incorporare dati dinamicamente aggiornati nelle sue risposte.
Modello di moderazione
I modelli di moderazione sono importanti nelle applicazioni di chatbot per imporre il filtraggio dei contenuti, il controllo della qualità, la sicurezza degli utenti e motivi legali e di conformità. La moderazione è un compito difficile e soggettivo e dipende molto dal dominio dell’applicazione di chatbot. OpenChatKit fornisce strumenti per moderare l’applicazione di chatbot e monitorare i prompt di testo di input per eventuali contenuti inappropriati. Il modello di moderazione fornisce una buona base che può essere adattata e personalizzata per vari bisogni.
OpenChatKit ha un modello di moderazione di 6 miliardi di parametri, GPT-JT-Moderation-6B, che può moderare il chatbot per limitare gli input ai soggetti moderati. Anche se il modello stesso ha una certa moderazione integrata, TogetherComputer ha addestrato un modello GPT-JT-Moderation-6B con il dataset di moderazione OIG di Ontocord.ai. Questo modello funziona insieme al chatbot principale per verificare che sia l’input dell’utente che la risposta del bot non contengano risultati inappropriati. È possibile utilizzare anche questo per rilevare eventuali domande fuori dal dominio del chatbot e annullare quando la domanda non fa parte del dominio del chatbot.
Il diagramma seguente illustra il flusso di lavoro di OpenChatKit.
Casi d’uso del sistema di recupero estensibile
Anche se possiamo applicare questa tecnica in vari settori per costruire applicazioni di intelligenza artificiale generative, in questo post discutiamo i casi d’uso nell’industria finanziaria. Il recupero aumentato dalla generazione può essere impiegato nella ricerca finanziaria per generare automaticamente rapporti di ricerca su specifiche aziende, settori o prodotti finanziari. Recuperando informazioni pertinenti da basi di conoscenza interne, archivi finanziari, articoli di notizie e ricerche, è possibile generare rapporti completi che riassumono le principali intuizioni, le metriche finanziarie, le tendenze di mercato e le raccomandazioni di investimento. È possibile utilizzare questa soluzione per monitorare e analizzare le notizie finanziarie, il sentiment del mercato e le tendenze.
Panoramica della soluzione
I seguenti passaggi sono coinvolti nella costruzione di un chatbot utilizzando i modelli OpenChatKit e nel loro rilascio su SageMaker:
- Scaricare il modello di base del chat
GPT-NeoXT-Chat-Base-20Be imballare gli artefatti del modello da caricare su Amazon Simple Storage Service (Amazon S3). - Utilizzare un contenitore di inferenza di modello grande di SageMaker, configurare le proprietà e impostare il codice di inferenza personalizzato per distribuire questo modello.
- Configurare le tecniche di parallelizzazione del modello e utilizzare le librerie di ottimizzazione dell’inferenza nelle proprietà di DJL Serving. Utilizzeremo Hugging Face Accelerate come motore per DJL Serving. Inoltre, definiamo le configurazioni parallele del tensore per partizionare il modello.
- Creare una configurazione del modello e del punto di endpoint SageMaker e distribuire il punto di endpoint SageMaker.
È possibile seguire eseguendo il notebook nel repo GitHub.
Scarica il modello OpenChatKit
Prima di tutto, scarichiamo il modello di base OpenChatKit. Utilizziamo huggingface_hub e utilizziamo snapshot_download per scaricare il modello, che scarica un’intera repository a una data revisione. I download vengono effettuati contemporaneamente per accelerare il processo. Vedere il seguente codice:
from huggingface_hub import snapshot_download
from pathlib import Path
import os
# - Questo scaricherà il modello nella directory corrente in cui viene eseguito il notebook jupyter
local_model_path = Path("./openchatkit")
local_model_path.mkdir(exist_ok=True)
model_name = "togethercomputer/GPT-NeoXT-Chat-Base-20B"
# Scarica solo i file di checkpoint pytorch
allow_patterns = ["*.json", "*.pt", "*.bin", "*.txt", "*.model"]
# - Sfrutta la libreria snapshot per scaricare il modello poiché il modello è archiviato nella repository utilizzando LFS
chat_model_download_path = snapshot_download(
repo_id=model_name,#Un nome utente o un nome di un'organizzazione e un nome di un repository
cache_dir=local_model_path, #Percorso della cartella in cui sono memorizzati i file in cache.
allow_patterns=allow_patterns, #vengono scaricati solo i file che corrispondono ad almeno un pattern.
)Proprietà di DJL Serving
È possibile utilizzare i contenitori LMI di SageMaker per ospitare grandi modelli di intelligenza artificiale generativi con codice di inferenza personalizzato senza fornire il proprio codice di inferenza. Ciò è estremamente utile quando non vi è alcuna personalizzazione personalizzata dei dati di input o della post-elaborazione delle previsioni del modello. È anche possibile distribuire un modello utilizzando un codice di inferenza personalizzato. In questo post, dimostriamo come distribuire i modelli OpenChatKit con un codice di inferenza personalizzato.
SageMaker si aspetta gli artefatti del modello in formato tar. Creiamo ciascun modello OpenChatKit con i seguenti file: serving.properties e model.py.
Il file di configurazione serving.properties indica a DJL Serving quali librerie di parallelizzazione del modello e di ottimizzazione dell’inferenza si desidera utilizzare. Di seguito è riportato un elenco di impostazioni che utilizziamo in questo file di configurazione:
openchatkit/serving.properties
engine = Python
option.tensor_parallel_degree = 4
option.s3url = {{s3url}}Questo contiene i seguenti parametri:
- engine – Il motore da utilizzare per DJL.
- option.entryPoint – Il file o modulo Python di ingresso. Ciò dovrebbe essere allineato con il motore che viene utilizzato.
- option.s3url – Impostare questo campo con l’URI del bucket S3 che contiene il modello.
- option.modelid – Se si desidera scaricare il modello da huggingface.co, è possibile impostare
option.modelidsull’ID del modello di un modello preaddestrato ospitato all’interno di un repository di modelli su huggingface.co ( https://huggingface.co/models ). Il contenitore utilizza questo ID del modello per scaricare il repository di modelli corrispondente su huggingface.co. - option.tensor_parallel_degree – Impostare questo valore sul numero di dispositivi GPU su cui DeepSpeed deve partizionare il modello. Questo parametro controlla anche il numero di lavoratori per modello che verranno avviati quando DJL Serving viene eseguito. Ad esempio, se abbiamo una macchina con 8 GPU e stiamo creando otto partizioni, avremo un lavoratore per modello per servire le richieste. È necessario regolare il grado di parallelismo e identificare il valore ottimale per una data architettura di modello e piattaforma hardware. Chiamiamo questa capacità parallelismo adattato all’inferenza.
Consultare Configurazioni e impostazioni per un elenco esaustivo di opzioni.
Modelli OpenChatKit
L’implementazione del modello di base di OpenChatKit ha i seguenti quattro file:
- model.py – Questo file implementa la logica di gestione del principale modello GPT-NeoX di OpenChatKit. Riceve la richiesta di input dell’inferenza, carica il modello, carica l’indice di Wikipedia e fornisce la risposta. Fare riferimento a
model.py(creato come parte del notebook) per ulteriori dettagli.model.pyutilizza le seguenti classi chiave:- OpenChatKitService – Questo gestisce il passaggio dei dati tra il modello GPT-NeoX, la ricerca di Faiss e l’oggetto di conversazione. Gli oggetti
WikipediaIndexeConversationsono inizializzati e le conversazioni di chat in ingresso vengono inviate all’indice per cercare contenuti pertinenti da Wikipedia. Vengono inoltre generati ID univoci per ogni invocazione, se non ne è fornito uno, per lo scopo di archiviare i prompt in Amazon DynamoDB. - ChatModel – Questa classe carica il modello e il tokenizer e genera la risposta. Si occupa della partizione del modello su più GPU utilizzando
tensor_parallel_degree, e configura idtypesedevice_map. I prompt vengono passati al modello per generare le risposte. Un criterio di arrestoStopWordsCriteriaè configurato per la generazione, in modo da produrre solo la risposta del bot nell’inferenza. - ModerationModel – Utilizziamo due modelli di moderazione nella classe
ModerationModel: il modello di input per indicare al modello di chat che l’input non è appropriato per sostituire il risultato di inferenza, e il modello di output per sostituire il risultato di inferenza. Classifichiamo il prompt di input e la risposta di output con le seguenti etichette possibili:- casual
- needs caution
- needs intervention (questo viene segnalato per essere moderato dal modello)
- possibly needs caution
- probably needs caution
- OpenChatKitService – Questo gestisce il passaggio dei dati tra il modello GPT-NeoX, la ricerca di Faiss e l’oggetto di conversazione. Gli oggetti
- wikipedia_prepare.py – Questo file si occupa del download e della preparazione dell’indice di Wikipedia. In questo post, utilizziamo un indice di Wikipedia fornito su Hugging Face datasets. Per cercare i documenti di Wikipedia per testo pertinente, l’indice deve essere scaricato da Hugging Face perché non è confezionato altrove. Il file
wikipedia_prepare.pyè responsabile della gestione del download quando viene importato. Solo un processo dei molti che sono in esecuzione per l’inferenza può clonare il repository. Gli altri attendono finché i file non sono presenti nel file system locale. - wikipedia.py – Questo file viene utilizzato per cercare l’indice di Wikipedia per documenti pertinenti dal contesto. La query di input viene tokenizzata e vengono create le embedding utilizzando
mean_pooling. Calcoliamo le metriche di distanza di similarità coseno tra l’embedding della query e l’indice di Wikipedia per recuperare frasi di Wikipedia pertinenti dal contesto. Fare riferimento awikipedia.pyper i dettagli di implementazione.
#funzione per creare l'embedding di una frase usando mean_pooling
def mean_pooling(token_embeddings, mask):
token_embeddings = token_embeddings.masked_fill(~mask[..., None].bool(), 0.0)
sentence_embeddings = token_embeddings.sum(dim=1) / mask.sum(dim=1)[..., None]
return sentence_embeddings
#funzione per calcolare la distanza di similarità coseno tra 2 embedding
def cos_sim_2d(x, y):
norm_x = x / np.linalg.norm(x, axis=1, keepdims=True)
norm_y = y / np.linalg.norm(y, axis=1, keepdims=True)
return np.matmul(norm_x, norm_y.T)- conversation.py – Questo file viene utilizzato per memorizzare e recuperare il thread di conversazione in DynamoDB da passare al modello e all’utente.
conversation.pyè adattato dal repository open-source OpenChatKit. Questo file è responsabile della definizione dell’oggetto che memorizza i turni di conversazione tra l’utente e il modello. In questo modo, il modello è in grado di mantenere una sessione per la conversazione, consentendo all’utente di fare riferimento ai messaggi precedenti. Poiché le invocazioni del punto finale di SageMaker sono senza stato, questa conversazione deve essere memorizzata in una posizione esterna alle istanze del punto finale. All’avvio, l’istanza crea una tabella DynamoDB se non esiste. Tutti gli aggiornamenti della conversazione vengono quindi memorizzati in DynamoDB in base alla chiavesession_id, che viene generata dal punto finale. Qualsiasi invocazione con un ID di sessione recupererà la stringa di conversazione associata e la aggiornerà come richiesto.
Creare un contenitore di inferenza LMI con dipendenze personalizzate
La ricerca dell’indice utilizza la libreria Faiss di Facebook per eseguire la ricerca di similarità. Poiché questo non è incluso nell’immagine base LMI, il contenitore deve essere adattato per installare questa libreria. Il seguente codice definisce un Dockerfile che installa Faiss dalla sorgente insieme ad altre librerie necessarie per il punto finale del bot. Utilizziamo l’utilità sm-docker per compilare e pushare l’immagine in Amazon Elastic Container Registry (Amazon ECR) da Amazon SageMaker Studio. Fare riferimento a Utilizzo della CLI di Amazon SageMaker Studio Image Build per compilare immagini del contenitore dai notebook del tuo Studio per ulteriori dettagli.
Il contenitore DJL non ha Conda installato, quindi Faiss deve essere clonato e compilato dalla sorgente. Per installare Faiss, è necessario installare le dipendenze per l’utilizzo delle API BLAS e il supporto Python. Dopo l’installazione di questi pacchetti, Faiss è configurato per utilizzare AVX2 e CUDA prima di essere compilato con le estensioni Python installate.
Vengono quindi installati pandas, fastparquet, boto3 e git-lfs perché sono necessari per scaricare e leggere i file di indice.
FROM 763104351884.dkr.ecr.us-east-1.amazonaws.com/djl-inference:0.21.0-deepspeed0.8.0-cu117
ARG FAISS_URL=https://github.com/facebookresearch/faiss.git
RUN apt-get update && apt-get install -y git-lfs wget cmake pkg-config build-essential apt-utils
RUN apt search openblas && apt-get install -y libopenblas-dev swig
RUN git clone $FAISS_URL && \
cd faiss && \
cmake -B build . -DFAISS_OPT_LEVEL=avx2 -DCMAKE_CUDA_ARCHITECTURES="86" && \
make -C build -j faiss && \
make -C build -j swigfaiss && \
make -C build -j swigfaiss_avx2 && \
(cd build/faiss/python && python -m pip install )
RUN pip install pandas fastparquet boto3 && \
git lfs install --skip-repo && \
apt-get clean allCreare il modello
Ora che abbiamo l’immagine Docker in Amazon ECR, possiamo procedere con la creazione dell’oggetto modello SageMaker per i modelli OpenChatKit. Deployiamo i modelli di moderazione dell’input e dell’output GPT-NeoXT-Chat-Base-20B usando GPT-JT-Moderation-6B. Fare riferimento a create_model per ulteriori dettagli.
from sagemaker.utils import name_from_base
chat_model_name = name_from_base(f"gpt-neoxt-chatbase-ds")
print(chat_model_name)
create_model_response = sm_client.create_model(
ModelName=chat_model_name,
ExecutionRoleArn=role,
PrimaryContainer={
"Image": chat_inference_image_uri,
"ModelDataUrl": s3_code_artifact,
},
)
chat_model_arn = create_model_response["ModelArn"]
print(f"Created Model: {chat_model_arn}")Configurare il punto finale
Successivamente, definiamo le configurazioni del punto finale per i modelli OpenChatKit. Distribuiamo i modelli utilizzando il tipo di istanza ml.g5.12xlarge. Fare riferimento a create_endpoint_config per ulteriori dettagli.
chat_endpoint_config_name = f"{chat_model_name}-config"
chat_endpoint_name = f"{chat_model_name}-endpoint"
chat_endpoint_config_response = sm_client.create_endpoint_config(
EndpointConfigName=chat_endpoint_config_name,
ProductionVariants=[
{
"VariantName": "variant1",
"ModelName": chat_model_name,
"InstanceType": "ml.g5.12xlarge",
"InitialInstanceCount": 1,
"ContainerStartupHealthCheckTimeoutInSeconds": 3600,
},
],
)Distribuire il punto finale
Infine, creiamo un punto finale utilizzando il modello e la configurazione del punto finale che abbiamo definito nei passaggi precedenti:
chat_create_endpoint_response = sm_client.create_endpoint(
EndpointName=f"{chat_endpoint_name}", EndpointConfigName=chat_endpoint_config_name
)
print(f"Endpoint creato: {chat_create_endpoint_response['EndpointArn']},")Eseguire inferenze dai modelli OpenChatKit
È ora il momento di inviare richieste di inferenza al modello e ottenere le risposte. Passiamo il prompt di testo di input e i parametri del modello come temperature, top_k, e max_new_tokens. La qualità delle risposte del chatbot è basata sui parametri specificati, quindi è consigliabile testare le prestazioni del modello rispetto a questi parametri per trovare l’impostazione ottimale per il proprio caso d’uso. Il prompt di input viene prima inviato al modello di moderazione dell’input, e l’output viene inviato a ChatModel per generare le risposte. Durante questo passaggio, il modello utilizza l’indice di Wikipedia per recuperare sezioni contestualmente pertinenti al modello come prompt per ottenere risposte specifiche del dominio dal modello. Infine, la risposta del modello viene inviata al modello di moderazione dell’output per il controllo della classificazione, e quindi le risposte vengono restituite. Vedere il seguente codice:
def chat(prompt, session_id=None, **kwargs):
if session_id:
chat_response_model = smr_client.invoke_endpoint(
EndpointName=chat_endpoint_name,
Body=json.dumps(
{
"inputs": prompt,
"parameters": {
"temperature": 0.6,
"top_k": 40,
"max_new_tokens": 512,
"session_id": session_id,
"no_retrieval": True,
},
}
),
ContentType="application/json",
)
else:
chat_response_model = smr_client.invoke_endpoint(
EndpointName=chat_endpoint_name,
Body=json.dumps(
{
"inputs": prompt,
"parameters": {
"temperature": 0.6,
"top_k": 40,
"max_new_tokens": 512,
},
}
),
ContentType="application/json",
)
response = chat_response_model["Body"].read().decode("utf8")
return response
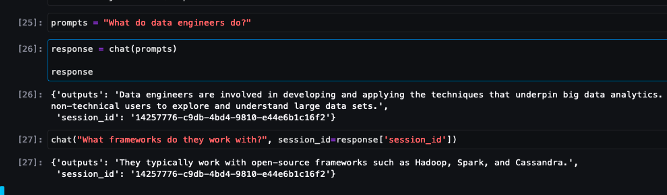
prompts = "Cosa fa un data engineer?"
chat(prompts)Fare riferimento alle interazioni di chat campione di seguito.
Pulire
Seguire le istruzioni nella sezione di pulizia del post per eliminare le risorse fornite come parte di questo post per evitare addebiti non necessari. Fare riferimento ai prezzi di Amazon SageMaker per i dettagli sul costo delle istanze di inferenza.
Conclusione
In questo post, abbiamo discusso dell’importanza dei modelli LLM open source e di come distribuire un modello OpenChatKit su SageMaker per costruire applicazioni di chatbot di nuova generazione. Abbiamo discusso dei vari componenti dei modelli OpenChatKit, dei modelli di moderazione e di come utilizzare una fonte di conoscenza esterna come Wikipedia per i flussi di lavoro di generazione aumentata del recupero (RAG). È possibile trovare istruzioni passo passo nel notebook di GitHub. Fateci sapere quali incredibili applicazioni di chatbot state creando. Cheers!





